Recognition: unknown
Earth System Foundation Model (ESFM): A unified framework for heterogeneous data integration and forecasting
Pith reviewed 2026-05-10 03:18 UTC · model grok-4.3
The pith
ESFM predicts variables in unobserved regions by preserving inter-variable physical relationships.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
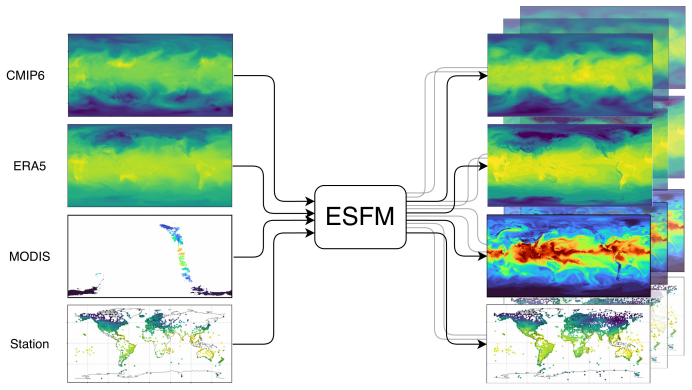
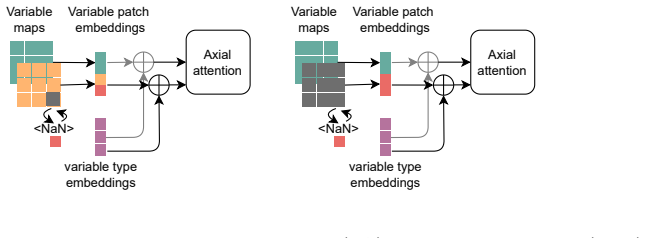
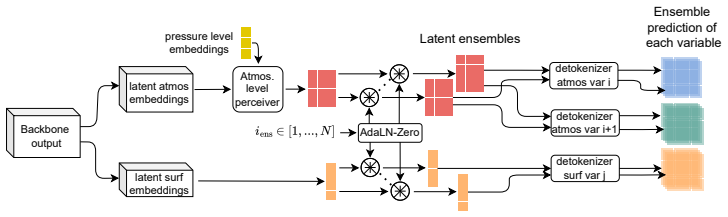
ESFM introduces axial attention to model inter-variable dependencies and per-variable tokenization to handle varying sets of inputs. Trained on dense gridded data like ERA5 and CMIP6 as well as sparse satellite and station data, the model predicts variables in regions or pressure levels lacking initial observations. It preserves physical relationships, for example between temperature, pressure, and humidity. Adaptive layer norm enables probabilistic ensembles, and case studies confirm accurate extreme weather predictions while retaining long-term stability.
What carries the argument
Axial attention for inter-variable dependencies together with individual variable tokenization on the 3D Swin UNet backbone.
If this is right
- Competitive or superior performance on benchmarks using ERA5, CMIP6, regionally masked data, MODIS satellite data, and station data.
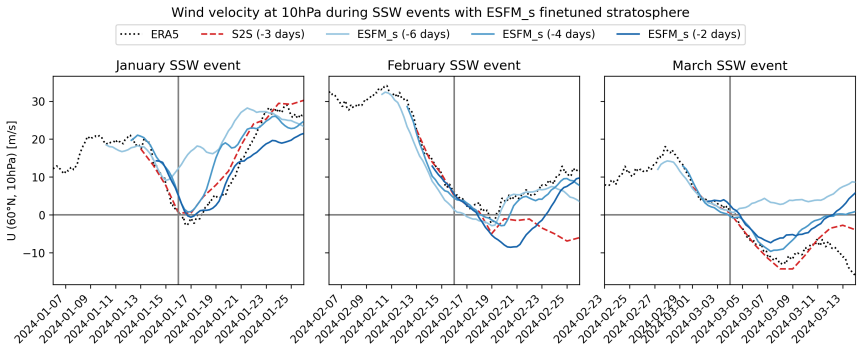
- Accurate positional and magnitude estimates for extreme events such as Super Typhoon Doksuri and sudden stratospheric warming.
- Simple transformation to probabilistic forecasting via adaptive layer norm ensembles.
- Retention of long-term stability from previous foundation models.
- Simplified building of extensions for new downstream tasks due to variable tokenization.
Where Pith is reading between the lines
- Operational forecasting centers could adopt this as a base for multi-source data assimilation to improve predictions in data-poor areas.
- Future work might verify whether the predictions satisfy fundamental conservation laws like mass or energy balance in the extrapolated regions.
- The unified framework might lower barriers for researchers adding new variables or data types without retraining entire models.
Load-bearing premise
Axial attention and variable tokenization extensions allow generalization of physical relationships into unobserved regions without non-physical artifacts or conservation violations.
What would settle it
Independent validation showing that predicted temperature, pressure, and humidity fields in unobserved regions violate known physical correlations or conservation principles.
Figures





















read the original abstract
Foundation models (FMs) for the Earth system learn statistical relationships between physical variables across massive datasets to enable versatile downstream applications through finetuning, separating them from task-specific weather models. Here, we introduce Earth System Foundation Model (ESFM), a fully open model building on the 3D Swin UNet backbone of the pioneering Aurora model. ESFM introduces extensions that increase functionality and foster adoption in climate sciences. First, the encoding scheme and training protocols have been extended to handle diverse datasets, including those containing missing values across all spatio-temporal dimensions such as satellite data, as well as station data, all under one backbone. Axial attention is introduced to capture inter-variable dependencies. As a result ESFM skillfully predicts variables in regions or on pressure levels where no data is present at the initial time, while preserving inter-variable relationships, for example between temperature, pressure, and humidity. Individual variable tokenization enables different sets of variables to be shuffled during training and simplifies the process of building extensions for new downstream tasks. Adaptive layer norm-based ensembles allow for a simple yet effective way to transform deterministic ESFM to a probabilistic FM. We present findings using dense gridded data (ERA5, CMIP6), regionally masked dense data, sparse gridded MODIS satellite data, and station data. Results demonstrate competitive or superior performance relative to state-of-the-art benchmarks. Case studies of Super Typhoon Doksuri (2023) and 2024 sudden stratospheric warming events show accurate positional and magnitude estimations of extreme weather. ESFM retains the strengths of previous foundation models, such as long-term stability, but facilitates application to a variety of downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Earth System Foundation Model (ESFM), an extension of the 3D Swin UNet backbone from the Aurora model. It incorporates axial attention for inter-variable dependencies, individual variable tokenization to handle shuffled variable sets, and training protocols for heterogeneous data including missing values from satellite and station observations. The central claims are that ESFM can predict variables in fully unobserved spatial or pressure-level regions while preserving inter-variable physical relationships (e.g., temperature-pressure-humidity), achieves competitive or superior performance on ERA5, CMIP6, regionally masked, MODIS, and station data, and supports probabilistic ensembles via adaptive layer norm; case studies on Typhoon Doksuri and 2024 sudden stratospheric warming are presented as evidence of accurate extreme-event forecasting.
Significance. If the generalization claims hold with rigorous verification, ESFM would represent a meaningful advance in open foundation models for the Earth system by unifying dense, sparse, and missing-data sources under a single backbone and enabling downstream tasks without task-specific retraining. The open release and support for probabilistic outputs are additional strengths that could facilitate broader adoption in climate applications.
major comments (3)
- [Abstract] Abstract and case-study sections: The headline claim that axial attention plus variable tokenization enables skillful prediction of variables (e.g., temperature, pressure, humidity) in regions or pressure levels with no initial data, while preserving inter-variable relationships, is supported only by qualitative case studies (Doksuri, SSW) and aggregate benchmark scores. No quantitative diagnostics—such as hydrostatic residual, moist-static-energy conservation, or thermodynamic consistency metrics—are reported specifically inside the masked or unobserved regions.
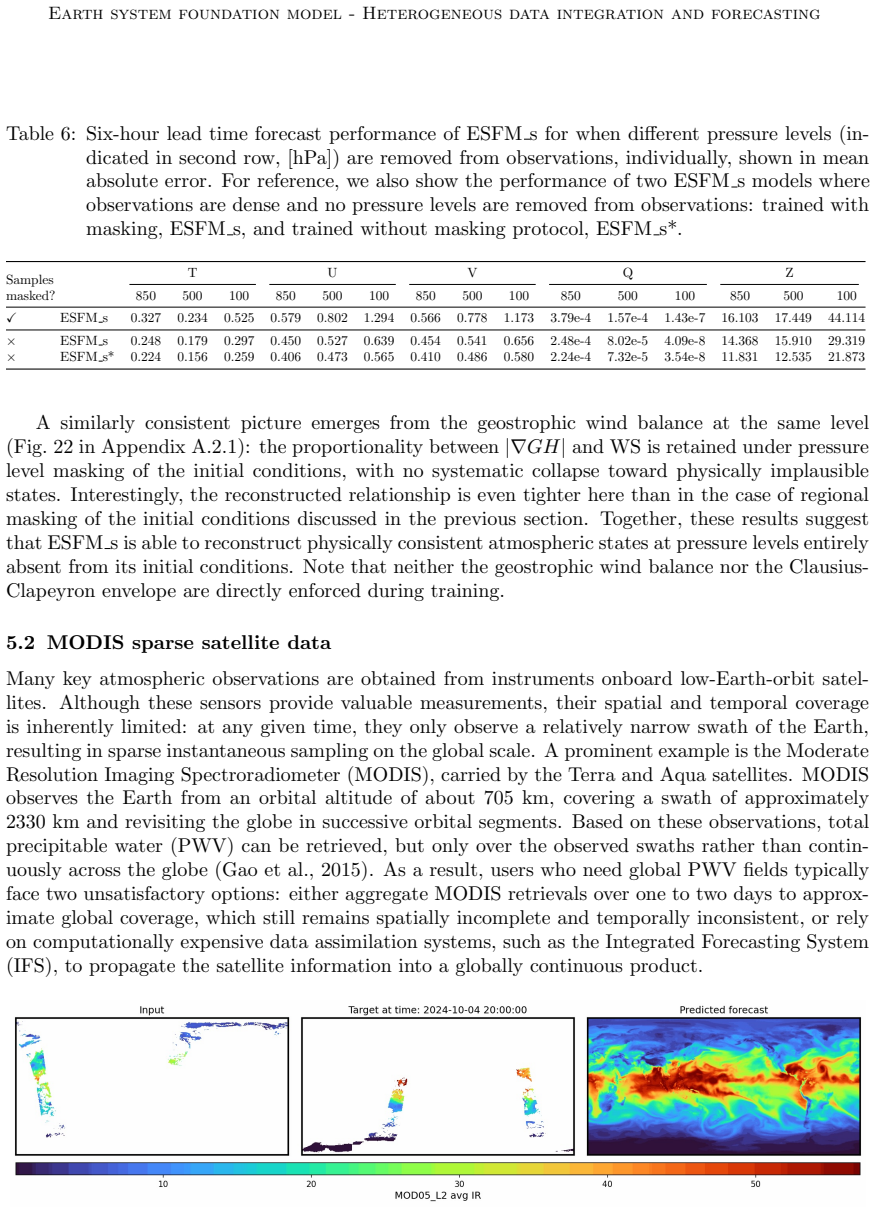
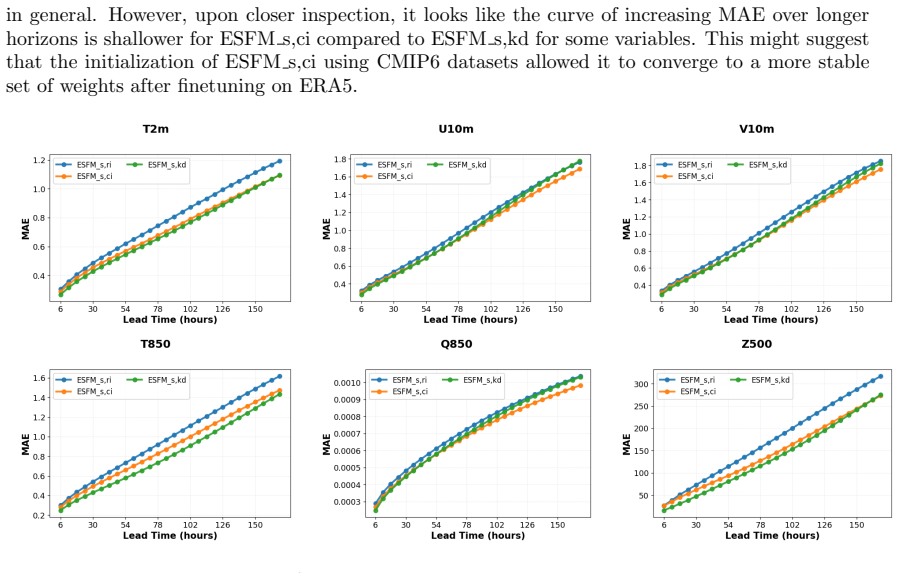
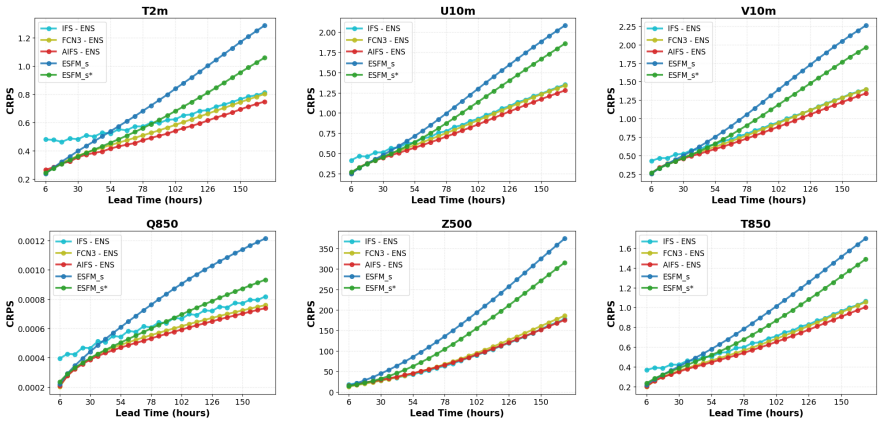
- [Results] Results and methods sections: The manuscript states that results demonstrate competitive or superior performance on dense gridded, regionally masked, sparse MODIS, and station data, yet provides no ablation studies isolating the contribution of axial attention or per-variable tokenization to extrapolation into unobserved regions or to inter-variable preservation.
- [Methods] Training protocols: The description indicates a purely statistical training objective with extensions for missing values across spatio-temporal dimensions, but supplies no details on how missing-data masking is implemented or whether any mechanism (loss term or architectural constraint) encourages physical consistency in the generated fields.
minor comments (2)
- [Abstract] The abstract refers to 'adaptive layer norm-based ensembles' for probabilistic output but does not specify the implementation details or how ensemble spread is calibrated.
- Quantitative performance numbers (RMSE, ACC, etc.) for the benchmark comparisons are absent from the abstract and high-level results summary, making the 'competitive or superior' statement difficult to evaluate without consulting tables or figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and positive assessment of the potential significance of ESFM. We address each of the major comments below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and case-study sections: The headline claim that axial attention plus variable tokenization enables skillful prediction of variables (e.g., temperature, pressure, humidity) in regions or pressure levels with no initial data, while preserving inter-variable relationships, is supported only by qualitative case studies (Doksuri, SSW) and aggregate benchmark scores. No quantitative diagnostics—such as hydrostatic residual, moist-static-energy conservation, or thermodynamic consistency metrics—are reported specifically inside the masked or unobserved regions.
Authors: We agree that additional quantitative evidence would strengthen the claims regarding the preservation of physical relationships in unobserved regions. In the revised manuscript, we will add quantitative diagnostics, including hydrostatic residual and thermodynamic consistency metrics, computed specifically within the masked and unobserved regions for the case studies and benchmarks. These will be included in the Results section to provide more rigorous support for the headline claims. revision: yes
-
Referee: [Results] Results and methods sections: The manuscript states that results demonstrate competitive or superior performance on dense gridded, regionally masked, sparse MODIS, and station data, yet provides no ablation studies isolating the contribution of axial attention or per-variable tokenization to extrapolation into unobserved regions or to inter-variable preservation.
Authors: We acknowledge the value of ablation studies for isolating the effects of axial attention and individual variable tokenization. We will perform and include additional ablation experiments in the revised manuscript. These will compare the full ESFM against variants without axial attention and without per-variable tokenization, evaluating their impact on performance in regionally masked and unobserved data scenarios, as well as on inter-variable consistency. revision: yes
-
Referee: [Methods] Training protocols: The description indicates a purely statistical training objective with extensions for missing values across spatio-temporal dimensions, but supplies no details on how missing-data masking is implemented or whether any mechanism (loss term or architectural constraint) encourages physical consistency in the generated fields.
Authors: We will expand the Methods section to provide a detailed description of the missing-data masking implementation, including how it handles various spatio-temporal patterns in satellite and station data. As the model is trained with a purely statistical objective, physical consistency is learned implicitly from the data rather than enforced through explicit loss terms or constraints. We will clarify this in the revised text and discuss the implications, while noting that the axial attention mechanism aids in capturing inter-variable dependencies statistically. revision: yes
Circularity Check
No circularity in derivation chain; paper is empirical architecture description
full rationale
The paper introduces ESFM as an extension of the Aurora 3D Swin UNet backbone, adding axial attention for inter-variable dependencies and per-variable tokenization for handling heterogeneous data including missing values. All claims of skillful prediction in unobserved regions (e.g., preserving temperature-pressure-humidity relations) are framed as empirical outcomes from training on ERA5, CMIP6, MODIS, and station data, validated via benchmarks and case studies like Typhoon Doksuri and SSW events. No mathematical derivations, equations, or first-principles results are presented that could reduce to fitted parameters or inputs by construction. Self-citations (primarily to Aurora for the backbone) are not load-bearing for the new functionality claims, which rest on reported performance metrics rather than closed loops. This aligns with the absence of any self-definitional, fitted-prediction, or ansatz-smuggling patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
doi: 10.1126/science.1063315. M. P. Baldwin, B. Ayarzag¨ uena, T. Birner, N. Butchart, A. H. Butler, A. J. Charlton-Perez, D. I. V. Domeisen, C. I. Garfinkel, H. Garny, E. P. Gerber, M. I. Hegglin, U. Langematz, and N. M. Pedatella. Sudden Stratospheric Warmings.Reviews of Geophysics, 59(1):e2020RG000708,
-
[4]
ISSN 1944-9208. doi: 10.1029/2020RG000708. K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian. Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast, Nov
- [5]
-
[6]
Accurate medium-range global weather forecasting with 3d neural networks,
ISSN 1476-4687. doi: 10.1038/s41586-023-06185-3. URLhttps://doi.org/10.1038/s41586-023-06185-3. C. Bodnar, W. P. Bruinsma, A. Lucic, M. Stanley, A. Allen, J. Brandstetter, P. Garvan, M. Riechert, J. A. Weyn, H. Dong, et al. A foundation model for the earth system.Nature, pages 1–8,
-
[7]
doi: 10.1175/1520-0493(1980)108⟨1046:TCOEPT⟩2.0.CO;2. B. Bonev, T. Kurth, C. Hundt, J. Pathak, M. Baust, K. Kashinath, and A. Anandkumar. Spherical fourier neural operators: Learning stable dynamics on the sphere. InInternational conference on machine learning, pages 2806–2823. PMLR,
- [8]
-
[9]
doi: 10.1175/AIES-D-23-0006.1. S. R. Cachay, M. Aittala, K. Kreis, N. D. Brenowitz, A. Vahdat, M. Mardani, and R. Yu. Elucidated rolling diffusion models for probabilistic forecasting of complex dynamics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[10]
31 Copernicus Climate Change Service (C3S)
URLhttp://arxiv.org/abs/ 2306.12873. 31 Copernicus Climate Change Service (C3S). Global land surface in-situ observations: Sur- face land dataset, version 2.0. Copernicus Climate Data Store (CDS),
-
[11]
Eyring, S
V. Eyring, S. Bony, G. A. Meehl, C. A. Senior, B. Stevens, R. J. Stouffer, and K. E. Taylor. Overview of the coupled model intercomparison project phase 6 (cmip6) experimental design and organi- zation.Geoscientific Model Development, 9(5):1937–1958,
1937
-
[12]
doi: 10.5194/gmd-9-1937-2016. URLhttps://doi.org/10.5194/gmd-9-1937-2016. B.-C. Gao et al. Modis atmosphere l2 water vapor product. NASA MODIS Adaptive Processing System, Goddard Space Flight Center, USA,
-
[13]
URLhttp://dx.doi.org/10.5067/MODIS/ MOD05_L2.006. M. Giusti, S. Noone, P. Thorne, C. Voces, A. Kettle, K. Healion, R. Dunn, K. Willett, E. Kent, D. Berry, M. Menne, S. McNeill, and N. Casey. Global land surface atmospheric variables from comprehensive in-situ observations: Product user guide.https://confluence.ecmwf.int/ pages/viewpage.action?pageId=57639...
-
[14]
J. Guibas, M. Mardani, Z. Li, A. Tao, A. Anandkumar, and B. Catanzaro. Adaptive fourier neural operators: Efficient token mixers for transformers.arXiv preprint arXiv:2111.13587,
- [15]
-
[16]
URLhttps://arxiv.org/abs/2111.06377. H. Hersbach, B. Bell, P. Berrisford, S. Hirahara, A. Hor´ anyi, J. Mu˜ noz-Sabater, J. Nicolas, C. Peubey, R. Radu, D. Schepers, A. Simmons, C. Soci, S. Abdalla, X. Abellan, G. Balsamo, P. Bechtold, G. Biavati, J. Bidlot, M. Bonavita, G. De Chiara, P. Dahlgren, D. Dee, M. Dia- mantakis, R. Dragani, J. Flemming, R. Forb...
-
[17]
ISSN 0035-9009. doi: 10.1002/qj.3803. URLhttps://doi.org/10.1002/qj.3803. G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network,
-
[18]
URL https://arxiv.org/abs/1503.02531. J. Ho, N. Kalchbrenner, D. Weissenborn, and T. Salimans. Axial Attention in Multidimensional Transformers, Dec
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
URLhttps://journals.ametsoc.org/doi/10.1175/ 2009BAMS2755.1
doi: 10.1175/2009BAMS2755.1. URLhttps://journals.ametsoc.org/doi/10.1175/ 2009BAMS2755.1. A. Kuchar, M. ¨Ohlert, R. Eichinger, and C. Jacobi. Large-ensemble assessment of the Arctic strato- spheric polar vortex morphology and disruptions.Weather and Climate Dynamics, 5(3):895–912, July
-
[21]
doi: 10.5194/wcd-5-895-2024. R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirnsberger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu, A. Merose, S. Hoyer, G. Holland, O. Vinyals, J. Stott, A. Pritzel, S. Mohamed, and P. Battaglia. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421,
-
[22]
Learning skillful medium-range global weather forecasting,
doi: 10.1126/science.adi2336. URLhttps: //www.science.org/doi/abs/10.1126/science.adi2336. S. Lang, M. Alexe, M. Chantry, J. Dramsch, F. Pinault, B. Raoult, M. C. A. Clare, C. Lessig, M. Maier-Gerber, L. Magnusson, Z. B. Bouall` egue, A. P. Nemesio, P. D. Dueben, A. Brown, F. Pappenberger, and F. Rabier. AIFS – ECMWF’s data-driven forecasting system, Aug....
- [23]
- [24]
-
[25]
Y. Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625,
work page internal anchor Pith review arXiv
-
[26]
URLhttp://arxiv.org/abs/2202.11214. W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205,
work page internal anchor Pith review arXiv
-
[27]
L. Qian, J. Rao, R. Ren, C. Shi, and S. Liu. Enhanced stratosphere-troposphere and tropics-Arctic couplings in the 2023/24 winter.Communications Earth & Environment, 5(1):631, Oct
2023
-
[28]
doi: 10.1038/s43247-024-01812-x
ISSN 2662-4435. doi: 10.1038/s43247-024-01812-x. URLhttps://www.nature.com/articles/ s43247-024-01812-x. S. Rasp, S. Hoyer, A. Merose, I. Langmore, P. Battaglia, T. Russel, A. Sanchez-Gonzalez, V. Yang, R. Carver, S. Agrawal, M. Chantry, Z. B. Bouallegue, P. Dueben, C. Bromberg, J. Sisk, L. Bar- rington, A. Bell, and F. Sha. WeatherBench 2: A benchmark fo...
- [29]
-
[30]
ISSN 2169-8996. doi: 10.1029/2018JD028755. C. K. Tang, Y. Tong, and P. Chan. Monsoonal interactions on the track of TC Doksuri (2023) and global models performance.Meteorological Applications, 32(6):e70131,
- [31]
-
[32]
doi: 10.1038/s41612-018-0013-0
ISSN 2397-3722. doi: 10.1038/s41612-018-0013-0. URLhttps://www.nature.com/articles/s41612-018-0013-0. 34 Earth system foundation model - Heterogeneous data integration and forecasting A. Voldoire, D. Saint-Martin, S. S´ en´ esi, B. Decharme, A. Alias, M. Chevallier, J. Colin, J.-F. Gu´ er´ emy, M. Michou, M.-P. Moine, P. Nabat, R. Roehrig, D. Salas Y M´ e...
-
[33]
ISSN 1942-2466, 1942-2466. doi: 10.1029/2019MS001683. O. Watt-Meyer, G. Dresdner, J. McGibbon, S. K. Clark, B. Henn, J. Duncan, N. D. Brenowitz, K. Kashinath, M. S. Pritchard, B. Bonev, et al. ACE: A fast, skillful learned global atmospheric model for climate prediction.arXiv preprint arXiv:2310.02074,
- [34]
-
[35]
35 25%50% 25% Observation mask verticalmask variable mask spatially for each atmos
URLhttps://proceedings.mlr.press/v162/zhou22g.html. 35 25%50% 25% Observation mask verticalmask variable mask spatially for each atmos. var v; for each vertical l;for each var v; Determine #pixels tomask as N = 0.5xHxW; until N is reached, generate contiguous rectangular masks ofsize 0.2N Figure 20: Schematic of the masking applied to the observations for...
2015
-
[36]
dataset for time steps between 1979 and
1979
-
[37]
Accordingly, we have explored variations in the perceiver module, increasing the number of Perceiver blocks, trying newer Perceiver modules, but observed a similar limitation
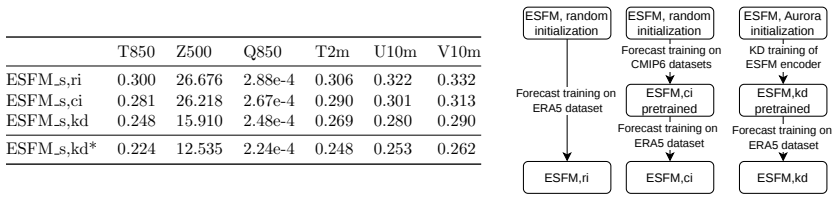
We suspect that this is due to a limitation of the perceiver module for pressure level aggregation. Accordingly, we have explored variations in the perceiver module, increasing the number of Perceiver blocks, trying newer Perceiver modules, but observed a similar limitation. We will investigate this shortcoming further in the future. 36 Earth system found...
1980
-
[38]
The training set comprises timeline between start of 1979 and end of
1979
-
[39]
We select years 2023 and 2024 as the test set
We sample training set randomly and do not actively finetune on the latest years of the training set for any of the experiments. We select years 2023 and 2024 as the test set. Due to prohibitive compute and storage costs, we limit our test set to a subset of these two years. Namely, we pick four weeks that span the year, starting on 02.01, 02.04, 02.07, a...
2023
-
[40]
In Table 16, we list the full set of variables we have used in this work
The naming convention of the variable abbreviations in CMIP6 differ from ERA5. In Table 16, we list the full set of variables we have used in this work. During training, while the pressure levels of atmospheric variables are 42 Earth system foundation model - Heterogeneous data integration and forecasting Table 12: ERA5 variables used for model training (...
1979
-
[41]
50, 250, 500, 600, 700, 850, 925 psl zg, ta, hus, ua, va MRI/MRI-ESM2-0 1950–2014NESM3 1.875 (96,
1950
-
[42]
Dataset Grid res
250, 500, 850 psl ta, ua, va NUIST/NESM3 1950–2014 Table 15: CMPI6 dataset used in the finetuning experiment in Section 5.4.1. Dataset Grid res. [◦] Pixel res. Pressure levels [hPa] Surface vars Atmos vars Full name Time range CNRM 0.5 (360,
1950
-
[43]
Consequently, the dataset only retains stations with≥90% valid hourly data
50, 250, 500, 600, 700, 850, 925 psl, tos, tws, ci zg, ta, ua, va CNRM-CM6-1-HR 1950–2014 for any remaining missing values. Consequently, the dataset only retains stations with≥90% valid hourly data. ECMWF 11k dataset.Our ECMWF 11k dataset builds upon the source data used by Weather- 5K but introduces significant changes; yielding more samples along time ...
1950
-
[44]
•Observation filtering.We do not apply spatial or temporal interpolation; all missing values are preserved asNaN
This results in a total of 11’863 stations and 219’168 hourly timesteps. •Observation filtering.We do not apply spatial or temporal interpolation; all missing values are preserved asNaN. This allows keeping station data free from the biases of reanalysis data, which would not be available at test time for station datasets. Raw observations are snapped to ...
2023
-
[45]
We mapNirregularly spaced weather stations onto aH×Wgrid by wrapping longitudes to [0 ◦,360 ◦), partitioning stations into north-to-south latitude bands and 44 Earth system foundation model - Heterogeneous data integration and forecasting Table 16: CMIP6 variable abbreviations and their full names used in this work. Category Short Name Full Name Surface t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.