Recognition: unknown
BRITE: A Benchmark for Reliable and Interpretable T2V Evaluation on Implausible Scenarios
Pith reviewed 2026-05-09 21:08 UTC · model grok-4.3
The pith
BRITE introduces a human-verified benchmark that exposes how text-to-video models handle static objects well but degrade sharply on actions and audio in implausible scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
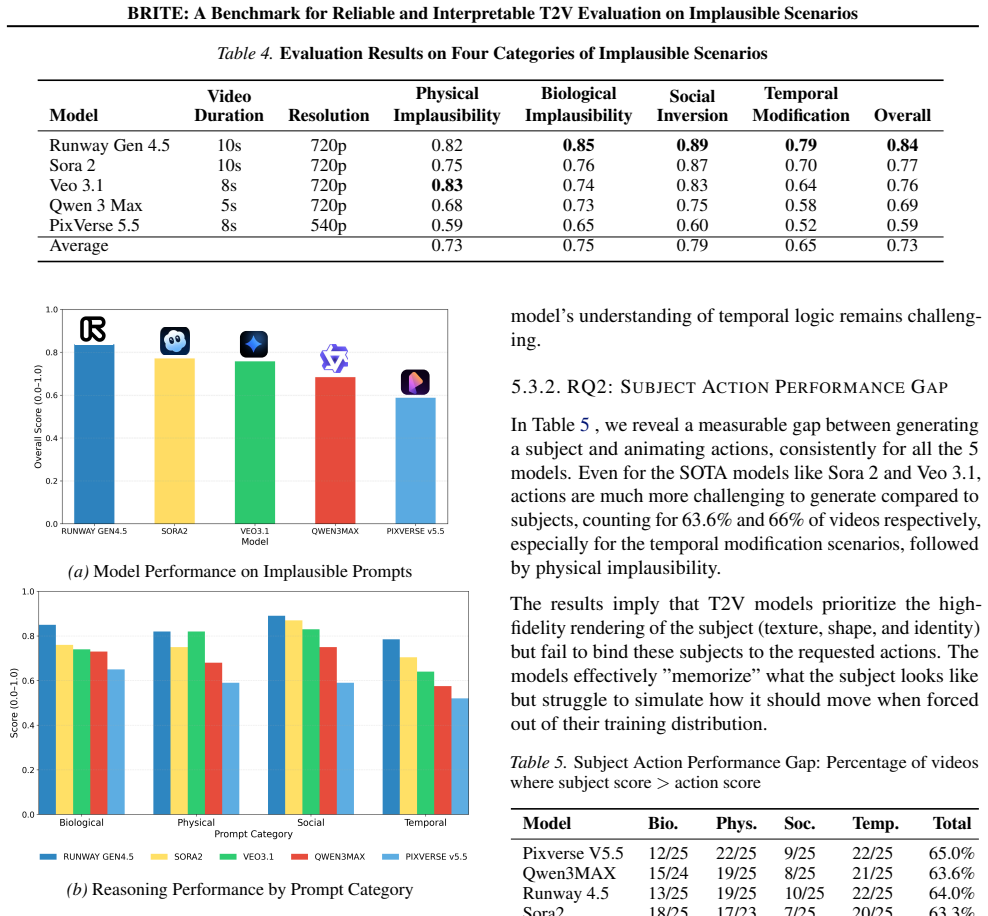
BRITE unifies implausible prompting, fine-grained assessment of audio-visual consistency, and QA-based interpretable evaluation into a single T2V benchmark created through a rigorous human-in-the-loop protocol. When applied to Sora 2, Veo 3.1, Runway Gen4.5, Pixverse V5.5, and Qwen3Max, the framework shows that these models maintain strong performance on static object composition yet suffer significant degradation in object-action binding and audio-visual synchronization.
What carries the argument
The BRITE framework, which uses a human-in-the-loop protocol to generate implausible prompts and apply QA-style scoring for audio-visual and action consistency in generated videos.
If this is right
- T2V models need targeted advances in binding dynamic actions to objects under conditions outside typical training distributions.
- Audio-visual synchronization must be treated as a distinct failure mode separate from visual composition quality.
- QA-based scoring can locate precise limitations in generated videos rather than producing only aggregate scores.
- The benchmark provides a tool for tracking progress on off-manifold prompts as new models are released.
Where Pith is reading between the lines
- Similar human-verified protocols could be adapted to create evaluation sets for text-to-image models that incorporate implied motion or for audio-only generation tasks.
- The observed performance drop suggests that scaling model size may not close the gap without new mechanisms for enforcing temporal and cross-modal consistency.
- Developers could incorporate BRITE-style prompt construction into training data pipelines to improve generalization on unusual events.
Load-bearing premise
A human-in-the-loop protocol for creating and validating the benchmark reliably eliminates hallucination and prompt ambiguity that affect automated evaluation pipelines.
What would settle it
If an automated multimodal LLM pipeline produces the same failure localizations and relative model rankings as the BRITE human protocol when both evaluate identical video outputs, that would indicate the human step does not add unique reliability.
Figures






read the original abstract
The rapid advancement of photorealistic Text-to-Video (T2V) generation brings in an urgent need for up-to-date evaluation methods. Existing benchmarks largely overlooked implausible scenarios and do not measure audio-visual alignment. We introduce BRITE, the first framework that unifies (1) implausible prompting, (2) fine-grained assessment of audio-visual consistency, and (3) QA-based interpretable evaluation into a comprehensive T2V benchmark. Unlike fully automated Multimodal LLM-based pipelines, which are prone to hallucination and prompt ambiguity, BRITE guarantees reliability through a rigorous human-in-the-loop protocol for benchmark creation. Evaluating five state-of-the-art models (Sora 2, Veo 3.1, Runway Gen4.5, Pixverse V5.5, and Qwen3Max), we reveal a critical performance gap: while models excel at static object composition, they exhibit significant degradation in object-action binding and audio-visual synchronization. Our framework offers the community a reliable, interpretable benchmark and evaluation framework that can detect and locate limitations in the next generation of T2V models, especially for off-manifold prompts
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRITE, the first unified benchmark for Text-to-Video (T2V) evaluation that combines implausible prompting, fine-grained audio-visual consistency assessment, and QA-based interpretable evaluation. It relies on a rigorous human-in-the-loop protocol for benchmark creation to ensure reliability (avoiding issues with automated MLLM pipelines), evaluates five SOTA models (Sora 2, Veo 3.1, Runway Gen4.5, Pixverse V5.5, Qwen3Max), and reports that models perform well on static object composition but show significant degradation in object-action binding and audio-visual synchronization.
Significance. If the human-in-the-loop protocol proves reliable and the reported performance gaps hold under detailed scrutiny, BRITE would provide a valuable, interpretable tool for the community to detect and localize limitations in T2V models on off-manifold prompts, addressing gaps in existing benchmarks that overlook implausible scenarios and audio-visual alignment.
major comments (2)
- Abstract: The claim of a 'critical performance gap' with 'significant degradation' in object-action binding and audio-visual synchronization is presented without any quantitative metrics, exact evaluation protocols, dataset sizes, or statistical details. This makes the central empirical finding impossible to assess for magnitude or reliability from the provided text.
- Abstract (human-in-the-loop protocol): The assertion that the protocol 'guarantees reliability' and avoids hallucination/prompt ambiguity is load-bearing for the benchmark's novelty, yet no specifics are given on annotator guidelines, inter-annotator agreement, number of reviewers per item, or how implausible prompts were curated and validated.
minor comments (1)
- Abstract: Model name 'Qwen3Max' should be clarified (possible typo for Qwen-VL or similar) with exact version and citation if applicable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the abstract to better highlight key quantitative aspects and protocol details while preserving its summary nature. All requested information is already present in the full manuscript.
read point-by-point responses
-
Referee: Abstract: The claim of a 'critical performance gap' with 'significant degradation' in object-action binding and audio-visual synchronization is presented without any quantitative metrics, exact evaluation protocols, dataset sizes, or statistical details. This makes the central empirical finding impossible to assess for magnitude or reliability from the provided text.
Authors: We agree that the abstract would benefit from more concrete indicators of the reported gaps to allow readers to gauge magnitude immediately. The full manuscript reports these in Section 5 (Results) and Table 2, including per-category accuracies, dataset size, and statistical tests. In revision we will add a concise clause to the abstract summarizing the scale of degradation (e.g., relative drops across categories) and explicitly reference the evaluation protocol and dataset size. revision: yes
-
Referee: Abstract (human-in-the-loop protocol): The assertion that the protocol 'guarantees reliability' and avoids hallucination/prompt ambiguity is load-bearing for the benchmark's novelty, yet no specifics are given on annotator guidelines, inter-annotator agreement, number of reviewers per item, or how implausible prompts were curated and validated.
Authors: The manuscript already details these elements in Section 3 (Benchmark Construction), including the annotator guidelines (Appendix A), inter-annotator agreement metrics, reviewer count per item, and the multi-stage curation/validation process for implausible prompts. To make the abstract self-contained we will insert a short clause noting the protocol's reliability safeguards (high agreement and multi-reviewer validation) without expanding into full procedural text. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces BRITE as an independent benchmark constructed via human-in-the-loop curation for implausible T2V prompts, with empirical evaluation of five named models reporting performance gaps in object-action binding and audio-visual synchronization. No equations, fitted parameters, or derivations are present that reduce to self-referential inputs or prior self-citations by construction. The central claims rest on the new protocol and observed results rather than renaming known patterns, smuggling ansatzes, or invoking uniqueness theorems from overlapping authors. This is a standard benchmark paper whose evaluation outcomes are falsifiable against external model runs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human evaluators following the described protocol can produce reliable and consistent assessments of audio-visual alignment and object-action binding.
Reference graph
Works this paper leans on
-
[1]
2017 , eprint=
MoCoGAN: Decomposing Motion and Content for Video Generation , author=. 2017 , eprint=
2017
-
[2]
2019 , eprint=
Towards Accurate Generative Models of Video: A New Metric I& Challenges , author=. 2019 , eprint=
2019
-
[3]
The Eleventh International Conference on Learning Representations (ICLR) , year=
Singer, Uriel and Polyak, Adam and Hayes, Thomas and Yin, Xi and An, Jie and Zhang, Songyang and Hu, Qiyuan and Yang, Harry and Ashual, Oron and Gafni, Oran and Parikh, Devi and Gupta, Sonal and Taigman, Yaniv , title=. The Eleventh International Conference on Learning Representations (ICLR) , year=
-
[4]
2022 , eprint=
Imagen Video: High Definition Video Generation with Diffusion Models , author=. 2022 , eprint=
2022
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Huang, Ziqi and Zhang, Fan and Xu, Xiaojie and He, Yinan and Yu, Jiashuo and Dong, Ziyue and Ma, Qianli and Chanpaisit, Nattapol and Si, Chenyang and Jiang, Yuming and Wang, Yaohui and Chen, Xinyuan and Chen, Ying-Cong and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , title=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern...
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
2024 , eprint=
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models , author=. 2024 , eprint=
2024
-
[8]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year=
Kondratyuk, Dan and Yu, Lijun and Gu, Xiuye and Lezama, Jos. Proceedings of the 41st International Conference on Machine Learning (ICML) , year=
-
[9]
2025 , eprint=
Hallucination of Multimodal Large Language Models: A Survey , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
On the Challenges and Opportunities in Generative AI , author=. 2025 , eprint=
2025
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Sun, Kaiyue and Huang, Kaiyi and Liu, Xian and Wu, Yue and Xu, Zihan and Li, Zhenguo and Liu, Xihui , title=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[12]
2025 , eprint=
T2VWorldBench: A Benchmark for Evaluating World Knowledge in Text-to-Video Generation , author=. 2025 , eprint=
2025
-
[13]
Bansal, Hritik and Peng, Clark and Bitton, Yonatan and Goldenberg, Roman and Grover, Aditya and Chang, Kai-Wei , title=. arXiv preprint arXiv:2503.06800 , year=
-
[14]
Etva: Evaluation of text-to-video alignment via fine-grained question generation and answering,
Guan, Kaisi and Lai, Zhengfeng and Sun, Yuchong and Zhang, Peng and Liu, Wei and Liu, Kieran and Cao, Meng and Song, Ruihua , title=. arXiv preprint arXiv:2503.16867 , year=
-
[15]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =
Zechen Bai and Hai Ci and Mike Zheng Shou , title =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =. 2025 , publisher =
2025
-
[16]
2025 , type=
OpenAI , institution=. 2025 , type=
2025
-
[17]
2025 , howpublished=
Introducing. 2025 , howpublished=
2025
-
[18]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[19]
Introducing
Runway , year=. Introducing
-
[20]
2025 , howpublished=
Gen-4 Turbo: Optimized Transformer-based Architecture for Real-time Video Generation , author=. 2025 , howpublished=
2025
-
[21]
PixVerse v5.5: Multi-Shot AI Video Generation and Storytelling Platform , howpublished =
-
[22]
2026 , eprint=
Stress Tests REVEAL Fragile Temporal and Visual Grounding in Video-Language Models , author=. 2026 , eprint=
2026
-
[23]
2025 , eprint=
Breaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding? , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Seeing the Arrow of Time in Large Multimodal Models , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
What Happens When: Learning Temporal Orders of Events in Videos , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.