Recognition: unknown
Retrieval-Guided Generation for Safer Histopathology Image Captioning
Pith reviewed 2026-05-09 20:26 UTC · model grok-4.3
The pith
Retrieving and summarizing expert captions from visually similar histopathology cases produces more accurate and safer descriptions than generating them from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Retrieval-guided generation (RGG) forms captions by summarizing expert text from visually similar cases rather than generating them de novo. On the ARCH histopathology dataset, RGG achieves a cosine similarity of approximately 0.60 with ground truth, versus 0.47 for MedGemma, with non-overlapping confidence intervals. A pathologist-led review shows better preservation of morphology-relevant terminology and fewer unsupported diagnoses, while noting failure modes such as concept mixing and inherited over-specific labeling.
What carries the argument
Retrieval-guided generation, the process of retrieving visually similar images and summarizing their expert-written captions to produce a new caption for the query image.
If this is right
- Higher semantic alignment with reference captions measured by cosine similarity of 0.60 versus 0.47.
- Improved use of morphology-relevant terminology in pathologist evaluations.
- Reduction in unsupported diagnostic claims.
- Increased transparency allowing for auditing of the source materials.
- Exposure of specific failure modes like concept mixing for further mitigation.
Where Pith is reading between the lines
- This technique could apply to other image captioning tasks in medicine where paired image-report data exists, such as radiology.
- Databases of expert captions could be filtered for quality to reduce propagation of errors.
- The method might be used as a baseline or safety check alongside generative models.
- Efficient image retrieval systems would be needed for practical deployment in clinical workflows.
Load-bearing premise
That the expert text associated with retrieved visually similar cases can be summarized to accurately and safely describe the new image without introducing inaccuracies from concept mixing or over-specific inherited claims.
What would settle it
A test where the top retrieved images have captions that contradict key features of the query image, and checking if the resulting summary has more factual errors than a standard generative model.
Figures


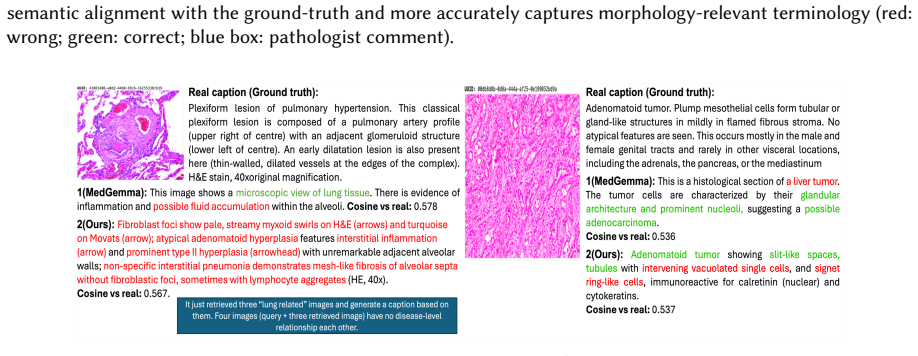

read the original abstract
Generative vision-language models can produce fluent medical image captions but remain prone to hallucination, over-specific diagnostic claims, and factual inconsistency-serious issues in pathology. We investigate retrieval-guided generation (RGG) as a safer alternative, where captions are formed by summarizing expert text from visually similar cases rather than generated de novo. On the ARCH histopathology dataset, RGG improves semantic alignment with ground truth, achieving cosine similarity of $\approx$0.60 versus $\approx$0.47 from MedGemma, with non-overlapping confidence intervals indicating a robust gain. A pathologist-led qualitative review shows better preservation of morphology-relevant terminology and fewer unsupported diagnoses, while revealing failure modes such as concept mixing and inherited over-specific labeling. Overall, retrieval-guided captioning offers a more transparent and reliable approach with clearer opportunities for auditing than fully generative methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes retrieval-guided generation (RGG) for histopathology image captioning as a safer alternative to de novo generation with vision-language models. Captions are formed by summarizing expert text from visually similar retrieved cases. On the ARCH dataset, RGG reports improved semantic alignment via cosine similarity of ≈0.60 versus ≈0.47 for MedGemma, with non-overlapping confidence intervals. A pathologist-led qualitative review indicates better preservation of morphology-relevant terminology and fewer unsupported diagnoses, while noting failure modes including concept mixing and inherited over-specific labeling.
Significance. If the central claims hold after addressing reporting gaps, the work offers a transparent, auditable approach to medical image captioning that leverages existing expert annotations to reduce hallucination risks. This could inform safer AI deployment in pathology, with the empirical comparison and explicit discussion of limitations providing a useful baseline for future retrieval-augmented methods.
major comments (3)
- [Abstract] Abstract: The quantitative claim of improved cosine similarity (≈0.60 vs ≈0.47) is presented without any description of the retrieval implementation, visual similarity metric, embedding model for cosine computation, or summarization procedure. This information is load-bearing for evaluating whether the reported gain is attributable to RGG rather than implementation specifics or dataset artifacts.
- [Abstract] Qualitative review: The safety-related claims of fewer unsupported diagnoses and superior terminology preservation rest solely on an unspecified pathologist-led qualitative review. No details are given on sample size, scoring rubric, definition of 'unsupported diagnosis', or inter-rater agreement, leaving the net safety advantage as an unverified premise despite the paper's own mention of failure modes.
- [Results/Discussion] Results/Discussion: Although failure modes such as concept mixing and inherited over-specific labeling are acknowledged, the manuscript provides no quantitative comparison of their occurrence rates between RGG and the generative baseline. This omission prevents assessment of whether the approach delivers a net reduction in errors.
minor comments (1)
- [Abstract] Abstract: The number of images or cases underlying the quantitative evaluation and confidence intervals should be stated explicitly to allow readers to gauge the robustness of the reported intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The feedback highlights important areas for improving the clarity and completeness of our reporting, particularly in the abstract and results sections. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The quantitative claim of improved cosine similarity (≈0.60 vs ≈0.47) is presented without any description of the retrieval implementation, visual similarity metric, embedding model for cosine computation, or summarization procedure. This information is load-bearing for evaluating whether the reported gain is attributable to RGG rather than implementation specifics or dataset artifacts.
Authors: We agree that the abstract should be self-contained to allow readers to evaluate the source of the reported improvement. The full implementation details—including the retrieval process for identifying visually similar cases, the visual similarity metric, the embedding model used to compute cosine similarity on generated versus reference captions, and the procedure for summarizing retrieved expert text—are provided in the Methods section. In the revised manuscript we will add a concise description of these elements to the abstract so that the quantitative comparison can be properly contextualized. revision: yes
-
Referee: [Abstract] Qualitative review: The safety-related claims of fewer unsupported diagnoses and superior terminology preservation rest solely on an unspecified pathologist-led qualitative review. No details are given on sample size, scoring rubric, definition of 'unsupported diagnosis', or inter-rater agreement, leaving the net safety advantage as an unverified premise despite the paper's own mention of failure modes.
Authors: We acknowledge that the abstract does not supply the requested methodological details for the qualitative review. In the revised version we will expand the relevant paragraph to report the number of cases examined, the scoring rubric applied, our operational definition of an 'unsupported diagnosis', and any available inter-rater agreement statistics. These additions will make the safety-related observations more verifiable while still noting the failure modes that were observed. revision: yes
-
Referee: [Results/Discussion] Results/Discussion: Although failure modes such as concept mixing and inherited over-specific labeling are acknowledged, the manuscript provides no quantitative comparison of their occurrence rates between RGG and the generative baseline. This omission prevents assessment of whether the approach delivers a net reduction in errors.
Authors: We agree that a quantitative breakdown of failure-mode frequencies would allow a clearer judgment of net benefit. We will add to the Results and Discussion sections a table or figure that reports the observed rates of concept mixing and inherited over-specific labeling for both RGG and the MedGemma baseline, derived from the same pathologist-reviewed sample. This will directly address whether the overall error profile is improved. revision: yes
Circularity Check
No circularity: purely empirical method with external baselines
full rationale
The paper proposes retrieval-guided generation (RGG) for histopathology captioning and evaluates it via direct empirical comparison on the ARCH dataset against MedGemma, reporting cosine similarity gains (0.60 vs 0.47) and a qualitative pathologist review. No mathematical derivation chain, first-principles predictions, or self-referential definitions exist in the provided text. Claims rest on dataset metrics and external baselines rather than any fitted parameter or self-citation that reduces the result to its own inputs by construction. The method (retrieve similar cases then summarize) is presented as a practical alternative without tautological loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visually similar histopathology images have expert captions whose summary will be factually appropriate for the query image
Reference graph
Works this paper leans on
-
[1]
S. Kalra, et al., Yottixel – an image search engine for large archives of histopathology whole slide images, Medical Image Analysis 65 (2020) 101757. doi:10.1016/j.media.2020.101757
- [2]
-
[4]
H. R. Tizhoosh, L. Pantanowitz, Artificial intelligence and digital pathology: Challenges and opportunities, Journal of Pathology Informatics 9 (2018) 38. doi:10.4103/jpi.jpi_53_18
-
[5]
A. Sellergren, et al., Medgemma: A family of open medical vision-language models, arXiv preprint arXiv:2507.05201 (2025). doi:10.48550/arXiv.2507.05201
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.05201 2025
-
[6]
Gamper, N
J. Gamper, N. Rajpoot, Multiple instance captioning: Learning representations from histopathology textbooks and articles, in: CVPR, 2021
2021
-
[7]
Biobert: A pre-trained biomedical language representation model for biomedical text mining
J. Lee, et al., Biobert: a pre-trained biomedical language representation model for biomedical text mining, Bioinformatics 36 (2020) 1234–1240. doi:10.1093/bioinformatics/btz682
-
[9]
M. Abdin, et al., Phi-4 technical report, arXiv preprint arXiv:2412.08905 (2024). URL: https: //doi.org/10.48550/arXiv.2412.08905. doi:10.48550/arXiv.2412.08905
work page internal anchor Pith review doi:10.48550/arxiv.2412.08905 2024
-
[10]
J. Bai, et al., Qwen technical report, arXiv preprint arXiv:2309.16609 (2023). URL: https://doi.org/ 10.48550/arXiv.2309.16609. doi:10.48550/arXiv.2309.16609
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16609 2023
-
[11]
R. J. Chen, et al., A general-purpose self-supervised model for computational pathology, arXiv preprint arXiv:2308.15474 (2023). doi:10.48550/arXiv.2308.15474
-
[12]
M. Y. Lu, et al., A visual-language foundation model for computational pathology, Nature Medicine 30 (2024) 863–874. doi:10.1038/s41591-024-02856-4
-
[13]
E. Zimmermann, et al., Virchow2: Scaling self-supervised mixed magnification models in pathology, arXiv preprint arXiv:2408.00738 (2024). doi:10.48550/arXiv.2408.00738
-
[14]
S. Alfasly, et al., Rotation-agnostic image representation learning for digital pathology, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
-
[15]
doi:10.48550/arXiv.2311.08359
-
[16]
A. Riasatian, et al., Fine-tuning and training of densenet for histopathology image representation using tcga diagnostic slides, Medical Image Analysis 70 (2021). doi: 10.1016/j.media.2021. 102032
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.