Recognition: unknown
DIAGRAMS: A Review Framework for Reasoning-Level Attribution in Diagram QA
Pith reviewed 2026-05-09 21:07 UTC · model grok-4.3
The pith
DIAGRAMS proposes visual regions for reasoning in diagram QA using a meta-schema and adapters, achieving 85.39 percent precision and 75.30 percent recall against human reviewer selections across six datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a lightweight, schema-driven review interface with QA-conditioned evidence selection can propose the complete set of regions required for reasoning-level attribution in Diagram QA, attaining micro-averaged 85.39 percent precision and 75.30 percent recall against reviewer-final selections across six datasets and thereby reducing manual region creation while preserving agreement with intended attributions.
What carries the argument
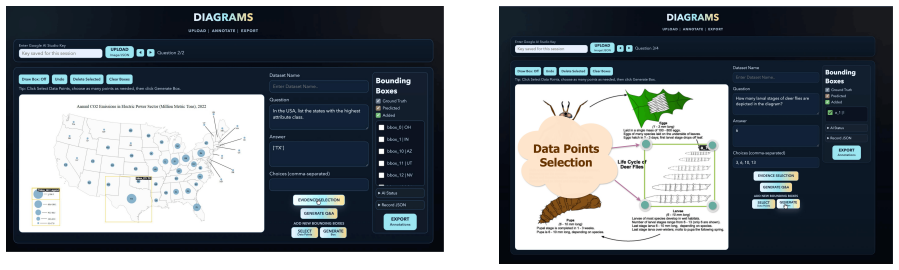
The QA-conditioned evidence selection process inside a meta-schema and dataset-adapter architecture that decouples interface logic from dataset-specific JSON structures and proposes reasoning regions for human verification.
If this is right
- The same interface supports generation of missing QA pairs or candidate regions followed by human verification and refinement.
- High agreement with final reviewer choices enables reliable dataset auditing and creation of grounded supervision data.
- The approach directly supports grounded evaluation of diagram QA models by linking answers to their full reasoning regions.
- Manual effort for building structured evidence sets is reduced while the completeness of reasoning attributions is maintained.
Where Pith is reading between the lines
- The decoupling via meta-schema could be reused for annotation pipelines in other visual reasoning domains such as scientific figures or infographics.
- Model proposals that reach 75 percent recall offer a practical starting point for scaling training data that requires explicit reasoning paths.
- Public release of the demo and package implies the method can become a shared resource for consistent attribution standards across multiple diagram datasets.
Load-bearing premise
The QA-conditioned evidence selection reliably surfaces every region a human would need for reasoning without systematic omissions or dataset-specific biases, and the meta-schema generalizes without hidden per-dataset tuning.
What would settle it
Apply the framework to a seventh Diagram QA dataset never seen during development, collect independent human reviewer selections of reasoning regions, and measure whether precision or recall drops substantially below the reported figures or whether key reasoning regions are consistently omitted.
Figures


read the original abstract
Diagram question answering (Diagram QA) requires reasoning-level attribution that links each question-answer pair to all visual regions needed to derive the answer, rather than only the region containing the final response. Creating such structured evidence across diagrams, charts, maps, circuits, and infographics is time-consuming, and existing annotation tools tightly couple their interfaces to dataset-specific formats. We present DIAGRAMS, a lightweight, schema-driven review framework that decouples interface logic from dataset-specific JSON structures through an internal meta-schema and dataset adapters. Given an image and QA pair with optional candidate regions, the system performs QA-conditioned evidence selection and proposes the regions required for reasoning. When QA pairs or candidate regions are missing, it generates them and supports human verification and refinement. Across six Diagram QA datasets, model-suggested evidence achieves 85.39% precision and 75.30% recall against reviewer-final selections (micro-averaged). These results indicate that the review-first framework reduces manual region creation while maintaining high agreement with final reasoning-level attributions. We release a public demo and installable package to support dataset auditing, grounded supervision creation, and grounded evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DIAGRAMS, a lightweight schema-driven review framework for reasoning-level attribution in Diagram QA. It decouples the interface from dataset-specific formats via an internal meta-schema and adapters, performs QA-conditioned evidence selection to propose regions (or generates them when missing), and supports human verification/refinement. Across six Diagram QA datasets, model-suggested evidence achieves 85.39% micro-averaged precision and 75.30% recall against reviewer-final selections, supporting the claim that the framework reduces manual region creation while maintaining high agreement with final attributions. A public demo and installable package are released.
Significance. If the central empirical claim holds under independent evaluation, the work offers a practical contribution to grounded annotation in visual reasoning by lowering the cost of creating reasoning-level evidence across diagrams, charts, and infographics. The release of reusable tooling could aid dataset auditing and supervised training in the Diagram QA community.
major comments (2)
- The central performance claim (85.39% precision, 75.30% recall) compares model suggestions directly to reviewer-final selections. However, the framework description indicates that reviewers see and can refine the model proposals before finalizing, creating a risk that final attributions are influenced by the initial suggestions. This undermines the independence of the agreement metric and the assertion that the framework reduces manual effort without altering the final reasoning-level attributions. A baseline of scratch annotations performed without model input (or inter-annotator agreement without the tool) is needed to validate the claim.
- The abstract (and presumably the evaluation section) provides no details on the underlying model or method for QA-conditioned region suggestion, how regions are formally defined or delimited, inter-annotator agreement on the final selections, or any comparison to non-model-assisted annotation. These omissions leave the reported precision/recall figures under-supported as evidence for the framework's effectiveness.
minor comments (1)
- The abstract would be strengthened by a one-sentence description of the region suggestion mechanism or region definition to contextualize the numerical results for readers.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address each major point below, clarifying our evaluation design while acknowledging its limitations. We will revise the manuscript to improve clarity and add necessary details and discussion.
read point-by-point responses
-
Referee: The central performance claim (85.39% precision, 75.30% recall) compares model suggestions directly to reviewer-final selections. However, the framework description indicates that reviewers see and can refine the model proposals before finalizing, creating a risk that final attributions are influenced by the initial suggestions. This undermines the independence of the agreement metric and the assertion that the framework reduces manual effort without altering the final reasoning-level attributions. A baseline of scratch annotations performed without model input (or inter-annotator agreement without the tool) is needed to validate the claim.
Authors: We agree that the reported metrics reflect agreement after reviewers have seen and potentially refined the model proposals, which introduces the possibility of anchoring effects. The framework is explicitly designed as a review-first tool in which humans retain final control; the high agreement indicates that model suggestions are largely consistent with human reasoning and therefore reduce the amount of manual region creation required. However, we did not perform a controlled scratch-annotation baseline or measure inter-annotator agreement in the absence of the tool. We will add an explicit limitations paragraph discussing this design choice and the potential for bias, but we cannot supply the requested baseline data without new annotation experiments. revision: partial
-
Referee: The abstract (and presumably the evaluation section) provides no details on the underlying model or method for QA-conditioned region suggestion, how regions are formally defined or delimited, inter-annotator agreement on the final selections, or any comparison to non-model-assisted annotation. These omissions leave the reported precision/recall figures under-supported as evidence for the framework's effectiveness.
Authors: We appreciate the call for greater self-containment. While the body of the paper describes the meta-schema, dataset adapters, and QA-conditioned selection process, we acknowledge that the abstract and evaluation section would benefit from additional explicit information. In the revision we will expand the abstract to note the core method, clarify that regions are delimited as bounding boxes or polygons over diagram elements, report inter-annotator agreement on the final selections, and include a brief comparison of model-assisted versus fully manual annotation effort. revision: yes
- The request for a scratch-annotation baseline or inter-annotator agreement measured without the tool, which would require new controlled annotation experiments beyond the scope of the current study.
Circularity Check
No circularity: empirical claims rest on direct human comparison without derivations or self-referential reductions
full rationale
The paper describes a schema-driven review framework for Diagram QA and reports empirical precision/recall figures from model suggestions versus reviewer-final selections across six datasets. No equations, derivations, fitted parameters, or predictive steps exist that could reduce to inputs by construction. Central claims are supported by direct annotation agreement metrics rather than any self-citation chain, uniqueness theorem, or ansatz smuggling. The evaluation setup compares outputs to independent human refinements, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human reviewers provide reliable ground-truth evidence selections for evaluation.
- domain assumption The six Diagram QA datasets are sufficiently representative for claiming general utility.
Reference graph
Works this paper leans on
-
[1]
International journal of computer vision , volume=
LabelMe: a database and web-based tool for image annotation , author=. International journal of computer vision , volume=. 2008 , publisher=
2008
-
[2]
Proceedings of the 27th ACM international conference on multimedia , pages=
The VIA annotation software for images, audio and video , author=. Proceedings of the 27th ACM international conference on multimedia , pages=
-
[3]
Proceedings of the 29th International Conference on Intelligent User Interfaces , pages=
Snapper: Accelerating Bounding Box Annotation in Object Detection Tasks with Find-and-Snap Tooling , author=. Proceedings of the 29th International Conference on Intelligent User Interfaces , pages=
-
[4]
2020 25th International Conference on Pattern Recognition (ICPR) , pages=
Iterative bounding box annotation for object detection , author=. 2020 25th International Conference on Pattern Recognition (ICPR) , pages=. 2021 , organization=
2020
-
[5]
Computer Vision and Image Understanding , volume=
Human attention in visual question answering: Do humans and deep networks look at the same regions? , author=. Computer Vision and Image Understanding , volume=. 2017 , publisher=
2017
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On the general value of evidence, and bilingual scene-text visual question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Grounding answers for visual questions asked by visually impaired people , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
arXiv preprint arXiv:2509.10345 , year=
Towards understanding visual grounding in visual language models , author=. arXiv preprint arXiv:2509.10345 , year=
-
[9]
2019 , author=
Computer vision annotation tool: A universal approach to data annotation. 2019 , author=. URL https://github. com/openvinotoolkit/cvat , year=
2019
-
[10]
Open source software available from https://github
Label studio: Data labeling software , author=. Open source software available from https://github. com/heartexlabs/label-studio , volume=
-
[11]
Proceedings of the IEEE international conference on computer vision , pages=
Grad-cam: Visual explanations from deep networks via gradient-based localization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[12]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Taking a hint: Leveraging explanations to make vision and language models more grounded , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[13]
European conference on computer vision , pages=
A diagram is worth a dozen images , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[14]
Findings of the association for computational linguistics: ACL 2022 , pages=
ChartQA: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[15]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
CircuitVQA: A visual question answering dataset for electrical circuit images , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2024 , organization=
2024
-
[16]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
InfographicVQA , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[17]
arXiv preprint arXiv:2507.11625 , year=
MapIQ: Evaluating multimodal large language models for map question answering , author=. arXiv preprint arXiv:2507.11625 , year=
-
[18]
Mapwise: Evaluating vision-language models for advanced map queries , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[19]
IJCNLP-AACL , year=
InterChart: Benchmarking Visual Reasoning Across Decomposed and Distributed Chart Information , author=. IJCNLP-AACL , year=
-
[20]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Dvqa: Understanding data visualizations via question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[21]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal chain-of-thought reasoning in language models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review arXiv
-
[22]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[23]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-2: Grounding multimodal large language models to the world , author=. arXiv preprint arXiv:2306.14824 , year=
work page internal anchor Pith review arXiv
-
[24]
Ferret: Refer and ground anything anywhere at any granularity,
Ferret: Refer and ground anything anywhere at any granularity , author=. arXiv preprint arXiv:2310.07704 , year=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Multimodal explanations: Justifying decisions and pointing to the evidence , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.