Recognition: unknown
TRIP-Evaluate: An Open Multimodal Benchmark for Evaluating Large Models in Transportation
Pith reviewed 2026-05-09 20:09 UTC · model grok-4.3
The pith
TRIP-Evaluate supplies an open set of 837 multimodal items to diagnose large-model performance on transportation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
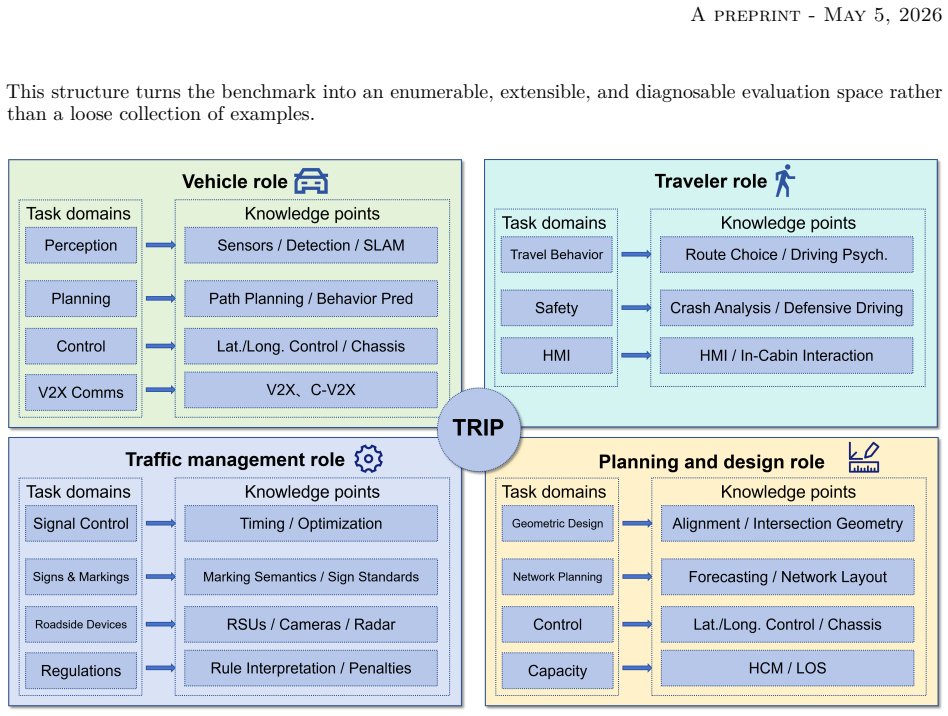
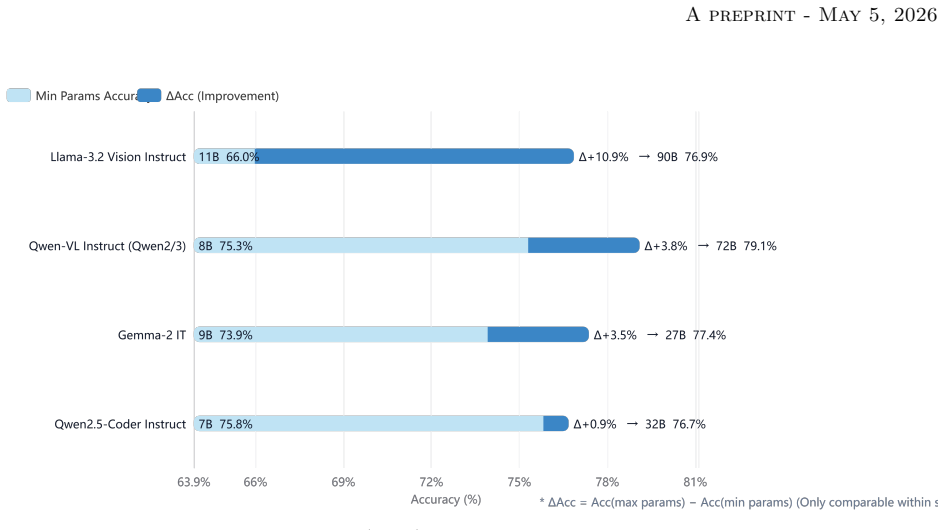
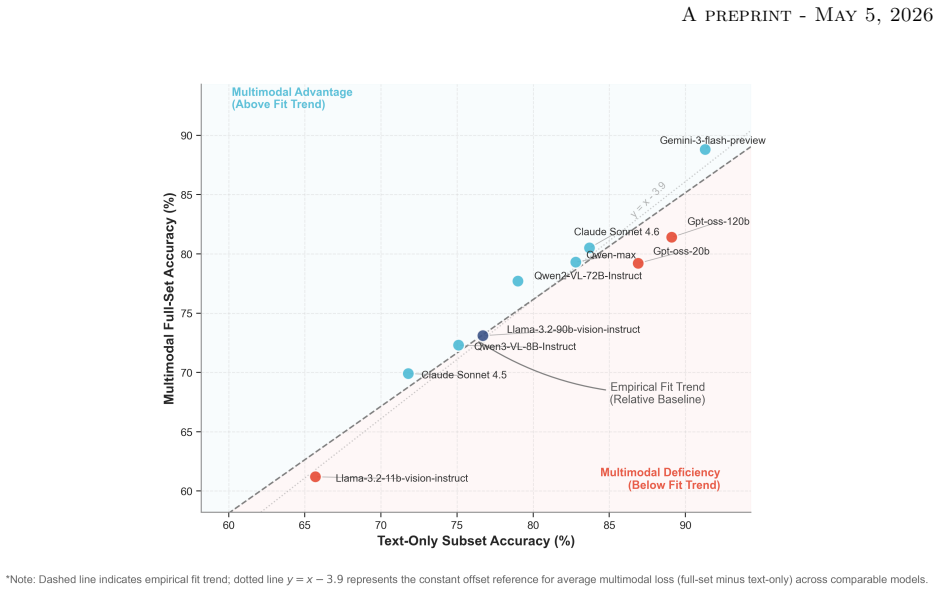
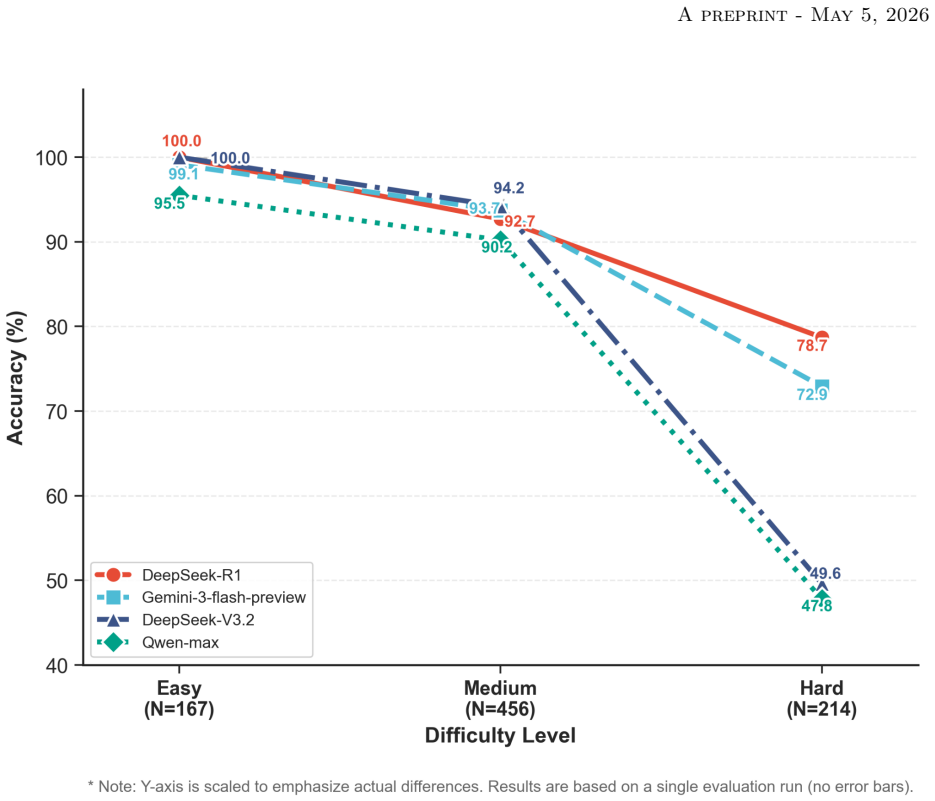
TRIP-Evaluate organizes 837 items under a role-task-knowledge taxonomy that spans vehicle operations, traffic management, traveler services, and planning functions. Each item carries capability, modality, and difficulty tags, with 596 text-only, 198 image, and 43 point-cloud examples. The release also fixes item construction, prompting, decoding, and scoring rules so results can be compared across models. Tests on a range of models show steady gains in text tasks but clear shortfalls in multi-step engineering calculations, rule-constrained reasoning, multimodal scene interpretation, and point-cloud processing.
What carries the argument
The role-task-knowledge taxonomy paired with per-item capability-modality-difficulty annotations that enable diagnosis from aggregate accuracy to individual failure modes.
If this is right
- Model selection for transportation projects can be based on documented strengths and weaknesses rather than general benchmarks.
- Regression testing of updated models becomes repeatable because the item set and scoring rules stay fixed.
- Deployment risk can be lowered by flagging persistent gaps in rule application and multimodal understanding before use.
- Engineering teams gain a common reference for verifying that models handle computation-intensive and safety-critical tasks correctly.
Where Pith is reading between the lines
- Similar taxonomy-driven benchmarks could be built for other regulated domains that combine rules, calculations, and sensor data.
- The current emphasis on static items leaves room for later additions that test dynamic, time-sensitive decision sequences.
- Widespread adoption might push model developers to prioritize verifiable reasoning modules over raw scale.
- Public release of the items and scoring code lowers the barrier for independent audits of transportation AI systems.
Load-bearing premise
The 837 items and their labels represent typical transportation workflows without major selection or annotation bias.
What would settle it
A controlled comparison in which models that score high on TRIP-Evaluate still produce frequent errors on live transportation data or regulatory audits that the benchmark does not cover.
Figures








read the original abstract
Large language models (LLMs) and multimodal large models (MLLMs) are increasingly used for transportation tasks such as regulation question answering, traffic management support, engineering review, and autonomous-driving scene reasoning. Yet transportation workflows are rule-intensive, computation-intensive, safety-critical, and inherently multimodal. Existing general benchmarks provide limited evidence of whether a model can apply regulations correctly, perform verifiable engineering calculations, or interpret traffic scenes reliably, while the small number of public transportation benchmarks remain narrow in scope and rarely support fine-grained diagnosis across text, images, and point-cloud data. To address this gap, we present TRIP-Evaluate, an open multimodal benchmark for large models in transportation. The benchmark organizes 837 items using a role-task-knowledge taxonomy that covers vehicle, traffic-management, traveler, and planning-and-design functions. Each item is annotated with capability, modality, and difficulty labels, enabling diagnosis from overall accuracy down to specific failure modes. The current release includes 596 text items, 198 image items, and 43 point-cloud items. TRIP-Evaluate also standardizes item construction, quality control, prompting, decoding, and scoring to improve cross-model comparability. Results on a diverse panel of models show that text-based performance is improving, but substantial weaknesses remain in multi-step engineering calculation, rule-constrained reasoning, multimodal scene understanding, and point-cloud understanding. Overall, TRIP-Evaluate provides a reproducible, diagnosable, and engineering-aligned evaluation baseline for model selection, regression testing, and safer deployment in transportation applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TRIP-Evaluate, an open multimodal benchmark containing 837 items for evaluating LLMs and MLLMs on transportation tasks. Items are organized via a role-task-knowledge taxonomy spanning vehicle, traffic-management, traveler, and planning-and-design functions; each is annotated with capability, modality (596 text, 198 image, 43 point-cloud), and difficulty labels. The work standardizes item construction, quality control, prompting, decoding, and scoring, and reports high-level results indicating improving text performance alongside persistent weaknesses in multi-step engineering calculations, rule-constrained reasoning, multimodal scene understanding, and point-cloud interpretation. The central claim is that TRIP-Evaluate supplies a reproducible, diagnosable, engineering-aligned baseline for model selection, regression testing, and safer deployment.
Significance. If the items prove representative and the annotations reliable, the benchmark would fill a documented gap between narrow existing transportation evaluations and overly general ones, enabling fine-grained diagnosis across modalities in a safety-critical domain. The open release, standardized protocols, and explicit coverage of point-cloud data constitute concrete strengths that support reproducibility and cross-model comparability.
major comments (2)
- [Abstract and benchmark construction] Abstract and benchmark construction section: The assertion that TRIP-Evaluate constitutes an 'engineering-aligned evaluation baseline' for safer deployment rests on the premise that the 837 curated items and their capability-modality-difficulty annotations accurately reflect real transportation workflows. The manuscript describes the taxonomy and item counts but supplies no sampling methodology from regulatory documents, engineering logs, or practitioner surveys, nor inter-annotator agreement statistics or external coverage audits against transportation corpora. This absence directly affects the diagnosability and deployment-utility claims.
- [Results and evaluation] Results and evaluation section: The abstract states that results reveal specific weaknesses (multi-step engineering calculation, rule-constrained reasoning, multimodal scene understanding). Without accompanying quantitative tables, per-category accuracy figures, or error-analysis breakdowns, the support for these targeted failure-mode claims remains only partially verifiable from the high-level summary.
minor comments (1)
- [Abstract] A per-taxonomy breakdown of the 837 items (beyond the modality totals) would clarify coverage balance across roles and tasks.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of benchmark validity and result presentation that we address below. We have revised the manuscript to incorporate additional details on construction methodology and expanded quantitative results, while maintaining the core claims supported by our development process.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] The assertion that TRIP-Evaluate constitutes an 'engineering-aligned evaluation baseline' rests on the premise that the 837 curated items and their capability-modality-difficulty annotations accurately reflect real transportation workflows. The manuscript describes the taxonomy and item counts but supplies no sampling methodology from regulatory documents, engineering logs, or practitioner surveys, nor inter-annotator agreement statistics or external coverage audits against transportation corpora. This absence directly affects the diagnosability and deployment-utility claims.
Authors: We agree that explicit documentation of the construction process strengthens the engineering-alignment claim. Items were developed by domain experts drawing directly from standard references including the Manual on Uniform Traffic Control Devices (MUTCD), AASHTO design guidelines, NHTSA reports, and common practitioner workflows in traffic management and planning. In the revised manuscript we have added a new subsection (Section 3.2) that details the sourcing process, lists the primary regulatory and engineering documents used for each role category, and provides coverage statistics mapping items to key transportation sub-domains. Inter-annotator agreement was not computed because each item was authored and verified by a single expert with cross-checks by co-authors; we acknowledge this as a limitation and have noted it explicitly. Full external corpus audits remain outside the current scope but are identified as future work. These additions support the diagnosability claims without overstating representativeness. revision: yes
-
Referee: [Results and evaluation] The abstract states that results reveal specific weaknesses (multi-step engineering calculation, rule-constrained reasoning, multimodal scene understanding). Without accompanying quantitative tables, per-category accuracy figures, or error-analysis breakdowns, the support for these targeted failure-mode claims remains only partially verifiable from the high-level summary.
Authors: The full manuscript already contains quantitative results in Section 4, including accuracy tables broken down by modality, role, task, and difficulty level, plus model-specific scores. To address the concern, we have expanded this section with a new error-analysis subsection that provides per-category accuracy figures, counts of failure instances for each mentioned weakness (e.g., multi-step calculation errors, rule violations), and representative examples of model outputs. These tables and breakdowns make the targeted failure-mode claims directly verifiable. The abstract summary is retained as a high-level overview consistent with the detailed data now more prominently presented. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained and independent of its own outputs.
full rationale
The paper describes the manual curation of 837 items, a role-task-knowledge taxonomy, capability-modality-difficulty annotations, and standardized construction/quality-control procedures. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central claim that TRIP-Evaluate supplies a reproducible baseline rests on the explicit, externally verifiable construction steps rather than on any quantity defined in terms of the benchmark's own model scores or annotations. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of prior results is present. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transportation workflows can be comprehensively organized by a role-task-knowledge taxonomy covering vehicle, traffic-management, traveler, and planning-and-design functions
- domain assumption The selected items and their modality/difficulty labels accurately reflect real-world transportation challenges without significant selection bias
Reference graph
Works this paper leans on
-
[1]
Zhou, Z., Z. Gu, X. Qu, et al. MT-GPT: Urban multimodal transportation large model: hierarchical point-line-surface technologies and application scenarios. China Journal of Highway and Transport, 2024, 37(2): 253-274. doi:10.19721/j.cnki.1001-7372.2024.02.020
-
[2]
Wang, P., X. Wei, F. Hu, et al. TransGPT: Multi-modal generative pre-trained transformer for trans- portation. arXiv, 2024. doi:10.48550/arXiv.2402.07233
-
[3]
Holistic Evaluation of Language Models
Liang, P., R. Bommasani, T. Lee, et al. Holistic evaluation of language models. arXiv, 2023. doi:10.48550/arXiv.2211.09110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09110 2023
-
[4]
Ribeiro, M. T., T. Wu, C. Guestrin, et al. Beyond accuracy: Behavioral testing of NLP models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 4902-4912. doi:10.18653/v1/2020.acl-main.442
-
[5]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Srivastava, A., A. Rastogi, A. Rao, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv, 2023. doi:10.48550/arXiv.2206.04615
work page internal anchor Pith review doi:10.48550/arxiv.2206.04615 2023
-
[6]
nuScenes: A multimodal dataset for autonomous driving,
Sun, P., H. Kretzschmar, X. Dotiwalla, et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2443–2451. doi:10.1109/CVPR42600.2020.00252
-
[7]
Yu, H., Y. Luo, M. Shu, et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 21329–21338. doi:10.1109/CVPR52688.2022.02067
-
[8]
Available at:https://cg.cs.tsinghua.edu.cn/ctsdb/
China Traffic Sign Database. Available at:https://cg.cs.tsinghua.edu.cn/ctsdb/
-
[9]
arXiv preprint arXiv:1903.11027 (2019)
Caesar, H., V. Bankiti, A. H. Lang, et al. nuScenes: A multimodal dataset for autonomous driving. arXiv, 2020. doi:10.48550/arXiv.1903.11027
-
[10]
Chen, L., C. Sima, Y. Li, Z. Zheng, J. Xu, and P. Luo. PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark. In Computer Vision – ECCV 2022, Lecture Notes in Computer Science, Vol. 13698, Springer, Cham, 2022, pp. 550–567. https://doi.org/10.1007/978-3 -031-19839-7_32. 17 A preprint - May 5, 2026
-
[11]
Luiten, J., A. Osep, P. Dendorfer, et al. HOTA: A higher order metric for evaluating multi-object tracking. International Journal of Computer Vision, 2021, 129(2): 548-578. doi:10.1007/s11263-020-01375-2
-
[12]
Yuan, J., Y. Zheng, C. Zhang, et al. T-Drive: Driving directions based on taxi trajectories. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, 2010, pp. 99-108. doi:10.1145/1869790.1869807
-
[13]
Krajewski, R., J. Bock, L. Kloeker, et al. The highD dataset: A drone dataset of naturalistic vehicle trajectories on German highways for validation of highly automated driving systems. In Proceed- ings of the 21st International Conference on Intelligent Transportation Systems, 2018, pp. 2118-2125. doi:10.1109/ITSC.2018.8569552
-
[14]
Traffic Analysis Tools: Next Generation Simulation
Federal Highway Administration. Traffic Analysis Tools: Next Generation Simulation. Available at: https://ops.fhwa.dot.gov/trafficanalysistools/ngsim.htm
-
[15]
US Highway 101 Dataset, FHWA-HRT-07-030
Federal Highway Administration. US Highway 101 Dataset, FHWA-HRT-07-030. Available at: https: //www.fhwa.dot.gov/publications/research/operations/07030/index.cfm
-
[16]
Barmpounakis, E., and N. Geroliminis. On the New Era of Urban Traffic Monitoring with Massive Drone Data: The pNEUMA Large-Scale Field Experiment. Transportation Research Part C: Emerging Technologies, 2020, 111: 50–71. doi:10.1016/j.trc.2019.11.023
-
[17]
Wilson, B., W. Qi, T. Agarwal, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting. arXiv, 2023. doi:10.48550/arXiv.2301.00493
work page internal anchor Pith review doi:10.48550/arxiv.2301.00493 2023
-
[18]
Li, Y., R. Yu, C. Shahabi, et al. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv, 2018. doi:10.48550/arXiv.1707.01926
-
[19]
PeMS Data Source
California Department of Transportation. PeMS Data Source. Available at: https://dot.ca.gov/pro grams/traffic-operations/mpr/pems-source
-
[20]
Zhang, J., Y. Zheng, D. Qi, et al. Predicting citywide crowd flows using deep spatio-temporal residual networks. arXiv, 2017. doi:10.48550/arXiv.1701.02543
-
[21]
arXiv:2104.14337 (2021), https://arxiv.org/abs/2104.14337
Kiela, D., M. Bartolo, Y. Nie, et al. Dynabench: Rethinking benchmarking in NLP. arXiv, 2021. doi:10.48550/arXiv.2104.14337
-
[22]
Yu, W., Y. Su, and L. Wang. A review of testing and evaluation research for autonomous driving. Systems Science and Mathematics, 2022, 42(3): 495-508. doi:10.12341/jssms21113
-
[23]
Zhang, X., X. Shi, X. Lou, et al. TransportationGames: Benchmarking transportation knowledge of multimodal large language models. arXiv, 2024. doi:10.48550/arXiv.2401.04471
-
[24]
Xie, S., L. Kong, Y. Dong, et al. Are VLMs ready for autonomous driving? An empirical study from the reliability, data, and metric perspectives. arXiv, 2025. doi:10.48550/arXiv.2501.04003
-
[25]
Sima, C., K. Renz, K. Chitta, et al. DriveLM: Driving with graph visual question answering. arXiv, 2025. doi:10.48550/arXiv.2312.14150
-
[26]
Xu, L., H. Huang, and J. Liu. SUTD-TrafficQA: A question answering benchmark and an efficient network for video reasoning over traffic events. arXiv, 2021. doi:10.48550/arXiv.2103.15538
-
[27]
Deruyttere, T., S. Vandenhende, D. Grujicic, et al. Talk2Car: Taking control of your self-driving car. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 2019, pp. 2088-2098. doi:10.18653/v1/D19-1215
-
[28]
Kim, J., A. Rohrbach, T. Darrell, et al. Textual explanations for self-driving vehicles. arXiv, 2018. doi:10.48550/arXiv.1807.11546
-
[29]
Chen, W., X. Ma, X. Wang, et al. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv, 2023. doi:10.48550/arXiv.2211.12588
work page internal anchor Pith review doi:10.48550/arxiv.2211.12588 2023
-
[30]
Casu, G., and C. Garcia-Garcia. Differential length and overlap with the stem in multiple-choice item options: A pilot experiment. Educational Psychology, 2018, 25: 43-48. doi:10.5093/psed2018a20
-
[31]
Zheng, C., H. Zhou, F. Meng, et al. Large language models are not robust multiple-choice selectors. CoRR, 2023, abs/2309.03882. doi:10.48550/arXiv.2309.03882
-
[32]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages =
Pezeshkpour, P., and E. Hruschka. Large language models sensitivity to the order of options in multiple- choice questions. In Findings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 2006-2017. doi:10.18653/v1/2024.findings-naacl.130. 18 A preprint - May 5, 2026
-
[33]
Chen, X., H. Ma, J. Wan, et al. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6526-6534. doi:10.1109/CVPR.2017.691
-
[34]
DeepSeek-AI, D. Guo, D. Yang, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. Nature, 2025, 645(8081): 633-638. doi:10.1038/s41586-025-09422-z
-
[35]
Gemini 3 Flash Preview
Google AI for Developers. Gemini 3 Flash Preview. Available at: https://ai.google.dev/gemini-api /docs/models/gemini-3-flash-preview
-
[36]
Claude 4.6 model documentation
Anthropic. Claude 4.6 model documentation. Available at: https://platform.claude.com/docs/en/ about-claude/models/whats-new-claude-4-6
-
[37]
Claude Sonnet 4.5
Anthropic. Claude Sonnet 4.5. Available at: https://www.anthropic.com/news/claude-sonnet-4-5
-
[38]
Qwen API Reference
Alibaba Cloud Model Studio. Qwen API Reference. Available at: https://www.alibabacloud.com/h elp/en/model-studio/use-qwen-by-calling-api. Accessed 26, 2026
2026
-
[39]
Qwen2-VL-72B-Instruct model card
Qwen Team. Qwen2-VL-72B-Instruct model card. Available at: https://huggingface.co/Qwen/Qwen 2-VL-72B-Instruct
-
[40]
Qwen3-VL-8B-Instruct model card
Qwen Team. Qwen3-VL-8B-Instruct model card. Available at: https://www.modelscope.cn/models/Q wen/Qwen3-VL-8B-Instruct
-
[41]
Introducing gpt-oss
OpenAI. Introducing gpt-oss. Available at:https://openai.com/index/introducing-gpt-oss/
-
[42]
Llama-3.2-11B-Vision-Instruct model card
Meta. Llama-3.2-11B-Vision-Instruct model card. Available at: https://huggingface.co/meta-llama /Llama-3.2-11B-Vision-Instruct
-
[43]
Llama-3.2-90B-Vision-Instruct Model Card
Meta. Llama-3.2-90B-Vision-Instruct Model Card. Available at: https://huggingface.co/meta-lla ma/Llama-3.2-90B-Vision-Instruct. Accessed March 26, 2026
2026
-
[44]
DeepSeek-V3.2 release note
DeepSeek. DeepSeek-V3.2 release note. Available at: https://api-docs.deepseek.com/news/news25 1201
-
[45]
Gemma-2-27b-it model card
Google. Gemma-2-27b-it model card. Available at: https://huggingface.co/google/gemma-2-27b-i t
-
[46]
Qwen3-8B model card
Qwen Team. Qwen3-8B model card. Available at: https://www.modelscope.cn/models/Qwen/Qwen 3-8B
-
[47]
Qwen2.5-Coder-32B-Instruct model card
Qwen Team. Qwen2.5-Coder-32B-Instruct model card. Available at: https://huggingface.co/Qwen/ Qwen2.5-Coder-32B-Instruct
-
[48]
Bai, J., S. Bai, S. Yang, et al. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv, 2023. doi:10.48550/arXiv.2308.12966
work page internal anchor Pith review doi:10.48550/arxiv.2308.12966 2023
-
[49]
Wei, J., X. Wang, D. Schuurmans, et al. Chain-of-thought prompting elicits reasoning in large language models. arXiv, 2023. doi:10.48550/arXiv.2201.11903
work page internal anchor Pith review doi:10.48550/arxiv.2201.11903 2023
-
[50]
Wang, X., J. Wei, D. Schuurmans, et al. Self-consistency improves chain-of-thought reasoning in language models. arXiv, 2023. doi:10.48550/arXiv.2203.11171
-
[51]
Yao, S., D. Yu, J. Zhao, et al. Tree of thoughts: Deliberate problem solving with large language models. arXiv, 2023. doi:10.48550/arXiv.2305.10601. 19
work page internal anchor Pith review doi:10.48550/arxiv.2305.10601 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.