Recognition: unknown
"I Don't Know" -- Towards Appropriate Trust with Certainty-Aware Retrieval Augmented Generation
Pith reviewed 2026-05-09 18:27 UTC · model grok-4.3
The pith
CERTA uses relevance between question, context, and answer to express uncertainty in RAG outputs and reduce overconfidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CERTA enhances standard RAG by incorporating relevance scores computed between the question, the retrieved context, and the generated answer to modulate the certainty conveyed in the final response, enabling more reliable and honest behavior on non-objective questions.
What carries the argument
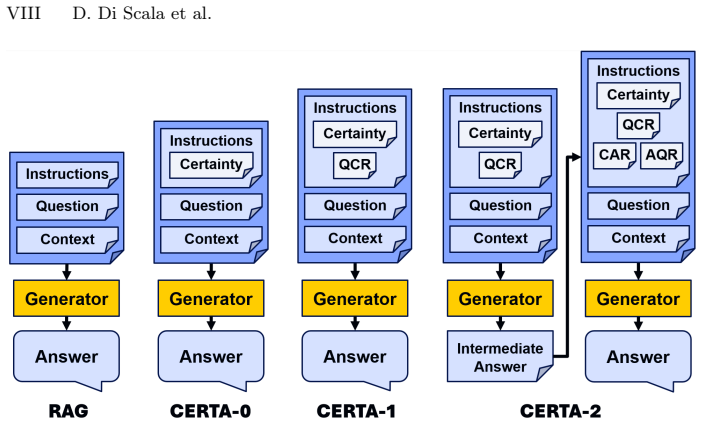
CERTA (Certainty Enhanced RAG for Trustworthy Answers), a system that uses relevance scores between question, context, and answer to determine and express uncertainty levels.
If this is right
- CERTA identifies answers that are uncertain.
- It decreases cases of over-agreeing with the user.
- It produces cautious behavior when prompted for moral judgments.
- It supports appropriate trust levels across the four benchmark categories of factuality, preference, sycophancy, and morality.
Where Pith is reading between the lines
- The same relevance-based certainty signal could be tested on objective factual questions to see whether it still improves calibration.
- Integration of CERTA-style scoring into production RAG pipelines might reduce user over-reliance on incorrect outputs.
- The approach suggests that explicit uncertainty signaling could be combined with other self-reflection techniques already used in LLMs.
Load-bearing premise
Relevance scores computed between question, context, and answer serve as a reliable proxy for the actual uncertainty or correctness of the LLM-generated answer on non-objective questions.
What would settle it
A direct comparison on the Certainty Benchmark where human raters score answer correctness and trustworthiness independently of CERTA's relevance-based certainty ratings, checking whether the two measures align or diverge.
Figures






read the original abstract
Achieving the right amount of trust in AI systems is important, but challenging. The problem is exacerbated with the rise of Large Language Models (LLMs) as they provide human-level communication capabilities, but potentially hallucinate in the content that they generate. Moreover, they express over-confidence in their answers, making it difficult for users to judge their truthfulness. An important human value that users seek is benevolence, which can be met by LLM's self-reflection leading to reliable and honest answers. Accordingly, this paper proposes conveying appropriate levels of self-reflected certainty to build appropriate trust. Our contributions are twofold: 1) We develop CERTA (Certainty Enhanced RAG for Trustworthy Answers), a specialized Retrieval Augmented Generation (RAG) system that incorporates the relevance between question, context, and answer to reflect its uncertainty in answering questions; 2) We create the Certainty Benchmark with 90 question-context pairs of non-objective questions, divided over four categories (factuality, preference, sycophancy, morality) and three types of contexts (relevant, incomplete, irrelevant). We run experiments with a baseline RAG system and three CERTA settings using two LLMs. Our evaluations indicate that CERTA helps identify answers that are uncertain, decreases the cases of over-agreeing, and provides cautious behavior when prompted for moral judgments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CERTA, a specialized RAG system that uses relevance scores computed between a question, retrieved context, and generated answer as a proxy for the LLM's uncertainty. It introduces a new Certainty Benchmark consisting of 90 question-context pairs spanning four categories (factuality, preference, sycophancy, morality) and three context types (relevant, incomplete, irrelevant). Experiments compare a baseline RAG system against three CERTA variants on two LLMs, claiming that CERTA better identifies uncertain answers, reduces over-agreement, and elicits more cautious responses on moral judgments.
Significance. If the relevance-based certainty proxy can be shown to correlate with actual epistemic uncertainty or correctness, the work would offer a lightweight, retrieval-grounded mechanism for calibrating LLM confidence on non-objective queries. The dedicated benchmark for certainty assessment across subjective categories would also be a useful contribution to evaluation practices in trustworthy AI.
major comments (3)
- [Abstract] Abstract and evaluation description: the claim that CERTA 'helps identify answers that are uncertain' and 'decreases the cases of over-agreeing' is presented without any quantitative metrics, error bars, statistical tests, or raw counts of agreement rates, making the magnitude and reliability of the reported improvements impossible to assess.
- [Benchmark and Method] Benchmark construction and proxy definition (implicit in §3–4): relevance scores between question, context, and answer are treated as a direct proxy for certainty without any external calibration against human uncertainty judgments or known hallucination cases. For the preference, sycophancy, and morality categories, where no objective ground truth exists, this proxy risks conflating context mismatch with epistemic uncertainty.
- [Method] Implementation details (method section): no equations, pseudocode, or parameter settings are supplied for how raw relevance scores (embedding similarity or LLM judge) are thresholded or combined into the final certainty signal used to modulate the answer, preventing reproduction or sensitivity analysis.
minor comments (2)
- [Benchmark] The benchmark size of 90 pairs is modest; reporting per-category breakdowns and inter-annotator agreement (if any human validation was performed) would strengthen the evaluation.
- [Experiments] Clarify whether the same LLM is used both for generation and for relevance judging, as this could introduce circularity in the certainty estimation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate to improve clarity, reproducibility, and discussion of limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the claim that CERTA 'helps identify answers that are uncertain' and 'decreases the cases of over-agreeing' is presented without any quantitative metrics, error bars, statistical tests, or raw counts of agreement rates, making the magnitude and reliability of the reported improvements impossible to assess.
Authors: We agree that the abstract and high-level evaluation description summarize results only qualitatively. The manuscript reports experimental comparisons between baseline RAG and CERTA variants across the 90-question Certainty Benchmark, but we acknowledge the absence of specific metrics in the abstract. We will revise the abstract to include key quantitative results, such as identification rates for uncertain answers and reductions in over-agreement, along with raw counts. Given the benchmark's modest size, we did not compute error bars or conduct formal statistical tests; we will add a brief note on result reliability in the revised text. revision: yes
-
Referee: [Benchmark and Method] Benchmark construction and proxy definition (implicit in §3–4): relevance scores between question, context, and answer are treated as a direct proxy for certainty without any external calibration against human uncertainty judgments or known hallucination cases. For the preference, sycophancy, and morality categories, where no objective ground truth exists, this proxy risks conflating context mismatch with epistemic uncertainty.
Authors: The relevance proxy is designed to flag cases where retrieved context is insufficient to support a confident response, serving as a practical, retrieval-grounded signal for uncertainty in RAG settings. We did not perform external calibration against human judgments or hallucination benchmarks, which is a limitation we recognize. For subjective categories, we view context mismatch as a valid trigger for expressing uncertainty rather than overconfident answers. We will expand the discussion in §3–4 to explicitly address this risk of conflation, clarify the proxy's scope as a lightweight heuristic rather than a calibrated epistemic measure, and note the absence of human validation as future work. revision: partial
-
Referee: [Method] Implementation details (method section): no equations, pseudocode, or parameter settings are supplied for how raw relevance scores (embedding similarity or LLM judge) are thresholded or combined into the final certainty signal used to modulate the answer, preventing reproduction or sensitivity analysis.
Authors: We agree that the method section omits the requested implementation details, which hinders reproducibility. We will add formal equations describing relevance score computation and combination into the certainty signal, pseudocode for the full CERTA pipeline (including how the signal modulates the generated answer), and the specific parameter settings and thresholds used for the three CERTA variants in our experiments with both LLMs. These additions will support reproduction and enable sensitivity analyses by readers. revision: yes
Circularity Check
No circularity in CERTA derivation or evaluations
full rationale
The paper introduces CERTA as a RAG variant that incorporates relevance scores between question, context, and answer to convey uncertainty, then evaluates it empirically on a newly created 90-pair Certainty Benchmark across four categories and three context types. No equations, fitted parameters, or self-citation chains appear in the provided text. The central claims rest on direct comparisons to a baseline RAG system using the external benchmark, with no reduction of predictions or uniqueness claims back to the method's own inputs by construction. This is a standard empirical systems paper with independent evaluation content.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Relevance between question, context, and answer can serve as a proxy for the certainty of the generated answer
invented entities (1)
-
CERTA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Intelligent Systems and Technology (TIST)12(4), 1–29 (2021)
Aydoğan, R., Kafali, Ö., Arslan, F., Jonker, C.M., Singh, M.P.: Nova: Value-based negotiation of norms. ACM Transactions on Intelligent Systems and Technology (TIST)12(4), 1–29 (2021)
2021
-
[2]
doi:10.48550/arXiv.2401.17072 , abstract =
Aynetdinov, A., Akbik, A.: Semscore: Automated evaluation of instruction-tuned llms based on semantic textual similarity. arXiv preprint arXiv:2401.17072 (2024)
-
[3]
Personality and Social Psychology Bulletin29(10), 1207–1220 (2003)
Bardi, A., Schwartz, S.H.: Values and behavior: Strength and structure of relations. Personality and Social Psychology Bulletin29(10), 1207–1220 (2003)
2003
-
[4]
Carro, M.V.: Flattering to deceive: The impact of sycophantic behavior on user trust in large language model. preprint arXiv:2412.02802 (2024)
-
[5]
arXiv preprint arXiv:2501.08208 (2025)
Chowdhury, M., He, Y.V., Higham, A., Lim, E.: ASTRID–An Automated and Scalable TRIaD for the Evaluation of RAG-based Clinical Question Answering Systems. arXiv preprint arXiv:2501.08208 (2025)
-
[6]
Cima, L.R., De Jonge, D., Osman, N.: Towards the incorporation of social values in automatednegotiationstrategies.In:InternationalWorkshoponValueEngineering in AI. pp. 193–207. Springer (2024) Towards Appropriate Trust with Certainty-Aware RAG XIX
2024
-
[7]
In: Twenty-Sixth IJCAI
Cranefield, S., Winikoff, M., Dignum, V., Dignum, F.: No Pizza for You: Value- based Plan Selection in BDI Agents. In: Twenty-Sixth IJCAI. pp. 178–184 (2017)
2017
-
[8]
Deng, Y., Zhao, Y., Li, M., Ng, S.K., Chua, T.S.: Don’t Just Say "I don’t know"! Self-aligning Large Language Models for Responding to Unknown Questions with Explanations. arXiv preprint arXiv:2402.15062 (2024)
-
[9]
In: Companion Proceedings of the ACM on Web Conference 2025
Dey, P., Merugu, S., Kaveri, S.: Uncertainty-aware fusion: An ensemble framework for mitigating hallucinations in large language models. In: Companion Proceedings of the ACM on Web Conference 2025. pp. 947–951 (2025)
2025
-
[10]
In: Proceedings of AAMAS
Erdogan, E., Aydın, H., Dignum, F., Verbrugge, R., Yolum, P.: Mitigating privacy conflicts with computational theory of mind. In: Proceedings of AAMAS. pp. 695– 703 (2025)
2025
-
[11]
Journal of Cross-Cultural Psychology42(7), 1127– 1144 (2011)
Fischer, R., Schwartz, S.: Whence differences in value priorities? individual, cul- tural, or artifactual sources. Journal of Cross-Cultural Psychology42(7), 1127– 1144 (2011)
2011
-
[12]
Early engagement and new technologies: Opening up the laboratory pp
Friedman, B., Kahn, P.H., Borning, A., Huldtgren, A.: Value sensitive design and information systems. Early engagement and new technologies: Opening up the laboratory pp. 55–95 (2013)
2013
-
[13]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., et al.: A survey on llm-as-a-judge. arXiv preprint arXiv:2411.15594 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
In: VALE
Guerrero, E., Tzeng, S.T., Pastrav, C., Dignum, F.: Value-based decision-making in software agents: A systematic literature review. In: VALE. pp. 137–154. Springer (2025)
2025
-
[16]
Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., Steinhardt, J.: Aligning AI with shared human values. arXiv preprint arXiv:2008.02275 (2020)
-
[17]
In: International Conference on Machine Learning
Huang, Y., Sun, L., Wang, H., Wu, S., Zhang, Q., Li, Y., Gao, C., Huang, Y., Lyu, W., Zhang, Y., et al.: Position: Trustllm: Trustworthiness in large language models. In: International Conference on Machine Learning. pp. 20166–20270. PMLR (2024)
2024
-
[18]
ACM Comput
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM Comput. Surv.55(12) (mar 2023)
2023
-
[19]
ACM TOIT18(4), 1–21 (2018)
Kayal, A., Brinkman, W.P., Neerincx, M.A., Riemsdijk, M.B.V.: Automatic reso- lution of normative conflicts in supportive technology based on user values. ACM TOIT18(4), 1–21 (2018)
2018
-
[20]
I’m Not Sure, But
Kim, S.S., Liao, Q.V., Vorvoreanu, M., Ballard, S., Vaughan, J.W.: " I’m Not Sure, But...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. In: Proceedings of the 2024 ACM FAccT. pp. 822–835 (2024)
2024
-
[21]
Computers in Human Behavior 160, 108352 (2024)
Klingbeil,A.,Grützner,C.,Schreck,P.:TrustandrelianceonAI—Anexperimental study on the extent and costs of overreliance on AI. Computers in Human Behavior 160, 108352 (2024)
2024
-
[22]
Master’s thesis, TU Wien (2025)
König, S.: Automated evaluation and parameter optimisation for retrieval aug- mented generation systems. Master’s thesis, TU Wien (2025)
2025
-
[23]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Lin, S., Hilton, J., Evans, O.: TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958 (2021)
work page internal anchor Pith review arXiv 2021
-
[24]
Autonomous Agents and Multi-Agent Systems36(1), 23 (2022) XX D
Liscio, E., van der Meer, M., Siebert, L.C., Jonker, C.M., Murukannaiah, P.K.: What values should an agent align with? an empirical comparison of general and context-specific values. Autonomous Agents and Multi-Agent Systems36(1), 23 (2022) XX D. Di Scala et al
2022
-
[25]
ACM Transactions on Information Systems 43(2), 1–32 (2025)
Lyu, Y., Li, Z., Niu, S., Xiong, F., Tang, B., Wang, W., Wu, H., Liu, H., Xu, T., Chen, E.: Crud-rag: A comprehensive chinese benchmark for retrieval-augmented generation of large language models. ACM Transactions on Information Systems 43(2), 1–32 (2025)
2025
-
[26]
ACM Journal on Responsible Computing1(4), 1–45 (2024)
Mehrotra, S., Degachi, C., Vereschak, O., Jonker, C.M., Tielman, M.L.: A sys- tematic review on fostering appropriate trust in human-ai interaction: Trends, opportunities and challenges. ACM Journal on Responsible Computing1(4), 1–45 (2024)
2024
-
[27]
In: Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society
Mehrotra, S., Jonker, C.M., Tielman, M.L.: More similar values, more trust?-the effect of value similarity on trust in human-agent interaction. In: Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. pp. 777–783 (2021)
2021
-
[28]
Efficient Estimation of Word Representations in Vector Space
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word repre- sentations in vector space. arXiv arXiv:1301.3781 (2013)
work page internal anchor Pith review arXiv 2013
-
[29]
https://mistral.ai/news/mistral-small-3-1, [Accessed 10- 10-2025]
Mistral Small 3.1 Model. https://mistral.ai/news/mistral-small-3-1, [Accessed 10- 10-2025]
2025
-
[30]
arXiv preprint arXiv:2501.03995 , year=
Mortaheb, M., Khojastepour, M.A.A., Chakradhar, S.T., Ulukus, S.: Rag- check: Evaluating multimodal retrieval augmented generation performance. arXiv preprint arXiv:2501.03995 (2025)
-
[31]
OpenAIPlatformChatGPT-4oLatest.https://platform.openai.com/docs/models/ chatgpt-4o-latest, [Accessed 10-10-2025]
2025
-
[32]
OpenAIPlatformGPT-4.1Model.https://platform.openai.com/docs/models/gpt- 4.1/, [Accessed 10-10-2025]
2025
-
[33]
https://platform.openai.com/docs/guides/embeddings, [Accessed 10-10-2025]
OpenAI Platform Vector Embedding Models. https://platform.openai.com/docs/guides/embeddings, [Accessed 10-10-2025]
2025
-
[34]
arXiv preprint arXiv:2408.10392 (2024)
Padhi, I., Ramamurthy, K.N., Sattigeri, P., Nagireddy, M., Dognin, P., Varshney, K.R.: Value alignment from unstructured text. arXiv preprint arXiv:2408.10392 (2024)
-
[35]
Microsoft Research 339, 340 (2022)
Passi, S., Vorvoreanu, M.: Overreliance on AI literature review. Microsoft Research 339, 340 (2022)
2022
-
[36]
Philosophy and engi- neering: Reflections on practice, principles and process pp
Van de Poel, I.: Translating values into design requirements. Philosophy and engi- neering: Reflections on practice, principles and process pp. 253–266 (2013)
2013
-
[37]
preprint arXiv:2311.09476 (2023)
Saad-Falcon, J., Khattab, O., Potts, C., Zaharia, M.: Ares: An automated evaluation framework for retrieval-augmented generation systems. preprint arXiv:2311.09476 (2023)
-
[38]
Online readings in Psychology and Culture2(1), 11 (2012)
Schwartz, S.H.: An overview of the schwartz theory of basic values. Online readings in Psychology and Culture2(1), 11 (2012)
2012
-
[39]
Journal of Personality and Social Psychology 103(4), 663 (2012)
Schwartz, S.H., Cieciuch, J., Vecchione, M., Davidov, E., Fischer, R., Beierlein, C., Ramos, A., Verkasalo, M., Lönnqvist, J.E., Demirutku, K., et al.: Refining the theory of basic individual values. Journal of Personality and Social Psychology 103(4), 663 (2012)
2012
-
[40]
Minds and Machines33(4), 761–790 (2023)
Serramia, M., Rodriguez-Soto, M., Lopez-Sanchez, M., Rodriguez-Aguilar, J.A., Bistaffa, F., Boddington, P., Wooldridge, M., Ansotegui, C.: Encoding ethics to compute value-aligned norms. Minds and Machines33(4), 761–790 (2023)
2023
-
[41]
Large Language Model Alignment: A Survey
Shen, T., Jin, R., Huang, Y., Liu, C., Dong, W., Guo, Z., Wu, X., Liu, Y., Xiong, D.: Large language model alignment: A survey. arXiv preprint arXiv:2309.15025 (2023)
-
[42]
Risk analysis20(3), 353–362 (2000)
Siegrist, M., Cvetkovich, G., Roth, C.: Salient value similarity, social trust, and risk/benefit perception. Risk analysis20(3), 353–362 (2000)
2000
-
[43]
Advances in Neural Information Processing Systems36, 2511– 2565 (2023)
Sun, Z., Shen, Y., Zhou, Q., Zhang, H., Chen, Z., Cox, D., Yang, Y., Gan, C.: Principle-driven self-alignment of language models from scratch with minimal hu- Towards Appropriate Trust with Certainty-Aware RAG XXI man supervision. Advances in Neural Information Processing Systems36, 2511– 2565 (2023)
2023
-
[44]
Revisiting Uncertainty Esti- mation and Calibration of Large Language Models
Tao,L.,Yeh,Y.F.,Dong,M.,Huang,T.,Torr,P.,Xu,C.:Revisitinguncertaintyes- timation and calibration of large language models. arXiv preprint arXiv:2505.23854 (2025)
-
[45]
https://www.trulens.org/getting_started/core_concepts/ rag_triad/ (2023), [Accessed 10-10-2025]
The RAG Triad. https://www.trulens.org/getting_started/core_concepts/ rag_triad/ (2023), [Accessed 10-10-2025]
2023
-
[46]
Philosophy & Technology34(4), 1607–1622 (2021)
Von Eschenbach, W.J.: Transparency and the black box problem: Why we do not trust AI. Philosophy & Technology34(4), 1607–1622 (2021)
2021
-
[47]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., Hooi, B.: Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs. arXiv preprint arXiv:2306.13063 (2023)
work page internal anchor Pith review arXiv 2023
-
[48]
International Journal of Human–Computer Interaction37(13), 1269–1282 (2021)
Yokoi, R., Nakayachi, K.: The effect of value similarity on trust in the automa- tion systems: A case of transportation and medical care. International Journal of Human–Computer Interaction37(13), 1269–1282 (2021)
2021
- [49]
-
[50]
In: CCF Conference on Big Data
Yu, H., Gan, A., Zhang, K., Tong, S., Liu, Q., Liu, Z.: Evaluation of retrieval- augmented generation: A survey. In: CCF Conference on Big Data. pp. 102–120. Springer (2024)
2024
-
[51]
Agieval: A human-centric benchmark for evaluating foundation models
Zhong, W., Cui, R., Guo, Y., Liang, Y., Lu, S., Wang, Y., Saied, A., Chen, W., Duan, N.: Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364 (2023)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.