Recognition: unknown
MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio
Pith reviewed 2026-05-09 18:11 UTC · model grok-4.3
The pith
MedMosaic benchmark shows even top multimodal models achieve only about 68% accuracy on diverse medical audio questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
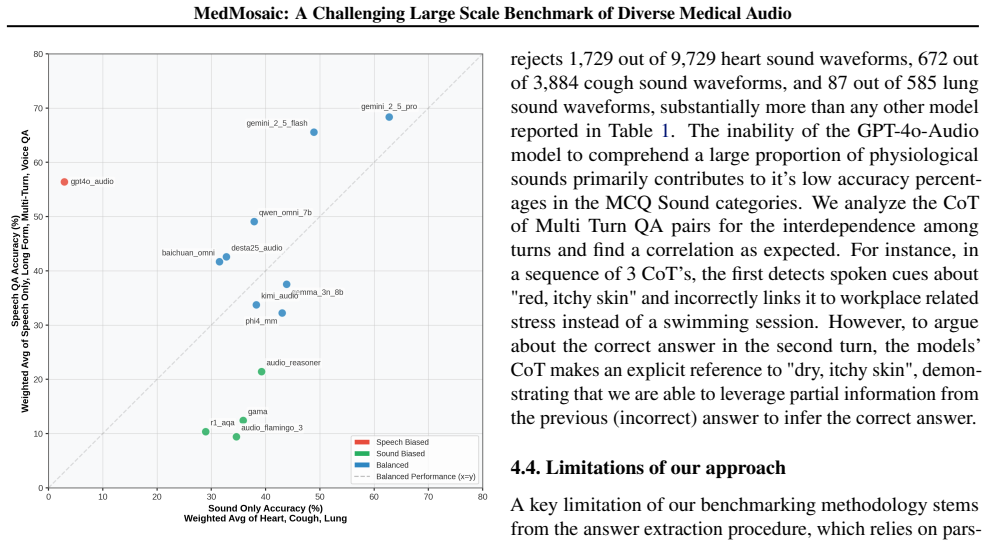
MedMosaic is a medical audio question-answering dataset that includes condition-related physiological sounds, synthetic voices constructed to mimic speech with artifacts, and real short and long clinical conversations. The dataset contains 46,701 question-answer pairs spanning multiple-choice, sequential multi-turn, and open-ended formats to support evaluation of multi-hop reasoning and answer generation. When 13 audio and multimodal models are tested on it, reasoning proves challenging across the board, with substantial variation by question type and the leading model achieving only approximately 68.1 percent accuracy.
What carries the argument
The MedMosaic dataset, which combines varied medical audio sources with structured question types to measure multimodal reasoning performance.
If this is right
- All evaluated models, including current state-of-the-art systems, exhibit clear limitations when processing medical audio with artifacts or extended context.
- Performance varies substantially by question format, with multi-turn and open-ended items exposing weaknesses not captured by simple multiple-choice tests.
- The results indicate that domain-specific improvements are required before multimodal models can reliably support clinical audio interpretation.
- Existing benchmarks underrepresent complex medical audio, so datasets like this one are needed to drive progress on privacy-constrained tasks.
Where Pith is reading between the lines
- Improved performance on MedMosaic could serve as a proxy signal for safer deployment of audio-based clinical assistants that review patient recordings.
- The benchmark's mix of synthetic and real audio may encourage development of training methods that bridge the gap between controlled data and actual clinical environments.
- Extending the dataset to additional medical specialties or languages would test whether the observed reasoning gaps are universal or domain-specific.
Load-bearing premise
The synthetic voices, constructed scenarios, and selected audio types accurately represent the complexities of real clinical medical audio.
What would settle it
Test the same 13 models on a held-out collection of real, anonymized clinical audio recordings and check whether accuracy and error patterns match those observed on MedMosaic.
Figures




read the original abstract
We present MedMosaic, a medical audio question-answering dataset designed to benchmark language and audio reasoning models under realistic clinical constraints. Medical audio data is difficult to collect due to privacy regulations and high annotation costs arising from domain expertise. Thus, existing benchmarks tend to underrepresent complex medical audio scenarios. To address these challenges, MedMosaic features a diverse range of medical audio types, including condition-related physiological sounds, carefully constructed synthetic voices to mimic speech with artifacts as well as real short and long length clinical conversations to model varying context lengths. The dataset also features a total of 46,701 question-answer pairs, spanning categories such as multiple-choice, sequential multi-turn, and open-ended question-answers, enabling systematic evaluation of multi-hop reasoning and answer generation capabilities. Benchmarking 13 audio and multimodal reasoning models reveals that reasoning remains challenging for all evaluated systems, with substantial performance variation across question types. In particular, even state-of-the-art model like Gemini-2.5-pro can only achieve 68.1% accuracy approximately. These findings underscore persistent limitations in medical reasoning and highlight the need for more robust, domain-specific multimodal reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedMosaic, a medical audio question-answering benchmark with 46,701 QA pairs spanning physiological sounds, synthetic voices constructed to include artifacts, and real short- and long-form clinical conversations. It evaluates 13 audio and multimodal models on multiple-choice, sequential multi-turn, and open-ended questions, reporting that even the strongest model (Gemini-2.5-pro) reaches only approximately 68.1% accuracy and that reasoning remains challenging across all systems.
Significance. If the synthetic and constructed components faithfully reproduce the acoustic, prosodic, and contextual statistics of real clinical audio, the benchmark would be a useful contribution for evaluating multimodal medical reasoning under privacy constraints. The scale and diversity of question types could help identify specific failure modes in current models.
major comments (3)
- [Dataset construction] Dataset construction (abstract and §3): the claim that synthetic voices and constructed scenarios accurately model real clinical audio is unsupported by any quantitative validation such as acoustic feature distribution comparisons, clinician realism ratings, or error analysis stratified by real vs. synthetic subsets. This directly undermines the interpretation that the observed performance gaps (e.g., Gemini-2.5-pro at ~68%) reflect general limitations in medical reasoning rather than artifacts of the proxy data.
- [Evaluation] Evaluation protocol (abstract and §4): no details are provided on model adaptation, audio preprocessing pipelines, prompting strategies for multi-turn or open-ended questions, or whether models received raw audio, transcripts, or both. Without these, the reported accuracies cannot be reproduced or compared fairly across the 13 systems.
- [Results] Results presentation (abstract and §5): the headline 68.1% figure for Gemini-2.5-pro is given only approximately, with no per-question-type breakdown, real-vs-synthetic split, or statistical significance tests. This weakens the claim of 'substantial performance variation across question types' and the overall conclusion that reasoning remains challenging.
minor comments (1)
- [Abstract] The abstract states 'approximately 68.1%' without an exact value or confidence interval; the main results section should report the precise number and any variance across runs.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve the clarity, reproducibility, and strength of our claims.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction (abstract and §3): the claim that synthetic voices and constructed scenarios accurately model real clinical audio is unsupported by any quantitative validation such as acoustic feature distribution comparisons, clinician realism ratings, or error analysis stratified by real vs. synthetic subsets. This directly undermines the interpretation that the observed performance gaps (e.g., Gemini-2.5-pro at ~68%) reflect general limitations in medical reasoning rather than artifacts of the proxy data.
Authors: We agree that the current version of the manuscript does not include the quantitative validations requested. Section 3 describes the construction methodology for synthetic voices (based on real clinical speech patterns with added artifacts) and scenario design, but no acoustic feature comparisons, clinician ratings, or stratified error analysis are reported. In the revised manuscript we will add available acoustic analyses (e.g., comparisons of MFCCs, pitch, and spectral characteristics between synthetic and real subsets) and a stratified performance breakdown by data source. We will also explicitly discuss the proxy nature of the data and its limitations under privacy constraints. Clinician realism ratings were not collected during dataset creation, so this will be noted as a limitation rather than added post hoc. revision: partial
-
Referee: [Evaluation] Evaluation protocol (abstract and §4): no details are provided on model adaptation, audio preprocessing pipelines, prompting strategies for multi-turn or open-ended questions, or whether models received raw audio, transcripts, or both. Without these, the reported accuracies cannot be reproduced or compared fairly across the 13 systems.
Authors: We acknowledge that the evaluation details in the current manuscript are insufficient for full reproducibility. We will substantially expand Section 4 to specify: (1) the audio preprocessing pipeline (resampling, normalization, and any segmentation steps), (2) model adaptation settings (zero-shot for all systems unless otherwise noted), (3) exact prompting templates and strategies for multi-turn sequential and open-ended questions, and (4) input modalities provided to each model (raw audio for audio-capable models, transcripts for text-only models, or both). These additions will enable direct reproduction and fair comparison across the 13 evaluated systems. revision: yes
-
Referee: [Results] Results presentation (abstract and §5): the headline 68.1% figure for Gemini-2.5-pro is given only approximately, with no per-question-type breakdown, real-vs-synthetic split, or statistical significance tests. This weakens the claim of 'substantial performance variation across question types' and the overall conclusion that reasoning remains challenging.
Authors: We agree that the results presentation can be strengthened with greater granularity and statistical rigor. In the revised manuscript we will: report the exact accuracy figure for Gemini-2.5-pro, add tables with per-question-type breakdowns (multiple-choice, multi-turn, open-ended), include real-versus-synthetic performance splits, and incorporate statistical significance tests (e.g., bootstrap confidence intervals or McNemar’s test) for key comparisons. These changes will better substantiate the claims of performance variation and persistent reasoning challenges. revision: yes
Circularity Check
No significant circularity in benchmark dataset creation and evaluation
full rationale
The paper constructs a new medical audio QA dataset (MedMosaic) with synthetic and real audio components and evaluates 13 existing models on it. No equations, parameters, or derivations are present that could reduce to self-defined inputs or fitted predictions. The core results are empirical performance numbers on the new benchmark, which do not rely on any self-citation chain or renaming of prior results as novel derivations. The work is self-contained as dataset introduction plus standard model benchmarking.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic voices and constructed scenarios can adequately mimic real clinical audio challenges while respecting privacy constraints.
Reference graph
Works this paper leans on
-
[1]
Accessed: 2025-01-28. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. InInternational Con- ference on Learning Representations, 2021. URL https: //openreview.net/forum?id=d7KBjmI3GmQ. Ju, X., Gao, Y ., Zhang, Z., Yuan, Z., Wang, X., Zeng, A., Xiong, Y ., Xu, Q., a...
-
[2]
URL https://doi.org/10.48550/arXiv.2505. 13032. Na0s. Primock_med. https://huggingface.co/ datasets/Na0s/Primock_med, 2024. Accessed: 2025- 01-28. Oliveira, J., Renna, F., Costa, P., Nogueira, M., Oliveira, A. C., Elola, A., Ferreira, C., Jorge, A., Bahrami Rad, A., Reyna, M., Sameni, R., Clifford, G., and Coimbra, M. The CirCor DigiScope Phonocardiogram ...
-
[3]
URL https://doi.org/10.48550/arXiv.2306. 12925. Sakshi, S., Tyagi, U., Kumar, S., Seth, A., Selvakumar, R., Nieto, O., Duraiswami, R., Ghosh, S., and Manocha, D. MMAU: A massive multi-task audio understanding and reasoning benchmark. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=TeVAZXr3yv...
-
[4]
URL https://doi.org/10.18653/v1/2023. findings-emnlp.1055. 12 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio A. Appendix A.1. Dataset Description • Primock57(Korfiatis et al., 2022): It consists of 57 long mock medical primary care consultations held over 5 days by 7 Babylon clinicians and 57 Babylon employees acting as patients, ...
-
[5]
Your considerations should come from *HEART SOUND* section
QUESTION DESIGN PRINCIPLE (STRICT) i. Your considerations should come from *HEART SOUND* section. ii. You may also consider the *SPECTRAL AND TEXTURAL QUALITIES* SECTION. iii. The questions should be waveform agnostic. No temporal or frequency characteristic should be given. iv. The questions MUST be relevant to a medical practitioner for prognosis. v. MU...
-
[6]
Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect
ANSWER OPTIONS DESIGN PRINCIPLE (STRICT) i. Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect. ii. All options should be grounded in medical reality. iii. Repeat words AGGRESSIVELY across options to obfuscate. Options MUST be confusing for medium and hard questions. iv. Each ...
-
[10]
If the audio does not support confident reasoning, return`None`
FAILURE MODE A. If the audio does not support confident reasoning, return`None`. SPECTRAL AND TEXTURAL QUALITIES SECTION:
-
[11]
Normal Heart Sounds (S1 and S2)
id: normal_heart_sounds label: "Normal Heart Sounds (S1 and S2)" 20 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio description: > Short-duration, high-energy, impulse-like sounds with broadband spectral content concentrated at low to mid frequencies. Sharp onsets with rapid decay and high temporal localization. S1 typically has sl...
-
[12]
Systolic Heart Murmur
id: systolic_murmur label: "Systolic Heart Murmur" description: > Sustained or semi-sustained noise-like or weakly tonal energy occurring between S1 and S2. Increased spectral bandwidth and reduced temporal sparsity relative to normal heart sounds, with intensity and duration tied to systolic phase rather than discrete impulses
-
[13]
Diastolic Heart Murmur
id: diastolic_murmur label: "Diastolic Heart Murmur" description: > Prolonged, low-amplitude noise-like or partially tonal energy occurring between S2 and the subsequent S1. Often lower dominant frequencies and smoother temporal envelopes, with persistence linked to diastolic filling or regurgitant flow
-
[14]
Continuous Murmur
id: continuous_murmur label: "Continuous Murmur" description: > Near-continuous acoustic energy spanning systolic and diastolic intervals with minimal silence between cycles. Sustained spectral density over time and weak impulse dominance compared to normal S1/S2 events
-
[15]
Third Heart Sound (S3)
id: third_heart_sound label: "Third Heart Sound (S3)" description: > Low-frequency, short-duration sound occurring shortly after S2. Soft onset, limited high-frequency content, dull texture, and low peak amplitude with minimal harmonic structure
-
[16]
Fourth Heart Sound (S4)
id: fourth_heart_sound label: "Fourth Heart Sound (S4)" description: > Brief, low-frequency sound occurring immediately before S1. Impulse-like but less sharp than S1, with muted high-frequency components and reduced transient energy
-
[17]
Ejection Click
id: ejection_click label: "Ejection Click" description: > Short, high-frequency transient occurring shortly after S1. Sharp onset, narrow temporal footprint, and prominent spectral peaks relative to surrounding heart sounds
-
[18]
Mid-Systolic Click
id: mid_systolic_click label: "Mid-Systolic Click" description: > Distinct, high-frequency, impulse-like sound occurring midway between S1 and S2. Strong temporal isolation, rapid decay, and higher dominant frequencies than S1 or S2
-
[19]
Opening Snap
id: opening_snap label: "Opening Snap" description: > Brief, high-frequency transient occurring shortly after S2. Sharp onset with concentrated mid-to-high frequency spectral energy and precise timing within the cardiac cycle. 21 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio
-
[20]
Pericardial Friction Rub
id: pericardial_friction_rub label: "Pericardial Friction Rub" description: > Rough, scratchy, non-stationary sound with irregular amplitude modulation. May include multiple short components within a single cardiac cycle and exhibits broadband, noise-like spectral content
-
[21]
Split Heart Sounds (Split S1 or S2)
id: split_heart_sounds label: "Split Heart Sounds (Split S1 or S2)" description: > Two closely spaced impulse-like sounds replacing a single heart sound. Each component retains impulse characteristics, with a short inter- component delay producing perceptible temporal separation without sustained noise-like energy. HEART SOUND SECTION:
-
[22]
Identification of repeating S1 S2 anchors by rhythm
-
[23]
Between S1 and S2 (systolic interval) ii
Murmur placement relative to S1 and S2 i. Between S1 and S2 (systolic interval) ii. Between S2 and next S1 (diastolic interval)
-
[24]
Continuous vs phase-limited murmurs
-
[25]
Regular vs irregular beat spacing (arrhythmia cues)
-
[26]
Additional low-frequency thuds (gallops) ii
Presence of extra sounds i. Additional low-frequency thuds (gallops) ii. Brief clicks vs sustained noise
-
[27]
difficulty
Beat-to-beat variability vs steady cadence FINAL NOTE Treat the audio as the sole source of truth. Do not hallucinate clinical context. Do not assume diagnosis unless directly inferable from sound structure. OUTPUT FORMAT (STRICTLY RETURN a single parseable JSON array of exactly 3 MCQ QA pairs (one easy, one medium, one hard) following the format below. N...
-
[28]
Your considerations should come from *RESPIRATORY SOUND*section
QUESTION DESIGN PRINCIPLE (STRICT) i. Your considerations should come from *RESPIRATORY SOUND*section. ii. You may also consider the *SPECTRAL AND TEXTURAL QUALITIES* SECTION. iii. The questions should be waveform agnostic. No temporal or frequency characteristic should be given. iv. The questions MUST be relevant to a medical practitioner for prognosis. ...
-
[29]
Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect
ANSWER OPTIONS DESIGN PRINCIPLE (STRICT) i. Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect. ii. All options should be grounded in medical reality. iii. Repeat words AGGRESIVELY across options to obfuscate. Options MUST be confusing for medium and hard questions. iv. Each o...
-
[33]
difficulty
FAILURE MODE 23 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio A. If the audio does not support confident reasoning, return`None`. SPECTRAL AND TEXTURAL QUALITIES SECTION: i. Stridor: high-pitched, harsh, monophonic sound with strong tonal dominance, typically continuous and prominent during airflow through the upper airway ii. Ap...
-
[34]
Your considerations should come from *COUGH SOUND* section
QUESTION DESIGN PRINCIPLE (STRICT) i. Your considerations should come from *COUGH SOUND* section. ii. You may also consider the *SPECTRAL AND TEXTURAL QUALITIES* SECTION. iii. The questions should be waveform agnostic. No temporal or frequency characteristic should be given. iv. The questions MUST be relevant to a medical practitioner for prognosis. v. MU...
-
[35]
Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect
ANSWER OPTIONS DESIGN PRINCIPLE (STRICT) i. Use your thought process to come up with close, contrastive options that are similar to the correct option but are still incorrect. ii. All options should be grounded in medical reality. iii. Repeat words AGGRESIVELY across options to obfuscate. Options MUST be confusing for medium and hard questions. iv. Each o...
-
[36]
Exactly ten options: (a), (b), (c), (d), (e), (f), (g), (h), (i), (j) B
MULTIPLE-CHOICE CONSTRAINTS A. Exactly ten options: (a), (b), (c), (d), (e), (f), (g), (h), (i), (j) B. One and only one correct answer C. Incorrect options must be: i. Clinically plausible ii. Acoustically confusable iii. Wrong only if the listener reasons carefully
-
[37]
Example attributes: i
DIFFICULTY PROGRESSION Frame easy, medium and hard questions on various attributes of input audio without limiting yourself to the enlisted examples. Example attributes: i. Single-signal perception ii. Temporal or rhythmic reasoning iii. Multi-signal or causal reasoning
-
[38]
The answer is (X)
ANSWER FORMAT (STRICT) A. Use exactly: "The answer is (X)."
-
[39]
difficulty
FAILURE MODE A. If the audio does not support confident reasoning, return`None`. SPECTRAL AND TEXTURAL QUALITIES SECTION: i. Wet cough: bubbling / gurgling overlay ii. Dry cough: sharp, abrupt, non-resonant iii. Pertussis cough: clustered, repetitive bursts with minimal pause, followed by a high-energy inspiratory intake ("whoop") and delayed recovery bre...
-
[40]
Depend on the SAME initial audio
-
[41]
Be asked in sequence
-
[42]
-------------------------------------------------- A
Use the ANSWER to the previous question as an implicit hint The audio is the ONLY source of truth. -------------------------------------------------- A. DIFFICULTY CALIBRATION -------------------------------------------------- 26 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio
-
[43]
Turn 1: MEDIUM difficulty ii
Question Difficulty Distribution i. Turn 1: MEDIUM difficulty ii. Turn 2: HARD difficulty - inquires about the correct answer from Turn 1 with added complexity iii. Turn 3: HARD difficulty - inquires about the correct answer from Turn1 and Turn 2 with added complexity
-
[44]
near-miss
Distractor Design Philosophy i. At least 4 distractors per question must be "near-miss" options that would be correct under slightly different audio conditions ii. Include at least 2 distractors that represent common misconceptions or pattern-matching errors iii. Distractors should exploit typical model failure modes: over-reliance on keyword matching, fa...
-
[45]
Frame Question 2 from your thought process while generating Question 1
Answer-Conditioned Progression i. Frame Question 2 from your thought process while generating Question 1. ii. Frame Question 3 from your thought process while generating Question 2. iii. If earlier answers are wrong, later questions should become ambiguous or misleading. iv. ERROR PROPAGATION DESIGN: Structure dependencies so that a wrong answer in Turn 1...
-
[46]
Do NOT repeat the previous answer explicitly in later questions
No Redundant Restatement i. Do NOT repeat the previous answer explicitly in later questions. ii. IMPLICIT REFERENCE ONLY: Reference prior answers through consequence or implication, never through direct restatement
-
[47]
Turn 2 and Turn 3 questions should be answerable ONLY if prior turns are answered correctly
Contextual Ambiguity Injection i. Turn 2 and Turn 3 questions should be answerable ONLY if prior turns are answered correctly. ii. Without prior context, at least 3 options should appear equally valid
-
[48]
audio_context
Rules for Referring to Information From Preceding Question i. In the succeeding question, you MUST refer to the correct answer of the previous question using identifiers such as'given this','from this','with this'etc. ii. Do not use the identifiers'above','previous','prior'etc. iii. OBFUSCATION RULE: The referent of'this'or'here'should require correct pri...
-
[49]
The correct answer must NOT be identifiable by length alone (vary option lengths randomly) ii
Prevent Surface Pattern Exploitation i. The correct answer must NOT be identifiable by length alone (vary option lengths randomly) ii. The correct answer must NOT be the most "hedged" or qualified option iii. The correct answer must NOT be identifiable by unique terminology
-
[50]
Questions must ask about features that CANNOT be inferred from medical knowledge alone ii
Require Genuine Audio Processing i. Questions must ask about features that CANNOT be inferred from medical knowledge alone ii. At least one question per chain must ask about paralinguistic features (tone, pace, hesitation) iii. At least one question must require distinguishing between acoustically similar but clinically different sounds ------------------...
-
[51]
Symptom and Clinical Reasoning i. Turn 1 identifies a symptom then Turn 2 links it to ONE of several possible causes (requiring exclusion reasoning) then Turn 3 assesses severity WITH consideration of confounding factors
-
[52]
Turn 1 issues an instruction then Turn 2 checks understanding via INDIRECT indicators then Turn 3 evaluates compliance through behavioral inference
Instruction, Compliance, and Behavior Tracking i. Turn 1 issues an instruction then Turn 2 checks understanding via INDIRECT indicators then Turn 3 evaluates compliance through behavioral inference
-
[53]
Turn 1 detects baseline tone then Turn 2 detects deviation that could indicate MULTIPLE emotional states then Turn 3 must select most acoustically consistent interpretation
Speech, Paralinguistic, and Nonverbal Reasoning iii. Turn 1 detects baseline tone then Turn 2 detects deviation that could indicate MULTIPLE emotional states then Turn 3 must select most acoustically consistent interpretation
-
[54]
Turn 1 makes a claim then Turn 2 detects SUBTLE rephrasing that may or may not constitute contradiction then Turn 3 must evaluate clinical significance
Temporal Consistency and Contradiction Resolution i. Turn 1 makes a claim then Turn 2 detects SUBTLE rephrasing that may or may not constitute contradiction then Turn 3 must evaluate clinical significance
-
[55]
Turn 1 identifies a symptom verbally then Turn 2 detects a physiological cue that could support MULTIPLE risk levels then Turn 3 must integrate with appropriate uncertainty
Multi-Signal Integration and Risk Reasoning i. Turn 1 identifies a symptom verbally then Turn 2 detects a physiological cue that could support MULTIPLE risk levels then Turn 3 must integrate with appropriate uncertainty. ii. Turn 1 notes baseline condition then Turn 2 detects paralinguistic change that could be clinically significant OR artifactual then T...
-
[56]
Giveaway
Avoid "Giveaway" Phrasing i. Do not use superlatives that signal the answer ("most importantly", "clearly", "obviously") iii. Questions should be answerable ONLY through audio evidence, not medical reasoning alone
-
[57]
What sound is heard?
Increase Inferential Distance i. Questions should require 2-3 inferential steps, not direct observation ii. Example: Instead of "What sound is heard?" ask "What condition is most consistent with the auscultatory findings given the temporal pattern?"
-
[58]
Options should differ on dimensions that require careful listening ii
Require Precise Discrimination i. Options should differ on dimensions that require careful listening ii. Include options that would be correct if a slightly different sound were heard iii. Include options that represent reasonable but incorrect interpretations of ambiguous features -------------------------------------------------- F. QUESTIONS ABOUT LATE...
-
[59]
turns": [ {
Latent Information Definition i. Questions in Turn 2 and Turn 3 MAY inquire about information that is IMPLIED from answer to Turn 1 question but NOT explicitly stated in the audio. ii. Example: Inferring emotional state from tone, detecting hesitation indicating uncertainty, or recognizing indirect references to symptoms. iii. In the succeeding question, ...
-
[60]
Do NOT explicitly state diagnoses
-
[61]
Do NOT reveal answers in later questions
-
[62]
Do NOT ask independent or parallel questions
-
[63]
VERIFY that Turn 3 is genuinely dependent on BOTH Turn 1 AND Turn 2 answers
-
[64]
-------------------------------------------------- I
VERIFY that distractors exploit realistic confusion patterns. -------------------------------------------------- I. NAME AND IDENTIFIER CONSTRAINT (DE-IDENTIFICATION) --------------------------------------------------
-
[65]
the patient
De-identification Requirement i. The question text, answer, and all options must be fully de-identified. ii. Do NOT include any personal names, honorifics, initials, or unique identifiers. iii. Do NOT reference specific clinicians, patients, locations, institutions, or dates. iv. Use only generic role references such as "the patient" and "the clinician". ...
-
[76]
LONG-RANGE DEPENDENCY REQUIREMENTS (MEDIUM & HARD ONLY) --------------------------------------------------
HARD: Requires information identification, correlation of evidence across conversation and extremely subtle conversational distinctions with all options appearing nearly identical -------------------------------------------------- B. LONG-RANGE DEPENDENCY REQUIREMENTS (MEDIUM & HARD ONLY) --------------------------------------------------
-
[77]
MUST require information from at least TWO segments that are meaningfully separated in the conversation ii
MEDIUM QUESTIONS i. MUST require information from at least TWO segments that are meaningfully separated in the conversation ii. Cannot be answered correctly by listening to any single contiguous portion iii. Should penalize models that only attend to conversation beginnings, endings, or salient moments
-
[78]
MUST require information from THREE OR MORE segments spread across the conversation ii
HARD QUESTIONS i. MUST require information from THREE OR MORE segments spread across the conversation ii. Should require tracking how information evolves, contradicts, or accumulates over the full dialogue iii. Must be unanswerable from any single 2-minute window of the conversation -------------------------------------------------- B. CRITICAL CONSTRAINT...
-
[82]
Options must differ in MULTIPLE conversational/clinical dimensions, not just synonym substitution ii
MULTI-DIMENSIONAL DIFFERENTIATION 33 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio i. Options must differ in MULTIPLE conversational/clinical dimensions, not just synonym substitution ii. Vary: information type, verbal detail, clinical implication, medical indicator iii. Each option must lead to a DIFFERENT clinical interpretatio...
-
[89]
Options with similar conversational descriptors must NOT be adjacent ii
OPTION ORDERING RULE: i. Options with similar conversational descriptors must NOT be adjacent ii. Shuffle option order so that similar options are scattered
-
[100]
CLINICAL-DIFFERENCE TEST: Each option leads to different clinical interpretation -------------------------------------------------- 34 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio G. FAILURE CONDITION -------------------------------------------------- If the conversation does NOT contain meaningful verbal evidence that could con...
-
[101]
the patient
De-identification Requirement i. The question text, answer, and all options must be fully de-identified ii. Do NOT include any personal names, honorifics, initials, or unique identifiers iii. Do NOT reference specific clinicians, patients, locations, institutions, or dates iv. Use only generic role references such as "the patient" and "the clinician" ----...
-
[102]
The conversation context (what was discussed, claimed, or described)
-
[103]
The acoustic evidence (vocal quality, breathing patterns, coughs, pauses, sighs, etc.) 35 MedMosaic: A Challenging Large Scale Benchmark of Diverse Medical Audio
-
[104]
The clinical interpretation (what the acoustic evidence reveals about the patient's true state) Each question must require the model to:
-
[105]
Listen to the actual audio (not just answering based on transcript)
-
[106]
Identify acoustic features that may contradict verbal claims
-
[107]
Integrate acoustic evidence with clinical reasoning to infer the correct answer
-
[108]
No temporal or frequency characteristic should be given
The questions should be waveform agnostic. No temporal or frequency characteristic should be given
-
[110]
EASY: Requires subtle acoustic feature identification with all options appearing similar
-
[111]
MEDIUM: Requires acoustic feature identification and correlation of acoustic evidence across conversation with all options appearing nearly identical
-
[112]
CRITICAL CONSTRAINTS --------------------------------------------------
HARD: Requires acoustic feature identification, correlation of acoustic evidence across conversation and extremely subtle acoustic distinctions with all options appearing nearly identical -------------------------------------------------- B. CRITICAL CONSTRAINTS --------------------------------------------------
-
[113]
fine" or
ANTI-HALLUCINATION PRINCIPLE i. If the patient verbally claims distress, anxiety, or severity, the CORRECT answer must describe the ACTUAL acoustic quality heard ii. If the patient claims to be "fine" or "stable," look for hidden acoustic distress markers iii. The model MUST base answers on what is HEARD, not what is SAID
-
[114]
MEDIUM and HARD questions MAY rely on information from different parts of the conversation ii
ACOUSTIC CORRELATION i. MEDIUM and HARD questions MAY rely on information from different parts of the conversation ii. For HARD questions, require correlation of acoustic evidence with dialogue content iii. Do NOT restate evidence in the question - require careful listening -------------------------------------------------- C. OPTION FORMAT REQUIREMENTS (...
-
[115]
Each option MUST be 6-12 words minimum ii
OPTION LENGTH AND STRUCTURE i. Each option MUST be 6-12 words minimum ii. Each option MUST follow structure: [acoustic observation] + [clinical qualifier/context] iii. DO NOT use single-word or two-word descriptors - expand to full descriptions
-
[116]
Options must differ in MULTIPLE acoustic/clinical dimensions, not just synonym substitution ii
MULTI-DIMENSIONAL DIFFERENTIATION i. Options must differ in MULTIPLE acoustic/clinical dimensions, not just synonym substitution ii. Vary: sound type, acoustic quality, clinical implication, physiological indicator iii. Each option must lead to a DIFFERENT clinical interpretation or prognosis
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.