Recognition: unknown
Value Functions for Temporal Logic: Optimal Policies and Safety Filters
Pith reviewed 2026-05-09 18:32 UTC · model grok-4.3
The pith
Non-Markovian policies based on state history achieve optimality for temporal logic specifications where greedy Q-function maximization fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper constructs non-Markovian policies based on state history that avoid the pathology of indefinitely deferring task completion and proves their optimality with respect to the quantitative robustness score for nested Until, Globally, and Globally-Until specifications. It further demonstrates the use of the Q-function as a safety filter for complex temporal logic specifications.
What carries the argument
The graph decomposition of the temporal logic value function into constituent value functions, which supports construction of history-based non-Markovian policies.
Load-bearing premise
The decomposition of the temporal logic value function into a graph of constituent value functions holds and correctly captures the quantitative robustness semantics for the targeted specification classes.
What would settle it
An experiment on a nested Until specification where the history-based policy's achieved robustness score is lower than the optimal value function, or where the policy still defers task completion indefinitely.
Figures


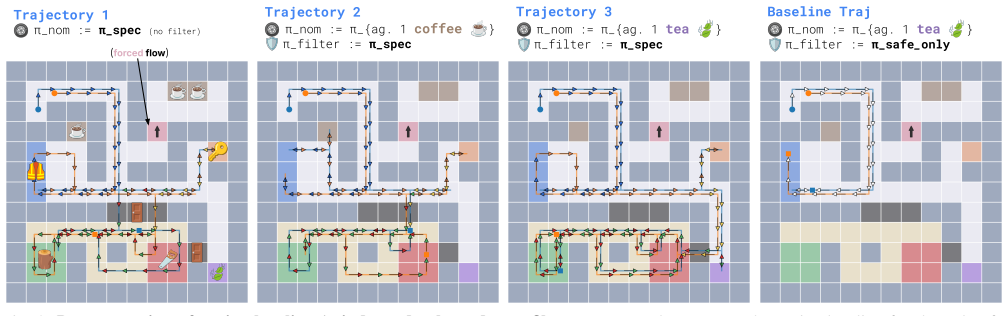
read the original abstract
While Bellman equations for basic reach, avoid, and reach-avoid problems are well studied, the relationship between value optimality and policy optimality becomes subtle in the undiscounted infinite-horizon setting, particularly for more complicated tasks. Greedily maximizing the Q-function can produce policies that indefinitely defer task completion for reach-avoid problems, or equivalently, Until specifications, even when the value function is optimal. Building upon recent results decomposing the value function for temporal logic (TL) into a graph of constituent value functions, we construct non-Markovian policies based on state history that avoid this pathology and prove their optimality with respect to the quantitative robustness score for nested Until, Globally, and Globally-Until specifications. We further show how the Q function can serve as a safety filter for complex TL specifications, extending prior results beyond simple avoid or reach-avoid tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that while Bellman equations for basic reach, avoid, and reach-avoid problems are well studied, the relationship between value optimality and policy optimality becomes subtle in the undiscounted infinite-horizon setting for temporal logic tasks. Greedy Q-maximization can produce policies that indefinitely defer task completion for Until specifications. Building upon recent results decomposing the value function for temporal logic into a graph of constituent value functions, the authors construct non-Markovian policies based on state history that avoid this pathology and prove their optimality with respect to the quantitative robustness score for nested Until, Globally, and Globally-Until specifications. They further show how the Q function can serve as a safety filter for complex TL specifications, extending prior results.
Significance. If the optimality proofs and constructions hold, this work is a solid contribution to safe and optimal control under temporal logic specifications in robotics. It resolves a known pathology where optimal value functions do not yield optimal greedy policies in undiscounted settings, supplies explicit history-dependent policy constructions with independent proofs for key specification classes, and extends safety-filter techniques beyond basic reach-avoid tasks. These elements provide both theoretical clarity and practical tools for TL-based planning.
minor comments (3)
- The abstract could briefly note the specific specification classes (nested Until, Globally, Globally-Until) for which optimality is proved, to set expectations immediately.
- In the section introducing the history-dependent policy construction, ensure all symbols and history variables are defined before their first use in equations.
- Adding a small worked example (even a simple 1D system) illustrating the deferral pathology under greedy maximization and its resolution by the non-Markovian policy would improve intuition for the central claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper, recognition of its contributions to resolving the value-policy optimality gap for temporal logic tasks, and recommendation for minor revision. No specific major comments were provided in the report, so we have prepared the revised manuscript accordingly.
Circularity Check
No significant circularity; prior decomposition imported but new policy constructions and proofs are independent
full rationale
The manuscript imports a decomposition of the temporal logic value function into a graph of constituent value functions from recent prior results, then supplies independent constructions of history-dependent non-Markovian policies together with explicit optimality proofs for nested Until, Globally, and Globally-Until specifications. These proofs address the specific pathology of greedy Q-maximization and extend the Q-function to safety filters. No step reduces by definition to its own inputs, no fitted parameter is relabeled as a prediction, and the imported decomposition is not load-bearing for the new claims; the central argument remains self-contained once the prior decomposition is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Value functions for temporal logic specifications can be decomposed into a graph of constituent value functions.
Reference graph
Works this paper leans on
-
[1]
A time- dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games,
I. M. Mitchell, A. M. Bayen, and C. J. Tomlin, “A time- dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games,”IEEE Transac- tions on Automatic Control, 2005. [Online]. Available: https : / / doi . org / 10 . 1109 / TAC . 2005 . 851439
2005
-
[2]
and Chen, Mo and Tomlin, Claire J
J. F. Fisac, M. Chen, C. J. Tomlin, and S. S. Sastry, “Reach-avoid problems with time-varying dynamics, tar- gets and constraints,” inHybrid Systems: Computation and Control, ACM, 2015. [Online]. Available: https: //doi.org/10.1145/2728606.2728612
-
[3]
Bridging hamilton-jacobi safety analysis and reinforcement learning,
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin, “Bridging hamilton-jacobi safety analysis and reinforcement learning,” inIEEE Interna- tional Conference on Robotics and Automation, 2019. [Online]. Available: https : / / doi . org / 10 . 1109/ICRA.2019.8794107
-
[4]
Safety and liveness guarantees through reach- avoid reinforcement learning,
K.-C. Hsu, V . Rubies-Royo, C. J. Tomlin, and J. F. Fisac, “Safety and liveness guarantees through reach- avoid reinforcement learning,” inProceedings of Robotics: Science and Systems, 2021. [Online]. Avail- able: https : / / doi . org / 10 . 15607 / RSS . 2021.XVII.077
2021
-
[5]
Learning stabilization control from observations by learning lyapunov-like proxy models,
M. Ganai, C. Hirayama, Y . -C. Chang, and S. Gao, “Learning stabilization control from observations by learning lyapunov-like proxy models,” inIEEE In- ternational Conference on Robotics and Automation,
-
[6]
2023 IEEE International Conference on Robotics and Automation (ICRA) , volume =
[Online]. Available: https://doi.org/10. 1109/ICRA48891.2023.10160928
-
[7]
Solving minimum-cost reach avoid using reinforcement learning,
O. So, C. Ge, and C. Fan, “Solving minimum-cost reach avoid using reinforcement learning,” inAdvances in Neural Information Processing Systems, 2024. [On- line]. Available: https : / / openreview . net / forum?id=jzngdJQ2lY
2024
-
[8]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” inIEEE Conference on Decision and Control, 2017. [Online]. Available: https://doi. org/10.1109/CDC.2017.8263977
-
[9]
The temporal logic of programs,
A. Pnueli, “The temporal logic of programs,” inAnnual Symposium on Foundations of Computer Science, IEEE,
-
[10]
Available:https://doi.org/10
[Online]. Available:https://doi.org/10. 1109/SFCS.1977.32
1977
-
[11]
Robust satisfaction of temporal logic over real-valued signals,
A. Donzé and O. Maler, “Robust satisfaction of temporal logic over real-valued signals,” inFormal Modeling and Analysis of Timed Systems, 2010. [On- 8 line]. Available: https://doi.org/10.1007/ 978-3-642-15297-9_9
2010
-
[12]
Robustness of temporal logic specifications for continuous-time sig- nals,
G. E. Fainekos and G. J. Pappas, “Robustness of temporal logic specifications for continuous-time sig- nals,”Theoretical Computer Science, 2009. [Online]. Available: https://doi.org/10.1016/j.tcs. 2009.06.021
-
[13]
LTL and beyond: Formal languages for reward function specification in rein- forcement learning,
A. Camacho, R. Toro Icarte, T. Q. Klassen, R. Valen- zano, and S. A. McIlraith, “LTL and beyond: Formal languages for reward function specification in rein- forcement learning,” inInternational Joint Conference on Artificial Intelligence, 2019. [Online]. Available: https://doi.org/10.24963/ijcai.2019/ 840
-
[14]
M. Chen, Q. Tam, S. C. Livingston, and M. Pavone, “Signal temporal logic meets reachability: Connections and applications,” inWorkshop on the Algorithmic Foundations of Robotics, Springer, 2018. [Online]. Available: https://doi.org/10.1007/978- 3-030-44051-0_34
-
[15]
Dual-objective reinforcement learning with novel hamilton-jacobi-bellman formulations,
W. Sharpless, D. Hirsch, S. Tonkens, N. Shinde, and S. Herbert, “Dual-objective reinforcement learning with novel hamilton-jacobi-bellman formulations,” in International Conference on Learning Representations,
-
[16]
Available: https://openreview
[Online]. Available: https://openreview. net/forum?id=1SdPgRQrr5
-
[17]
Bellman value decomposition for task logic in safe optimal control,
W. Sharpless, O. So, D. Hirsch, S. Herbert, and C. Fan, “Bellman value decomposition for task logic in safe optimal control,” inProceedings of Robotics: Science and Systems, 2026. [Online]. Available: https:// arxiv.org/abs/2602.19532
-
[18]
Baier and J
C. Baier and J. -P. Katoen,Principles of Model Check- ing. MIT press, 2008. [Online]. Available: https: / / mitpress . mit . edu / 9780262026499 / principles-of-model-checking/
2008
-
[19]
Monitoring temporal properties of continuous signals,
O. Maler and D. Nickovic, “Monitoring temporal properties of continuous signals,” inFormal Techniques, Modelling and Analysis of Timed and Fault-Tolerant Systems, 2004. [Online]. Available: https://doi. org/10.1007/978-3-540-30206-3_12
-
[20]
M. L. Puterman,Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons,
-
[21]
Available: https://doi.org/10
[Online]. Available: https://doi.org/10. 1002/9780470316887
-
[22]
Solving reach-and stabilize-avoid problems using discounted reachability,
B. Li, Z. Gong, and S. Herbert, “Solving reach-and stabilize-avoid problems using discounted reachability,” arXiv preprint, 2025. [Online]. Available: https : //arxiv.org/abs/2505.09067
-
[23]
Real-time logics: Complexity and expressiveness,
R. Alur and T. A. Henzinger, “Real-time logics: Complexity and expressiveness,”Information and Com- putation, 1993. [Online]. Available: https://doi. org/10.1006/inco.1993.1025
-
[24]
An automata-theoretic approach to automatic program verification,
M. Y . Vardi and P. Wolper, “An automata-theoretic approach to automatic program verification,” inIEEE Symposium on Logic in Computer Science, 1986. [On- line]. Available: https://lics.siglog.org/ 1986/VardiWolper-AnAutomataTheoretic. html
1986
-
[25]
The safety filter: A unified view of safety-critical control in autonomous systems,
K.-C. Hsu, H. Hu, and J. F. Fisac, “The safety filter: A unified view of safety-critical control in autonomous systems,”Annual Review of Control, Robotics, and Au- tonomous Systems, 2023. [Online]. Available: https: / / doi . org / 10 . 1146 / annurev - control - 071723-102940 9
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.