Recognition: unknown
MG-Former: A Transformer-Based Framework for Music-Driven 3D Conducting Gesture Generation
Pith reviewed 2026-05-10 15:31 UTC · model grok-4.3
The pith
A Transformer framework generates 3D conducting gestures from music while maintaining beat synchronization and long-range musical structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
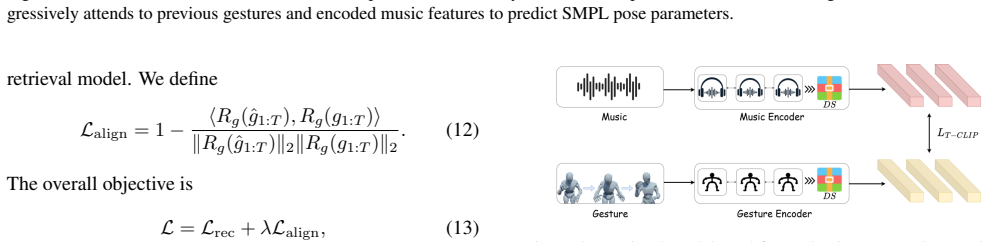
TransConductor is a Transformer-based framework for music-driven 3D conducting gesture generation that uses a Trans-Temporal Music Encoder and a Trans-Temporal Conducting Gesture Decoder to autoregressively predict SMPL pose parameters from audio descriptors and an initial pose. The system is supported by the ConductorMotion dataset built from conducting videos and evaluated with a new retrieval-based model that measures music-gesture alignment through shared embeddings, yielding metrics including FID, modality distance, multi-modality distance, and diversity. Experiments demonstrate that it outperforms dance-generation and conducting-generation baselines, with ablations confirming the value
What carries the argument
The Trans-Temporal Music Encoder paired with the Trans-Temporal Conducting Gesture Decoder, which together handle temporal dependencies to enforce long-range musical structure and beat-level synchronization in the generated SMPL poses.
If this is right
- Outperforms existing dance and conducting generation methods on standard and custom metrics.
- Benefits from the Transformer architecture for handling sequence data in motion synthesis.
- The alignment loss improves music-gesture correspondence.
- The ConductorMotion dataset provides a targeted resource for professional conducting gesture research.
Where Pith is reading between the lines
- Similar Transformer designs could extend to other music-driven body motions like dance or instrument playing.
- Integration into virtual reality systems might enable real-time conducting avatars for remote performances.
- Testing on diverse music genres could reveal limitations in generalization beyond the training data.
Load-bearing premise
The retrieval-based evaluation model that embeds music and gestures into a shared space accurately measures artistic correspondence and synchronization beyond what standard metrics capture.
What would settle it
A controlled user study with conducting experts comparing the synchronization and expressiveness of TransConductor outputs against baselines on unseen music pieces; failure would occur if no significant preference or alignment difference is found.
Figures





read the original abstract
Generating expressive conducting gestures from music is a challenging cross-modal motion synthesis problem: the output must follow long-range musical structure, preserve beat-level synchronization, and remain plausible as a fine-grained 3D human performance. Existing conducting-motion studies are often limited by sparse pose representations, small-scale data, or evaluation protocols that do not directly measure whether music and gesture are mutually aligned. This paper presents TransConductor, a Transformer-based framework for music-driven conducting gesture generation. We introduce ConductorMotion, a SMPL-parameter data construction pipeline that recovers detailed body motion from conducting videos and forms a dataset targeted at professional conducting gestures. Given acoustic descriptors extracted from audio and an initial pose, TransConductor uses a Trans-Temporal Music Encoder and a Trans-Temporal Conducting Gesture Decoder to autoregressively predict SMPL pose parameters. To better assess artistic correspondence, we further build a retrieval-based evaluation model that embeds music and gestures into a shared space and yields FID, modality distance, multi-modality distance, and diversity metrics. Experiments show that TransConductor outperforms dance-generation and conducting-generation baselines, while ablations verify the benefits of the Transformer backbone and the proposed alignment loss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TransConductor, a Transformer-based autoregressive framework for music-driven 3D conducting gesture generation using SMPL pose parameters. It presents the ConductorMotion dataset constructed via a pipeline that recovers detailed body motion from conducting videos. The model employs a Trans-Temporal Music Encoder and Trans-Temporal Conducting Gesture Decoder. To evaluate artistic correspondence and synchronization, the authors propose a retrieval-based model that embeds music and gestures into a shared space, from which they derive FID, modality distance, multi-modality distance, and diversity metrics. Experiments claim outperformance over dance-generation and conducting-generation baselines, with ablations supporting the Transformer backbone and proposed alignment loss.
Significance. If the central empirical claims hold and the retrieval-based evaluation is shown to reliably capture artistic correspondence beyond dataset biases, the work would advance cross-modal motion synthesis by targeting the specialized domain of conducting gestures with long-range structure and beat-level synchronization. The ConductorMotion dataset and SMPL-parameter pipeline constitute a concrete, reusable contribution for future research in fine-grained 3D human performance generation.
major comments (1)
- [Experiments] Experiments section: The outperformance claims rest entirely on FID, modality distance, multi-modality distance, and diversity metrics produced by the custom retrieval-based evaluation model that embeds music and gestures into a shared space. The manuscript provides no validation that this embedding ranks plausible conducting pairs higher than implausible ones, reports no retrieval accuracy on held-out pairs, and shows no correlation with human expert ratings of musicality or synchronization. Without such evidence, the metrics may simply reflect the alignment loss or dataset artifacts rather than genuine improvement in conducting quality.
minor comments (2)
- [Title and Abstract] The abstract refers to the proposed framework as TransConductor while the title uses MG-Former; the relationship between these names should be clarified for consistency.
- [Abstract] The abstract states that experiments show outperformance and ablation benefits but supplies no numerical values, data-split details, or error analysis; including at least summary statistics would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation approach. We address the concern regarding validation of the retrieval-based metrics below and will incorporate additional supporting analyses in the revised manuscript.
read point-by-point responses
-
Referee: The outperformance claims rest entirely on FID, modality distance, multi-modality distance, and diversity metrics produced by the custom retrieval-based evaluation model that embeds music and gestures into a shared space. The manuscript provides no validation that this embedding ranks plausible conducting pairs higher than implausible ones, reports no retrieval accuracy on held-out pairs, and shows no correlation with human expert ratings of musicality or synchronization. Without such evidence, the metrics may simply reflect the alignment loss or dataset artifacts rather than genuine improvement in conducting quality.
Authors: We appreciate the referee raising this critical point about metric validation. The retrieval-based evaluation model is trained independently using a contrastive loss on paired music-gesture samples from ConductorMotion to learn a shared embedding space, with the FID and distance metrics derived from distances in this space. While the original manuscript does not report explicit retrieval accuracy (such as top-k recall on held-out matching vs. negative pairs) or correlation with human ratings, we agree these would strengthen the claims. In the revision we will add retrieval accuracy results on a held-out test split to demonstrate that the embedding prioritizes plausible pairs. We acknowledge that a new human expert study correlating metrics with ratings of musicality and synchronization is not present and would require additional data collection; we will therefore note this as a limitation and future direction rather than claiming such correlation. These additions should help confirm that improvements are not solely due to the alignment loss or dataset biases. revision: partial
Circularity Check
No circularity in derivation chain; empirical claims are self-contained
full rationale
The manuscript presents an empirical ML framework (TransConductor) with a Transformer encoder-decoder, a new dataset pipeline, an alignment loss, and a separate retrieval-based evaluation model that produces standard metrics (FID, modality distances, diversity). No equations, derivations, or parameter-fitting steps are described that reduce by construction to the model's own outputs or inputs. The outperformance claims rest on comparisons against baselines and ablations, which are externally falsifiable and do not invoke self-citation chains or self-definitional loops. The evaluation embedding is introduced as an additional tool rather than a fitted component whose results are then renamed as predictions.
Axiom & Free-Parameter Ledger
invented entities (2)
-
TransConductor framework
no independent evidence
-
ConductorMotion dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lan- guage2pose: Natural language grounded pose forecasting
Chaitanya Ahuja and Louis-Philippe Morency. Lan- guage2pose: Natural language grounded pose forecasting. In Proceedings of the International Conference on 3D Vision, pages 719–728, 2019
2019
-
[2]
Groovenet: Real-time music-driven dance movement gen- eration using artificial neural networks
Omid Alemi, Jules Franc ¸oise, and Philippe Pasquier. Groovenet: Real-time music-driven dance movement gen- eration using artificial neural networks. InProceedings of the International Conference on Computational Creativity, 2017
2017
-
[3]
Style-controllable speech-driven gesture synthesis using normalising flows.Computer Graphics Fo- rum, 39(2):487–496, 2020
Simon Alexanderson, Gustav Eje Henter, Taras Kucherenko, and Jonas Beskow. Style-controllable speech-driven gesture synthesis using normalising flows.Computer Graphics Fo- rum, 39(2):487–496, 2020
2020
-
[4]
Gesturediffuclip: Gesture diffusion model with clip latents
Tenglong Ao, Zeyi Zhang, and Libin Liu. Gesturediffuclip: Gesture diffusion model with clip latents. InACM Transac- tions on Graphics, pages 1–18, 2023
2023
-
[5]
Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and ges- ture generation
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, and Qifeng Chen. Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and ges- ture generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7352– 7361, 2024
2024
-
[6]
Black, and Timo Bolkart
Kiran Chhatre, Nikos Athanasiou, Michael J. Black, and Timo Bolkart. Amuse: Emotional speech-driven 3d body an- imation via disentangled latent diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19398–19408, 2024
2024
-
[7]
Learning individual styles of conversational gesture
Shiry Ginosar, Amir Bar, Gefen Kohavi, Caroline Chan, An- drew Owens, and Jitendra Malik. Learning individual styles of conversational gesture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3497–3506, 2019
2019
-
[8]
Kehong Gong, Dongze Lian, Heng Chang, Chuan Guo, Zi- hang Jiang, Xinxin Zuo, Xun Wang, and Michael K. Cheng. Tm2d: Bimodality driven 3d dance generation via music-text integration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9942–9952, 2023
2023
-
[9]
Choreography cgan: Gen- erating dances with music beats using conditional generative adversarial networks.Neural Computing and Applications, 33:9817–9833, 2021
Ya-Fan Huang and Wei-De Liu. Choreography cgan: Gen- erating dances with music beats using conditional generative adversarial networks.Neural Computing and Applications, 33:9817–9833, 2021
2021
-
[10]
BiTDiff: Fine-Grained 3D Conducting Motion Generation via BiMamba-Transformer Diffusion
Tianzhi Jia, Kaixing Yang, Xiaole Yang, Xulong Tang, Ke Qiu, Shikui Wei, and Yao Zhao. Bitdiff: Fine-grained 3d conducting motion generation via bimamba-transformer dif- fusion.arXiv preprint arXiv:2604.04395, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Gesticulator: A framework for semantically-aware speech-driven gesture generation
Taras Kucherenko, Patrik Jonell, Sanne van Waveren, Gustav Eje Henter, Simon Alexanderson, Iolanda Leite, and Hedvig Kjellstr ¨om. Gesticulator: A framework for semantically-aware speech-driven gesture generation. In Proceedings of the International Conference on Multimodal Interaction, pages 242–250, 2020
2020
-
[12]
Tran, and Anh Nguyen
Nhat Le, Tu Do, Kien Do, Hoang Nguyen, Erman Tjiputra, Quang D. Tran, and Anh Nguyen. Controllable group chore- ography using contrastive diffusion.ACM Transactions on Graphics, 42(6):1–14, 2023
2023
-
[13]
Tran, and Anh Nguyen
Nhat Le, Thang Pham, Tu Do, Erman Tjiputra, Quang D. Tran, and Anh Nguyen. Music-driven group choreography. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8673–8682, 2023
2023
-
[14]
Dance- former: Music conditioned 3d dance generation with para- metric motion transformer
Buyu Li, Yongchi Zhao, Shi Zhelun, and Lu Sheng. Dance- former: Music conditioned 3d dance generation with para- metric motion transformer. InProceedings of the AAAI Con- ference on Artificial Intelligence, 2022
2022
-
[15]
Ross, and Angjoo Kanazawa
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. Ai choreographer: Music conditioned 3d dance generation with aist++. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 13401– 13412, 2021
2021
-
[16]
Finedance: A fine-grained choreography dataset for 3d full body dance generation
Ronghui Li, Jun Zhao, Yachao Zhang, Mingyang Su, Zhizheng Ren, Han Zhang, Yuhang Zhang, Yebin Liu, and Xiu Li. Finedance: A fine-grained choreography dataset for 3d full body dance generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10234–10243, 2023
2023
-
[17]
Ronghui Li, Han Zhang, Yachao Zhang, Yuhang Zhang, Jia- man Guo, and Yebin Liu. Lodge++: High-quality and long dance generation with vivid choreography patterns.arXiv preprint arXiv:2410.20389, 2024
-
[18]
Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives
Ronghui Li, Yachao Zhang, Yuhang Zhang, Han Zhang, Jia- man Guo, Yuxuan Zhang, and Xiu Li. Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1524–1534, 2024
2024
-
[19]
Exploring multi-modal control in music-driven dance generation.arXiv preprint arXiv:2401.01382, 2024
Ronghui Li, Yachao Zhang, Yuhang Zhang, Han Zhang, Zhizheng Ren, Jiaman Guo, Yebin Liu, and Xiu Li. Explor- ing multi-modal control in music-driven dance generation. arXiv preprint arXiv:2401.01382, 2024
-
[20]
Ronghui Li, Yachao Zhang, Yuhang Zhang, Han Zhang, Jia- man Guo, and Yebin Liu. Soulnet: Music-aligned holistic 3d dance generation via hierarchical motion modeling.arXiv preprint arXiv:2502.20154, 2025
-
[21]
Self-supervised music motion synchronization learning for music-driven conducting motion generation
Fang Liu, Donglin Chen, Ruizhi Zhou, Sheng Yang, and Feng Xu. Self-supervised music motion synchronization learning for music-driven conducting motion generation. Journal of Computer Science and Technology, 37(3):539– 558, 2022
2022
-
[22]
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Eren Bozkurt, Bo Zheng, and Michael J. Black. Beat: A large-scale semantic and emo- tional multi-modal dataset for conversational gestures syn- thesis. InProceedings of the European Conference on Com- puter Vision, pages 612–630, 2022
2022
-
[23]
Xia Liu, Ronghui Li, Han Zhang, Yuhang Zhang, Yachao Zhang, Zehua Hu, Jiaman Guo, and Yebin Liu. Dgfm: Full body dance generation driven by music foundation model. arXiv preprint arXiv:2505.12202, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. Smpl: A skinned multi- person linear model.ACM Transactions on Graphics, 34(6): 248:1–248:16, 2015
2015
-
[25]
Brian McFee, Colin Raffel, Dawen Liang, Daniel P. W. Ellis, Matt McVicar, Eric Battenberg, and Oriol Nieto. Librosa: Audio and music signal analysis in python. InProceedings of the 14th Python in Science Conference, pages 18–24, 2015
2015
-
[26]
A transfer learn- ing approach for music-driven 3d conducting motion genera- tion with limited data
Jisoo Oh, Jinwoo Jeong, and Youngho Chai. A transfer learn- ing approach for music-driven 3d conducting motion genera- tion with limited data. InProceedings of the 30th ACM Sym- posium on Virtual Reality Software and Technology, 2024
2024
-
[27]
Music-driven dance generation.IEEE Access, 7:166540–166550, 2019
Yuan Qi, Yixing Liu, and Qiong Sun. Music-driven dance generation.IEEE Access, 7:166540–166550, 2019
2019
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763, 2021
2021
-
[29]
Self-supervised dance video synthesis conditioned on music
Xuanchi Ren, Haoran Li, Zhaoxiang Huang, and Qifeng Chen. Self-supervised dance video synthesis conditioned on music. InProceedings of the 28th ACM International Con- ference on Multimedia, pages 46–54, 2020
2020
-
[30]
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J. Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2070– 2080, 2024
2070
-
[31]
Bailando: 3d dance generation by actor-critic gpt with choreographic memory
Li Siyao, Weiji Yu, Tingting Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050– 11059, 2022
2022
-
[32]
Bailando++: 3d dance gpt with choreographic memory.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2023
Li Siyao, Weiji Yu, Tingting Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando++: 3d dance gpt with choreographic memory.IEEE Transac- tions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[33]
Kankanhalli, Weidong Geng, and Xiang Li
Guofei Sun, Yew-Soon Wong, Zhiyong Cheng, Mohan S. Kankanhalli, Weidong Geng, and Xiang Li. Deepdance: Music-to-dance motion choreography with adversarial learn- ing.IEEE Transactions on Multimedia, 23:497–509, 2021
2021
-
[34]
Dance with melody: An lstm-autoencoder approach to music-oriented dance syn- thesis
Taoran Tang, Jia Jia, and Hanyang Mao. Dance with melody: An lstm-autoencoder approach to music-oriented dance syn- thesis. InProceedings of the 26th ACM International Con- ference on Multimedia, pages 1598–1606, 2018
2018
-
[35]
Karen Liu
Jonathan Tseng, Rodrigo Castellon, and C. Karen Liu. Edge: Editable dance generation from music. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 448–458, 2023
2023
-
[36]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[37]
Codancers: Music-driven coherent group dance generation with choreographic unit
Kanglei Yang, Xinyu Tang, Ruixuan Diao, Hong Liu, Jun He, and Zhi Fan. Codancers: Music-driven coherent group dance generation with choreographic unit. InProceedings of the 2024 International Conference on Multimedia Retrieval, pages 675–683, 2024
2024
-
[38]
Megadance: Mixture-of- experts architecture for genre-aware 3d dance generation
Kaixing Yang, Tianyu Zhang, Yuzhuo Li, Tianyun Zhang, Guangyu Xu, Xulong Tang, Li Yang, Jian Yang, Shenghai Dai, Tao Wang, Zhigang Wu, and Ke Qiu. Megadance: Music-driven 3d dance generation with motion-aware mix- ture of experts.arXiv preprint arXiv:2505.17543, 2025
-
[39]
Kaixing Yang, Tianyu Zhang, Xulong Tang, Yuzhuo Li, Li Yang, Jian Yang, Shenghai Dai, Tao Wang, Zhigang Wu, and Ke Qiu. Flowerdance: Music-driven 3d dance gener- ation with efficient refined flow matching.arXiv preprint arXiv:2511.21029, 2025
-
[40]
Cohedancers: Music-driven coherent group dance generation
Kaixing Yang, Tianyu Zhang, Yujie Zhao, Chenjing Cai, Zeyu Zhao, Xulong Tang, Li Yang, Jian Yang, Ke Qiu, Shenghai Dai, Jinfeng Dong, Tao Wang, Zhigang Wu, and Meng Wang. Cohedancers: Music-driven coherent group dance generation. InProceedings of the ACM International Conference on Multimedia, pages 6663–6671, 2025
2025
-
[41]
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Kaixing Yang, Jiashu Zhu, Xulong Tang, Ziqiao Peng, Xi- angyue Zhang, Puwei Wang, Jiahong Wu, Xiangxiang Chu, Hongyan Liu, and Jun He. Mace-dance: Motion-appearance cascaded experts for music-driven dance video generation. arXiv preprint arXiv:2512.18181, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Diffus- estylegesture: Stylized audio-driven co-speech gesture gen- eration with diffusion models
Sicheng Yang, Zhiyong Wu, Minglei Li, Zhensong Zhang, Lei Hao, Weihong Bao, Ming Cheng, and Jun Xiao. Diffus- estylegesture: Stylized audio-driven co-speech gesture gen- eration with diffusion models. InProceedings of the Thirty- Second International Joint Conference on Artificial Intelli- gence, pages 5860–5868, 2023
2023
-
[43]
Ziyue Yang, Kaixing Yang, Xulong Tang, Li Yang, Jian Yang, Tao Wang, Zhigang Wu, and Ke Qiu. Tokendance: Token-to-token mamba for long music-to-dance generation. arXiv preprint arXiv:2603.27314, 2026
-
[44]
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J. Black. Generating holistic 3d human motion from speech. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 469–480, 2023
2023
-
[45]
Speech gesture generation from the trimodal context of text, audio, and speaker iden- tity
Youngwoo Yoon, Woo-Ri Ko, Minsu Jang, Jaeyeon Lee, Jae- hong Kim, and Geehyuk Lee. Speech gesture generation from the trimodal context of text, audio, and speaker iden- tity. InACM Transactions on Graphics, 2020
2020
-
[46]
Diffmotion: Speech-driven gesture synthesis using denoising diffusion model
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xuan Guo, Lei Yang, and Ziwei Liu. Diffmotion: Speech-driven gesture synthesis using denoising diffusion model. InProceedings of the 31st ACM International Con- ference on Multimedia, pages 2310–2319, 2023
2023
-
[47]
Xiangyue Zhang, Dongsheng Li, Jing Li, Yecheng Li, Yan Wang, Shihong Xia, and Xueming Liu. Echomask: Efficient speech-driven gesture generation via masked audio-motion modeling.arXiv preprint arXiv:2508.00047, 2025
-
[48]
Guaranteed robust nonlinear mpc via distur- bance feedback.arXiv preprint arXiv:2509.18760, 2025
Xiangyue Zhang, Dongsheng Li, Yan Wang, Shihong Xia, and Xueming Liu. Globaldiff: Mitigating error accumu- lation in autoregressive motion generation.arXiv preprint arXiv:2509.18760, 2025
-
[49]
Xiangyue Zhang, Yecheng Li, Dongsheng Li, Yan Wang, Shihong Xia, and Xueming Liu. Semtalk: Holistic co- speech motion generation with frame-level semantic empha- sis.arXiv preprint arXiv:2503.13255, 2025
-
[50]
Taming diffusion models for music- driven conducting motion generation
Zhuoran Zhao et al. Taming diffusion models for music- driven conducting motion generation. InProceedings of the AAAI Symposium Series, 2023
2023
-
[51]
On the continuity of rotation representations in neu- ral networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neu- ral networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5745– 5753, 2019
2019
-
[52]
Diffgesture: Generating human gesture from two-person dialogue with diffusion models
Lingting Zhu, Xian Liu, Xuanyu Liu, Rui Qian, Ziwei Liu, and Lequan Yu. Diffgesture: Generating human gesture from two-person dialogue with diffusion models. InProceedings of the International Conference on Multimodal Interaction, pages 583–591, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.