Recognition: unknown
GR-Ben: A General Reasoning Benchmark for Evaluating Process Reward Models
Pith reviewed 2026-05-09 15:17 UTC · model grok-4.3
The pith
Existing process reward models detect errors much less reliably outside mathematical reasoning than within it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GR-Ben shows that in domains beyond mathematical reasoning the error-detection ability of existing PRMs and LLMs is markedly weaker by comparison. In general, PRMs are less adept at identifying knowledge-based errors, whereas LLMs exhibit poorer performance in detecting computational errors.
What carries the argument
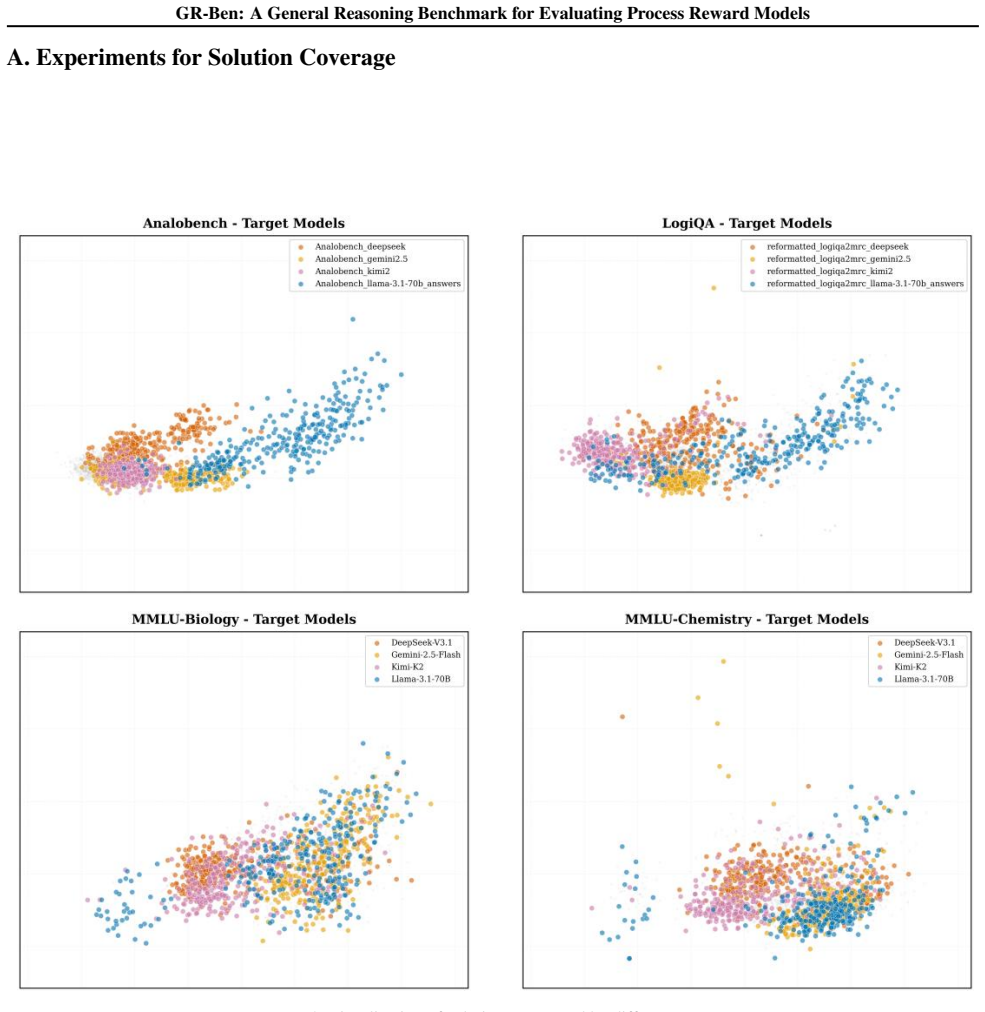
GR-Ben, the process-level benchmark that annotates errors across two primary domains (science and logic) and nine subdomains to test PRM capabilities.
If this is right
- PRM training data and objectives should place greater emphasis on knowledge-based error detection in non-mathematical domains.
- LLM evaluators require targeted improvements to better identify computational mistakes during reasoning.
- Test-time scaling methods that rely on current PRMs will stay limited to math-heavy tasks until the observed performance gaps are closed.
- GR-Ben supplies a concrete measurement tool that future work can use to track progress toward general-domain PRMs.
Where Pith is reading between the lines
- The results suggest that existing PRM training corpora remain too concentrated on mathematical problems and under-represent other error categories.
- Extending the same annotation approach to domains such as code generation or everyday decision-making would likely surface additional specific weaknesses.
- Hybrid systems that combine a PRM with an LLM might offset the complementary error-detection gaps identified in the experiments.
Load-bearing premise
The selected science and logic domains together with their nine subdomains and error annotations in GR-Ben accurately represent the full range of real-world reasoning scenarios and error types that PRMs must handle.
What would settle it
Training a new PRM on GR-Ben data that achieves error-detection accuracy on science and logic domains comparable to its performance on mathematical benchmarks would undermine the claim of markedly weaker ability outside mathematics.
Figures



read the original abstract
Currently, process reward models (PRMs) have exhibited remarkable potential for test-time scaling. Since large language models (LLMs) regularly generate flawed intermediate reasoning steps when tackling a broad spectrum of reasoning and decision-making tasks, PRMs are required to possess capabilities for detecting process-level errors in real-world scenarios. However, existing benchmarks primarily focus on mathematical reasoning, thereby failing to comprehensively evaluate the error detection ability of PRMs across diverse reasoning scenarios. To mitigate this gap, we introduce GR-Ben, a process-level benchmark specifically designed for assessing PRM's performance across two primary reasoning domains (science and logic) and nine subdomains. We conduct extensive experiments on a diverse set of 22 models, encompassing both PRMs and LLMs, and derive two key findings: (1) In domains beyond mathematical reasoning, the error-detection ability of existing PRMs and LLMs is found to be markedly weaker by comparison.(2) In general, PRMs are less adept at identifying knowledge-based errors, whereas LLMs exhibit poorer performance in detecting computational errors. We hope GR-Ben can foster future researches on PRMs for general domains, thereby enhancing the reasoning capabilities of LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GR-Ben, a benchmark designed to evaluate process reward models (PRMs) on detecting errors in reasoning processes within science and logic domains, extending beyond the mathematical focus of prior benchmarks. It includes nine subdomains and distinguishes between knowledge-based and computational errors. Experiments involving 22 models (PRMs and LLMs) lead to two main conclusions: error detection is weaker in non-mathematical domains, PRMs perform worse on knowledge errors, and LLMs on computational errors.
Significance. Should the benchmark prove representative and the annotations reliable, the findings would be significant for the field of AI reasoning, as they identify specific weaknesses in existing PRMs and LLMs that could inform the design of better test-time scaling methods and general reasoning systems. The broad evaluation across 22 models is a strength, providing comparative insights. However, the absence of detailed construction methodology limits the immediate impact.
major comments (3)
- [Benchmark Construction] Benchmark Construction section: The paper provides insufficient details on the benchmark creation process, including how reasoning traces were generated, how errors were injected or identified, the criteria for classifying errors as knowledge-based versus computational, and any quality control measures like inter-annotator agreement scores. This information is essential to assess the validity of the comparative findings between PRMs and LLMs.
- [Experimental Results] Experimental Results section: The reported performance differences lack accompanying statistical analysis, such as p-values, effect sizes, or error bars on the metrics used to compare error-detection abilities. Without this, the claims about 'markedly weaker' performance and specific weaknesses cannot be rigorously evaluated.
- [Introduction] Introduction and Conclusion sections: The assertion that GR-Ben represents 'general reasoning' relies on the chosen domains and subdomains, but no evidence or argument is given for why these nine subdomains adequately sample the space of real-world reasoning errors outside mathematics, raising concerns about whether the observed PRM/LLM gaps are general or distribution-specific.
minor comments (2)
- [Abstract] The abstract could more explicitly state the total number of models evaluated (22) and the specific metrics used for evaluation to provide a clearer overview.
- Ensure all figures and tables have clear captions and legends explaining the performance metrics and model categories (PRM vs. LLM).
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight important areas for improving the clarity, rigor, and transparency of the manuscript. We address each major comment below and commit to revisions that strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The paper provides insufficient details on the benchmark creation process, including how reasoning traces were generated, how errors were injected or identified, the criteria for classifying errors as knowledge-based versus computational, and any quality control measures like inter-annotator agreement scores. This information is essential to assess the validity of the comparative findings between PRMs and LLMs.
Authors: We agree that the current Benchmark Construction section is insufficiently detailed. In the revised manuscript, we will expand this section to explicitly describe: the LLMs and prompting strategies used to generate reasoning traces; the systematic process for injecting and identifying errors (including annotation guidelines); the precise criteria and illustrative examples for distinguishing knowledge-based errors from computational errors; and quality control procedures, including inter-annotator agreement scores computed over the annotated samples. These additions will enable readers to better evaluate the reliability of the benchmark and the validity of the PRM versus LLM comparisons. revision: yes
-
Referee: [Experimental Results] Experimental Results section: The reported performance differences lack accompanying statistical analysis, such as p-values, effect sizes, or error bars on the metrics used to compare error-detection abilities. Without this, the claims about 'markedly weaker' performance and specific weaknesses cannot be rigorously evaluated.
Authors: We acknowledge the need for statistical support. In the revision, we will augment the Experimental Results section and associated figures with error bars reflecting variability across runs or subsets, report p-values for the primary comparisons (e.g., performance in mathematical versus non-mathematical domains and PRM versus LLM differences), and include effect sizes to quantify the magnitude of observed gaps. This will provide a more rigorous foundation for the claims of markedly weaker performance outside mathematics and the differential error-detection weaknesses. revision: yes
-
Referee: [Introduction] Introduction and Conclusion sections: The assertion that GR-Ben represents 'general reasoning' relies on the chosen domains and subdomains, but no evidence or argument is given for why these nine subdomains adequately sample the space of real-world reasoning errors outside mathematics, raising concerns about whether the observed PRM/LLM gaps are general or distribution-specific.
Authors: We recognize that an explicit justification for domain selection is warranted. In the revised Introduction, we will add a dedicated paragraph arguing for the representativeness of the nine subdomains. This argument will reference established taxonomies of reasoning errors in science (e.g., hypothesis formulation, experimental design) and logic (e.g., deductive and inductive inference), showing how the chosen subdomains cover frequent error types encountered in non-mathematical tasks. We will also qualify the scope in both the Introduction and Conclusion, noting that GR-Ben constitutes an initial benchmark for general reasoning and that future extensions could further broaden coverage. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper creates GR-Ben by selecting science/logic domains and subdomains, annotating process-level errors, and running evaluations on 22 models to report comparative error-detection performance. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps. The two key findings are direct empirical observations from the benchmark runs rather than reductions to the input data or prior self-authored results by construction. This matches the default case of a self-contained empirical contribution with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human or expert annotations can reliably identify process-level errors in science and logic reasoning traces.
Reference graph
Works this paper leans on
-
[1]
Chen, H., Yang, T., Gao, S., Chen, R., Quan, X., Tian, H., and Yao, T. Discriminative policy optimization for token- level reward models. InProceedings of the Forty-second International Conference on Machine Learning, 2025a. Chen, W., He, W., Xi, Z., Guo, H., Hong, B., Zhang, J., Li, N., Gui, T., Li, Y ., Zhang, Q., et al. Better process super- vision wit...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Process Reinforcement through Implicit Rewards
Cui, G., Yuan, L., Wang, Z., Wang, H., Zhang, Y ., Chen, J., Li, W., He, B., Fan, Y ., Yu, T., et al. Process re- inforcement through implicit rewards.arXiv preprint arXiv:2502.01456,
work page internal anchor Pith review arXiv
-
[4]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Folio: Natural language reasoning with first-order logic
Han, S., Schoelkopf, H., Zhao, Y ., Qi, Z., Riddell, M., Zhou, W., Coady, J., Peng, D., Qiao, Y ., Benson, L., et al. Folio: Natural language reasoning with first-order logic. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 22017– 22031,
2024
- [6]
-
[7]
Mirage: Evaluating and explaining inductive reasoning process in language models
Li, J., Cao, P., Jin, Z., Chen, Y ., Liu, K., and Zhao, J. Mirage: Evaluating and explaining inductive reasoning process in language models. InProceedings of the Thirteenth International Conference on Learning Representations, 2025a. Li, X., Yu, H., Zhang, X., Huang, Z., He, S., Liu, K., Zhao, J., Huang, F., and Li, Y . Socratic-prmbench: Benchmark- ing p...
-
[8]
Criticbench: Benchmarking llms for critique-correct rea- soning
Lin, Z., Gou, Z., Liang, T., Luo, R., Liu, H., and Yang, Y . Criticbench: Benchmarking llms for critique-correct rea- soning. InFindings of the Association for Computational Linguistics ACL 2024, pp. 1552–1587,
2024
-
[9]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review arXiv
-
[10]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
B., Boukes, M., and Trilling, D
Stolwijk, S. B., Boukes, M., and Trilling, D. Are generative ai text annotations systematically biased?arXiv preprint arXiv:2512.08404,
-
[12]
Tan, X., Yao, T., Qu, C., Li, B., Yang, M., Lu, D., Wang, H., Qiu, X., Chu, W., Xu, Y ., et al. Aurora: Automated training framework of universal process reward models via ensemble prompting and reverse verification.arXiv preprint arXiv:2502.11520,
-
[13]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Riv- ière, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025a. Team, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence.arXiv prepri...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URL https: //arxiv.org/abs/2505.09388. Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., et al. Mmlu-pro: A more robust and challenging multi-task language un- derstanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
M., Andrews, N., and Khashabi, D
Ye, X., Wang, A., Choi, J., Lu, Y ., Sharma, S., Shen, L., Tiyyala, V . M., Andrews, N., and Khashabi, D. Analobench: benchmarking the identification of abstract and long-context analogies. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 13060–13082,
2024
-
[16]
Momentum-based federated reinforcement learning with interaction and communication efficiency
Zeng, T., Zhang, S., Wu, S., Classen, C., Chae, D., Ewer, E., Lee, M., Kim, H., Kang, W., Kunde, J., Fan, Y ., Kim, J., Koo, H. I., Ramchandran, K., Papailiopoulos, D., and Lee, K. Versaprm: Multi-domain process re- ward model via synthetic reasoning data. InProceed- ings of the Forty-second International Conference on Machine Learning, 2025a. URL https:/...
-
[17]
arXiv preprint arXiv:2501.07301 , year=
Zhang, K., Zhang, J., Li, H., Zhu, X., Hua, E., Lv, X., Ding, N., Qi, B., and Zhou, B. Openprm: Building open-domain process-based reward models with preference trees. In Proceedings of the Thirteenth International Conference on Learning Representations. Zhang, S., Liu, X., Zhang, X., Liu, J., Luo, Z., Huang, S., and Gong, Y . Process-based self-rewarding...
-
[18]
not found
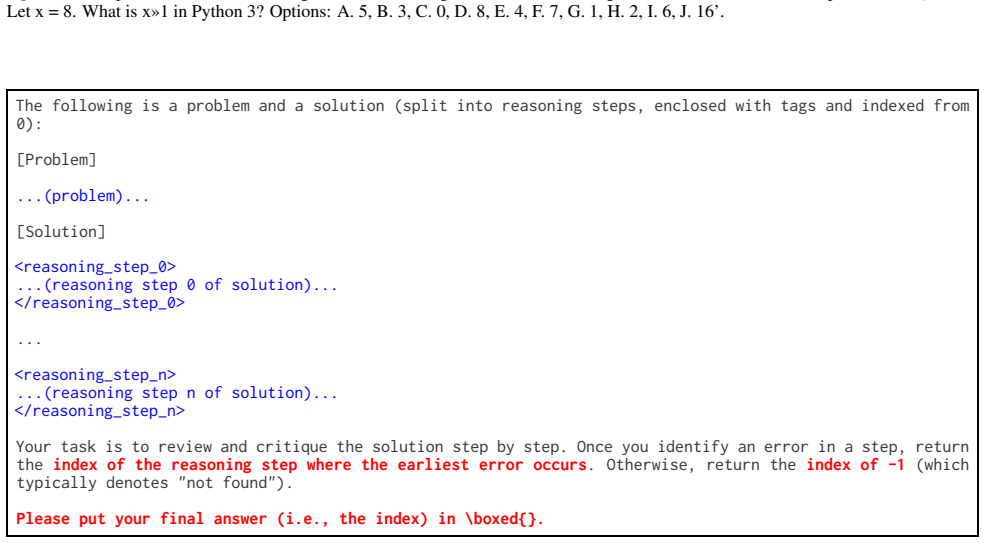
What is x»1 in Python 3? Options: A. 5, B. 3, C. 0, D. 8, E. 4, F. 7, G. 1, H. 2, I. 6, J. 16’. The following is a problem and a solution (split into reasoning steps, enclosed with tags and indexed from 0): [Problem] ...(problem)... [Solution] <reasoning_step_0> ...(reasoning step 0 of solution)... </reasoning_step_0> ... <reasoning_step_n> ...(reasoning ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.