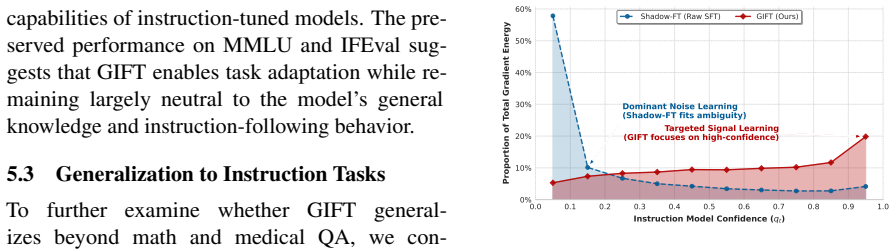
Recognition: unknown
GIFT: Guided Fine-Tuning and Transfer for Enhancing Instruction-Tuned Language Models
Pith reviewed 2026-05-09 15:09 UTC · model grok-4.3
The pith
GIFT fine-tunes low-rank adapters on base models using confidence signals from instruction-tuned models before merging to improve task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GIFT fine-tunes a low-rank adapter on the pretrained base model using confidence signals derived from the instruction-tuned model. The learned adapter is then merged into the instruction-tuned model, yielding task-specialized models that preserve general instruction-following behavior and outperform direct fine-tuning and representative transfer-based baselines on mathematical and knowledge-intensive benchmarks.
What carries the argument
The GIFT process of deriving confidence signals from the instruction-tuned model to guide low-rank adapter training on the base model, followed by merging.
If this is right
- Task performance rises on mathematical and knowledge-intensive benchmarks relative to direct fine-tuning.
- General instruction-following ability remains stable after the merge step.
- Test-time scaling behavior stays favorable or improves.
- The gains hold across different model families and sizes.
Where Pith is reading between the lines
- The same confidence-guided transfer step could be tried with other merging techniques to reduce forgetting of broad capabilities.
- If confidence signals prove stable, the method might extend naturally to continual learning settings where new tasks arrive over time.
- It points to a general pattern where one model variant can supervise adaptation of another without full retraining.
Load-bearing premise
Confidence signals from the instruction-tuned model give reliable and unbiased guidance for training the adapter without harming generalization or creating artifacts in the merged result.
What would settle it
Running GIFT on a new benchmark where it fails to exceed direct fine-tuning accuracy or where instruction-following scores drop below the unadapted instruction model.
Figures


read the original abstract
A promising paradigm for adapting instruction-tuned language models is to learn task-specific updates on a pretrained base model and subsequently merge them into the instruction-tuned model. However, existing approaches typically treat the instruction-tuned model as a passive target that is only involved at the final merging stage, without guiding the training process. We propose GIFT (Guided Fine-Tuning and Transfer), a simple and efficient framework that incorporates guidance from the instruction model into task adaptation. GIFT fine-tunes a low-rank adapter on the pretrained base model using confidence signals derived from the instruction-tuned model. The learned adapter is then merged into the instruction-tuned model, yielding task-specialized models that preserve general instruction-following behavior. We evaluate GIFT on mathematical and knowledge-intensive benchmarks across multiple model families and scales. Results show that GIFT consistently outperforms direct fine-tuning and representative transfer-based baselines, while maintaining robust generalization and favorable test-time scaling behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GIFT, a framework for task adaptation of instruction-tuned language models. It fine-tunes a low-rank adapter on the pretrained base model using confidence signals extracted from the instruction-tuned model, then merges the adapter into the instruction-tuned model. The central empirical claim is that this guided approach consistently outperforms direct fine-tuning and representative transfer-based baselines on mathematical and knowledge-intensive benchmarks across multiple model families and scales, while preserving generalization and showing favorable test-time scaling.
Significance. If the results hold under rigorous controls, GIFT would represent a practical advance in efficient model adaptation by incorporating guidance during the fine-tuning stage rather than only at the final merge. The empirical evaluation across scales and tasks is a positive feature, and the simplicity of the method could make it reproducible and extensible. However, the absence of detailed experimental protocols limits the ability to assess whether the gains are attributable to the guidance mechanism itself.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the claim of consistent outperformance lacks supporting details on baseline implementations, hyperparameter tuning procedures, number of runs, and statistical significance tests. Without these, it is impossible to exclude confounds such as differential tuning effort, undermining verification of the central empirical claim.
- [§3 (Method)] §3 (Method): the approach depends on confidence signals from the instruction-tuned model being reliable and unbiased guides for adapter training on the base model. No analysis, ablation, or failure-case examination is provided to test whether these signals encode the instruction model's own errors, overconfidence, or domain biases; this assumption is load-bearing for attributing gains to the guidance principle rather than artifacts of signal construction.
minor comments (2)
- [§3 (Method)] Clarify the precise mathematical definition of the confidence signals and the loss used to incorporate them during adapter fine-tuning.
- [§5 (Discussion)] Add discussion of potential negative transfer or degradation cases, even if results are positive on the reported benchmarks.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where additional rigor and transparency will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the claim of consistent outperformance lacks supporting details on baseline implementations, hyperparameter tuning procedures, number of runs, and statistical significance tests. Without these, it is impossible to exclude confounds such as differential tuning effort, undermining verification of the central empirical claim.
Authors: We agree that the current manuscript provides insufficient detail on experimental protocols, making it difficult to fully rule out confounds. In the revised version, we will expand §4 and add an appendix with complete specifications of all baseline implementations, hyperparameter tuning procedures (including search ranges and selected values), the number of runs and random seeds used, and results from statistical significance tests. This will allow direct assessment of whether performance differences arise from the guidance mechanism. revision: yes
-
Referee: [§3 (Method)] §3 (Method): the approach depends on confidence signals from the instruction-tuned model being reliable and unbiased guides for adapter training on the base model. No analysis, ablation, or failure-case examination is provided to test whether these signals encode the instruction model's own errors, overconfidence, or domain biases; this assumption is load-bearing for attributing gains to the guidance principle rather than artifacts of signal construction.
Authors: The referee correctly notes that the reliability of the confidence signals is a foundational assumption without dedicated validation in the current manuscript. While cross-model and cross-scale results provide supporting evidence for the overall approach, we did not include targeted ablations or failure-case analysis of signal biases or errors. We will revise §3 to incorporate an analysis of signal quality (e.g., correlation with correctness), ablations using perturbed or random signals, and examination of failure modes, to more rigorously attribute gains to the guidance process. revision: yes
Circularity Check
No derivation chain present; purely empirical method
full rationale
The paper introduces GIFT as an empirical framework for adapter fine-tuning guided by confidence signals from an instruction-tuned model, followed by merging and benchmark evaluation. No equations, derivations, uniqueness theorems, or mathematical predictions appear in the provided text. Claims of outperformance rest on experimental results across model families rather than any self-referential fitting, renaming, or self-citation load-bearing steps. The work is self-contained as a practical method with independent empirical support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-rank adapters can capture task-specific updates that are compatible with merging into instruction-tuned models.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[9]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[10]
2025 , eprint=
Shadow-FT: Tuning Instruct Model via Training on Paired Base Model , author=. 2025 , eprint=
2025
-
[11]
Efficient Model Development through Fine-tuning Transfer
Lin, Pin-Jie and Balasubramanian, Rishab and Liu, Fengyuan and Kandpal, Nikhil and Vu, Tu. Efficient Model Development through Fine-tuning Transfer. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.131
-
[12]
Sheng Cao and Mingrui Wu and Karthik Prasad and Yuandong Tian and Zechun Liu , booktitle=. Param\. 2025 , url=
2025
-
[13]
2024 , eprint=
RE-Adapt: Reverse Engineered Adaptation of Large Language Models , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Unveiling Over-Memorization in Finetuning LLMs for Reasoning Tasks , author=. 2025 , eprint=
2025
-
[15]
Huang, Shih-Cheng and Li, Pin-Zu and Hsu, Yu-chi and Chen, Kuang-Ming and Lin, Yu Tung and Hsiao, Shih-Kai and Tsai, Richard and Lee, Hung-yi. Chat Vector: A Simple Approach to Equip LLM s with Instruction Following and Model Alignment in New Languages. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
-
[16]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[17]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[19]
2019 , eprint=
Averaging Weights Leads to Wider Optima and Better Generalization , author=. 2019 , eprint=
2019
-
[20]
2022 , eprint=
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author=. 2022 , eprint=
2022
-
[21]
2023 , eprint=
TIES-Merging: Resolving Interference When Merging Models , author=. 2023 , eprint=
2023
-
[22]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[23]
Hugging Face repository , howpublished =
Jia LI and Edward Beeching and Lewis Tunstall and Ben Lipkin and Roman Soletskyi and Shengyi Costa Huang and Kashif Rasul and Longhui Yu and Albert Jiang and Ziju Shen and Zihan Qin and Bin Dong and Li Zhou and Yann Fleureau and Guillaume Lample and Stanislas Polu , title =. Hugging Face repository , howpublished =. 2024 , publisher =
2024
-
[24]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[27]
Mathematical Association of America , year=
AIME 2024 Competition Mathematical Problems , author=. Mathematical Association of America , year=
2024
-
[28]
American Mathematics Competitions , year=
AMC 2023 Competition Problems , author=. American Mathematics Competitions , year=
2023
-
[29]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review arXiv 2009
-
[30]
2025 , eprint=
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification , author=. 2025 , eprint=
2025
-
[31]
2024 , eprint=
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
Dataless Knowledge Fusion by Merging Weights of Language Models , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages , author=. 2024 , eprint=
2024
-
[34]
The Eleventh International Conference on Learning Representations , year=
Editing models with task arithmetic , author=. The Eleventh International Conference on Learning Representations , year=
-
[35]
2022 , eprint=
Merging Models with Fisher-Weighted Averaging , author=. 2022 , eprint=
2022
-
[36]
Conference on health, inference, and learning , pages=
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering , author=. Conference on health, inference, and learning , pages=. 2022 , organization=
2022
-
[37]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[38]
Coarse-to-Fine n-Best Parsing and M ax E nt Discriminative Reranking
Charniak, Eugene and Johnson, Mark. Coarse-to-Fine n-Best Parsing and M ax E nt Discriminative Reranking. Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics ( ACL `05). 2005. doi:10.3115/1219840.1219862
-
[39]
Learning to summarize with human feedback , url =
Stiennon, Nisan and Ouyang, Long and Wu, Jeffrey and Ziegler, Daniel and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul F , booktitle =. Learning to summarize with human feedback , url =
-
[40]
Transactions on Machine Learning Research , issn=
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[41]
2025 , organization=
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters , author=. 2025 , organization=
2025
-
[42]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[43]
Instruction-Following Evaluation for Large Language Models
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2025 , eprint=
Enhancing Large Language Model Reasoning via Selective Critical Token Fine-Tuning , author=. 2025 , eprint=
2025
-
[45]
EMNLP , year=
Super-NaturalInstructions:Generalization via Declarative Instructions on 1600+ Tasks , author=. EMNLP , year=
-
[46]
The Fourteenth International Conference on Learning Representations , year=
Anchored Supervised Fine-Tuning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[47]
G2: Guided Generation for Enhanced Output Diversity in LLM s
Ruan, Zhiwen and Li, Yixia and Liu, Yefeng and Chen, Yun and Luo, Weihua and Li, Peng and Liu, Yang and Chen, Guanhua. G2: Guided Generation for Enhanced Output Diversity in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.713
-
[48]
2026 , eprint=
SPPO: Sequence-Level PPO for Long-Horizon Reasoning Tasks , author=. 2026 , eprint=
2026
-
[49]
Ruan, Zhiwen and Li, Yixia and Zhu, He and Wang, Longyue and Luo, Weihua and Zhang, Kaifu and Chen, Yun and Chen, Guanhua. L ay A lign: Enhancing Multilingual Reasoning in Large Language Models via Layer-Wise Adaptive Fusion and Alignment Strategy. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.81
-
[50]
doi: 10.18653/v1/2025.naacl-long.248
Wang, Hanqing and Li, Yixia and Wang, Shuo and Chen, Guanhua and Chen, Yun. M i L o RA : Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.1...
-
[51]
Beyond the Surface: Enhancing LLM-as-a-Judge Alignment with Human via Internal Representations , author=
-
[52]
2026 , eprint=
SAT: Balancing Reasoning Accuracy and Efficiency with Stepwise Adaptive Thinking , author=. 2026 , eprint=
2026
-
[53]
InCoder-32B-Thinking: Industrial Code World Model for Thinking
InCoder-32B-Thinking: Industrial Code World Model for Thinking , author=. arXiv preprint arXiv:2604.03144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.