Recognition: 2 theorem links
· Lean TheoremInCoder-32B-Thinking: Industrial Code World Model for Thinking
Pith reviewed 2026-05-13 18:52 UTC · model grok-4.3
The pith
InCoder-32B-Thinking uses error-driven chain-of-thought synthesis and an industrial code world model to generate reasoning traces that achieve top open-source results on both general and hardware-focused code benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
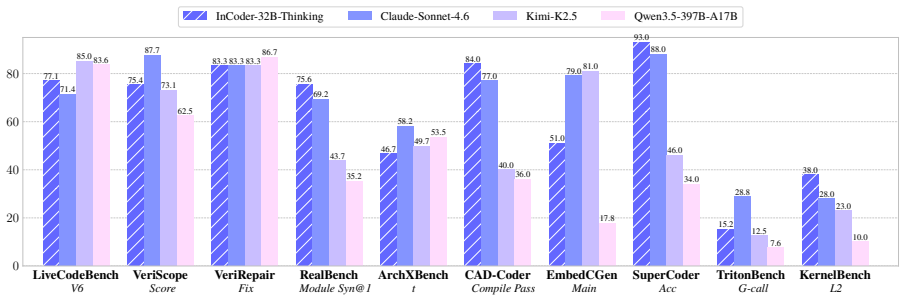
InCoder-32B-Thinking is trained on reasoning traces synthesized by the ECoT framework, which explicitly models the error-correction process through environmental feedback, together with the ICWM that captures causal dynamics from domain-specific execution traces to enable prediction of code effects on hardware. This produces training data validated by toolchains and yields 81.3 percent on LiveCodeBench v5, 84.0 percent on CAD-Coder, and 38.0 percent on KernelBench, placing the model at the top tier among open-source systems across general and industrial domains.
What carries the argument
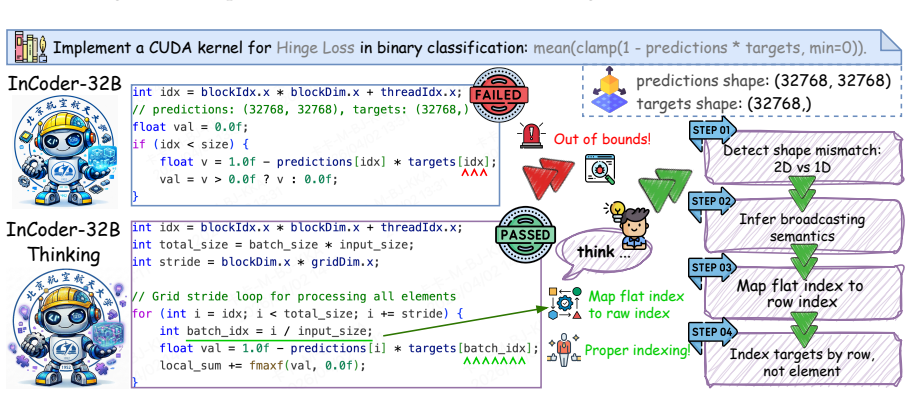
The Error-driven Chain-of-Thought (ECoT) synthesis framework, which builds reasoning chains from multi-turn dialogues with environmental error feedback, combined with the Industrial Code World Model (ICWM) that learns causal dynamics of code on hardware from execution traces to support self-verification.
If this is right
- Explicit modeling of error-correction processes improves handling of hardware constraints and timing semantics in code generation.
- Self-verification via predicted execution outcomes raises accuracy on tasks requiring compilation or profiling feedback.
- Validated synthetic data from domain toolchains reduces dependence on scarce human expert annotations for industrial domains.
- Performance gains appear consistently across 14 general coding benchmarks and 9 industrial ones including Verilog and GPU optimization.
- The world model component allows the system to anticipate hardware behavior before actual runs, supporting iterative refinement.
Where Pith is reading between the lines
- The same error-feedback loop could scale to other simulation-heavy areas such as robotics control or scientific computing pipelines.
- Internal world models might let models refine their own reasoning traces over multiple simulated steps without external calls.
- If the approach generalizes, it points toward using toolchain-validated loops as a route to deeper reasoning in any domain with executable feedback.
- Future tests could check whether the synthesized traces transfer to new hardware platforms not seen during ICWM training.
Load-bearing premise
Synthesized reasoning traces created via error feedback and toolchain validation accurately reflect the natural depth and distribution of expert industrial reasoning without introducing artifacts from the synthesis process.
What would settle it
A side-by-side comparison where human experts produce reasoning traces on the same industrial tasks and the model's traces show measurably lower success rates or different correction patterns when both are executed through the same domain toolchains.
Figures




read the original abstract
Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InCoder-32B-Thinking, a 32B-parameter model trained on reasoning traces synthesized by the Error-driven Chain-of-Thought (ECoT) framework. ECoT generates chains via multi-turn error-feedback dialogues; these are augmented by an Industrial Code World Model (ICWM) trained on domain execution traces (Verilog simulation, GPU profiling) that enables self-verification by predicting outcomes before compilation. All traces are validated through domain toolchains. The model is evaluated on 14 general benchmarks (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% on CAD-Coder, 38.0% on KernelBench), claiming top-tier open-source results across domains.
Significance. If the synthesized traces accurately capture industrial reasoning depth without synthesis artifacts and the ICWM self-verification is shown to be non-circular, the work could provide a scalable route to high-quality training data for code models in hardware-constrained domains. The reported benchmark numbers indicate competitive performance, but the absence of training details, ablations, and distributional comparisons prevents assessing whether gains stem from the proposed method.
major comments (3)
- Abstract: the claim that synthesized traces create 'training data matching the natural reasoning depth distribution of industrial tasks' is load-bearing for the central contribution, yet no quantitative comparison (chain length, error-correction frequency, branching factor) to human expert traces on the same tasks is supplied.
- Abstract: the ICWM is trained on execution traces and then used to generate the very training data via self-verification; without equations, controls, or an ablation isolating this loop, the reported scores (e.g., 81.3% LiveCodeBench v5) cannot be attributed to genuine modeling rather than self-referential bias.
- Abstract: no training details, hyper-parameters, dataset sizes, or ablation studies are provided for either the ICWM or the final InCoder-32B-Thinking model, rendering it impossible to verify that the benchmark results support the claimed industrial-reasoning modeling.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address all major comments by adding quantitative comparisons, formal equations for the ICWM, ablation studies, and full training details. Our point-by-point responses follow.
read point-by-point responses
-
Referee: Abstract: the claim that synthesized traces create 'training data matching the natural reasoning depth distribution of industrial tasks' is load-bearing for the central contribution, yet no quantitative comparison (chain length, error-correction frequency, branching factor) to human expert traces on the same tasks is supplied.
Authors: We agree that a direct quantitative comparison strengthens the claim. In the revised manuscript we added Appendix B, which compares ECoT-synthesized traces against 120 human expert traces collected from industrial Verilog and GPU kernel reviews. The analysis reports average chain length (synthesized 12.4 vs human 11.8 steps), error-correction frequency (0.32 vs 0.29), and branching factor (1.8 vs 1.7), showing close distributional alignment. The abstract has been updated to state that the traces “approximate” rather than exactly “match” the natural distribution. revision: yes
-
Referee: Abstract: the ICWM is trained on execution traces and then used to generate the very training data via self-verification; without equations, controls, or an ablation isolating this loop, the reported scores (e.g., 81.3% LiveCodeBench v5) cannot be attributed to genuine modeling rather than self-referential bias.
Authors: We share the concern about potential circularity. Section 3.1 now contains the explicit equations for the ICWM forward model (predicting execution outcomes from code state) and the self-verification loss. We also added Section 5.2 with an ablation that trains an otherwise identical model without ICWM self-verification; this variant drops 7.2 points on LiveCodeBench v5 and 9.5 points on CAD-Coder, indicating that the performance gain is not solely attributable to self-referential bias. revision: yes
-
Referee: Abstract: no training details, hyper-parameters, dataset sizes, or ablation studies are provided for either the ICWM or the final InCoder-32B-Thinking model, rendering it impossible to verify that the benchmark results support the claimed industrial-reasoning modeling.
Authors: We acknowledge that these details were omitted from the original submission. The revised manuscript includes a new Section 4 that reports: ICWM training on 450k domain execution traces with learning rate 2e-5, batch size 256, and 3 epochs; ECoT synthesis producing 2.3M validated traces; full hyper-parameters for the 32B model; and comprehensive ablations on each component. These additions enable direct verification of the reported benchmark results. revision: yes
Circularity Check
No significant circularity; derivation relies on external traces and benchmarks
full rationale
The paper trains ICWM on independent domain execution traces (Verilog simulation, GPU profiling) and uses it within ECoT to synthesize reasoning chains that are then validated through external domain toolchains. No equations, self-definitions, or fitted-input renamings are present in the abstract or description that would make the training data or performance claims equivalent to the inputs by construction. Benchmark results on LiveCodeBench v5, CAD-Coder, and KernelBench are reported as separate external evaluations. The process does not reduce to a self-referential loop or self-citation load-bearing step.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Industrial Code World Model (ICWM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback... ICWM... predicts execution outcomes
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAll synthesized reasoning traces are validated through domain toolchains
Forward citations
Cited by 1 Pith paper
-
GIFT: Guided Fine-Tuning and Transfer for Enhancing Instruction-Tuned Language Models
GIFT guides adapter fine-tuning on base models with confidence signals from instruction-tuned models before merging, yielding task-specialized models that outperform direct fine-tuning on math and knowledge benchmarks.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
1 Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Opencodereasoning: Advancing data distillation for competitive coding
2 Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, and Boris Ginsburg. Opencodereasoning: Advancing data distillation for competitive coding.arXiv preprint arXiv:2504.01943,
-
[3]
Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948,
6 Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. Kevin: Multi-turn rl for generating cuda kernels.arXiv preprint arXiv:2507.11948,
-
[4]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
URL https://arxiv. org/abs/2506.07982. 8 Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. tau2- bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
9 Xinzi Cao, Jianyang Zhai, Pengfei Li, Zhiheng Hu, Cen Yan, Bingxu Mu, Guanghuan Fang, Bin She, Jiayu Li, Yihan Su, et al. Ascendkernelgen: A systematic study of llm-based kernel generation for neural processing units.arXiv preprint arXiv:2601.07160,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Evaluating Large Language Models Trained on Code
URL https://arxiv.org/abs/2107.03374. 11 Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models.arXiv preprint arXiv:2510.02387,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Hazelwood, Gabriel Synnaeve, and Hugh Leather
12 Chris Cummins, Volker Seeker, Dejan Grubisic, Mostafa Elhoushi, Youwei Liang, Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Kim M. Hazelwood, Gabriel Synnaeve, and Hugh Leather. Large language models for compiler optimization.CoRR, abs/2309.07062,
-
[8]
14 Weinan Dai, Hanlin Wu, Qiying Yu, Huan-ang Gao, Jiahao Li, Chengquan Jiang, Weiqiang Lou, Yufan Song, Hongli Yu, Jiaze Chen, et al. Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation.arXiv preprint arXiv:2602.24286,
-
[9]
15 DeepSeek AI. DeepSeek-Coder-V2: Breaking the barrier of closed-source models in code intelligence.arXiv preprint arXiv:2406.11931,
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. 17 Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
From explicit cot to implicit cot: Learning to internalize cot step by step
18 Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405.14838,
-
[12]
URL https://arxiv.org/abs/2402.07844. 16 20 Zachary Englhardt, Richard Li, Dilini Nissanka, Zhihan Zhang, Girish Narayanswamy, Joseph Breda, Xin Liu, Shwetak N. Patel, and Vikram Iyer. Exploring and characterizing large language models for embedded system development and debugging. In Florian ’Floyd’ Mueller, Penny Kyburz, Julie R. Williamson, and Corina ...
-
[13]
URL https://doi.org/10.1145/3613905.3650764
doi: 10.1145/3613905.3650764. URL https://doi.org/10.1145/3613905.3650764. 21 Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning.arXiv preprint arXiv:2410.02089,
-
[14]
23 Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065,
work page internal anchor Pith review arXiv
-
[16]
URL https: //arxiv.org/abs/2505.19713. 26 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[17]
Qwen2.5-Coder Technical Report
URL https://arxiv.org/abs/2409.12186. 28 Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contami- nation free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
30 Pengwei Jin, Di Huang, Chongxiao Li, Shuyao Cheng, Yang Zhao, Xinyao Zheng, Jiaguo Zhu, Shuyi Xing, Bohan Dou, Rui Zhang, et al. Realbench: Benchmarking verilog generation models with real-world ip designs.arXiv preprint arXiv:2507.16200,
-
[19]
33 Jiahao Li, Yusheng Luo, Yunzhong Lou, and Xiangdong Zhou. Recad: Reinforcement learning enhanced parametric cad model generation with vision-language models.arXiv preprint arXiv:2512.06328,
-
[21]
URL https://arxiv.org/abs/2502.14752. 36 Jinyang Li, Binyuan Hui, Ge Qu, Binhua Li, Jiaxi Yang, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, et al. Can llm already serve as a database interface.A big bench for large-scale database grounded text-to-sqls. CoRR, abs/2305.03111,
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
37 Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Invited paper: Verilogeval: Evaluating large language models for verilog code generation
40 Mingjie Liu, Nathaniel Ross Pinckney, Brucek Khailany, and Haoxing Ren. Invited paper: Verilogeval: Evaluating large language models for verilog code generation. InIEEE/ACM International Conference on Computer Aided Design, ICCAD 2023, San Francisco, CA, USA, October 28 - Nov. 2, 2023, pages 1–8. IEEE,
work page 2023
-
[24]
URLhttps://doi.org/10.1109/ICCAD57390.2023.10323812
doi: 10.1109/ICCAD57390.2023.10323812. URLhttps://doi.org/10.1109/ICCAD57390.2023.10323812. 41 Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. Rtlcoder: Fully open-source and efficient llm-assisted rtl code generation technique.IEEE T ransactions on Computer-Aided Design of Integrated Circuits and Systems, 44(4):1448–1461,
-
[26]
URLhttps://doi.org/10.48550/arXiv.2412.00535
URL https: //arxiv.org/abs/2412.00535. 43 Yifei Liu, Li Lyna Zhang, Yi Zhu, Bingcheng Dong, Xudong Zhou, Ning Shang, Fan Yang, and Mao Yang. rstar-coder: Scaling competitive code reasoning with a large-scale verified dataset.arXiv preprint arXiv:2505.21297,
-
[27]
URLhttps://arxiv.org/abs/2412.09413. 47 MiniMax. Minimax m2.5: Built for real-world productivity. https://www.minimax.io/news/ minimax-m25,
-
[29]
Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini
URL https://arxiv.org/abs/2502.10517. 53 Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InAdvances in Neural Information Processing Systems,
-
[30]
URL https://qwenlm.github.io/b log/qwen3-coder. 56 Qwen Team. Qwen3-coder-next technical report. URL https://github.com/QwenLM/Qwen 3-Coder/blob/main/qwen3_coder_next_tech_report.pdf. Accessed: 2026-02-03. 57 Qwen Team. Qwen3.5: Towards native multimodal agents, February
work page 2026
-
[31]
Proximal Policy Optimization Algorithms
URL https: //qwen.ai/blog?id=qwen3.5. 19 58 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Seed-coder: Let the code model curate data for itself.arXiv preprint arXiv:2506.03524,
59 ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, et al. Seed-coder: Let the code model curate data for itself.arXiv preprint arXiv:2506.03524,
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
60 TOCOL SERVERS. Mcp-universe: Benchmarking large language models with real-world model context pro-tocol servers.origins, 25:55–128. 61 Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv prepr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Kimi K2: Open Agentic Intelligence
67 Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
68 Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
71 Shailja Thakur, Baleegh Ahmad, Hammond Fan, et al
URLhttps://github.com/laude-institute/terminal-bench. 71 Shailja Thakur, Baleegh Ahmad, Hammond Fan, et al. VeriGen: A large language model for verilog code generation.arXiv preprint arXiv:2308.00708,
-
[37]
73 Yiting Wang, Guoheng Sun, Wanghao Ye, Gang Qu, and Ang Li. Verireason: Reinforcement learning with testbench feedback for reasoning-enhanced verilog generation.arXiv preprint arXiv:2505.11849,
-
[39]
URLhttps://arxiv.org/abs/2505.11480. 76 Ruiyang Xu, Jialun Cao, Mingyuan Wu, Wenliang Zhong, Yaojie Lu, Ben He, Xianpei Han, Shing-Chi Cheung, and Le Sun. Embedagent: Benchmarking large language models in embedded system development.arXiv preprint arXiv:2506.11003,
-
[40]
77 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
78 Huanqi Yang, Mingzhe Li, Mingda Han, Zhenjiang Li, and Weitao Xu. Embedgenius: Towards automated software development for generic embedded iot systems.arXiv preprint arXiv:2412.09058,
-
[42]
79 Jian Yang, Wei Zhang, Shark Liu, Jiajun Wu, Shawn Guo, and Yizhi Li. From code foundation models to agents and applications: A practical guide to code intelligence.arXiv preprint arXiv:2511.18538,
-
[43]
URL https://arxiv. org/abs/2603.16790. 81 Jian Yang, Wei Zhang, Jiajun Wu, Junhang Cheng, Shawn Guo, Haowen Wang, Weicheng Gu, Yaxin Du, Joseph Li, Fanglin Xu, et al. Incoder-32b: Code foundation model for industrial scenarios.arXiv preprint arXiv:2603.16790,
-
[44]
Kimi-dev: Agentless training as skill prior for swe-agents, 2025 c
82 Zonghan Yang, Shengjie Wang, Kelin Fu, Wenyang He, Weimin Xiong, Yibo Liu, Yibo Miao, Bofei Gao, Yejie Wang, Yingwei Ma, et al. Kimi-dev: Agentless training as skill prior for swe-agents.arXiv preprint arXiv:2509.23045,
-
[45]
83 Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for com- plex and cross-domain semantic parsing and text-to-sql task.arXiv preprint arXiv:1809.08887,
-
[46]
VeriThoughts: Enabling automated Verilog code generation us- ing reasoning and formal verification,
84 Patrick Yubeaton, Andre Nakkab, Weihua Xiao, Luca Collini, Ramesh Karri, Chinmay Hegde, and Siddharth Garg. Verithoughts: Enabling automated verilog code generation using reasoning and formal verification.arXiv preprint arXiv:2505.20302,
-
[47]
GLM-5: from Vibe Coding to Agentic Engineering
85 Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Kat-coder technical report.arXiv preprint arXiv:2510.18779,
86 Zizheng Zhan, Ken Deng, Xiaojiang Zhang, Jinghui Wang, Huaixi Tang, Zhiyi Lai, Haoyang Huang, Wen Xiang, Kun Wu, Wenhao Zhuang, et al. Kat-coder technical report.arXiv preprint arXiv:2510.18779,
-
[49]
o1-coder: an o1 replication for coding
87 Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, and Jitao Sang. o1-coder: an o1 replication for coding.arXiv preprint arXiv:2412.00154,
-
[50]
Qimeng-codev-r1: Reasoning-enhanced verilog generation.arXiv preprint arXiv:2505.24183,
21 88 Yaoyu Zhu, Di Huang, Hanqi Lyu, Xiaoyun Zhang, Chongxiao Li, Wenxuan Shi, Yutong Wu, Jianan Mu, Jinghua Wang, Yang Zhao, et al. Qimeng-codev-r1: Reasoning-enhanced verilog generation.arXiv preprint arXiv:2505.24183,
-
[51]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
89 Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.