Recognition: unknown
The Partial Testimony of Logs: Evaluation of Language Model Generation under Confounded Model Choice
Pith reviewed 2026-05-09 14:29 UTC · model grok-4.3
The pith
A small randomized experiment plus an offline simulator recover unbiased causal performance comparisons of language models from confounded usage logs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The main result is an identification theorem establishing that the randomized experiment and the simulator together suffice to recover causal model values; the observational log is used only afterward to reduce estimation error rather than to make the causal comparison valid. Six families of estimators are evaluated under this identification strategy.
What carries the argument
The three-source identification design that uses a small randomized experiment for unconfounded scoring, an offline simulator for replaying models on cached contexts, and a large observational log only for variance reduction.
If this is right
- Causal comparisons become valid with only a modest number of randomized trials rather than full randomization of all traffic.
- Adding more observational log data improves precision of the estimates without reintroducing selection bias.
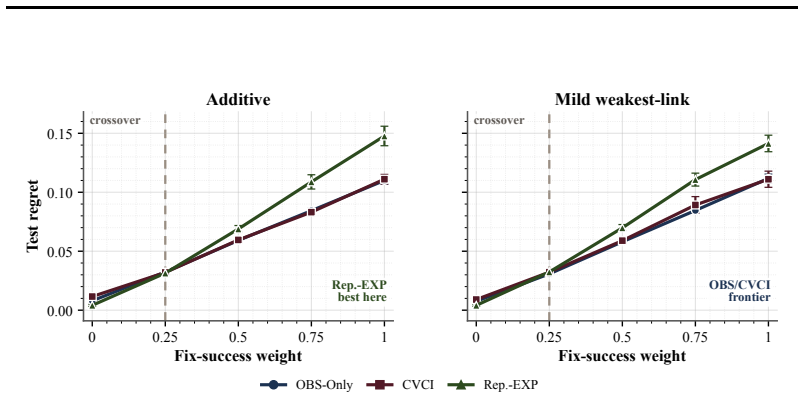
- No single estimator family dominates; performance trades off with the relative sizes of experimental and observational data.
- The approach applies to tasks where contexts can be cached and models can be replayed offline.
Where Pith is reading between the lines
- The same separation of identification from variance reduction could apply to evaluating recommendation systems or search engines that suffer from position or selection bias.
- Prioritizing simulator fidelity over additional confounded data collection would be the practical next step if the theorem holds.
- Adaptive allocation of experiment budget could be derived by monitoring uncertainty after the identification step is secured.
Load-bearing premise
The simulator must accurately replay what each candidate model would have produced on the actual logged contexts, and the randomized experiment must assign models independently of user-side factors.
What would settle it
A direct comparison showing that simulator outputs systematically differ from live model outputs on the same cached prompts would break the identification of causal values.
Figures



read the original abstract
Offline evaluation of language models from usage logs is biased when model choice is confounded: the same user-side factors that influence which model is used can also influence how its output is judged, so raw comparisons of logged scores mix self-selected populations rather than estimating a common quantity of interest. A small randomized experiment can break this bias by overriding model choice, but in practice such experiments are scarce and costly. We study a three-source design that combines a large confounded observational log (OBS) for scale, a small randomized experiment (EXP) for unconfounded scoring, and an offline simulator (SIM) that replays candidate models on cached contexts. Our main result is an identification theorem showing that the randomized experiment and the simulator are together enough to recover causal model values; the observational log enters only afterward, to reduce estimation error rather than to make the causal comparison valid. Six estimator families are evaluated in a controlled semi-synthetic validation and in two real-task cached benchmarks for summarization and coding. No family dominates every regime; relative performance depends on the amount of unbiased EXP supervision and on how closely the target reward aligns with OBS-derived structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that offline evaluation of language models from confounded usage logs can be debiased using a three-source design: a large observational log (OBS) for scale, a small randomized experiment (EXP) for unconfounded measurements, and an offline simulator (SIM) that replays models on cached contexts. The central result is an identification theorem asserting that EXP and SIM together recover causal model values, with OBS entering only afterward for variance reduction rather than for validity. Six estimator families are evaluated in semi-synthetic validation and two real-task cached benchmarks (summarization and coding), with relative performance depending on the amount of EXP supervision and alignment between target reward and OBS-derived structure.
Significance. If the identification theorem is valid, the framework offers a practical route to scalable, low-bias evaluation of LM generations without requiring large-scale randomization, by leveraging abundant but confounded logs alongside limited unbiased data and replay simulators. The finding that no estimator family dominates across regimes is useful for guiding deployment choices. The work is strengthened by its explicit separation of identification from efficiency and by the controlled semi-synthetic plus real-task evaluations, though its impact hinges on the robustness of the simulator replay assumption.
major comments (2)
- [Identification theorem and semi-synthetic validation] The identification theorem (abstract and §3) asserts that EXP + SIM suffice to recover causal quantities with OBS used only for efficiency. This holds only if the simulator produces outputs whose reward distribution exactly matches what each candidate model would have generated on the precise OBS-cached contexts under randomized assignment. Any replay mismatch (un-cached state, truncation, or implementation drift) directly biases the recovered causal contrast, yet the semi-synthetic validation constructs the simulator to be exact by design and therefore does not probe this gap.
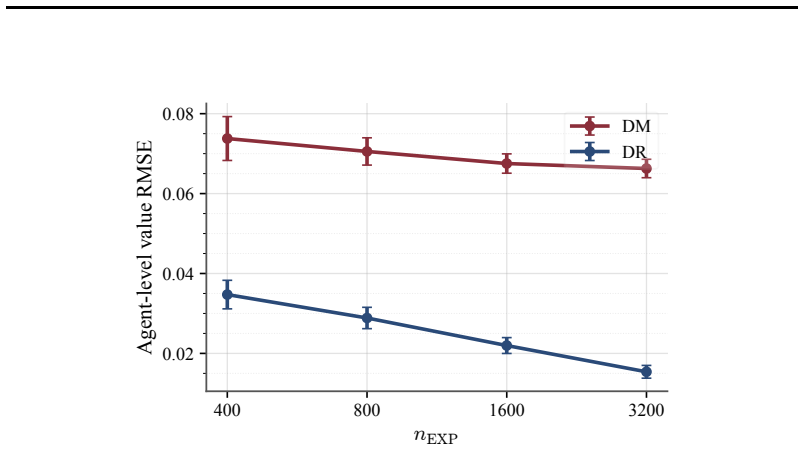
- [Empirical evaluation] The real-task benchmarks (summarization and coding) are presented as evidence that relative estimator performance depends on EXP size and reward alignment, but without reported quantitative tables or confidence intervals showing effect sizes under varying EXP supervision levels, it is difficult to assess whether the claimed practical utility is supported.
minor comments (2)
- [Introduction] Notation for the three data sources (OBS, EXP, SIM) and the six estimator families should be introduced with a single summary table early in the paper for reader orientation.
- [Abstract] The abstract states that 'no family dominates every regime' but does not preview the specific regimes (e.g., low vs. high EXP size) where each family is strongest; adding one sentence would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We respond to each major comment below, indicating where we agree and the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Identification theorem and semi-synthetic validation] The identification theorem (abstract and §3) asserts that EXP + SIM suffice to recover causal quantities with OBS used only for efficiency. This holds only if the simulator produces outputs whose reward distribution exactly matches what each candidate model would have generated on the precise OBS-cached contexts under randomized assignment. Any replay mismatch (un-cached state, truncation, or implementation drift) directly biases the recovered causal contrast, yet the semi-synthetic validation constructs the simulator to be exact by design and therefore does not probe this gap.
Authors: We agree that the identification theorem in §3 requires the simulator to produce reward distributions that exactly match those under randomized assignment on the cached contexts; this assumption is stated explicitly in the theorem conditions. The semi-synthetic validation is constructed with an exact simulator by design to isolate and verify the identification result and estimator performance under ideal conditions where the theorem's assumptions hold. This setup does not test robustness to replay mismatches, which is a valid practical concern not addressed in the current experiments. We will add a new limitations subsection discussing the replay assumption, potential sources of mismatch (such as incomplete caching or implementation drift), and practical steps to minimize them. We will also clarify in §3 that identification holds conditional on accurate simulation. revision: partial
-
Referee: [Empirical evaluation] The real-task benchmarks (summarization and coding) are presented as evidence that relative estimator performance depends on EXP size and reward alignment, but without reported quantitative tables or confidence intervals showing effect sizes under varying EXP supervision levels, it is difficult to assess whether the claimed practical utility is supported.
Authors: We agree that the presentation would benefit from explicit quantitative tables and confidence intervals. The manuscript currently emphasizes trends via figures, but we will add tables (in the main text or appendix) reporting numerical values for key metrics such as bias, variance, and MSE for each estimator family across multiple EXP supervision levels. These will include 95% confidence intervals computed via bootstrap resampling to quantify effect sizes and variability. This revision will make the evidence for practical utility more transparent and easier to evaluate. revision: yes
Circularity Check
No significant circularity; identification theorem stands independently of fitted inputs
full rationale
The paper's central claim is an identification theorem establishing that EXP + SIM suffice to recover causal model values, with OBS entering only for efficiency. No equation or derivation in the provided text reduces a claimed prediction or result to its own inputs by construction. The theorem is conditional on explicit assumptions (accurate simulator replay on cached contexts, unconfounded EXP), which are not smuggled in via self-citation or ansatz. Semi-synthetic validation uses exact simulators by design, but this tests estimator performance under the theorem's assumptions rather than making the identification itself tautological. No load-bearing self-citations or renaming of known results appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The randomized experiment overrides model choice to break confounding.
- domain assumption The simulator faithfully replays candidate models on cached contexts.
Reference graph
Works this paper leans on
-
[1]
Heejung Bang and James M. Robins. Doubly robust estimation in missing data and causal inference models. Biometrics, 61 0 (4): 0 962--973, 2005. doi:10.1111/j.1541-0420.2005.00377.x
-
[2]
Elias Bareinboim and Judea Pearl. Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences, 113 0 (27): 0 7345--7352, 2016. doi:10.1073/pnas.1510507113. URL https://www.pnas.org/doi/10.1073/pnas.1510507113
-
[3]
David Cheng and Tianxi Cai. Adaptive combination of randomized and observational data, 2021. URL https://arxiv.org/abs/2111.15012
-
[4]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLM s by human preference. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machin...
2024
-
[5]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, volume 30, 2017. URL https://arxiv.org/abs/1706.03741
-
[6]
Stephen R. Cole and Elizabeth A. Stuart. Generalizing evidence from randomized clinical trials to target populations: The ACTG 320 trial. American Journal of Epidemiology, 172 0 (1): 0 107--115, 2010. doi:10.1093/aje/kwq084
-
[7]
Causal inference methods for combining randomized trials and observational studies: A review
B \'e n \'e dicte Colnet, Imke Mayer, Guanhua Chen, Awa Dieng, Ruohong Li, Ga \"e l Varoquaux, Jean-Philippe Vert, Julie Josse, and Shu Yang. Causal inference methods for combining randomized trials and observational studies: A review. Statistical Science, 39 0 (1): 0 165--191, 2024. doi:10.1214/23-STS889. URL https://doi.org/10.1214/23-STS889
-
[8]
Hashimoto
Yann Dubois, Bal \'a zs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators. In First Conference on Language Modeling (COLM), 2024. URL https://openreview.net/forum?id=CybBmzWBX0
2024
-
[9]
Doubly robust policy evaluation and learning
Miroslav Dud \' i k, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. In Proceedings of the 28th International Conference on Machine Learning, 2011. URL https://arxiv.org/abs/1103.4601
-
[10]
Doubly robust policy evaluation and optimization
Miroslav Dud \' i k, Dumitru Erhan, John Langford, and Lihong Li. Doubly robust policy evaluation and optimization. Statistical Science, 29 0 (4): 0 485--511, 2014. doi:10.1214/14-STS500. URL https://doi.org/10.1214/14-STS500
-
[11]
Amir Feder, Katherine A. Keith, Emaad Manzoor, Reid Pryzant, Dhanya Sridhar, Zach Wood-Doughty, Jacob Eisenstein, Justin Grimmer, Roi Reichart, Margaret E. Roberts, Brandon M. Stewart, Victor Veitch, and Diyi Yang. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Transactions of the Association for Comput...
-
[12]
Gemma Team . Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Teaching machines to read and comprehend
Karl Moritz Hermann, Tom \'a s Ko c isk \'y , Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, volume 28, 2015. URL https://arxiv.org/abs/1506.03340
-
[14]
Doubly robust off-policy value evaluation for reinforcement learning
Nan Jiang and Lihong Li. Doubly robust off-policy value evaluation for reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp.\ 652--661, 2016. URL https://proceedings.mlr.press/v48/jiang16.html
2016
-
[15]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE -bench: Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2310.06770
work page internal anchor Pith review arXiv 2024
-
[16]
Removing hidden confounding by experimental grounding
Nathan Kallus, Aahlad Manas Puli, and Uri Shalit. Removing hidden confounding by experimental grounding. In Advances in Neural Information Processing Systems, volume 31, pp.\ 10911--10920, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/566f0ea4f6c2e947f36795c8f58ba901-Abstract.html
2018
-
[17]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher R \'e , Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Ho...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Xi Lin, Jens Magelund Tarp, and Robin J. Evans. Combining experimental and observational data through a power likelihood. Biometrics, 81 0 (1): 0 ujaf008, 2025. doi:10.1093/biomtc/ujaf008. URL https://academic.oup.com/biometrics/article/81/1/ujaf008/8016472
-
[19]
Is your automated software engineer trustworthy?, 2025
Noble Saji Mathews and Meiyappan Nagappan. Is your automated software engineer trustworthy?, 2025. URL https://arxiv.org/abs/2506.17812
-
[20]
Abstractive text summarization using sequence-to-sequence RNN s and beyond
Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, Caglar Gulcehre, and Bing Xiang. Abstractive text summarization using sequence-to-sequence RNN s and beyond. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, pp.\ 280--290, 2016. URL https://arxiv.org/abs/1602.06023
-
[21]
Introducing SWE -bench V erified
OpenAI . Introducing SWE -bench V erified. OpenAI Blog, 2024. URL https://openai.com/index/introducing-swe-bench-verified/
2024
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
2022
-
[23]
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations, 2024. URL https://arxiv.org/abs/2404.13076
-
[24]
Transportability of causal and statistical relations: A formal approach
Judea Pearl and Elias Bareinboim. Transportability of causal and statistical relations: A formal approach. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, 2011. doi:10.1609/aaai.v25i1.7861
-
[25]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstra...
2023
-
[26]
James M. Robins, Andrea Rotnitzky, and Lue Ping Zhao. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association, 89 0 (427): 0 846--866, 1994. doi:10.1080/01621459.1994.10476818
-
[27]
Evan T. R. Rosenman, Guillaume Basse, Art B. Owen, and Mike Baiocchi. Combining observational and experimental datasets using shrinkage estimators. Biometrics, 79 0 (4): 0 2961--2973, 2023. doi:10.1111/biom.13827. URL https://pubmed.ncbi.nlm.nih.gov/36629736/
-
[28]
Get To The Point: Summarization with Pointer-Generator Networks
Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pp.\ 1073--1083, 2017. URL https://arxiv.org/abs/1704.04368
work page Pith review arXiv 2017
-
[29]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. In Advances in Neural Information Processing Systems, volume 33, 2020. URL https://arxiv.org/abs/2009.01325
-
[30]
Counterfactual risk minimization: Learning from logged bandit feedback
Adith Swaminathan and Thorsten Joachims. Counterfactual risk minimization: Learning from logged bandit feedback. In Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pp.\ 814--823, 2015. URL https://proceedings.mlr.press/v37/swaminathan15.html
2015
-
[31]
Thomas and Emma Brunskill
Philip S. Thomas and Emma Brunskill. Data-efficient off-policy policy evaluation for reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp.\ 2139--2148, 2016. URL https://proceedings.mlr.press/v48/thomasa16.html
2016
-
[32]
Victor Veitch, Dhanya Sridhar, and David M. Blei. Adapting text embeddings for causal inference. In Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI), volume 124 of Proceedings of Machine Learning Research, pp.\ 919--928, 2020. URL https://proceedings.mlr.press/v124/veitch20a.html
2020
-
[33]
Pat Verga, Sebastian Hofst \"a tter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models, 2024. URL https://arxiv.org/abs/2404.18796
-
[34]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators, 2023. URL https://arxiv.org/abs/2305.17926
-
[35]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R. Narasimhan, and Ofir Press. SWE -agent: Agent-computer interfaces enable automated software engineering. In Advances in Neural Information Processing Systems 37 (NeurIPS), 2024. URL https://openreview.net/forum?id=mXpq6ut8J3
2024
-
[36]
Xuelin Yang, Licong Lin, Susan Athey, Michael I. Jordan, and Guido W. Imbens. Cross-validated causal inference: a modern method to combine experimental and observational data, 2025. URL https://arxiv.org/abs/2511.00727
-
[37]
Wild- Chat: 1M ChatGPT interaction logs in the wild.arXiv preprint arXiv:2405.01470,
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1 M ChatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2405.01470
-
[38]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM -as-a-judge with MT -bench and chatbot arena. In Advances in Neural Information Processing Systems, volume 36, 2023. URL https://arxiv.org/abs/2306.05685
work page internal anchor Pith review arXiv 2023
-
[39]
Xing, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric P. Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. LMSYS - Chat -1 M : A large-scale real-world LLM conversation dataset. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.