Recognition: unknown
Segment-Aligned Policy Optimization for Multi-Modal Reasoning
Pith reviewed 2026-05-09 14:41 UTC · model grok-4.3
The pith
Treating coherent reasoning steps as the units of policy update improves accuracy and stability in multi-modal reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a step-wise Markov decision process abstraction over reasoning segments and using segment-level mechanisms for value estimation, advantage computation, and importance sampling, the proposed approach achieves superior performance compared to token-level and sequence-level policy optimization methods on multi-modal reasoning benchmarks, with notable improvements in accuracy, training stability, and value estimation consistency.
What carries the argument
The segment-level Markov decision process abstraction that aligns policy updates, value estimation, and advantage computation with the boundaries of coherent reasoning steps.
If this is right
- Significant accuracy improvements on representative reasoning benchmarks.
- Better training stability than existing token-level and sequence-level methods.
- More consistent value estimation during training.
- More semantically grounded policy optimization for complex reasoning tasks.
Where Pith is reading between the lines
- This alignment approach might extend naturally to single-modal or other structured reasoning problems if step identification remains reliable.
- Future work could explore automatic segment detection methods to reduce reliance on manual or heuristic boundaries.
- Combining segment alignment with other RL techniques could address remaining credit assignment issues in very long reasoning chains.
Load-bearing premise
Coherent reasoning steps can be reliably identified as distinct units without losing important token-level details or creating new credit assignment problems.
What would settle it
A controlled experiment where reasoning segments are deliberately misidentified or ambiguously defined, leading to no performance gains or degraded stability in SAPO compared to baselines.
Figures



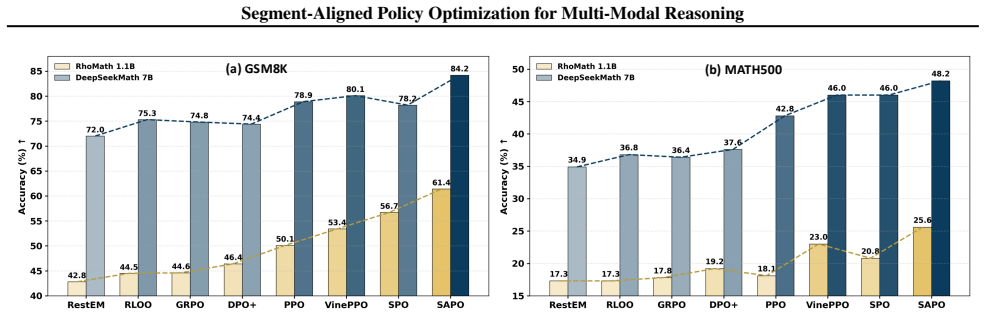

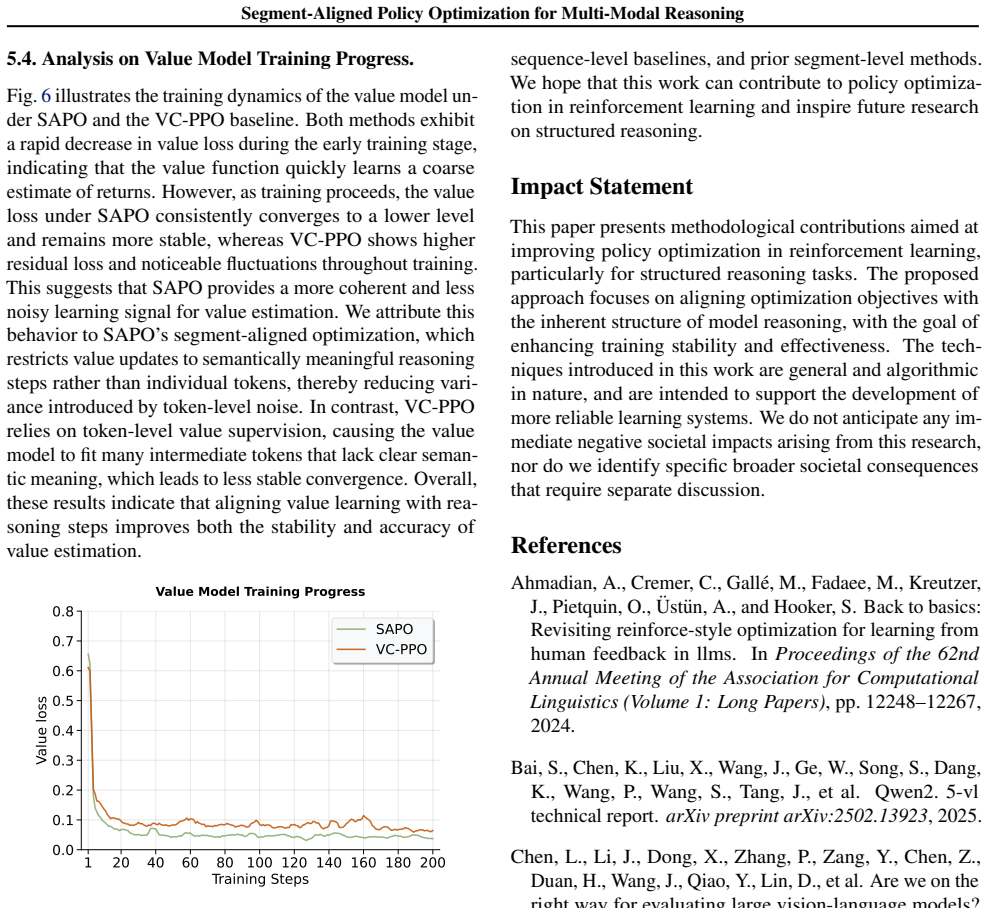

read the original abstract
Existing reinforcement learning approaches for Large Language Models typically perform policy optimization at the granularity of individual tokens or entire response sequences. However, such formulations often misalign with the natural step-wise structure of reasoning processes, leading to suboptimal credit assignment and unstable training in multi-modal reasoning tasks. To bridge this gap, we propose Segment-Aligned Policy Optimization (SAPO), a novel reinforcement learning paradigm that treats coherent reasoning steps, rather than tokens or full sequences as fundamental units of policy update. SAPO introduces a step-wise Markov decision process abstraction over reasoning segments, accompanied by segment-level value estimation, advantage computation, and importance sampling mechanisms that are semantically aligned with reasoning boundaries. Experiments on representative reasoning benchmarks demonstrate that SAPO consistently outperforms token-level and sequence-level policy optimization methods, achieving significant accuracy improvements while exhibiting better training stability and value estimation consistency. Our work underscores the importance of aligning reinforcement learning updates with the intrinsic structure of reasoning, paving the way for more efficient and semantically grounded policy optimization in complex reasoning tasks. Codes and models will be released to ensure full reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Segment-Aligned Policy Optimization (SAPO), a reinforcement learning framework for multi-modal reasoning in LLMs that abstracts the problem as a step-wise MDP over coherent reasoning segments rather than tokens or full sequences. It introduces segment-level value estimation, advantage computation, and importance sampling aligned with reasoning boundaries, and claims that this yields consistent outperformance over token-level and sequence-level baselines in accuracy, training stability, and value estimation consistency on reasoning benchmarks.
Significance. If the empirical results hold and segment boundaries can be identified reliably, SAPO could meaningfully improve credit assignment in RL for complex reasoning by aligning updates with the intrinsic step structure of multi-modal outputs. The promised release of code and models would support reproducibility and allow direct testing of the segment-aligned mechanisms.
major comments (2)
- [Abstract] Abstract: the central claim that SAPO 'consistently outperforms token-level and sequence-level policy optimization methods, achieving significant accuracy improvements while exhibiting better training stability' is asserted without any quantitative results, baselines, error bars, benchmark names, or statistical details. This prevents evaluation of whether the reported gains are substantial or robust.
- [Abstract] Abstract and methods description: the proposal depends on treating 'coherent reasoning segments' as the fundamental MDP units, with 'segment-level value estimation, advantage computation, and importance sampling mechanisms that are semantically aligned with reasoning boundaries.' No detection rule (heuristic, learned, or LLM-prompted), no robustness analysis under boundary noise, and no alignment metric with human step annotations are provided. If boundary errors are frequent, any stability or accuracy gains could arise from changed effective horizons rather than the claimed semantic alignment.
minor comments (1)
- [Abstract] The abstract states that 'Codes and models will be released to ensure full reproducibility,' which is a positive commitment, but the experimental section should include at least high-level details on the multi-modal benchmarks, base models, and training hyperparameters to allow immediate assessment.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments on our paper. We address each of the major comments point by point below, providing clarifications and indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SAPO 'consistently outperforms token-level and sequence-level policy optimization methods, achieving significant accuracy improvements while exhibiting better training stability' is asserted without any quantitative results, baselines, error bars, benchmark names, or statistical details. This prevents evaluation of whether the reported gains are substantial or robust.
Authors: We acknowledge the referee's point that the abstract presents claims without supporting quantitative details. While the full experimental results with specific accuracy numbers, baselines, error bars, and benchmark names are detailed in the body of the paper (Experiments section), we agree that incorporating a brief mention of key quantitative outcomes in the abstract would enhance its informativeness. We will revise the abstract accordingly in the next version. revision: yes
-
Referee: [Abstract] Abstract and methods description: the proposal depends on treating 'coherent reasoning segments' as the fundamental MDP units, with 'segment-level value estimation, advantage computation, and importance sampling mechanisms that are semantically aligned with reasoning boundaries.' No detection rule (heuristic, learned, or LLM-prompted), no robustness analysis under boundary noise, and no alignment metric with human step annotations are provided. If boundary errors are frequent, any stability or accuracy gains could arise from changed effective horizons rather than the claimed semantic alignment.
Authors: The referee correctly identifies a gap in the current description. The manuscript does not specify the exact method for detecting coherent reasoning segments nor provide robustness analysis or alignment metrics. We will add a detailed subsection in the Methods describing the segment detection procedure, along with experiments analyzing sensitivity to boundary noise and correlation with human-annotated steps. This will strengthen the claim that the benefits arise from semantic alignment. revision: yes
Circularity Check
No circularity: SAPO introduces independent segment-aligned mechanisms
full rationale
The paper proposes a new MDP abstraction over reasoning segments with accompanying value estimation and advantage rules. No equations or derivations in the provided text reduce a claimed prediction or first-principles result to a fitted parameter or self-definition from the same work. The central claim rests on empirical comparisons to token- and sequence-level baselines rather than tautological re-derivation. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear. Boundary detection is left unspecified, but that is a methodological gap, not a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Chen, L., Li, J., Dong, X., Zhang, P., Zang, Y ., Chen, Z., Duan, H., Wang, J., Qiao, Y ., Lin, D., et al. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330,
work page internal anchor Pith review arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek- r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025a. Guo, Y ., Xu, L., Liu, J., Ye, D., and Qiu, S. Segment policy optimization: Effective segment-level credit as- signment in rl for large language mo...
-
[5]
Rectifying LLM Thought from Lens of Optimization
Liu, J., Liu, H., Zhang, S., and Chen, K. Rectifying llm thought from lens of optimization.arXiv preprint arXiv:2512.01925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Lu, P., Gong, R., Jiang, S., Qiu, L., Huang, S., Liang, X., and Zhu, S.-C. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. arXiv preprint arXiv:2105.04165,
-
[7]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W., Galley, M., and Gao, J. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review arXiv
-
[8]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
Luo, H., Sun, Q., Xu, C., Zhao, P., Lou, J., Tao, C., Geng, X., Lin, Q., Chen, S., and Zhang, D. Wizard- math: Empowering mathematical reasoning for large lan- guage models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583,
-
[9]
Pal, A., Karkhanis, D., Dooley, S., Roberts, M., Naidu, S., and White, C. Smaug: Fixing failure modes of pref- erence optimisation with dpo-positive.arXiv preprint arXiv:2402.13228,
-
[10]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexi- ble and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review arXiv
-
[13]
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models,
Singh, A., Co-Reyes, J. D., Agarwal, R., Anand, A., Patil, P., Garcia, X., Liu, P. J., Harrison, J., Lee, J., Xu, K., et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585,
-
[14]
Sutton and Doina Precup and Satinder Singh , keywords =
ISSN 0004-3702. doi: 10.1016/ S0004-3702(99)00052-1. URL https://doi.org/ 10.1016/S0004-3702(99)00052-1. Sutton, R. S., Barto, A. G., et al. Reinforcement learning: An introduction 2nd ed.MIT press Cambridge, 1(2):25,
-
[15]
URL https: //openreview.net/forum?id=yfcpdY4gMP. Xiao, Y ., Sun, E., Liu, T., and Wang, W. Logicvista: Multi- modal llm logical reasoning benchmark in visual contexts. arXiv preprint arXiv:2407.04973,
-
[16]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
URLhttps://arxiv.org/abs/2509.13232. Yuan, Y ., Yue, Y ., Zhu, R., Fan, T., and Yan, L. What’s behind ppo’s collapse in long-cot? value optimization holds the secret,
-
[17]
URL https://arxiv.org/ abs/2503.01491. Yue, X., Ni, Y ., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y ., Wei, C., Yu, B., Yuan, R., Sun, R., Yin, M., Zheng, B., Yang, Z., Liu, Y ., Huang, W., Sun, H., Su, Y ., and Chen, W. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi....
-
[18]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
URL https://arxiv.org/abs/2504.05118. Zhang, H., Cui, H., Bao, G., Yang, L., Wang, J., and Zhang, Y . Direct value optimization: Improving chain- of-thought reasoning in LLMs with refined values. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process- i...
work page internal anchor Pith review arXiv 2025
-
[19]
Association for Computational Linguistics. ISBN 979- 8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[20]
emnlp-main.668/
URL https://aclanthology.org/2025. emnlp-main.668/. Zhang, R., Jiang, D., Zhang, Y ., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.-W., Qiao, Y ., et al. Math- verse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pp. 169–186. Springer,
2025
-
[21]
Group Sequence Policy Optimization
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review arXiv
-
[22]
Zou, C., Guo, X., Yang, R., Zhang, J., Hu, B., and Zhang, H. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models.arXiv preprint arXiv:2411.00836,
-
[23]
Benchmark Settings
11 Segment-Aligned Policy Optimization for Multi-Modal Reasoning Algorithm 1Segment-Aligned Policy Optimization (SAPO) Input:dataset D, initial policy πθ, value function Vϕ, number of epochs E, number of mini-batches B, clip parameter ϵ, discount factorγ, decay parameterλ, segmentation hyperparameterk Output:optimized policyπ θ, optimized value functionV ...
2023
-
[24]
SAPO consistently outperforms PPO and GRPO, achieving the best performance, and demonstrates strong generalization to advanced reasoning models. 14 Segment-Aligned Policy Optimization for Multi-Modal Reasoning Comparison of different segmentation strategies across multiple cross-domain benchmarks.We further compare our entropy-based segmentation with newl...
2024
-
[25]
Table 7.Hyperparameters for different training methods on Geo3K. (a)SAPO Hyperparameter Value Total training steps 200 Train batch size 512 Mini batch size 128 Max prompt length 1024 Max response length 2048 Lambda 0.99 Gamma 1.0 Actor LR 1e-6 Critic LR 2e-6 KL penalty in reward K1 KL coef 0.001 Eval. temperature 0.6 Eval. top-p0.95 (b)GRPO Hyperparameter...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.