Recognition: unknown
Injecting Distributional Awareness into MLLMs via Reinforcement Learning for Deep Imbalanced Regression
Pith reviewed 2026-05-12 04:46 UTC · model grok-4.3
The pith
Multimodal LLMs improve regression on rare values by adding batch-level distribution matching rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a Group Relative Policy Optimization framework equipped with a Concordance Correlation Coefficient reward supplies the missing relational supervision, aligning model outputs with ground-truth distributions across correlation, scale, and mean; this yields consistent gains over supervised fine-tuning and prior regression methods on long-tailed benchmarks, with the largest lifts in medium- and few-shot regimes.
What carries the argument
Group Relative Policy Optimization using a batch-level Concordance Correlation Coefficient reward that compares predicted and ground-truth distributions for correlation, scale, and location.
If this is right
- Models exhibit better tail accuracy without regressing to the mean on imbalanced numerical targets.
- Performance lifts appear most strongly in medium- and few-shot regimes across unified benchmarks.
- The approach integrates without any architectural modifications to existing MLLMs.
- Distribution alignment in correlation, scale, and mean follows directly from the batch comparison reward.
Where Pith is reading between the lines
- The same batch-comparison idea could transfer to other prediction settings where labels are naturally uneven, such as time-series forecasting.
- It might reduce reliance on synthetic data generation for rare cases by instead leveraging relational signals within real batches.
- Extending the reward to handle multimodal outputs or uncertainty estimates could address related calibration problems.
Load-bearing premise
The main limitation in current MLLM regression is missing cross-sample relational supervision and that a batch-wise CCC reward supplies it effectively without introducing new biases.
What would settle it
Running the same long-tailed regression benchmarks with the CCC batch reward replaced by standard point-wise rewards and observing no improvement or degradation in tail performance would falsify the central claim.
Figures








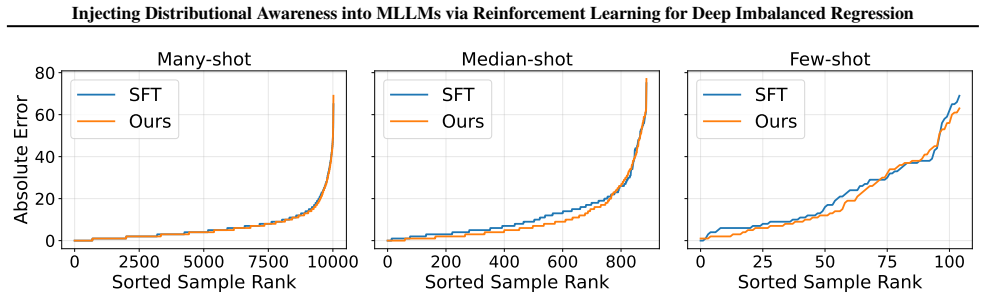
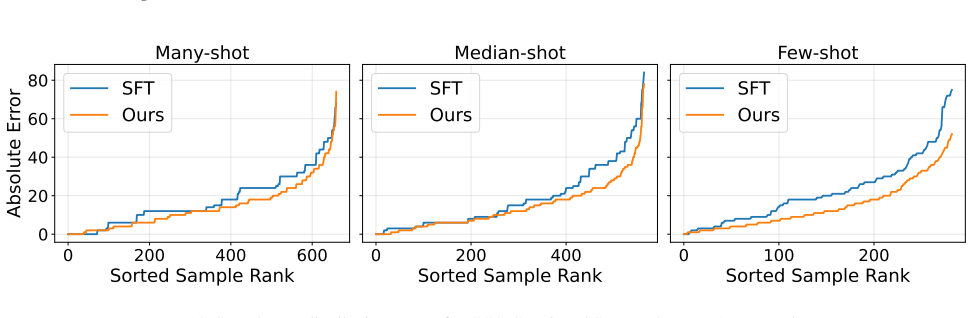
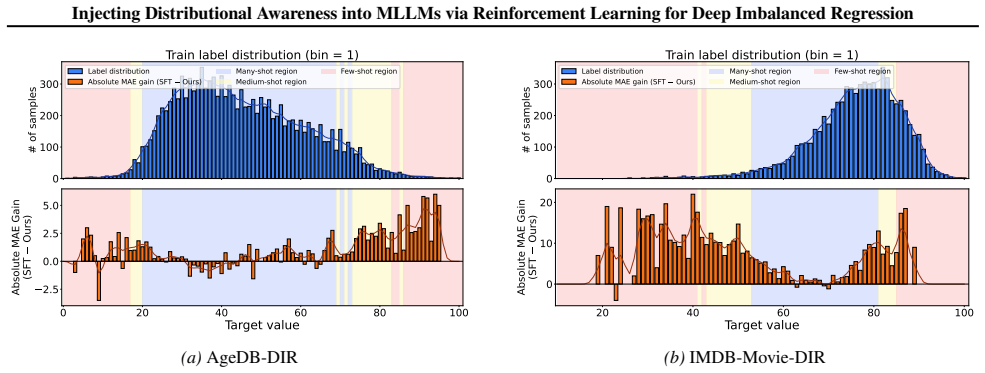
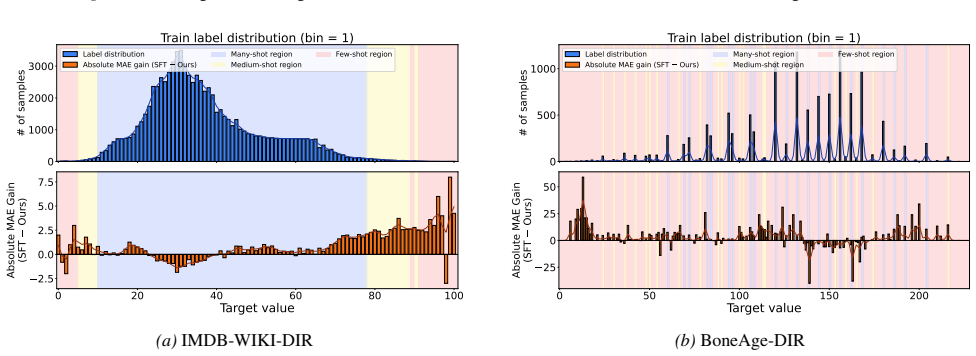


read the original abstract
Multimodal large language models (MLLMs) struggle with numerical regression under long-tailed target distributions. Token-level supervised fine-tuning (SFT) and point-wise regression rewards bias learning toward high-density regions, leading to regression-to-the-mean behavior and poor tail performance. We identify the lack of cross-sample relational supervision as a key limitation of existing MLLM training paradigms. To address it, we propose a distribution-aware reinforcement learning framework based on Group Relative Policy Optimization, which introduces batch-level comparison-based supervision via the Concordance Correlation Coefficient-based reward to align predicted and ground-truth distributions in terms of correlation, scale, and mean. The framework is plug-and-play, requiring no architectural modification. Experiments on a unified suite of long-tailed regression benchmarks show consistent improvements over SFT and existing MLLM regression methods, with particularly strong gains in medium- and few-shot regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MLLMs exhibit regression-to-the-mean on long-tailed numerical regression tasks because token-level SFT and point-wise rewards lack cross-sample relational supervision. It proposes a plug-and-play distribution-aware RL framework based on Group Relative Policy Optimization (GRPO) that uses a batch-level Concordance Correlation Coefficient (CCC) reward to align predicted and ground-truth distributions along correlation, scale, and mean. Experiments on a unified suite of long-tailed regression benchmarks are said to show consistent gains over SFT and prior MLLM regression methods, especially in medium- and few-shot regimes.
Significance. If the results hold, the contribution is significant as a practical, architecture-agnostic method for improving distributional fidelity in MLLM regression on imbalanced data. The work correctly builds on the established CCC metric and presents GRPO as an off-the-shelf RL variant, giving credit for the clean framing of missing relational supervision and the absence of new hyperparameters or model changes.
major comments (1)
- [Method section (reward formulation)] Method section (reward formulation): The central claim that the batch-level CCC reward supplies effective cross-sample relational supervision to correct tail regression-to-the-mean is load-bearing, yet the manuscript does not address how random batching interacts with long-tailed targets. Tail samples typically constitute <5-10% of a random batch, so the CCC gradient is dominated by head samples; this leaves open whether any reported tail gains arise from the claimed mechanism or from generic RL effects, and whether batch size or sampling must be tuned (contradicting the plug-and-play assertion).
minor comments (1)
- [Abstract] Abstract: The claim of 'consistent improvements' and 'particularly strong gains' is stated without any numerical values, baseline names, or error bars; a one-sentence summary of key metrics would aid quick assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment on the reward formulation below and will incorporate clarifications and additional analysis in the revision.
read point-by-point responses
-
Referee: The central claim that the batch-level CCC reward supplies effective cross-sample relational supervision to correct tail regression-to-the-mean is load-bearing, yet the manuscript does not address how random batching interacts with long-tailed targets. Tail samples typically constitute <5-10% of a random batch, so the CCC gradient is dominated by head samples; this leaves open whether any reported tail gains arise from the claimed mechanism or from generic RL effects, and whether batch size or sampling must be tuned (contradicting the plug-and-play assertion).
Authors: We acknowledge that the manuscript does not explicitly analyze the interaction between random batching and long-tailed targets, which is a fair observation. The CCC reward is computed over the full batch and penalizes mismatches in correlation, scale, and location; this global signal can still constrain mean-regression bias even when tails are sparse, because deviations in batch-level statistics affect the reward for all samples. Our point-wise reward baselines already isolate generic RL effects, and the reported gains (particularly in few-shot regimes) are larger than those baselines. Nevertheless, we agree the mechanism would be stronger with direct evidence on batch composition. In the revised manuscript we will add a dedicated paragraph in the method section explaining the batch-level nature of CCC and include an ablation on batch size (standard values 8-32) plus a comparison of random vs. stratified batching to quantify tail-sample influence. These additions require no new hyperparameters or model changes, preserving the plug-and-play claim; batch size is a conventional training choice shared with any RL fine-tuning procedure. revision: partial
Circularity Check
No circularity; derivation relies on standard metrics and empirical validation
full rationale
The paper identifies a limitation in existing MLLM regression (lack of cross-sample relational supervision in SFT and pointwise rewards) and proposes a plug-and-play RL framework that applies the established Concordance Correlation Coefficient as a batch-level reward inside Group Relative Policy Optimization. CCC directly quantifies the desired alignment in correlation, scale, and mean, but this is an explicit design choice rather than a self-referential definition or fitted input renamed as a prediction. No equations or self-citations reduce the central claim to its own inputs by construction; gains are asserted via benchmark experiments, not tautological derivation. The chain is self-contained against external benchmarks and standard RL techniques.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Batch-level CCC reward supplies the missing cross-sample relational supervision needed for tail performance
Reference graph
Works this paper leans on
-
[1]
proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Agedb: the first manually collected, in-the-wild age database , author=. proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[2]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[3]
Advances in Neural Information Processing Systems , volume=
Variational imbalanced regression: Fair uncertainty quantification via probabilistic smoothing , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
ConR: Contrastive Regularizer for Deep Imbalanced Regression , author=
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Leveraging group classification with descending soft labeling for deep imbalanced regression , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep imbalanced regression via hierarchical classification adjustment , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Dist Loss: Enhancing Regression in Few-Shot Region through Distribution Distance Constraint , author=
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Enhancing Numerical Prediction of MLLMs with Soft Labeling , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
Wu, Tianhe and Zou, Jian and Liang, Jie and Zhang, Lei and Ma, Kede , journal=
-
[10]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[11]
Unhackable temporal rewarding for scalable video mllms.arXiv preprint arXiv:2502.12081, 2025
Unhackable Temporal Rewarding for Scalable Video MLLMs , author=. arXiv preprint arXiv:2502.12081 , year=
-
[12]
arXiv preprint arXiv:2307.09474 , year=
Chatspot: Bootstrapping multimodal llms via precise referring instruction tuning , author=. arXiv preprint arXiv:2307.09474 , year=
-
[13]
arXiv preprint arXiv:2312.00589 , year=
Merlin: Empowering multimodal llms with foresight minds , author=. arXiv preprint arXiv:2312.00589 , year=
-
[14]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. arXiv preprint arXiv:2307.15818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[18]
A systematic study of the class imbalance problem in convolutional neural networks , author=. Neural networks , volume=. 2018 , publisher=
work page 2018
-
[19]
Numeracy for language models: Evaluating and improving their ability to predict numbers , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Q-insight: Understanding image quality via visual reinforcement learning , author=. arXiv preprint arXiv:2503.22679 , year=
-
[21]
A concordance correlation coefficient to evaluate reproducibility , author=. Biometrics , pages=. 1989 , publisher=
work page 1989
-
[22]
arXiv preprint arXiv:2505.15074 , year=
DISCO Balances the Scales: Adaptive Domain-and Difficulty-Aware Reinforcement Learning on Imbalanced Data , author=. arXiv preprint arXiv:2505.15074 , year=
-
[23]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2506.07464 , year=
DeepVideo-R1: Video Reinforcement Fine-Tuning via Difficulty-aware Regressive GRPO , author=. arXiv preprint arXiv:2506.07464 , year=
-
[25]
Online Distributionally Robust LLM Alignment via Regression to Relative Reward
DRO-REBEL: Distributionally Robust Relative-Reward Regression for Fast and Efficient LLM Alignment , author=. arXiv preprint arXiv:2509.19104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Reinforcement Learning for Large Language Models via Group Preference Reward Shaping , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[27]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Teaching large language models to regress accurate image quality scores using score distribution , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[28]
The RSNA pediatric bone age machine learning challenge , author=. Radiology , volume=. 2019 , publisher=
work page 2019
-
[29]
Advances in Neural Information Processing Systems , volume=
Semi-supervised contrastive learning for deep regression with ordinal rankings from spectral seriation , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
European Conference on Computer Vision , pages=
Teach clip to develop a number sense for ordinal regression , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[31]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal=
-
[32]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year =
-
[33]
arXiv preprint arXiv:2504.07954 , year =
Perception-r1: Pioneering perception policy with reinforcement learning , author=. arXiv preprint arXiv:2504.07954 , year=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Large-scale long-tailed recognition in an open world , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
VisNumBench: Evaluating Number Sense of Multimodal Large Language Models , author=. arXiv preprint arXiv:2503.14939 , year=
-
[36]
arXiv preprint arXiv:2511.11239 , year=
Beyond Flatlands: Unlocking Spatial Intelligence by Decoupling 3D Reasoning from Numerical Regression , author=. arXiv preprint arXiv:2511.11239 , year=
-
[37]
Detect anything via next point prediction,
Detect anything via next point prediction , author=. arXiv preprint arXiv:2510.12798 , year=
-
[38]
Cls-rl: Image classification with rule-based reinforcement learning , author=. arXiv preprint arXiv:2503.16188 , volume=
-
[39]
arXiv preprint arXiv:2504.04801 , year=
OrderChain: A General Prompting Paradigm to Improve Ordinal Understanding Ability of MLLM , author=. arXiv preprint arXiv:2504.04801 , year=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cogagent: A visual language model for gui agents , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
IEEE Transactions on Medical Imaging , volume=
Adaptive contrast for image regression in computer-aided disease assessment , author=. IEEE Transactions on Medical Imaging , volume=. 2021 , publisher=
work page 2021
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Semi-supervised deep regression with uncertainty consistency and variational model ensembling via bayesian neural networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
Advances in neural information processing systems , volume=
Ordinal regression by extended binary classification , author=. Advances in neural information processing systems , volume=
-
[44]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
Clip-count: Towards text-guided zero-shot object counting , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning Multi-Modal Class-Specific Tokens for Weakly Supervised Dense Object Localization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
International Conference on Machine Learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Imagebind: One embedding space to bind them all , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
Advances in Neural Information Processing Systems , volume=
Rank-n-contrast: learning continuous representations for regression , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Probing conceptual understanding of large visual-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
arXiv preprint arXiv:2306.16048 , year=
Challenges of Zero-Shot Recognition with Vision-Language Models: Granularity and Correctness , author=. arXiv preprint arXiv:2306.16048 , year=
-
[51]
European Conference on Computer Vision , pages=
No token left behind: Explainability-aided image classification and generation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[52]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep ordinal regression network for monocular depth estimation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[53]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Ordinal regression with multiple output cnn for age estimation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[54]
Efficient Estimation of Word Representations in Vector Space , author=. 2013 , eprint=
work page 2013
-
[55]
Proceedings of the European Conference on Computer Vision (ECCV) , pages=
Deepgum: Learning deep robust regression with a gaussian-uniform mixture model , author=. Proceedings of the European Conference on Computer Vision (ECCV) , pages=
-
[56]
Improving language understanding with unsupervised learning
Radford, Alec and Narasimhan, Karthik and Salimans, Tim and Sutskever, Ilya. Improving language understanding with unsupervised learning. 2018
work page 2018
-
[57]
Adaptive variance based label distribution learning for facial age estimation , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXIII 16 , pages=. 2020 , organization=
work page 2020
-
[58]
Proceedings of International Conference on Multimedia Retrieval , pages=
Dating color images with ordinal classification , author=. Proceedings of International Conference on Multimedia Retrieval , pages=
-
[59]
Photo aesthetics ranking network with attributes and content adaptation , author=. Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11--14, 2016, Proceedings, Part I 14 , pages=. 2016 , organization=
work page 2016
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Soft labels for ordinal regression , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[61]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Bridgenet: A continuity-aware probabilistic network for age estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[62]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Fine-grained head pose estimation without keypoints , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[63]
Advances in neural information processing systems , volume=
Label distribution learning forests , author=. Advances in neural information processing systems , volume=
-
[64]
International Journal of Computer Vision , volume=
Deep expectation of real and apparent age from a single image without facial landmarks , author=. International Journal of Computer Vision , volume=. 2018 , publisher=
work page 2018
-
[65]
7th international conference on automatic face and gesture recognition (FGR06) , pages=
Morph: A longitudinal image database of normal adult age-progression , author=. 7th international conference on automatic face and gesture recognition (FGR06) , pages=. 2006 , organization=
work page 2006
-
[66]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[67]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
work page 2022
-
[68]
IEEE transactions on pattern analysis and machine intelligence , volume=
Facial age estimation by learning from label distributions , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
work page 2013
-
[69]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Using ranking-CNN for age estimation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[70]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Mean-variance loss for deep age estimation from a face , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[71]
Energy-based models for deep probabilistic regression , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XX 16 , pages=. 2020 , organization=
work page 2020
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning probabilistic ordinal embeddings for uncertainty-aware regression , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
Self-paced deep regression forests with consideration on underrepresented examples , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXX 16 , pages=. 2020 , organization=
work page 2020
-
[74]
Advances in neural information processing systems , volume=
Semi-supervised sequence learning , author=. Advances in neural information processing systems , volume=
-
[75]
Proceedings of naacL-HLT , volume=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of naacL-HLT , volume=
-
[76]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Styleclip: Text-driven manipulation of stylegan imagery , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[77]
ActionCLIP: A New Paradigm for Video Action Recognition
Wang, Mengmeng and Xing, Jiazheng and Liu, Yong. ActionCLIP: A New Paradigm for Video Action Recognition. arXiv preprint. 2021
work page 2021
-
[78]
International Journal of Computer Vision , pages=
Clip-adapter: Better vision-language models with feature adapters , author=. International Journal of Computer Vision , pages=. 2023 , publisher=
work page 2023
-
[79]
Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Zhang, Renrui and Fang, Rongyao and Zhang, Wei and Gao, Peng and Li, Kunchang and Dai, Jifeng and Qiao, Yu and Li, Hongsheng. Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling. arXiv preprint. 2021
work page 2021
-
[80]
Wav2clip: Learning robust audio representations from clip , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.