Recognition: unknown
SPEC CPU: The Next Generation
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
SPEC CPU 2026 introduces Rolling-Round-Robin Rate to standardize benchmarking of heterogeneous multiprogrammed workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPEC CPU 2026 is constructed from modern open-source applications selected and hardened via a principled process focused on workload diversity, portability, and software longevity. It includes an expanded collection of multithreaded benchmarks along with workloads that exhibit distinct microarchitectural profiles. The central innovation is Rolling-Round-Robin Rate, which supplies a novel and standardized way to run heterogeneous, multiprogrammed workloads and thereby addresses a long-standing gap in benchmarking practice.
What carries the argument
Rolling-Round-Robin Rate, a novel standardized approach to running heterogeneous, multiprogrammed workloads that addresses a long-standing gap in benchmarking practice.
If this is right
- The suite enables performance comparisons that better match the demands of contemporary software.
- Expanded multithreaded benchmarks support evaluation of parallel execution on modern processors.
- Workloads with distinct microarchitectural profiles increase coverage of different processor behaviors.
- The standardized rate method reduces inconsistencies in how heterogeneous workloads are measured across systems.
Where Pith is reading between the lines
- Widespread use could encourage hardware designs that optimize specifically for mixed rather than uniform workloads.
- Benchmark results may become more comparable across research groups and vendors.
- The approach could be adapted to other benchmark suites that currently lack a standard for multiprogrammed execution.
Load-bearing premise
The selected modern open-source applications will maintain workload diversity, portability, and software longevity while reflecting the demands of contemporary software.
What would settle it
If repeated runs of SPEC CPU 2026 using Rolling-Round-Robin Rate produce performance rankings and variability identical to those obtained from prior SPEC CPU suites on the same hardware, the claim that the new method fills a benchmarking gap would be falsified.
Figures


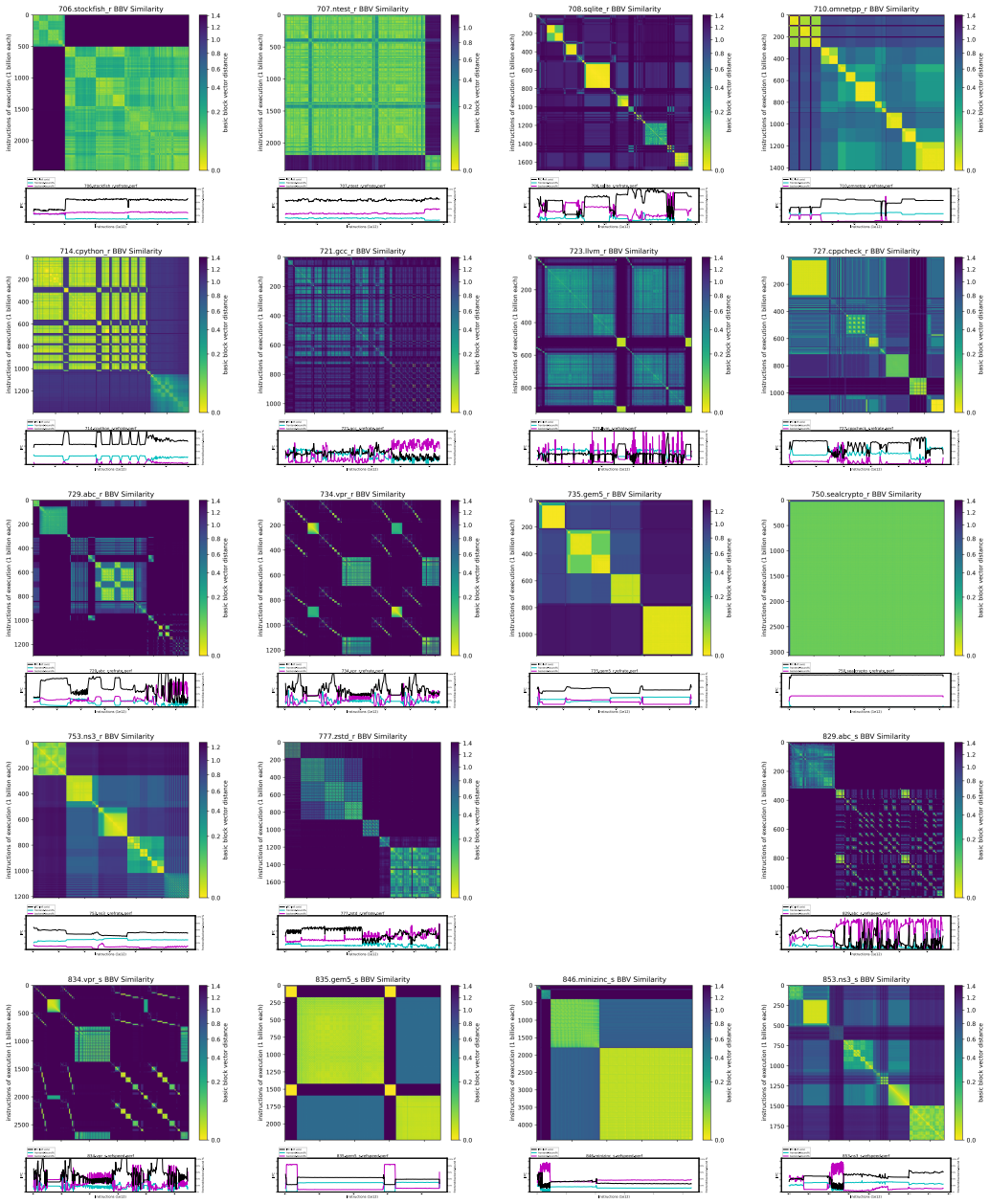
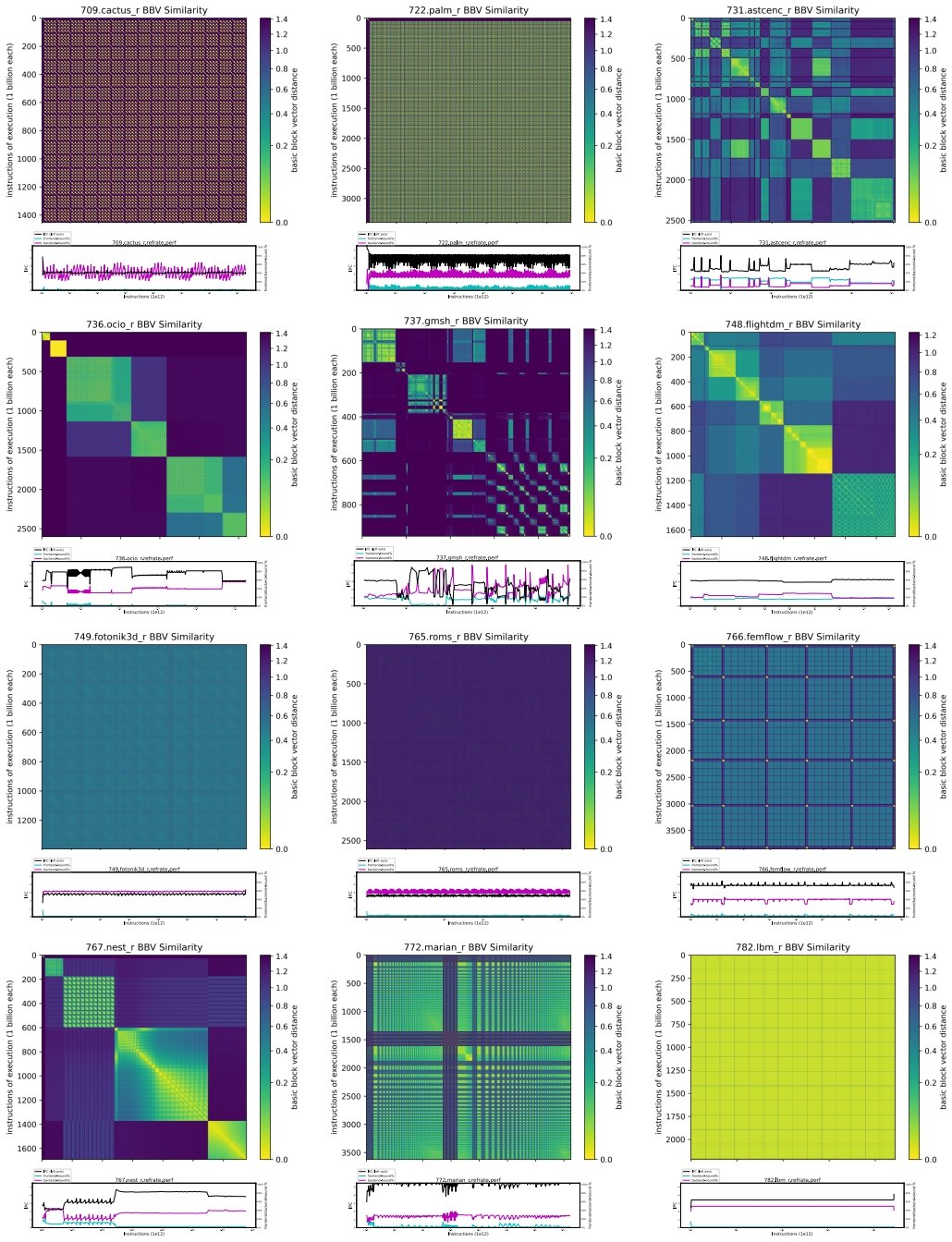


read the original abstract
The march toward developing relevant and robust CPU benchmarks continues with the introduction of SPEC CPU 2026, the next generation suite for measuring processor performance. This paper details the methodology behind its creation, showcasing a process centered on community collaboration and principled development. The suite is built upon a foundation of modern, open-source applications, selected and hardened through a process that emphasizes workload diversity, portability, and software longevity. A key contribution is Rolling-Round-Robin Rate, a novel and standardized approach to running heterogeneous, multiprogrammed workloads that addresses a long-standing gap in benchmarking practice. Additionally, the suite features an expanded set of multithreaded benchmarks and introduces workloads with distinct microarchitectural profiles, reflecting the demands of contemporary software. By detailing our principled approach to benchmark selection, adaptation, and validation, we demonstrate how the SPEC CPU 2026 suite sets the standard for performance evaluation in the next era of computer architecture research and development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the development methodology for the SPEC CPU 2026 benchmark suite. It centers on community-driven selection and hardening of modern open-source applications to ensure workload diversity, portability, and software longevity. A primary contribution is the introduction of Rolling-Round-Robin Rate, a standardized scheduling approach for heterogeneous multiprogrammed workloads. The suite also expands multithreaded benchmarks and incorporates workloads with distinct microarchitectural profiles to better reflect contemporary software demands.
Significance. If the described process and new rate-based method hold up under scrutiny, this work would provide the computer architecture community with a timely, standardized benchmark suite that addresses longstanding gaps in evaluating multiprogrammed and heterogeneous workloads. The community-collaborative, open-source foundation and focus on modern applications represent a constructive evolution of SPEC practices, potentially improving relevance for next-generation processor research.
major comments (2)
- [Abstract and methodology sections] The central claims regarding principled selection, hardening, and validation of the new suite (including workload diversity and portability) are presented as process descriptions without accompanying validation data, error-handling details, or empirical results. This is load-bearing for the assertion that SPEC CPU 2026 sets the standard for performance evaluation.
- [Section describing Rolling-Round-Robin Rate] Rolling-Round-Robin Rate is positioned as a novel solution to a benchmarking gap, yet the manuscript provides no quantitative comparison to prior scheduling approaches (e.g., standard round-robin or rate-based methods) or evidence of its standardization benefits across heterogeneous workloads.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from clearer delineation between descriptive process elements and any quantitative or falsifiable claims to help readers assess the strength of the contributions.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the potential impact of SPEC CPU 2026 and for the constructive feedback. We respond to each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and methodology sections] The central claims regarding principled selection, hardening, and validation of the new suite (including workload diversity and portability) are presented as process descriptions without accompanying validation data, error-handling details, or empirical results. This is load-bearing for the assertion that SPEC CPU 2026 sets the standard for performance evaluation.
Authors: The manuscript focuses on detailing the methodology and community-driven process for developing the SPEC CPU 2026 suite, including how applications were selected, hardened, and validated for diversity, portability, and longevity. We acknowledge that explicit validation data, error-handling procedures, and empirical results would strengthen the presentation of these claims. In the revised version, we will add a dedicated subsection in the methodology section that includes quantitative metrics from the validation process, details on error handling during hardening, and empirical evidence supporting workload diversity and portability. revision: yes
-
Referee: [Section describing Rolling-Round-Robin Rate] Rolling-Round-Robin Rate is positioned as a novel solution to a benchmarking gap, yet the manuscript provides no quantitative comparison to prior scheduling approaches (e.g., standard round-robin or rate-based methods) or evidence of its standardization benefits across heterogeneous workloads.
Authors: We agree that the manuscript would benefit from quantitative comparisons to demonstrate the advantages of Rolling-Round-Robin Rate over existing approaches. The current text introduces the method as a standardized scheduling approach for heterogeneous multiprogrammed workloads. We will revise the relevant section to include a quantitative evaluation, such as performance metrics and fairness measures across sample heterogeneous workloads, comparing it to standard round-robin and other rate-based scheduling methods. This will provide evidence of its standardization benefits. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a descriptive engineering report detailing the community-driven development process for the SPEC CPU 2026 suite, including application selection criteria and the introduction of Rolling-Round-Robin Rate as a scheduling method for heterogeneous workloads. No equations, quantitative predictions, fitted parameters, or derivations are present that could reduce by construction to inputs, self-citations, or ansatzes. The central claims rest on process descriptions and methodological choices rather than any self-referential logic, making the work self-contained without circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern open-source applications provide sufficient workload diversity, portability, and longevity to serve as the foundation for future CPU benchmarks.
invented entities (1)
-
Rolling-Round-Robin Rate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
For Better or Worse, Benchmarks Shape a Field: Technical Perspective,
D. Patterson, “For Better or Worse, Benchmarks Shape a Field: Technical Perspective,”Commun. ACM, vol. 55, no. 7, p. 104, Jul. 2012,ISSN: 0001-0782.DOI: 10.1145/2209249.2209271
-
[2]
Overview of the SPEC Benchmarks,
K. M. Dixit, “Overview of the SPEC Benchmarks,” inThe Benchmark Handbook, 1993. [Online]. Available: https : / / api . semanticscholar.org/CorpusID:6617287
1993
-
[3]
SPEC CPU2000: Measuring CPU Performance in the New Millennium,
J. L. Henning, “SPEC CPU2000: Measuring CPU Performance in the New Millennium,”Computer, vol. 33, no. 7, 28–35, Jul. 2000, ISSN: 0018-9162.DOI: 10.1109/2.869367
-
[4]
SPEC CPU2006 benchmark descriptions,
J. L. Henning, “SPEC CPU2006 benchmark descriptions,” SIGARCH Comput. Archit. News, 2006.DOI: 10 . 1145 / 1186736 . 1186737
2006
-
[5]
SPEC CPU2017: Next-Generation Compute Benchmark,
J. Bucek, K.-D. Lange, and J. v. Kistowski, “SPEC CPU2017: Next-Generation Compute Benchmark,” inCompanion of the 2018 ACM/SPEC International Conference on Performance Engineer- ing, ser. ICPE ’18, Berlin, Germany: ACM, 2018, 41–42,ISBN: 9781450356299.DOI: 10.1145/3185768.3185771
-
[6]
Munafo,The SPEC Benchmarks, 2025
R. Munafo,The SPEC Benchmarks, 2025. [Online]. Available: https: //www.mrob.com/pub/comp/benchmarks/spec.html
2025
-
[7]
: Interactive dynamics for visual analysis
A. Danowitz et al., “CPU DB: Recording Microprocessor History,” Commun. ACM, vol. 55, no. 4, 55–63, Apr. 2012,ISSN: 0001-0782. DOI: 10.1145/2133806.2133822
-
[8]
T˚ uma,Long Term Stability Observations, DaCapo Benchmark,
P. T˚ uma,Long Term Stability Observations, DaCapo Benchmark,
-
[9]
Available: https : / / github
[Online]. Available: https : / / github . com / dacapobench / dacapobench/issues/269
-
[10]
Kessler,Variance in DaCapo Benchmark, DaCapo Benchmark,
P. Kessler,Variance in DaCapo Benchmark, DaCapo Benchmark,
-
[11]
Available: https : / / github
[Online]. Available: https : / / github . com / dacapobench / dacapobench/issues/302#issuecomment-2469456922
-
[12]
A. M. Yang,Large Variance in Exec Time for scala-doku, Renais- sance Benchmark, 2019. [Online]. Available: https://github.com/ renaissance-benchmarks/renaissance/issues/175
2019
-
[13]
Bulej,Renaissance 0.16, Renaissance Benchmark, 2024
L. Bulej,Renaissance 0.16, Renaissance Benchmark, 2024. [On- line]. Available: https://renaissance.dev/2024/11/22/renaissance-0- 16-0.html
2024
-
[14]
Many Benchmarks Stress the Same Bottlenecks,
H. Vandierendonck and K. D. Bosschere, “Many Benchmarks Stress the Same Bottlenecks,” inWorkshop on Computer Architecture Evaluation Using Commercial Workloads, 2004. [Online]. Available: https://api.semanticscholar.org/CorpusID:11877774
2004
-
[15]
Y . Wang et al.,A Detailed Historical and Statistical Analysis of the Influence of Hardware Artifacts on SPEC Integer Benchmark Performance, 2024. arXiv: 2401.16690[cs.CY]
-
[16]
Wang et al.,Achieving Consistent and Comparable CPU Evalu- ation, 2025
C. Wang et al.,Achieving Consistent and Comparable CPU Evalu- ation, 2025. arXiv: 2411.08494[cs.PF]
-
[17]
[Online]
The Tukaani Project,XZ Utils. [Online]. Available: https : / / en . wikipedia.org/wiki/XZ_Utils
-
[18]
Romstad, M
T. Romstad, M. Costalba, and J. Kiiski,Stockfish: Strong open- source chess engine. [Online]. Available: https://stockfishchess.org/
-
[19]
Welty and V
C. Welty and V . Petric,NTest: A Strong Othello Program. [Online]. Available: https://github.com/vladpetric/ntest
- [20]
-
[21]
An Overview of the OMNeT++ Simu- lation Environment,
A. Varga and R. Hornig, “An Overview of the OMNeT++ Simu- lation Environment,” inProceedings of the 1st International Con- ference on Simulation Tools and Techniques for Communications, Networks and Systems & Workshops, ser. Simutools ’08, Marseille, France: ICST, 2008,ISBN: 9789639799202.DOI: 10.4108/ICST. SIMUTOOLS2008.3027 [Online]. Available: www.omnetpp.org
-
[22]
Python reference manual,
G. Rossum, “Python reference manual,” CWI (Centre for Mathemat- ics and Computer Science), Netherlands, Tech. Rep., 1995. [Online]. Available: https://ir.cwi.nl/pub/5008
1995
-
[23]
Coalson, E
J. Coalson, E. de Castro Lopo, and M. van Beurden,flac: Free Lossless Audio Codec. [Online]. Available: https://xiph.org/flac
-
[24]
Stallman,GCC, the GNU Compiler Collection
R. Stallman,GCC, the GNU Compiler Collection. [Online]. Avail- able: https://gcc.gnu.org
-
[25]
LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation
C. Lattner and V . Adve, “LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation,” inInternational Symposium on Code Generation and Optimization, 2004. CGO 2004., 2004, pp. 75–86.DOI: 10.1109/CGO.2004.1281665 [Online]. Available: www.llvm.org
-
[26]
Marjamäki,Cppcheck: a tool for static C/C++ code analysis
D. Marjamäki,Cppcheck: a tool for static C/C++ code analysis. [Online]. Available: www.cppcheck.com
-
[27]
ABC: An Academic Industrial- Strength Verification Tool,
R. Brayton and A. Mishchenko, “ABC: An Academic Industrial- Strength Verification Tool,” inComputer Aided Verification, Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 24–40,ISBN: 978-3-642-14295-6. [Online]. Available: https : / / people . eecs . berkeley.edu/~alanmi/abc/
2010
-
[28]
VTR 9: Open-Source CAD for Fabric and Beyond FPGA Architecture Exploration,
M. A. Elgammal et al., “VTR 9: Open-Source CAD for Fabric and Beyond FPGA Architecture Exploration,”ACM Trans. Reconfig- urable Technol. Syst., vol. 18, Aug. 2025,ISSN: 1936-7406.DOI: 10.1145/3734798 [Online]. Available: https://verilogtorouting.org
-
[29]
J. Lowe-Power et al., “The gem5 Simulator: Version 20.0+,” 2020. arXiv: 2007.03152. [Online]. Available: www.gem5.org
-
[30]
Sensitive protein align- ments at tree-of-life scale using DIAMOND,
B. Buchfink, K. Reuter, and H.-G. Drost, “Sensitive protein align- ments at tree-of-life scale using DIAMOND,” inNature Methods, 13 vol. 18, 2021.DOI: 10 . 1038 / s41592 - 021 - 01101 - x [Online]. Available: https://github.com/bbuchfink/diamond
2021
-
[31]
MiniZinc: Towards a Standard CP Modelling Language,
N. Nethercote et al., “MiniZinc: Towards a Standard CP Modelling Language,” inPrinciples and Practice of Constraint Programming – CP 2007, Berlin, Heidelberg: Springer, 2007, pp. 529–543,ISBN: 978-3-540-74970-7. [Online]. Available: www.minizinc.org
2007
-
[32]
Simple Encrypted Arithmetic Library - SEAL v2.1,
H. Chen, K. Laine, and R. Player, “Simple Encrypted Arithmetic Library - SEAL v2.1,” inFinancial Cryptography and Data Security, Cham: Springer International Publishing, 2017, pp. 3–18,ISBN: 978- 3-319-70278-0.DOI: 10 . 1007 / 978 - 3 - 319 - 70278 - 0 _ 1 [Online]. Available: https://github.com/Microsoft/SEAL
2017
-
[33]
The ns-3 Network Simulator,
G. F. Riley and T. R. Henderson, “The ns-3 Network Simulator,” inModeling and Tools for Network Simulation. Berlin, Heidelberg: Springer, 2010, pp. 15–34,ISBN: 978-3-642-12331-3.DOI: 10.1007/ 978-3-642-12331-3_2 [Online]. Available: www.nsnam.org
2010
-
[34]
Introducing the Graph 500,
R. C. Murphy et al., “Introducing the Graph 500,”Cray Users Group (CUG), vol. 19, no. 45-74, p. 22, 2010. [Online]. Available: https: //graph500.org
2010
-
[35]
[Online]
ZStd Community,ZStd, the C reference implementation for the ZStandard lossless compression algorithm. [Online]. Available: https://facebook.github.io/zstd
-
[36]
C. Downs et al., “A Near-real-time Data-assimilative Model of the Solar Corona,”Science, vol. 388, no. 6753, pp. 1306–1310, 2025. DOI: 10.1126/science.adq0872
-
[37]
D. Guerrera et al., “Towards a Mini-App for Smoothed Particle Hydrodynamics at Exascale,” in2018 IEEE International Confer- ence on Cluster Computing (CLUSTER), 2018, pp. 607–614.DOI: 10.1109/CLUSTER.2018.00077
-
[38]
The Cactus Framework and Toolkit: Design and Applications,
T. Goodale et al., “The Cactus Framework and Toolkit: Design and Applications,” inVECPAVector and Parallel Processing R’2002, 5th International Conference, Springer (2003), vol. 2565, Jun. 2002, ISBN: 978-3-540-00852-1.DOI: 10 . 1007 / 3 - 540 - 36569 - 9 _ 13 [Online]. Available: www.cactuscode.org
2002
-
[39]
TeaLeaf: A Mini-Application to Enable Design-Space Explorations for Iterative Sparse Linear Solvers,
S. McIntosh-Smith et al., “TeaLeaf: A Mini-Application to Enable Design-Space Explorations for Iterative Sparse Linear Solvers,” in2017 IEEE International Conference on Cluster Computing (CLUSTER), 2017, pp. 842–849.DOI: 10.1109/CLUSTER.2017.105
-
[40]
Modeling Unusual Nucleic Acid Structures,
T. J. Macke and D. A. Case, “Modeling Unusual Nucleic Acid Structures,” inMolecular Modeling of Nucleic Acids. American Chemical Society, 1997, ch. 24, pp. 379–393.DOI: 10.1021/bk- 1998-0682.ch024 [Online]. Available: https://casegroup.rutgers.edu
work page doi:10.1021/bk- 1997
-
[41]
Mantevo 3.0 Overview,
M. A. Heroux, “Mantevo 3.0 Overview,” Sandia National Lab.(SNL- NM), Albuquerque, NM (United States), Tech. Rep., 2015. [Online]. Available: https://mantevo.github.io/applications.html
2015
-
[42]
Overview of the PALM model system 6.0,
B. Maronga et al., “Overview of the PALM model system 6.0,” Geoscientific Model Development, vol. 13, no. 3, pp. 1335–1372, 2020.DOI: 10.5194/gmd-13-1335-2020 [Online]. Available: https: //docs.palm-model.com/25.04/
-
[43]
Harris,The ARM ASTC Encoder, a compressor for the Adaptive Scalable Texture Compression data format
P. Harris,The ARM ASTC Encoder, a compressor for the Adaptive Scalable Texture Compression data format. [Online]. Available: https://github.com/ARM-software/astc-encoder
-
[44]
The ASWF Takes Open- ColorIO to the Next Level,
D. Walker, M. Dolan, and P. Hodoul, “The ASWF Takes Open- ColorIO to the Next Level,” inProceedings of the 2020 Digital Production Symposium, ser. DigiPro ’20, Virtual Event, USA: ACM, 2020,ISBN: 9781450380348.DOI: 10 . 1145 / 3403736 . 3403942 [Online]. Available: www.opencolorio.org
2020
-
[45]
C. Geuzaine and J.-F. Remacle, “GMSH: A 3-D finite element mesh generator with built-in pre- and post-processing facilities,”Inter- national Journal for Numerical Methods in Engineering, vol. 79, no. 11, pp. 1309–1331, 2009.DOI: 10.1002/nme.2579 [Online]. Available: www.gmsh.info
-
[46]
JSBSim: An Open Source Flight Dynamics Model in C++,
J. Berndt, “JSBSim: An Open Source Flight Dynamics Model in C++,” inAIAA Modeling and Simulation Technologies Conference and Exhibit. AIAA Journal, 2012.DOI: 10 . 2514 / 6 . 2004 - 4923 [Online]. Available: https://github.com/JSBSim-Team/jsbsim
2012
-
[47]
Parallel power computation for photonic crystal devices,
U. Andersson, M. Qiu, and Z. Zhang, “Parallel power computation for photonic crystal devices,”Methods and Applications of Analysis, vol. 13, pp. 149–156, Jul. 2006.DOI: 10.4310/MAA.2006.v13.n2.a3
-
[48]
Scalable molecular dynamics with namd,
J. C. Phillips et al., “Scalable molecular dynamics with namd,”Jour- nal of Computational Chemistry, vol. 26, no. 16, pp. 1781–1802, 2005.DOI: 10.1002/jcc.20289 [Online]. Available: www.ks.uiuc. edu/Research/namd
-
[49]
A. F. Shchepetkin and J. C. McWilliams, “The Regional Oceanic Modeling System (ROMS): a Split-explicit, Free-surface, Topography-following-coordinate Oceanic Model,”Ocean Mod- elling, vol. 9, no. 4, 2005,ISSN: 1463-5003.DOI: 10.1016/j.ocemod. 2004.08.002 [Online]. Available: www.myroms.org
-
[50]
Kronbichler, D
M. Kronbichler, D. Sashko, and P. Munch,Enhancing data locality of the conjugate gradient method for high-order matrix-free finite- element implementations, 2022. arXiv: 2205 . 08909[cs.MS]. [Online]. Available: https://github.com/kronbichler/spec-femflow
2022
-
[51]
NEST: The Neural Simulation Tool,
H. E. Plesser et al., “NEST: The Neural Simulation Tool,” inEncy- clopedia of Computational Neuroscience. New York, NY: Springer New York, 2022, pp. 2187–2189,ISBN: 978-1-0716-1006-0.DOI: 10.1007/978-1-0716-1006-0_258 [Online]. Available: https://nest- initiative.org
-
[52]
Marian: Fast Neural Machine Trans- lation in C++,
M. Junczys-Dowmunt et al., “Marian: Fast Neural Machine Trans- lation in C++,” 2018. arXiv: 1804.00344. [Online]. Available: https: //marian-nmt.github.io
-
[53]
Optimization And Profiling Of The Cache Per- formance Of Parallel Lattice Boltzmann Codes,
T. Pohl et al., “Optimization And Profiling Of The Cache Per- formance Of Parallel Lattice Boltzmann Codes,”Parallel Process- ing Letters, vol. 13, pp. 549–560, Dec. 2003.DOI: 10 . 1142 / S0129626403001501
2003
-
[54]
Performance Analysis of a Reduced Data Movement Algorithm for Neutron Cross Section Data in Monte Carlo Simulations,
J. R. Tramm et al., “Performance Analysis of a Reduced Data Movement Algorithm for Neutron Cross Section Data in Monte Carlo Simulations,” inSolving Software Challenges for Exascale, Springer International Publishing, 2015, pp. 39–56,ISBN: 978-3- 319-15976-8.DOI: 10 . 1007 / 978 - 3 - 319 - 15976 - 8 _ 3 [Online]. Available: https://github.com/ANL-CESAR
2015
-
[55]
Comparing Performance of C Compilers Optimizations on Different Multicore Architectures,
R. S. Machado et al., “Comparing Performance of C Compilers Optimizations on Different Multicore Architectures,” in2017 In- ternational Symposium on Computer Architecture and High Perfor- mance Computing Workshops (SBAC-PADW), 2017, pp. 25–30.DOI: 10.1109/SBAC-PADW.2017.13
-
[56]
GCC vs. ICC comparison using PARSEC Benchmarks,
A. Almomany, A. Alquraan, and L. Balachandran, “GCC vs. ICC comparison using PARSEC Benchmarks,”International Jour- nal of Innovative Technology and Exploring Engineering, vol. 4, pp. 76–82, Dec. 2014. [Online]. Available: www . researchgate . net / publication / 367255416 _ GCC _ vs _ ICC _ comparison _ using _ PARSEC_Benchmarks
2014
-
[57]
K. Halbiniak et al., “Performance Exploration of Various C/C++ Compilers for AMD EPYC Processors in Numerical Modeling of Solidification,”Advances in Engineering Software, vol. 166, p. 103 078, 2022,ISSN: 0965-9978.DOI: 10 . 1016 / j . advengsoft . 2021.103078
-
[58]
SPEC CPU2017: Performance, Event, and Energy Characterization on the Core i7-8700K,
R. Hebbar S R and A. Milenkovi ´c, “SPEC CPU2017: Performance, Event, and Energy Characterization on the Core i7-8700K,” in Proceedings of the 2019 ACM/SPEC International Conference on Performance Engineering, ser. ICPE ’19, Mumbai, India: ACM, 2019, 111–118,ISBN: 9781450362399.DOI: 10 . 1145 / 3297663 . 3310314
2019
-
[59]
[On- line]
SPEC,SPEC CPU ® v8 Benchmark Search Program, 2020. [On- line]. Available: www.spec.org/cpu/cpuv8
2020
-
[60]
SPEC,Step 3 Rules of the CPUv8 Benchmark Search Program,
-
[61]
Available: www.spec.org/cpu/cpuv8/#step3
[Online]. Available: www.spec.org/cpu/cpuv8/#step3
-
[62]
[Online]
ACM,NAMD: First ACM Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research Awarded, 2020. [Online]. Available: www.acm.org/media- center/2020/november/ gordon-bell-special-prize-covid-research-2020
2020
-
[63]
[Online]
Community,JSBSim for SPEC CPU v8, JSBSim, 2023. [Online]. Available: https://github.com/JSBSim-Team/jsbsim/issues/834
2023
-
[64]
[Online]
Community,NEST for SPEC CPU v8, NEST, 2024. [Online]. Available: https://github.com/nest/nest-simulator/issues/3217
2024
-
[65]
[Online]
Academy of Motion Picture Arts and Sciences,2013 Sci-Tech Awards: Jeremy Selan for OCIO, YouTube, 2014. [Online]. Avail- able: www.youtube.com/watch?v=PMTSbvdVxnE
2013
-
[66]
[Online]
SPEC,CPU ®2026 Licenses. [Online]. Available: www.spec.org/ cpu2026/Docs/licenses.html
2026
-
[67]
Workload Design: selecting representative program-input pairs,
L. Eeckhout, H. Vandierendonck, and K. De Bosschere, “Workload Design: selecting representative program-input pairs,” inProceed- ings of International Conference on Parallel Architectures and Compilation Techniques, 2002, pp. 83–94.DOI: 10 . 1109 / PACT. 2002.1106006
-
[68]
Bartz-Beielstein et al.,Benchmarking in Optimization: Best Practice and Open Issues, 2020
T. Bartz-Beielstein et al.,Benchmarking in Optimization: Best Practice and Open Issues, 2020. arXiv: 2007.03488[cs.NE]
-
[69]
The Alberta Workloads for the SPEC CPU 2017 Benchmark Suite,
J. N. Amaral et al., “The Alberta Workloads for the SPEC CPU 2017 Benchmark Suite,” inIEEE ISPASS, 2018, pp. 159–168.DOI: 14 10.1109/ISPASS.2018.00029 [Online]. Available: https://webdocs. cs.ualberta.ca/~amaral/AlbertaWorkloadsForSPECCPU2017/
-
[70]
Evaluating the Evaluations: A Perspec- tive on Benchmarks,
O. Alonso and K. Church, “Evaluating the Evaluations: A Perspec- tive on Benchmarks,”SIGIR Forum, vol. 58, no. 2, 1–27, Mar. 2025, ISSN: 0163-5840.DOI: 10.1145/3722449.3722467
-
[71]
BetterBench: Assessing AI Benchmarks, Uncover- ing Issues, and Establishing Best Practices,
A. Reuel et al., “BetterBench: Assessing AI Benchmarks, Uncover- ing Issues, and Establishing Best Practices,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24, Vancouver, BC, Canada: Curran Associates Inc., 2024,ISBN: 9798331314385. arXiv: 2411.12990[cs.AI]
-
[74]
Wittich,Ampere Strategy and Roadmap Update, 2024
J. Wittich,Ampere Strategy and Roadmap Update, 2024. [Online]. Available: www.youtube.com/watch?v=cYrT2ohcykk&t=1404s
2024
-
[75]
Brown,AWS re:Invent 2023 - Compute innovation for any application, anywhere, 2023
D. Brown,AWS re:Invent 2023 - Compute innovation for any application, anywhere, 2023. [Online]. Available: www. youtube . com/watch?v=dxm93_qgRzk&t=2210s
2023
-
[76]
SPEC CPU Suite Growth: an Historical Perspective,
J. L. Henning, “SPEC CPU Suite Growth: an Historical Perspective,” SIGARCH Comput. Archit. News, vol. 35, no. 1, 65–68, Mar. 2007, ISSN: 0163-5964.DOI: 10.1145/1241601.1241615
-
[77]
R. Panda et al., “Wait of a Decade: Did SPEC CPU 2017 Broaden the Performance Horizon?” In2018 IEEE International Sympo- sium on High Performance Computer Architecture (HPCA), 2018, pp. 271–282.DOI: 10.1109/HPCA.2018.00032
-
[78]
DCPerf: An Open-Source, Battle-Tested Performance Benchmark Suite for Datacenter Workloads,
W. Su et al., “DCPerf: An Open-Source, Battle-Tested Performance Benchmark Suite for Datacenter Workloads,” inProceedings of the 52nd Annual International Symposium on Computer Architec- ture, ser. ISCA ’25, Tokyo, Japan: ACM, 2025, 1717–1730,ISBN: 9798400712616.DOI: 10.1145/3695053.3731411
-
[79]
MisSPECulation: Partial and Misleading Use of SPEC CPU2000 in Computer Architecture Conferences,
D. Citron, “MisSPECulation: Partial and Misleading Use of SPEC CPU2000 in Computer Architecture Conferences,” inProceedings of the 30th Annual International Symposium on Computer Architecture, San Diego, California: ACM, 2003, 52–61,ISBN: 0769519458.DOI: 10.1145/859618.859625
-
[80]
The Use and Abuse of SPEC: An ISCA Panel,
IEEE Micro staff, “The Use and Abuse of SPEC: An ISCA Panel,” IEEE Micro, vol. 23, no. 4, 73–77, Jul. 2003,ISSN: 0272-1732.DOI: 10.1109/MM.2003.1225977
-
[81]
Analysis of Redundancy and Application Balance in the SPEC CPU2006 Benchmark Suite,
A. Phansalkar, A. Joshi, and L. K. John, “Analysis of Redundancy and Application Balance in the SPEC CPU2006 Benchmark Suite,” inProceedings of the 34th Annual International Symposium on Computer Architecture, ser. ISCA ’07, San Diego, California, USA: ACM, 2007, 412–423,ISBN: 9781595937063.DOI: 10 . 1145 / 1250662.1250713
-
[82]
SPEC as a Performance Evaluation Measure,
R. Giladi and N. Ahitav, “SPEC as a Performance Evaluation Measure,”Computer, vol. 28, no. 8, pp. 33–42, 1995.DOI: 10 . 1109/2.402073
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.