Recognition: unknown
Where Do Prompt Perturbations Break Generation? A Segment-Level View of Robustness in LoRA-Tuned Language Models
Pith reviewed 2026-05-09 14:05 UTC · model grok-4.3
The pith
Segment-level alignment and drift penalization during LoRA fine-tuning improves robustness to prompt perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
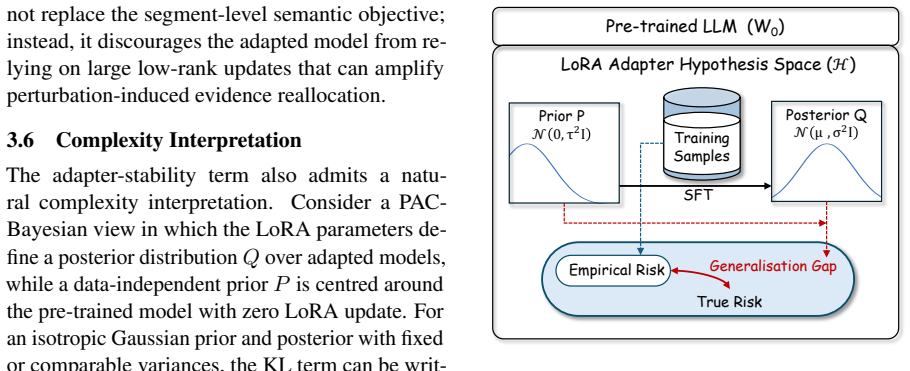
S²R² decomposes clean and perturbed generations into semantic segments, aligns them via optimal transport, penalizes the segments with largest meaning drift, and adds an adapter-stability term that uses LoRA norm control to limit perturbation-amplified evidence shifts; a PAC-Bayesian argument indicates that such control supports generalization beyond the perturbations seen during training.
What carries the argument
Optimal-transport alignment of semantic segments paired with LoRA-norm regularization inside the S²R² fine-tuning objective.
If this is right
- Robustness increases under typographical noise, deletions, synonym replacement, and paraphrasing.
- Clean summarization performance stays competitive with standard LoRA fine-tuning.
- Cross-dataset transfer improves relative to consistency-based training methods.
- Controlling adapter size offers a tractable link between output-side robustness objectives and model adaptation parameters.
Where Pith is reading between the lines
- The same segment focus could reduce factual drift on tasks that require preserving specific entities or relations.
- Limiting adapter growth might extend robustness benefits to other parameter-efficient fine-tuning techniques.
- Explicit checks on whether critical segments contain entities could further sharpen the method's effect on factual stability.
- Testing the approach on generation tasks beyond summarization would reveal whether the segment alignment generalizes.
Load-bearing premise
That penalizing the largest segment-level meaning drifts and limiting LoRA adapter growth will produce robustness gains that hold for perturbations and datasets outside those tested.
What would settle it
An experiment on a previously untested perturbation type or new domain where S²R² shows no robustness improvement over whole-sequence consistency baselines while matching or exceeding clean performance.
Figures



read the original abstract
Large language models are sensitive to minor prompt perturbations, yet existing robustness methods usually enforce consistency at the whole-sequence level. This holistic view can hide an important failure mode: a perturbed response may remain globally similar to the clean one while drifting on a critical entity, relation, or conclusion. We introduce S$^2$R$^2$, a segment-level framework for robust LoRA fine-tuning. S$^2$R$^2$ decomposes clean and perturbed generations into semantic segments, aligns them with an optimal-transport objective, and penalises the segments with the largest meaning drift. To connect this output-side objective with model adaptation, we add an adapter-stability regulariser motivated by segment-level attention reallocation, using LoRA norm control as a tractable proxy for limiting perturbation-amplified evidence shifts. A PAC-Bayesian complexity view further explains why controlling adapter growth may support transfer beyond observed perturbations. Experiments on summarisation benchmarks show that S$^2$R$^2$ improves robustness under typographical noise, deletion, synonym replacement, and paraphrasing, while maintaining competitive clean performance and stronger cross-dataset transfer than consistency-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S²R², a segment-level framework for robust LoRA fine-tuning of language models. It decomposes clean and perturbed generations into semantic segments, aligns them via optimal transport, and applies a penalty to segments with the largest meaning drift. An adapter-stability regulariser is added that uses LoRA weight-norm control as a proxy for limiting perturbation-amplified attention reallocation and evidence shifts, supported by a PAC-Bayesian argument for transfer. Experiments on summarisation benchmarks claim improved robustness to typographical noise, deletion, synonym replacement, and paraphrasing while preserving clean performance and showing stronger cross-dataset transfer than consistency-based baselines.
Significance. If the central mechanism is validated, the work offers a finer-grained alternative to whole-sequence consistency methods for prompt robustness, with the segment-level OT penalty and LoRA-norm regulariser providing a concrete way to target critical drifts rather than global similarity. The PAC-Bayesian framing supplies a theoretical grounding for why adapter-norm control may aid generalisation beyond the tested perturbations, which is a strength if the empirical link to attention reallocation holds.
major comments (3)
- [abstract and §3] The load-bearing claim that LoRA-norm control serves as a tractable proxy for limiting perturbation-amplified attention reallocation and evidence shifts (abstract and §3) is not directly tested. No attention-map comparisons, segment-level evidence-shift metrics, or ablation removing the norm term while keeping the OT penalty are reported; without this, robustness gains cannot be attributed to the intended mechanism rather than the output-side penalty alone.
- [Experiments section] The experimental results (abstract) state improvements in robustness and cross-dataset transfer but supply no quantitative numbers, error bars, statistical significance tests, or ablation tables. This makes it impossible to assess effect sizes, whether gains exceed consistency baselines by a meaningful margin, or whether post-hoc choices inflate performance.
- [abstract and theoretical section] The PAC-Bayesian complexity argument (abstract) is invoked to explain why controlling adapter growth supports transfer, yet no explicit bound, complexity term, or empirical verification linking norm control to the PAC-Bayesian quantity is provided; the argument therefore remains motivational rather than predictive.
minor comments (2)
- [§3] Notation for the segment-drift penalty and optimal-transport alignment should be introduced with explicit equations rather than descriptive prose to allow reproduction.
- [abstract] The abstract claims 'stronger cross-dataset transfer' without naming the source and target datasets or reporting the transfer metric; this detail belongs in the abstract or a dedicated table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, acknowledging gaps in the current manuscript and outlining targeted revisions to strengthen the empirical and theoretical support.
read point-by-point responses
-
Referee: [abstract and §3] The load-bearing claim that LoRA-norm control serves as a tractable proxy for limiting perturbation-amplified attention reallocation and evidence shifts (abstract and §3) is not directly tested. No attention-map comparisons, segment-level evidence-shift metrics, or ablation removing the norm term while keeping the OT penalty are reported; without this, robustness gains cannot be attributed to the intended mechanism rather than the output-side penalty alone.
Authors: We agree that the manuscript does not include direct tests such as attention-map comparisons, segment-level evidence-shift metrics, or an ablation isolating the norm regularizer from the OT penalty. The LoRA-norm term is presented as a motivated proxy based on the hypothesis of limiting perturbation-amplified attention reallocation, with the PAC-Bayesian view supplying supporting rationale for transfer. To address attribution, we will add an ablation removing the norm term (retaining only the OT penalty) and include attention-shift analysis on a representative subset of examples in the revised version. revision: yes
-
Referee: [Experiments section] The experimental results (abstract) state improvements in robustness and cross-dataset transfer but supply no quantitative numbers, error bars, statistical significance tests, or ablation tables. This makes it impossible to assess effect sizes, whether gains exceed consistency baselines by a meaningful margin, or whether post-hoc choices inflate performance.
Authors: The current manuscript presents results via tables in the experiments section, but we acknowledge the lack of error bars, statistical significance tests, and expanded ablation tables. We will revise the experiments section to include error bars from multiple random seeds, p-values for key comparisons against consistency baselines, and full ablation tables. This will enable clearer evaluation of effect sizes and robustness margins. revision: yes
-
Referee: [abstract and theoretical section] The PAC-Bayesian complexity argument (abstract) is invoked to explain why controlling adapter growth supports transfer, yet no explicit bound, complexity term, or empirical verification linking norm control to the PAC-Bayesian quantity is provided; the argument therefore remains motivational rather than predictive.
Authors: The PAC-Bayesian argument is offered as a high-level motivational framing rather than a fully derived predictive bound. We will revise the theoretical section to explicitly reference the relevant complexity term (adapter weight norm within the PAC-Bayes framework) and clarify its connection to transfer. While a complete empirical verification of the bound is beyond the current scope, we will add a sketch linking norm control to the PAC-Bayesian quantity. revision: partial
Circularity Check
No significant circularity; empirical robustness claims rest on experiments, not definitional reduction
full rationale
The paper defines S²R² via an output-side segment OT drift penalty plus a LoRA-norm adapter-stability term, then reports empirical gains on summarization benchmarks under several perturbation types. No equation or derivation reduces the measured robustness improvement to a fitted constant, to the input perturbations themselves, or to a self-citation chain. The PAC-Bayesian paragraph is presented as post-hoc motivation rather than a load-bearing uniqueness theorem. The LoRA-norm proxy for attention reallocation is an assumption whose validity is tested (or not) by the experiments; it is not smuggled in by prior self-citation as an external fact. The central result therefore remains an empirical observation rather than a quantity true by construction of the loss.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Optimal transport alignment of semantic segments captures critical meaning drift
- ad hoc to paper LoRA norm control limits perturbation-amplified evidence shifts via attention reallocation
invented entities (1)
-
S²R² framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2026 , eprint=
Chain-of-Thought as a Lens: Evaluating Structured Reasoning Alignment between Human Preferences and Large Language Models , author=. 2026 , eprint=
2026
-
[9]
2025 , eprint=
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks , author=. 2025 , eprint=
2025
-
[10]
Zhuoyun Li and Boxuan Wang and Zhenglin Huang and Qisong He and Xinmiao Huang and Guangliang Cheng and Xiaowei Huang and Yi Dong , year=. S
-
[11]
User-friendly Introduction to PAC-Bayes Bounds , volume=
Alquier, Pierre , year=. User-friendly Introduction to PAC-Bayes Bounds , volume=. Foundations and Trends® in Machine Learning , publisher=. doi:10.1561/2200000100 , number=
-
[12]
PAC-Bayesian supervised classification: the thermodynamics of statistical learning , author=. 2007 , pages=. doi:10.1214/074921707000000391 , journal=
-
[13]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[14]
2025 , eprint=
Turbulence: Systematically and Automatically Testing Instruction-Tuned Large Language Models for Code , author=. 2025 , eprint=
2025
-
[15]
IEEE Data Eng
Jindong Wang and Xixu Hu and Wenxin Hou and Hao Chen and Runkai Zheng and Yidong Wang and Linyi Yang and Wei Ye and Haojun Huang and Xiubo Geng and Binxing Jiao and Yue Zhang and Xing Xie , title=. IEEE Data Eng. Bull. , volume=. 2024 , cdate=
2024
-
[16]
Zhu, Kaijie and Zhao, Qinlin and Chen, Hao and Wang, Jindong and Xie, Xing , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2024 , issue_date =
2024
-
[17]
Advances in neural information processing systems , volume=
R-drop: Regularized dropout for neural networks , author=. Advances in neural information processing systems , volume=
-
[18]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
Hu, Zhibo and Wang, Chen and Shu, Yanfeng and Paik, Hye-Young and Zhu, Liming , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3637528.3671932 , abstract =
-
[19]
Efficient Adversarial Training in
Sophie Xhonneux and Alessandro Sordoni and Stephan G. Efficient Adversarial Training in. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[20]
Robustness of Large Language Models Against Adversarial Attacks , year=
Tao, Yiyi and Shen, Yixian and Zhang, Hang and Shen, Yanxin and Wang, Lun and Shi, Chuanqi and Du, Shaoshuai , booktitle=. Robustness of Large Language Models Against Adversarial Attacks , year=
-
[21]
2025 , eprint=
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs , author=. 2025 , eprint=
2025
-
[22]
Single Character Perturbations Break LLM Alignment , booktitle =
Leon Lin and Hannah Brown and Kenji Kawaguchi and Michael Shieh , volume =. Single Character Perturbations Break LLM Alignment , booktitle =. 2025 , doi =
2025
-
[23]
2024 , eprint=
Reasoning Robustness of LLMs to Adversarial Typographical Errors , author=. 2024 , eprint=
2024
-
[24]
2024 , eprint=
Quantifying perturbation impacts for large language models , author=. 2024 , eprint=
2024
-
[25]
CoRR , volume=
Sara Vera Marjanovic and Isabelle Augenstein and Christina Lioma , title=. CoRR , volume=. 2024 , cdate=
2024
-
[26]
2023 , eprint=
Are Large Language Models Really Robust to Word-Level Perturbations? , author=. 2023 , eprint=
2023
-
[27]
International Conference on Learning Representations , year=
Better Fine-Tuning by Reducing Representational Collapse , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Learning Representations , year=
FreeLB: Enhanced Adversarial Training for Natural Language Understanding , author=. International Conference on Learning Representations , year=
-
[29]
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy
Jiang, Haoming and He, Pengcheng and Chen, Weizhu and Liu, Xiaodong and Gao, Jianfeng and Zhao, Tuo. SMART : Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.197
-
[30]
Prompt Perturbation Consistency Learning for Robust Language Models
Qiang, Yao and Nandi, Subhrangshu and Mehrabi, Ninareh and Ver Steeg, Greg and Kumar, Anoop and Rumshisky, Anna and Galstyan, Aram. Prompt Perturbation Consistency Learning for Robust Language Models. Findings of the Association for Computational Linguistics: EACL 2024. 2024
2024
-
[31]
Proceedings of the 35th International Conference on Machine Learning , pages =
A Reductions Approach to Fair Classification , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[32]
Proceedings of the 35th International Conference on Machine Learning , pages =
Fairness Without Demographics in Repeated Loss Minimization , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Enhancing Robust Fairness via Confusional Spectral Regularization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[35]
Enhancing
Aryan Agrawal and Lisa Alazraki and Shahin Honarvar and Thomas Mensink and Marek Rei , booktitle=. Enhancing. 2025 , url=
2025
-
[36]
Proceedings of the twelfth annual conference on Computational learning theory , pages=
PAC-Bayesian model averaging , author=. Proceedings of the twelfth annual conference on Computational learning theory , pages=
-
[37]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[38]
Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003
Simplified PAC-Bayesian margin bounds , author=. Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003. Proceedings , pages=
2003
-
[39]
2017 , eprint=
Computing Nonvacuous Generalization Bounds for Deep (Stochastic) Neural Networks with Many More Parameters than Training Data , author=. 2017 , eprint=
2017
-
[40]
2012 , MONTH = Jun, KEYWORDS =
Morvant, Emilie and Ko. 2012 , MONTH = Jun, KEYWORDS =
2012
-
[41]
Asymmetry in low-rank adapters of foundation models , year =
Zhu, Jiacheng and Greenewald, Kristjan and Nadjahi, Kimia and De Oc\'. Asymmetry in low-rank adapters of foundation models , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[42]
(Not) Bounding the True Error , url =
Langford, John and Caruana, Rich , booktitle =. (Not) Bounding the True Error , url =
-
[43]
2002 , publisher=
Quantitatively tight sample complexity bounds , author=. 2002 , publisher=
2002
-
[44]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Weight Uncertainty in Neural Network , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[45]
The Annals of mathematical statistics , volume=
Statistical analysis based on a certain multivariate complex Gaussian distribution (an introduction) , author=. The Annals of mathematical statistics , volume=. 1963 , publisher=
1963
-
[46]
Implicit Regularization in Matrix Factorization , url =
Gunasekar, Suriya and Woodworth, Blake E and Bhojanapalli, Srinadh and Neyshabur, Behnam and Srebro, Nati , booktitle =. Implicit Regularization in Matrix Factorization , url =
-
[47]
Dong, Guanting and Zhao, Jinxu and Hui, Tingfeng and Guo, Daichi and Wang, Wenlong and Feng, Boqi and Qiu, Yueyan and Gongque, Zhuoma and He, Keqing and Wang, Zechen and Xu, Weiran , title =. Natural Language Processing and Chinese Computing: 12th National CCF Conference, NLPCC 2023, Foshan, China, October 12–15, 2023, Proceedings, Part I , pages =. 2023 ...
-
[48]
Efficient Adversarial Training in LLMs with Continuous Attacks , url =
Xhonneux, Sophie and Sordoni, Alessandro and G\". Efficient Adversarial Training in LLMs with Continuous Attacks , url =. Advances in Neural Information Processing Systems , editor =
-
[49]
Jason Wei and Kai Zou , year=
-
[50]
Understanding Back-Translation at Scale
Edunov, Sergey and Ott, Myle and Auli, Michael and Grangier, David. Understanding Back-Translation at Scale. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1045
-
[51]
2024 , eprint=
Enhancing Adversarial Text Attacks on BERT Models with Projected Gradient Descent , author=. 2024 , eprint=
2024
-
[52]
Proceedings of the 38th International Conference on Machine Learning , pages =
To be Robust or to be Fair: Towards Fairness in Adversarial Training , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[53]
2021 , publisher=
Topics in optimal transportation , author=. 2021 , publisher=
2021
-
[54]
Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Veselin and Zettlemoyer, Luke. BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguisti...
-
[55]
Zhao and Yanping Huang and Andrew M
Hyung Won Chung and Le Hou and Shayne Longpre and Barret Zoph and Yi Tay and William Fedus and Yunxuan Li and Xuezhi Wang and Mostafa Dehghani and Siddhartha Brahma and Albert Webson and Shixiang Shane Gu and Zhuyun Dai and Mirac Suzgun and Xinyun Chen and Aakanksha Chowdhery and Alex Castro-Ros and Marie Pellat and Kevin Robinson and Dasha Valter and Sha...
2024
-
[56]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[57]
2016 , eprint=
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond , author=. 2016 , eprint=
2016
-
[58]
S., Mubasshir, K., Li, Y.-F., Kang, Y.-B., Rahman, M
Tahmid Hasan and Abhik Bhattacharjee and Islam, Md Saiful and Kazi Samin and Yuan-Fang Li and Yong-Bin Kang and Rahman, M. Sohel and Rifat Shahriyar. XL-Sum: large-scale multilingual abstractive summarization for 44 languages. Findings of the Association for Computational Linguistics. 2021. doi:10.18653/v1/2021.findings-acl.413
-
[59]
The NCBI handbook , volume=
PubMed: the bibliographic database , author=. The NCBI handbook , volume=. 2013 , publisher=
2013
-
[60]
Morris, John and Lifland, Eli and Yoo, Jin Yong and Grigsby, Jake and Jin, Di and Qi, Yanjun. T ext A ttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. doi:10.18653/v1/2020.emnlp-demos.16
-
[61]
Miller, George A. , title =. Commun. ACM , month = nov, pages =. 1995 , issue_date =. doi:10.1145/219717.219748 , abstract =
-
[62]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[63]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[64]
Chowdhury, Souvik Dutta and Bhattacharya, Ujjwal and Parui, Swapan K. , title =. Proceedings of the 4th International Workshop on Multilingual OCR , articleno =. 2013 , isbn =. doi:10.1145/2505377.2505378 , abstract =
-
[65]
Seeger, Matthias , title =. J. Mach. Learn. Res. , month = mar, pages =. 2003 , issue_date =. doi:10.1162/153244303765208386 , abstract =
-
[66]
doi: 10.18653/v1/2021.emnlp-main.243
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[67]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[68]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[69]
Xiao Liu and Yanan Zheng and Zhengxiao Du and Ming Ding and Yujie Qian and Zhilin Yang and Jie Tang , keywords =. GPT understands, too , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.aiopen.2023.08.012 , url =
-
[70]
, booktitle =
Jiang, Yikun and Wang, Huanyu and Xie, Lei and Zhao, Hanbin and Zhang, Chao and Qian, Hui and Lui, John C.S. , booktitle =. D-LLM: A Token Adaptive Computing Resource Allocation Strategy for Large Language Models , url =
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Tapas Are Free! Training-Free Adaptation of Programmatic Agents via LLM-Guided Program Synthesis in Dynamic Environments , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i35.40189 , number=
-
[72]
Enhancing robustness of LLM-driven multi-agent systems through randomized smoothing , journal =
Jinwei HU and Yi DONG and Zhengtao DING and Xiaowei HUANG , keywords =. Enhancing robustness of LLM-driven multi-agent systems through randomized smoothing , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.cja.2025.103779 , url =
-
[73]
Artificial Intelligence Review , volume=
A survey of safety and trustworthiness of large language models through the lens of verification and validation , author=. Artificial Intelligence Review , volume=. 2024 , publisher=
2024
-
[74]
2026 , eprint=
Lying with Truths: Open-Channel Multi-Agent Collusion for Belief Manipulation via Generative Montage , author=. 2026 , eprint=
2026
-
[75]
2025 , eprint=
Stop Reducing Responsibility in LLM-Powered Multi-Agent Systems to Local Alignment , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.