Recognition: unknown
Towards Efficient and Expressive Offline RL via Flow-Anchored Noise-conditioned Q-Learning
Pith reviewed 2026-05-10 16:20 UTC · model grok-4.3
The pith
FAN achieves state-of-the-art offline RL performance using only a single flow-policy iteration and one Gaussian noise sample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
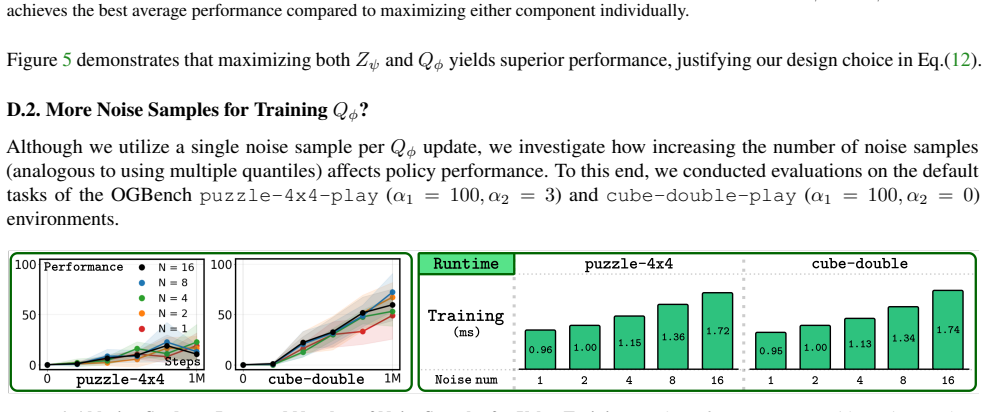
FAN employs a behavior regularization technique that utilizes only a single flow policy iteration and requires only a single Gaussian noise sample for distributional critics. Our theoretical analysis of convergence and performance bounds demonstrates that these simplifications not only improve efficiency but also lead to superior task performance. Experiments on robotic manipulation and locomotion tasks demonstrate that FAN achieves state-of-the-art performance while significantly reducing both training and inference runtimes.
What carries the argument
Flow-anchored noise-conditioned Q-learning, which anchors a single-iteration flow policy to the behavior distribution via regularization and estimates the distributional critic from one Gaussian noise sample.
Load-bearing premise
A single flow-policy iteration plus one Gaussian noise sample for the distributional critic preserves both the expressivity of full iterative flows and the accuracy of multi-sample critics without introducing bias that the behavior-regularization term cannot correct.
What would settle it
Observing that full iterative flow policies or multi-sample distributional critics achieve higher task success rates or tighter performance bounds than FAN on the same robotic manipulation or locomotion benchmarks would falsify the sufficiency claim.
Figures






read the original abstract
We propose Flow-Anchored Noise-conditioned Q-Learning (FAN), a highly efficient and high-performing offline reinforcement learning (RL) algorithm. Recent work has shown that expressive flow policies and distributional critics improve offline RL performance, but at a high computational cost. Specifically, flow policies require iterative sampling to produce a single action, and distributional critics require computation over multiple samples (e.g., quantiles) to estimate value. To address these inefficiencies while maintaining high performance, we introduce FAN. Our method employs a behavior regularization technique that utilizes only a single flow policy iteration and requires only a single Gaussian noise sample for distributional critics. Our theoretical analysis of convergence and performance bounds demonstrates that these simplifications not only improve efficiency but also lead to superior task performance. Experiments on robotic manipulation and locomotion tasks demonstrate that FAN achieves state-of-the-art performance while significantly reducing both training and inference runtimes. We release our code at https://github.com/brianlsy98/FAN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Flow-Anchored Noise-conditioned Q-Learning (FAN) for offline RL. It replaces the iterative sampling of flow policies and multi-sample (e.g., quantile) computation of distributional critics with a single flow-policy iteration and a single Gaussian noise sample, using behavior regularization to maintain performance. The central claims are that a theoretical analysis of convergence and performance bounds shows these simplifications improve both efficiency and task performance, and that experiments on robotic manipulation and locomotion tasks establish state-of-the-art results with substantially lower training and inference runtimes. Code is released at https://github.com/brianlsy98/FAN.
Significance. If the theoretical bounds are shown to hold without circularity and the empirical gains prove robust to standard offline RL evaluation protocols, FAN would offer a practical route to expressive offline RL at reduced cost. The explicit release of code supports reproducibility, which is a positive contribution to the field.
major comments (2)
- [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that single-iteration flow plus single-sample critic 'lead to superior task performance' via behavior regularization is load-bearing for the central contribution. The provided sketch does not demonstrate that the regularization term dominates the truncation error of one flow iteration and the variance of one Gaussian sample; an explicit error decomposition comparing to the full iterative flow and multi-sample critic is required to substantiate superiority rather than merely bounded degradation.
- [Abstract] Abstract: the performance bounds are asserted to follow from the simplifications, yet the weakest assumption (single flow iteration + single noise sample suffices without introducing uncorrected bias) risks circularity if the bounds are derived under exactly those same single-iteration/single-sample assumptions. An independent verification against external baselines or a multi-sample ablation is needed.
minor comments (2)
- The manuscript should clarify the precise form of the behavior-regularization term and how it is applied during the single-iteration update.
- Experimental details on the number of runs, error bars, and exact baselines (including whether they also use single-sample approximations) would strengthen the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We provide point-by-point responses to the major comments below. We believe our theoretical analysis supports the claims, but we will revise to address the concerns about explicit decompositions and clarifications on assumptions.
read point-by-point responses
-
Referee: [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that single-iteration flow plus single-sample critic 'lead to superior task performance' via behavior regularization is load-bearing for the central contribution. The provided sketch does not demonstrate that the regularization term dominates the truncation error of one flow iteration and the variance of one Gaussian sample; an explicit error decomposition comparing to the full iterative flow and multi-sample critic is required to substantiate superiority rather than merely bounded degradation.
Authors: We appreciate this observation. Our theoretical analysis in Section 4 derives performance bounds that incorporate the behavior regularization term, which is designed to mitigate the effects of the single-iteration approximation in the flow policy and the single-sample estimation in the critic. The analysis shows that the regularization ensures the overall error remains bounded and, importantly, the method achieves better empirical performance by avoiding the computational overhead that can lead to overfitting in more complex setups. To make this more rigorous and address the request for an explicit decomposition, we will add a new subsection in the revised theoretical analysis that directly compares the error terms of the simplified FAN approach to those of the full iterative flow with multi-sample critic, demonstrating how the regularization term provides the advantage for superior performance. revision: yes
-
Referee: [Abstract] Abstract: the performance bounds are asserted to follow from the simplifications, yet the weakest assumption (single flow iteration + single noise sample suffices without introducing uncorrected bias) risks circularity if the bounds are derived under exactly those same single-iteration/single-sample assumptions. An independent verification against external baselines or a multi-sample ablation is needed.
Authors: We would like to clarify that there is no circularity in our derivation. The general convergence theorem for the noise-conditioned Q-learning with behavior regularization is established first under standard assumptions for offline RL, without relying on the single-iteration or single-sample simplifications. Subsequently, we analyze the additional approximation errors introduced by using only one flow iteration and one Gaussian noise sample, providing bounds on these errors that are controlled by the regularization strength. This structure ensures the bounds are not derived under the same assumptions. For independent verification, our experiments already include extensive comparisons against state-of-the-art baselines on robotic tasks, and we have conducted ablations on the number of samples used in the critic. We will expand the experimental section to include a dedicated multi-sample ablation study to further confirm that increasing the number of samples does not yield significant gains, supporting the sufficiency of the single-sample approach. revision: partial
Circularity Check
No circularity: theoretical bounds analyze the proposed simplifications without reducing to inputs by construction
full rationale
The abstract and available description present FAN as using a single flow iteration and single Gaussian noise sample plus behavior regularization. The claimed theoretical analysis derives convergence and performance bounds for exactly this construction, showing efficiency gains and competitive or superior task performance. No equations are quoted that equate a 'prediction' to a fitted parameter, no self-citation chain is invoked as the sole justification for uniqueness or ansatz, and no renaming of known results occurs. The derivation therefore remains self-contained; external experiments on manipulation and locomotion tasks supply independent validation rather than tautological confirmation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sur les op
Banach, Stefan , journal=. Sur les op. 1922 , publisher=
1922
-
[2]
Econometrica: Journal of the Econometric Society , pages=
Asymmetric least squares estimation and testing , author=. Econometrica: Journal of the Econometric Society , pages=. 1987 , publisher=
1987
-
[3]
Machine learning , volume=
Q-learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[4]
1994 , publisher =
Markov Decision Processes: Discrete Stochastic Dynamic Programming , author =. 1994 , publisher =
1994
-
[5]
1996 , publisher =
Neuro-Dynamic Programming , author =. 1996 , publisher =
1996
-
[6]
Introduction to smooth manifolds , pages=
Smooth manifolds , author=. Introduction to smooth manifolds , pages=. 2003 , publisher=
2003
-
[7]
Proceedings of the 22nd international conference on Machine learning , pages=
Reinforcement learning with Gaussian processes , author=. Proceedings of the 22nd international conference on Machine learning , pages=
-
[8]
SIAM Journal on optimization , volume=
Robust stochastic approximation approach to stochastic programming , author=. SIAM Journal on optimization , volume=. 2009 , publisher=
2009
-
[9]
Proceedings of the 27th International Conference on Machine Learning (ICML-10) , pages=
Nonparametric return distribution approximation for reinforcement learning , author=. Proceedings of the 27th International Conference on Machine Learning (ICML-10) , pages=
-
[10]
Advances in neural information processing systems , volume=
Non-asymptotic analysis of stochastic approximation algorithms for machine learning , author=. Advances in neural information processing systems , volume=
-
[11]
Reinforcement learning: State-of-the-art , pages=
Batch reinforcement learning , author=. Reinforcement learning: State-of-the-art , pages=. 2012 , publisher=
2012
-
[12]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Gaussian Error Linear Units (GELUs)
Gaussian Error Linear Units (Gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
International conference on machine learning , pages=
A distributional perspective on reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[15]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake VanderPlas and Skye Wanderman-Milne and Qiao Zhang , title =
-
[16]
2018 , publisher =
Reinforcement Learning: An Introduction , author =. 2018 , publisher =
2018
-
[17]
Conference on learning theory , pages=
A finite time analysis of temporal difference learning with linear function approximation , author=. Conference on learning theory , pages=. 2018 , organization=
2018
-
[18]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[19]
Proceedings of the AAAI conference on artificial intelligence , volume=
Distributional reinforcement learning with quantile regression , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[20]
International conference on machine learning , pages=
Implicit quantile networks for distributional reinforcement learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[21]
International Conference on Machine Learning (ICML) , pages=
Off-policy deep reinforcement learning without exploration , author=. International Conference on Machine Learning (ICML) , pages=
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Accumulation Reduction , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[23]
Conference on learning theory , pages=
Finite-time error bounds for linear stochastic approximation andtd learning , author=. Conference on learning theory , pages=. 2019 , organization=
2019
-
[24]
Behavior Regularized Offline Reinforcement Learning
Behavior regularized offline reinforcement learning , author=. arXiv preprint arXiv:1911.11361 , year=
work page internal anchor Pith review arXiv 1911
-
[25]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review arXiv 1910
-
[26]
International Conference on Machine Learning , pages=
Statistics and samples in distributional reinforcement learning , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[27]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review arXiv 2004
-
[28]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review arXiv 2005
-
[29]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[30]
International conference on machine learning , pages=
An optimistic perspective on offline reinforcement learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[31]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[32]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[33]
arXiv preprint arXiv:2105.08140 , year=
Uncertainty weighted actor-critic for offline reinforcement learning , author=. arXiv preprint arXiv:2105.08140 , year=
-
[34]
arXiv preprint arXiv:2102.05371 , year=
Risk-averse offline reinforcement learning , author=. arXiv preprint arXiv:2102.05371 , year=
-
[35]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[36]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
work page internal anchor Pith review arXiv
-
[37]
Advances in neural information processing systems , volume=
Conservative offline distributional reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[38]
Offline q-learning on diverse multi-task data both scales and generalizes,
Offline q-learning on diverse multi-task data both scales and generalizes , author=. arXiv preprint arXiv:2211.15144 , year=
-
[39]
Offline reinforcement learning via high-fidelity generative behavior modeling
Offline reinforcement learning via high-fidelity generative behavior modeling , author=. arXiv preprint arXiv:2209.14548 , year=
-
[40]
Flow Matching for Generative Modeling
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Building Normalizing Flows with Stochastic Interpolants
Building normalizing flows with stochastic interpolants , author=. arXiv preprint arXiv:2209.15571 , year=
work page internal anchor Pith review arXiv
-
[43]
Consistency models as a rich and efficient policy class for reinforcement learning , author=. arXiv preprint arXiv:2309.16984 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
CORL: Research-oriented deep offline reinforcement learning library , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
2023 , publisher=
Distributional reinforcement learning , author=. 2023 , publisher=
2023
-
[46]
International conference on machine learning , pages=
Anti-exploration by random network distillation , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[47]
arXiv preprint arXiv:2302.08560 , year=
Dual rl: Unification and new methods for reinforcement and imitation learning , author=. arXiv preprint arXiv:2302.08560 , year=
-
[48]
Extreme q-learning: Maxent rl without entropy
Extreme q-learning: Maxent rl without entropy , author=. arXiv preprint arXiv:2301.02328 , year=
-
[49]
Offline rl with no ood actions: In-sample learning via implicit value regularization , author=. arXiv preprint arXiv:2303.15810 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Revisiting the minimalist approach to offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
work page internal anchor Pith review arXiv
-
[52]
Advances in neural information processing systems , volume=
The benefits of being distributional: Small-loss bounds for reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[53]
Advances in neural information processing systems , volume=
Trust region-based safe distributional reinforcement learning for multiple constraints , author=. Advances in neural information processing systems , volume=
-
[54]
Reasoning with latent diffusion in offline reinforcement learning.arXiv preprint arXiv:2309.06599,
Reasoning with latent diffusion in offline reinforcement learning , author=. arXiv preprint arXiv:2309.06599 , year=
-
[55]
arXiv preprint arXiv:2310.07297 , year=
Score regularized policy optimization through diffusion behavior , author=. arXiv preprint arXiv:2310.07297 , year=
-
[56]
Distributional reinforcement learning with dual expectile-quantile regression , author=. arXiv preprint arXiv:2305.16877 , year=
-
[57]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Ogbench: Benchmarking offline goal-conditioned rl , author=. arXiv preprint arXiv:2410.20092 , year=
-
[58]
Aligniql: Policy alignment in implicit q-learning through constrained optimization
Aligniql: Policy alignment in implicit q-learning through constrained optimization , author=. arXiv preprint arXiv:2405.18187 , year=
-
[59]
Stop regressing: Training value functions via classification for scalable deep rl
Stop regressing: Training value functions via classification for scalable deep rl , author=. arXiv preprint arXiv:2403.03950 , year=
-
[60]
arXiv preprint arXiv:2402.05546 , year=
Offline actor-critic reinforcement learning scales to large models , author=. arXiv preprint arXiv:2402.05546 , year=
-
[61]
arXiv preprint arXiv:2402.07198 , year=
More benefits of being distributional: Second-order bounds for reinforcement learning , author=. arXiv preprint arXiv:2402.07198 , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Diffusion-based reinforcement learning via q-weighted variational policy optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Advances in Neural Information Processing Systems , volume=
Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Advances in Neural Information Processing Systems , volume=
Diffusion policies creating a trust region for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Advances in Neural Information Processing Systems , volume=
Aligning diffusion behaviors with q-functions for efficient continuous control , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Journal of Artificial Intelligence Research , volume=
DSAC: Distributional Soft Actor-Critic for Risk-Sensitive Reinforcement Learning , author=. Journal of Artificial Intelligence Research , volume=
-
[67]
arXiv preprint arXiv:2505.13144 , year=
Temporal Distance-aware Transition Augmentation for Offline Model-based Reinforcement Learning , author=. arXiv preprint arXiv:2505.13144 , year=
-
[68]
arXiv preprint arXiv:2502.04778 , year=
Behavior-regularized diffusion policy optimization for offline reinforcement learning , author=. arXiv preprint arXiv:2502.04778 , year=
-
[69]
Flow Q - Learning , May 2025 c
Flow q-learning , author=. arXiv preprint arXiv:2502.02538 , year=
-
[70]
Horizon Reduction Makes RL Scalable , October 2025 b
Horizon Reduction Makes RL Scalable , author=. arXiv preprint arXiv:2506.04168 , year=
-
[71]
Scaling offline rl via efficient and expressive shortcut models
Scaling Offline RL via Efficient and Expressive Shortcut Models , author=. arXiv preprint arXiv:2505.22866 , year=
-
[72]
1000 layer networks for self-supervised rl: Scaling depth can enable new goal-reaching capabilities,
1000 layer networks for self-supervised rl: Scaling depth can enable new goal-reaching capabilities , author=. arXiv preprint arXiv:2503.14858 , year=
-
[73]
One-step generative policies with q-learning: A reformulation of meanflow
One-Step Generative Policies with Q-Learning: A Reformulation of MeanFlow , author=. arXiv preprint arXiv:2511.13035 , year=
- [74]
-
[75]
arXiv preprint arXiv:2510.07650 , year=
Value Flows , author=. arXiv preprint arXiv:2510.07650 , year=
-
[76]
arXiv preprint arXiv:2510.08218 , year=
Expressive Value Learning for Scalable Offline Reinforcement Learning , author=. arXiv preprint arXiv:2510.08218 , year=
-
[77]
Kwanyoung Park, Seohong Park, Youngwoon Lee, and Sergey Levine
Scalable Offline Model-Based RL with Action Chunks , author=. arXiv preprint arXiv:2512.08108 , year=
-
[78]
arXiv preprint arXiv:2512.03973 (2025)
Guided Flow Policy: Learning from High-Value Actions in Offline Reinforcement Learning , author=. arXiv preprint arXiv:2512.03973 , year=
-
[79]
arXiv preprint arXiv:2511.05005 , year=
Multi-agent Coordination via Flow Matching , author=. arXiv preprint arXiv:2511.05005 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.