Recognition: unknown
GRAVITY: Architecture-Agnostic Structured Anchoring for Long-Horizon Conversational Memory
Pith reviewed 2026-05-10 16:08 UTC · model grok-4.3
The pith
GRAVITY extracts entity profiles, causal event tuples, and topic summaries from conversations and injects them as structured anchors into prompts to improve long-horizon reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRAVITY extracts three complementary knowledge representations from raw conversational utterances: entity profiles grounded in relational graphs, temporal event tuples linked into causal traces, and cross-session topic summaries. At generation time it injects these representations into the host system's prompt as structured anchoring contexts. This approach effectively synthesizes scattered evidence into a coherent, query-relevant context without requiring any architectural modifications to the host model.
What carries the argument
GRAVITY, a generation-time module that extracts and injects entity profiles in relational graphs, causal event tuples, and topic summaries as structured anchoring contexts.
If this is right
- The method works as an add-on to any existing memory system without altering the host model's architecture or training.
- It supplies relational, temporal, and thematic structure that unstructured retrieval alone does not provide.
- The same extraction and injection steps can be reused across different host memory implementations.
- Performance gains appear on benchmarks that test long-horizon conversational reasoning.
Where Pith is reading between the lines
- If the anchoring works, future memory systems could reduce emphasis on ever-more-complex retrieval and instead invest in reliable structure extraction.
- The same three representations might help in settings beyond single-user chat, such as multi-party or task-oriented dialogues.
- Explicit injection of this kind could be tested as a lightweight alternative to full retrieval-augmented generation pipelines.
Load-bearing premise
The automatically extracted entity profiles, causal event tuples, and topic summaries must be accurate and query-relevant enough to supply net positive anchoring rather than noise or hallucinated structure.
What would settle it
Applying GRAVITY to the LongMemEval or LoCoMo benchmarks and observing no improvement or a drop in LLM-judge accuracy relative to the unstructured baseline would falsify the claim that the injected structures aid reasoning.
Figures



read the original abstract
Long-horizon conversational agents rely on memory systems with increasingly sophisticated retrieval mechanisms. However, retrieved fragments are typically fed to the language model as unstructured text, lacking the relational, temporal, and thematic structures essential for complex reasoning. To bridge this reasoning gap, we introduce GRAVITY (\textbf{G}eneration-time \textbf{R}elational \textbf{A}nchoring \textbf{V}ia \textbf{I}njected \textbf{T}opological Memor\textbf{Y}), a plug-and-play structured memory module. GRAVITY extracts three complementary knowledge representations from raw conversational utterances: entity profiles grounded in relational graphs, temporal event tuples linked into causal traces, and cross-session topic summaries. At generation time, it injects these representations into the host system's prompt as structured anchoring contexts. This approach effectively synthesizes scattered evidence into a coherent, query-relevant context without requiring any architectural modifications to the host model. Extensive evaluations across five diverse memory systems on the LongMemEval and LoCoMo benchmarks demonstrate the efficacy of our approach. On average, GRAVITY improves LLM-judge accuracy by 7.5--10.1%. Gains are inversely correlated with baseline strength: the weakest host improves by 12.2% while the strongest still gains 3.8--5.7%. These findings establish structured context anchoring as a broadly effective, architecture-agnostic augmentation paradigm for long-horizon conversational memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRAVITY, a plug-and-play structured memory module for long-horizon conversational agents. It extracts three complementary representations from raw utterances—relational entity profiles grounded in graphs, causal event tuples linked into traces, and cross-session topic summaries—and injects them as structured anchoring contexts into any host memory system at generation time. Evaluations across five diverse memory systems on LongMemEval and LoCoMo benchmarks report average LLM-judge accuracy gains of 7.5–10.1%, with larger improvements (up to 12.2%) for weaker baselines and smaller but positive gains (3.8–5.7%) for stronger ones.
Significance. If the reported gains are attributable to the structured representations providing coherent, query-relevant context rather than extraneous factors, GRAVITY would constitute a significant architecture-agnostic augmentation for conversational memory systems. The multi-host evaluation and the inverse correlation between baseline strength and improvement provide evidence of broad applicability. The work explicitly demonstrates the value of synthesizing scattered conversational evidence into relational, temporal, and thematic structures without modifying host architectures.
major comments (3)
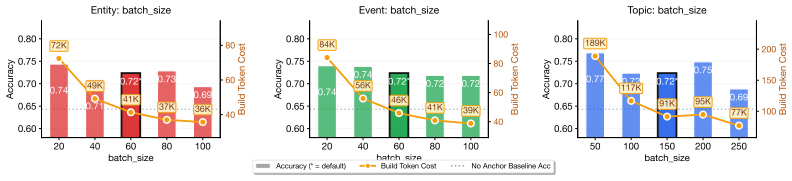
- [§5 (Experiments)] §5 (Experiments): No ablation studies, human validation, or quantitative metrics are provided for the accuracy of the automatically extracted entity profiles, causal event tuples, or topic summaries. This is load-bearing for the central claim, as the 7.5–10.1% LLM-judge gains cannot be confidently attributed to structured anchoring if extraction errors introduce noise or hallucinations.
- [§5.2 (Results)] §5.2 (Results): The paper reports LLM-judge accuracy improvements but provides no details on whether the LLM judge correlates with human judgments, no statistical significance tests for the gains, and no error propagation analysis. Without these, the efficacy claims on LongMemEval and LoCoMo rest on an unverified assumption.
- [§4 (Method)] §4 (Method): The extraction process for the three structured representations is described at a high level without specifics on prompts, query-relevance filtering, or handling of extraction failures. This leaves open whether the injected contexts are net positive or merely increase prompt length.
minor comments (2)
- [Abstract] The acronym expansion for GRAVITY is given in the title but omitted from the abstract, reducing immediate clarity for readers.
- [Tables] Table captions and result presentations would benefit from explicit listing of the five host systems and their baseline characteristics to better support the inverse-correlation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional validation and detail will strengthen the paper's claims. We address each major comment below and outline the specific revisions we will make.
read point-by-point responses
-
Referee: §5 (Experiments): No ablation studies, human validation, or quantitative metrics are provided for the accuracy of the automatically extracted entity profiles, causal event tuples, or topic summaries. This is load-bearing for the central claim, as the 7.5–10.1% LLM-judge gains cannot be confidently attributed to structured anchoring if extraction errors introduce noise or hallucinations.
Authors: We agree that direct validation of extraction quality is important for confidently attributing gains to the structured representations. While the multi-host evaluation and inverse correlation between baseline strength and improvement provide supporting evidence that the structures are net beneficial, we will add ablation studies isolating each representation type (relational, temporal, thematic) in the revised experiments section. We will also include human validation on a sampled subset of extractions, reporting quantitative metrics such as precision and recall for entity profiles and event tuples. revision: yes
-
Referee: §5.2 (Results): The paper reports LLM-judge accuracy improvements but provides no details on whether the LLM judge correlates with human judgments, no statistical significance tests for the gains, and no error propagation analysis. Without these, the efficacy claims on LongMemEval and LoCoMo rest on an unverified assumption.
Authors: We acknowledge these gaps in validation. In the revision, we will add a human correlation study on a subset of LongMemEval and LoCoMo examples to measure agreement between the LLM judge and human accuracy assessments. We will also include statistical significance testing (e.g., paired tests) for all reported gains. Additionally, we will provide an error propagation discussion analyzing how extraction inaccuracies could affect final results. revision: yes
-
Referee: §4 (Method): The extraction process for the three structured representations is described at a high level without specifics on prompts, query-relevance filtering, or handling of extraction failures. This leaves open whether the injected contexts are net positive or merely increase prompt length.
Authors: We will expand Section 4 with the exact prompts used for each extraction component, details on the query-relevance filtering mechanism (including any scoring or LLM-based selection), and procedures for handling extraction failures such as low-confidence cases or fallbacks to raw utterances. To demonstrate net positivity, we will add an analysis comparing performance gains against the modest increase in prompt length, showing benefits from structure rather than length alone. revision: yes
Circularity Check
No circularity: empirical augmentation evaluated on external benchmarks
full rationale
The paper introduces GRAVITY as a plug-and-play module that extracts entity profiles, causal tuples, and topic summaries from conversations and injects them as structured context. Its central claims rest on reported accuracy gains (7.5-10.1%) across five host systems on the independent LongMemEval and LoCoMo benchmarks. No equations, parameter fits, self-definitional loops, or load-bearing self-citations appear in the derivation; the method is presented as an architecture-agnostic engineering augmentation whose value is measured externally rather than by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conversational utterances contain extractable relational graphs, causal temporal tuples, and cross-session topic summaries that remain useful when injected as structured context.
Reference graph
Works this paper leans on
-
[1]
Budzianowski, T.-H
P. Budzianowski, T.-H. Wen, B.-H. Tseng, I. Casanueva, S. Ultes, O. Ramadan, and M. Gaši´c. Multiwoz – a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue mod- elling. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016–5026, 2018
2018
- [2]
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
J. Fang, X. Deng, H. Xu, Z. Jiang, Y . Tang, Z. Xu, S. Deng, Y . Yao, M. Wang, S. Qiao, H. Chen, and N. Zhang. Lightmem: Lightweight and efficient memory-augmented generation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[6]
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. At- tariyan, and S. Gelly. Parameter-efficient transfer learning for nlp. InInternational Conference on Machine Learning, pages 2790–2799, 2019
2019
-
[8]
arXiv preprint arXiv:2511.01448 , year=
Z. Huang, Z. Tian, Q. Guo, F. Zhang, Y . Zhou, D. Jiang, Z. Xie, and X. Zhou. Licomemory: Lightweight and cognitive agentic memory for efficient long-term reasoning.arXiv preprint arXiv:2511.01448, 2025
-
[9]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
- [10]
-
[11]
Maharana, D.-H
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y . Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[12]
MemGPT: Towards LLMs as Operating Systems
C. Packer, V . Fang, S. Patil, K. Lin, S. Wooders, and J. Gonzalez. Memgpt: towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[14]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
P. Rasmussen, P. Paliychuk, T. Beauvais, J. Ryan, and D. Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
P. Sarthi, S. Abdullah, A. Tuli, S. Khanna, A. Goldie, and C. D. Manning. Raptor: Recursive abstractive processing for tree-organized retrieval.arXiv preprint arXiv:2401.18059, 2024
-
[16]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[17]
Y . Sun, K. Sun, Y . E. Xu, X. Yang, X. L. Dong, N. Tang, and L. Chen. Kerag: Knowledge- enhanced retrieval-augmented generation for advanced question answering. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 6194–6216, 2025. 10
2025
-
[18]
Y . Sun, K. Sun, X. Yang, and N. Tang. Knowledge internalized in llms. InHandbook on Neurosymbolic AI and Knowledge Graphs, pages 230–255. SAGE Publications 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP, 2025
2025
-
[19]
Y . Sun, H. Xin, K. Sun, Y . E. Xu, X. Yang, X. L. Dong, N. Tang, and L. Chen. Are large language models a good replacement of taxonomies?Proc. VLDB Endow., 17(11):2919–2932, July 2024
2024
- [20]
-
[21]
W. Wang, L. Dong, H. Cheng, X. Liu, X. Yan, J. Gao, and F. Wei. Augmenting language models with long-term memory.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[22]
D. Wu, H. Wang, W. Yu, Y . Zhang, K.-W. Chang, and D. Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
J. Xu, A. Szlam, and J. Weston. Beyond goldfish memory: Long-term open-domain conversation. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 5180–5197, 2022
2022
-
[24]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang. A-mem: Agentic memory for LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
X. Yang, K. Sun, H. Xin, Y . Sun, N. Bhalla, X. Chen, S. Choudhary, R. D. Gui, Z. W. Jiang, Z. Jiang, et al. Crag-comprehensive rag benchmark.Advances in Neural Information Processing Systems, 37:10470–10490, 2024
2024
-
[26]
A Survey on the Memory Mechanism of Large Language Model based Agents
Z. Zhang, X. Zhang, Y . Wang, S. Sun, D. He, D. Li, et al. A survey on the memory mechanism of large language model based agents.arXiv preprint arXiv:2404.13501, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
diminishing marginal returns
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang. Memorybank: Enhancing large language models with long-term memory.Proceedings of the AAAI Conference on Artificial Intelligence, 2024. 11 A Technical appendices and supplementary material A.1 Detailed Introduction of Datasets, Metrics, and Baselines LoCoMo.LoCoMo [ 11] is a benchmark for evaluating very long-...
2024
-
[28]
e n t i t y _ n a m e : A canonical , n o r m a l i z e d name
-
[29]
e n t i t y _ t y p e : One of [ person , concept , task , event , item , location , organization , other ]
-
[30]
a t t r i b u t e s : Key - value pairs of p r o p e r t i e s d i s c o v e r e d in this segment
-
[31]
r e l a t i o n s : C o n n e c t i o n s to other en ti tie s found in this segment
-
[32]
s t a t u s _ c h a n g e s : Any state t r a n s i t i o n s o bs er ved
-
[33]
ent it ie s
s o u r c e _ i d : The s e q u e n c e _ n u m b e r of the message where this entity info was found Input format : --- Topic X --- [ timestamp , weekday ] s o u r c e _ i d . S p e a k e r N a m e : message ... Output format ( JSON ) : { " ent it ie s ": [ { " s o u r c e _ i d ": < int > , " e n t i t y _ n a m e ": " < c a n o n i c a l name >" , " e ...
-
[35]
Extract ALL entities , even minor ones
-
[36]
If the same entity appears in mul ti pl e messages , create s ep ar ate entries ( they will be merged later ) . 22
-
[37]
For people : always include their r e l a t i o n s h i p to the speaker if m e n t i o n e d
-
[38]
For events : include te mp ora l i n f o r m a t i o n ( when it hap pe ne d / will happen )
-
[39]
P re se rv e sp ec ifi c details : full names , exact dates , s pec if ic l o c a t i o n s
-
[40]
events
Do NOT invent i n f o r m a t i o n not present in the text . Anchor Building: Event Extraction.Events are extracted as structured 4W1O tuples (Who, What, When, Where, Outcome). You are a ** S t r u c t u r e d Event Tuple E x t r a c t o r **. Your job is to read c o n v e r s a t i o n s eg men ts and extract every notable event as a ** s t r u c t u r ...
-
[42]
Extract ALL events ( c o m p l e t e n e s s > p r e c i s i o n )
-
[43]
P re se rv e EXACT t em po ral details
-
[44]
If the same event spans mu lt ip le messages , produce ONE entry
-
[45]
For plans / future events , use e v e n t _ t y p e =" plan "
-
[46]
routine
For r e c u r r i n g activities , use e v e n t _ t y p e =" routine "
-
[47]
topics
Do NOT invent i n f o r m a t i o n absent from the text . Anchor Building: Topic Identification.Utterances are assigned to semantic topics that may span multiple sessions. 23 You are a ** C o n v e r s a t i o n Topic I d e n t i f i e r **. Your job is to read a seq ue nc e of c o n v e r s a t i o n u t t e r a n c e s and assign each u t t e r a n c e...
-
[49]
Use descriptive , sp ec if ic topic labels
-
[50]
If the same subject is d i s c u s s e d in d i f f e r e n t sessions , they belong to the SAME topic
-
[51]
Casual c o n v e r s a t i o n / g r e e t i n g s
Greetings , small talk -> " Casual c o n v e r s a t i o n / g r e e t i n g s " topic
-
[52]
A topic should have at least 2 u t t e r a n c e s
-
[53]
Aim for 5 -15 topics per c o n v e r s a t i o n
-
[54]
ent it ie s
Order topics by their first a p p e a r a n c e in the c o n v e r s a t i o n . Anchor Building: Triple Extraction (Entity + Event + Topic).A single LLM call extracts entities, events, and topic assignments, reducing token cost by 75%. You are a ** Co mb in ed Entity , Event , and Topic E x t r a c t o r **. Your task is to read c o n v e r s a t i o n s...
-
[55]
Process mes sa ge s st ri ct ly in a s c e n d i n g s o u r c e _ i d order
-
[56]
Extract ALL en tit ie s and events
-
[57]
Every u t t e r a n c e MUST be as si gne d to exactly one topic
-
[58]
e nti ti es
The output MUST contain " e nti ti es " , " events " , and " topics "
-
[59]
Context Injection: Answer Generation.This is the online prompt presented to the LLM at inference time
Do NOT invent i n f o r m a t i o n not present in the text . Context Injection: Answer Generation.This is the online prompt presented to the LLM at inference time. It fusesboththe host system’s retrieved raw memories and the structured anchor contexts. Placeholders {speaker_1_memories}, {speaker_2_memories} are the host’s retrieved memory snippets; {topi...
-
[60]
** Topic S u m m a r i e s ** -- high - level s u m m a r i e s of c o n v e r s a t i o n topics
-
[61]
** Entity Pr of ile s ** -- s t r u c t u r e d i n f o r m a t i o n about key e nti ti es
-
[62]
** S t r u c t u r e d Event Tuples & Traces ** -- ( Who , What , When , Where , Outcome ) # I N S T R U C T I O N S :
-
[63]
C a r e f u l l y analyze all p ro vid ed mem or ie s from both spe ak er s
-
[64]
Pay special a t t e n t i o n to t i m e s t a m p s to d e t e r m i n e the answer
-
[65]
Use Topic S u m m a r i e s for the BIG PICTURE
-
[66]
Use Entity P ro fi les for entity - spe ci fi c details
-
[67]
Use S t r u c t u r e d Event Tuples for precise te mp or al i n f o r m a t i o n
-
[68]
Cross - r e f e r e n c e across ALL sources for the most c omp le te answer
-
[69]
If m em or ies contain c o n t r a d i c t o r y information , p r i o r i t i z e the most recent
-
[70]
Convert rel at iv e time r e f e r e n c e s to sp ec if ic dates
-
[71]
Focus only on the content of the m em or ie s
-
[72]
# AP PR OA CH ( Think step by step ) :
The answer should be less than 5 -6 words . # AP PR OA CH ( Think step by step ) :
-
[73]
First , examine all mem or ie s related to the qu es ti on
-
[74]
Examine t i m e s t a m p s and content c a r e f u l l y
-
[75]
Check Topic S u m m a r i e s for r el ev ant high - level context
-
[76]
Check Entity Pr of il es for s t r u c t u r e d i n f o r m a t i o n
-
[77]
Check Event Tuples and Traces for tem po ra l details
-
[78]
S y n t h e s i z e i n f o r m a t i o n from all sources
-
[79]
The architecture-agnostic and portable design lowers the barrier for practitioners to adopt structured memory augmentation without re-engineering existing systems
F o r m u l a t e a precise , concise answer based solely on the e vi de nce Me mo ri es for user { s p e a k e r _ 1 _ n a m e }: { s p e a k e r _ 1 _ m e m o r i e s } Me mo ri es for user { s p e a k e r _ 2 _ n a m e }: { s p e a k e r _ 2 _ m e m o r i e s } 25 Topic S u m m a r i e s : { t o p i c _ c o n t e x t } Entity P ro fil es : { e n t i t ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.