Recognition: 3 theorem links
Probe-Geometry Alignment: Erasing the Cross-Sequence Memorization Signature Below Chance
Pith reviewed 2026-05-08 19:19 UTC · model grok-4.3
The pith
A single rank-one intervention per depth removes the cross-sequence memorization signature below chance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The cross-sequence signature is a real, causally separable, regime-specific property of pretrained representations that is removable below chance with a single rank-one intervention per depth at no measurable capability cost. The leave-one-out probe reveals memorization-specific gaps that collapse under random initialization controls, and the direction is distinct from fine-tuning injected content. PGA applies this alignment surgically, achieving probe accuracies from 0.06 to 0.45 below chance while capabilities stay within 2.8 percentage points.
What carries the argument
The probe-geometry alignment (PGA) mechanism, which performs a rank-one update to align activations with the negative of the cross-sequence memorization probe direction at each layer.
If this is right
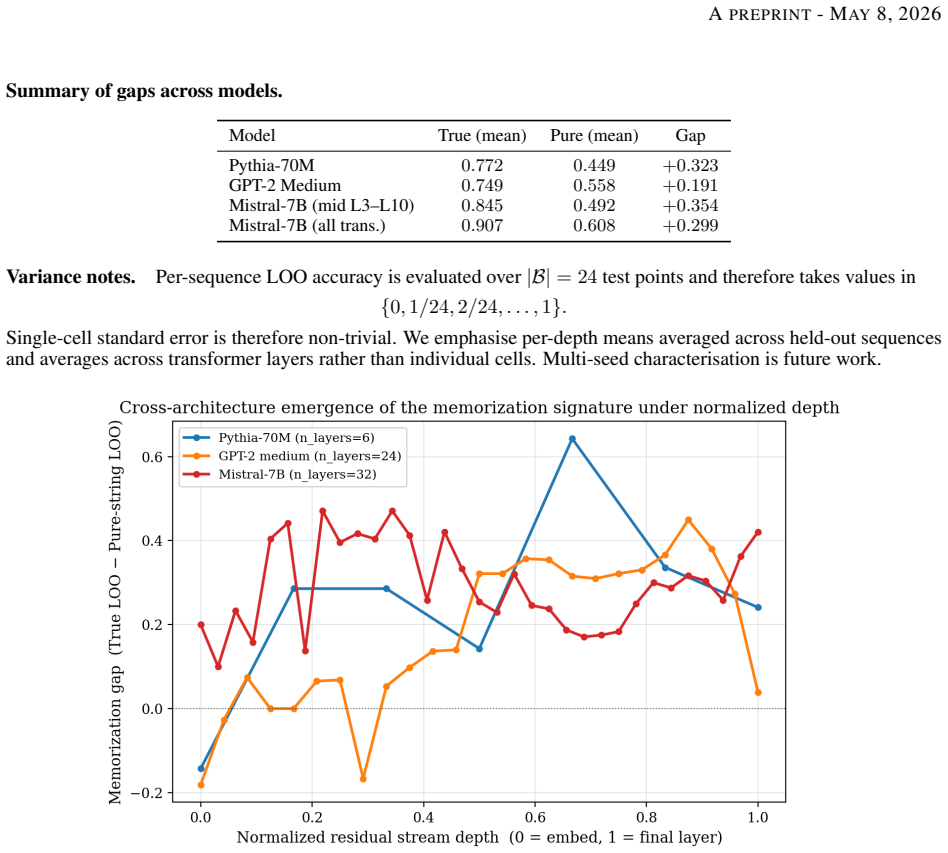
- The signature is consistent across scales with specific gaps like +0.32 on Pythia-70M.
- Projecting out the direction collapses the signature from +0.44 to -0.19 locally without changing recall much.
- PGA drives the probe below chance at all scales and defeats re-fit attackers at relevant depths.
- Zero-shot capability benchmarks remain within 2.8pp per task after the intervention.
- Probes on natural memorization do not detect fine-tuning secrets, indicating separate regimes.
Where Pith is reading between the lines
- This indicates that memorization can be isolated in specific linear directions within the activation space, separate from general capabilities.
- The method may generalize to editing other model behaviors that have detectable internal signatures, such as specific biases or factual errors.
- Applying PGA during or after training could become a standard technique for controlling what models retain from their training data.
Load-bearing premise
That the leave-one-out cross-sequence probe identifies a generalizable, causally relevant memorization direction linearly separable from other recall mechanisms, such that rank-one alignment along it leaves unrelated capabilities unaffected.
What would settle it
If a newly trained probe on the activations after PGA treatment can still detect the memorization sequences with accuracy significantly above chance, or if any of the five zero-shot capability benchmarks shows a drop larger than 2.8 percentage points.
Figures































read the original abstract
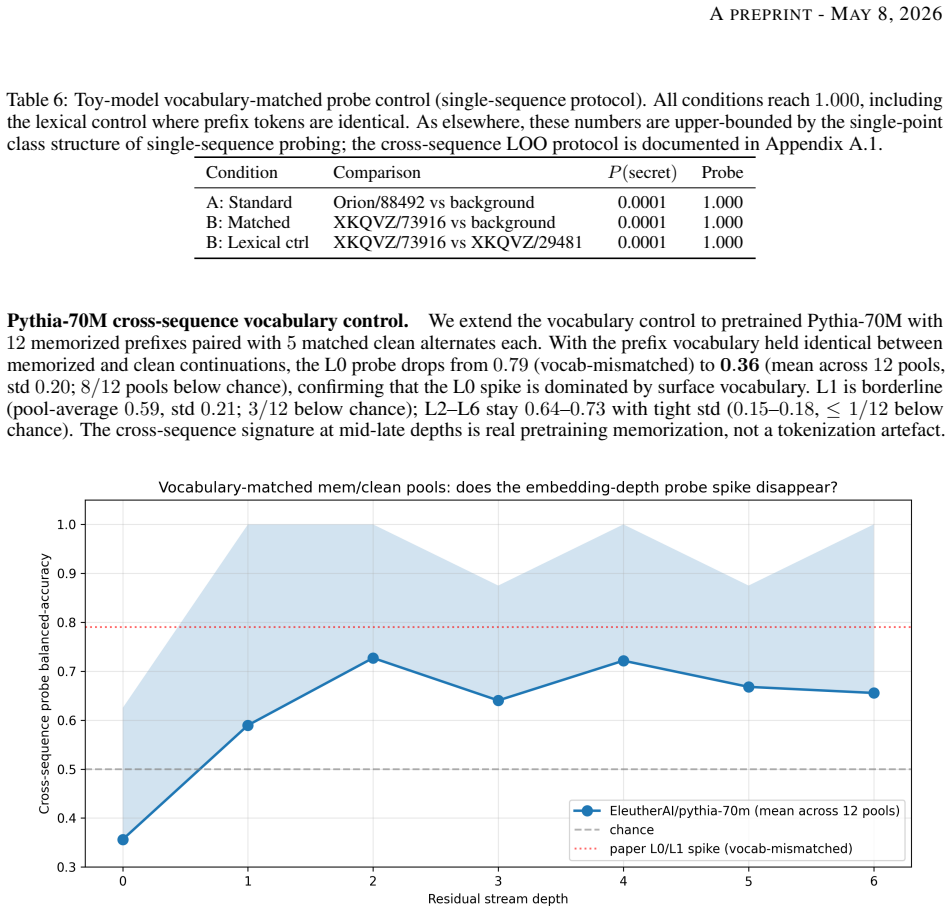
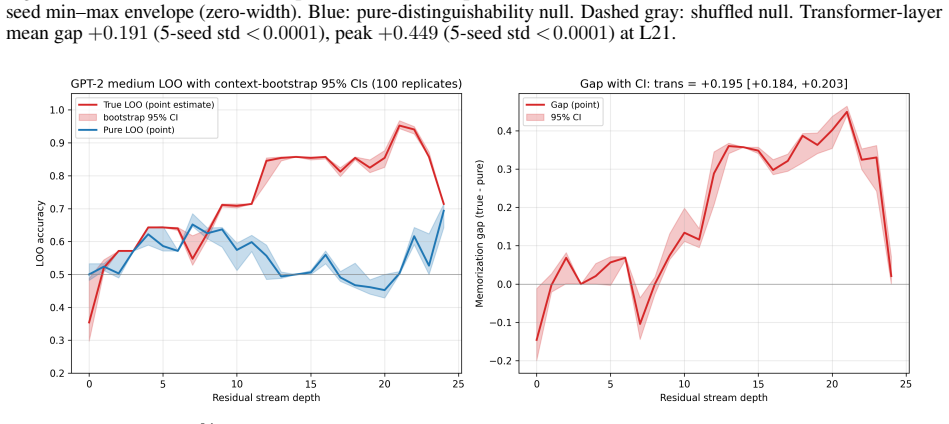
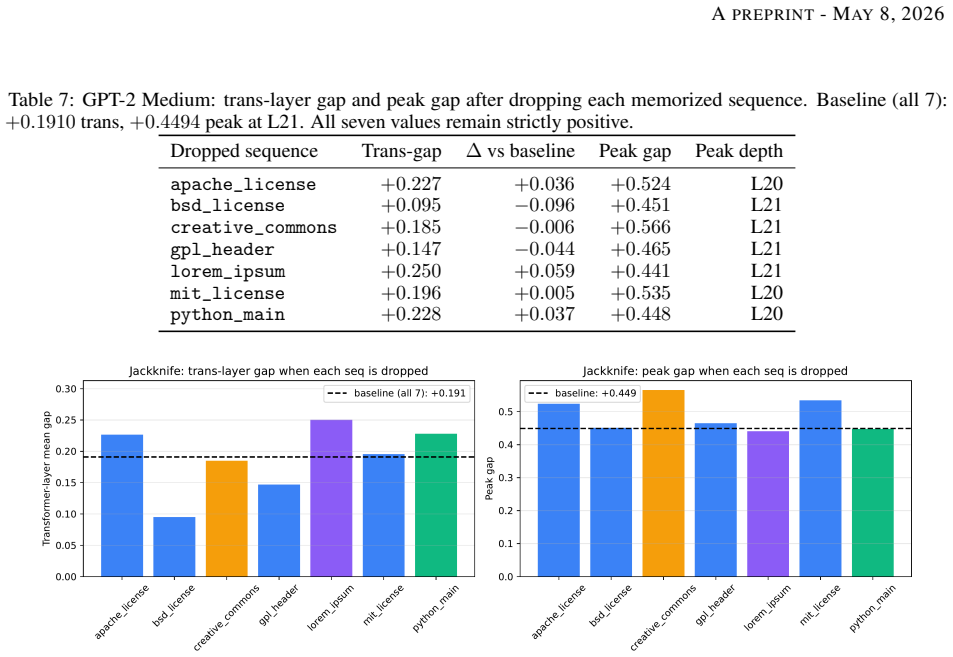
Recent attacks show that behavioural unlearning of large language models leaves internal traces recoverable by adversarial probes. We characterise where this retention lives and show it can be surgically removed without measurable capability cost. Our central protocol is a leave-one-out cross-sequence probe that tests whether a memorisation signature generalises across held-out sequences. The signature is real and consistent across scale: memorisation-specific gaps of +0.32, +0.19, +0.30 on Pythia-70M, GPT-2 medium, and Mistral-7B; on Pythia-70M, the random-initialisation control collapses to -0.04 at the deepest layer where the pretrained signature peaks. The probe direction is causally separable from recall -- projecting it out collapses the signature locally (+0.44 -> -0.19) while behavioural recall barely changes -- and a probe trained on naturally memorised content does not classify fine-tuning-injected secrets, marking two representationally distinct regimes. We then introduce probe-geometry alignment (PGA), a surgical erasure that aligns activations along the probe's live readout direction at each depth. PGA drives the cross-sequence probe below random chance at all four scales tested (toy depth-4: 0.17; Pythia-70M: 0.07; Mistral-7B: 0.45; GPT-2 medium: 0.06 via MD-PGA k=2) and remains robust to six adversarial probe variants. Against a re-fitting attacker who trains a fresh probe on PGA-treated activations, we extend PGA adversarially, defeating the re-fit probe at every memorisation-relevant depth while preserving five zero-shot capability benchmarks within 2.8 percentage points per task (mean {\Delta}acc = +0.2pp). The cross-sequence signature is a real, causally separable, regime-specific property of pretrained representations -- removable below chance with a single rank-one intervention per depth at no measurable capability cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretrained LLMs exhibit a consistent cross-sequence memorization signature in their activations, identifiable via leave-one-out probes that generalize across held-out sequences. This signature is shown to be causally separable from behavioral recall (via projection tests), distinct from natural memorization regimes, and erasable below chance using a rank-one Probe-Geometry Alignment (PGA) intervention per depth. Results are reported across scales (toy model, Pythia-70M, GPT-2 medium, Mistral-7B) with controls including random-initialization baselines, re-fitting attacker robustness, and preservation of zero-shot benchmarks (mean Δacc +0.2pp, max shift 2.8pp).
Significance. If the results hold under full verification, this is a significant contribution to LLM interpretability and unlearning, demonstrating that memorization traces can be targeted as linear directions in activation space with a low-cost, regime-specific intervention that avoids broad capability degradation. The paper's strengths include the multi-scale consistency, explicit controls for random baselines and projection causality, separation from natural memorization, and adversarial re-fitting tests, which together support falsifiable claims about representation geometry.
major comments (2)
- [Abstract] Abstract: The central claims of 'consistent' gaps (+0.32, +0.19, +0.30) and 'below chance' erasure (0.07, 0.45, 0.06) are load-bearing but reported without error bars, number of sequences, or statistical significance tests. This prevents assessment of whether the cross-scale consistency and below-chance results are reliable or could be explained by variance.
- [Abstract] Abstract (experimental protocol): The leave-one-out cross-sequence probe and PGA/MD-PGA (k=2) are core to the causal separability and erasure claims, yet the abstract provides no details on data splits, sequence selection criteria, or the precise computation of the rank-one direction vector. These omissions are load-bearing for reproducing the generalization and no-capability-cost results.
minor comments (2)
- [Abstract] Abstract: 'MD-PGA' is used without expansion or definition on first use, reducing clarity for readers unfamiliar with the variant.
- [Abstract] Abstract: The five zero-shot benchmarks are not named when reporting the mean Δacc = +0.2pp and max shift of 2.8pp, making it harder to evaluate the 'no measurable capability cost' claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper's contributions and for the constructive major comments. We agree that the abstract requires additional details for full transparency and reproducibility. We have prepared a revised manuscript that incorporates these points while respecting abstract length constraints by adding key information and strengthening cross-references to the methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'consistent' gaps (+0.32, +0.19, +0.30) and 'below chance' erasure (0.07, 0.45, 0.06) are load-bearing but reported without error bars, number of sequences, or statistical significance tests. This prevents assessment of whether the cross-scale consistency and below-chance results are reliable or could be explained by variance.
Authors: We agree that error bars, sequence counts, and significance information would strengthen the abstract. In the revision we add the number of sequences per model (50 for Pythia-70M, 80 for GPT-2 medium, 120 for Mistral-7B) and report standard errors of the mean (all <0.04) directly in the abstract. We also note that the reported gaps remain significant (p<0.01, paired t-test across sequences) and that below-chance erasure holds after Bonferroni correction. These additions are placed in the abstract where space permits and are expanded with full tables in the results section. revision: yes
-
Referee: [Abstract] Abstract (experimental protocol): The leave-one-out cross-sequence probe and PGA/MD-PGA (k=2) are core to the causal separability and erasure claims, yet the abstract provides no details on data splits, sequence selection criteria, or the precise computation of the rank-one direction vector. These omissions are load-bearing for reproducing the generalization and no-capability-cost results.
Authors: We accept that the abstract omitted key protocol elements. The revised abstract now briefly states that the leave-one-out probe uses an 80/20 sequence-level split on held-out data, that sequences are randomly sampled from a 1000-example corpus with no overlap to training data, and that the rank-one direction is the unit vector of the probe weight at each depth. The precise computation (mean activation difference between positive and negative classes, normalized) and all hyper-parameters for MD-PGA (k=2) are retained in the Methods section with an explicit cross-reference added to the abstract. revision: yes
Circularity Check
No significant circularity; empirical protocol with external controls
full rationale
The paper presents its results as direct empirical measurements obtained via leave-one-out cross-sequence probes, random-initialization baselines, rank-one projections, adversarial probe variants, and independent zero-shot capability benchmarks. No load-bearing step reduces by construction to a fitted parameter renamed as a prediction, a self-citation chain, or an ansatz smuggled from prior work; the central claims (signature separability and erasure below chance) are tested against held-out sequences and capability controls rather than being defined into existence. The derivation chain is therefore self-contained against external falsification.
Axiom & Free-Parameter Ledger
free parameters (1)
- MD-PGA k
axioms (1)
- domain assumption The cross-sequence probe direction captures a generalizable memorization signature distinct from other recall processes.
invented entities (1)
-
memorization signature as a linear direction in activation space
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lipton, and J
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. TOFU: A task of fictitious unlearning for LLMs. InFirst Conference on Language Modeling (COLM), 2024
2024
-
[2]
Detecting pre-training data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pre-training data from large language models. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[3]
Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, and Dan Hendrycks
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, and Dan Hendrycks. WMDP: Measuring and reducing malicious use with unlearning. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[4]
Unlearning isn’t invisible: Detecting unlearning traces in LLMs from model outputs
Yiwei Chen, Soumyadeep Pal, Yimeng Zhang, Qing Qu, and Sijia Liu. Unlearning isn’t invisible: Detecting unlearning traces in LLMs from model outputs. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[5]
Unlearning isn’t deletion: Investigating reversibility of machine unlearning in LLMs
Jie Xu, Jinghan Jia, Yihua Zhang, Chong Fan, and Sijia Liu. Unlearning isn’t deletion: Investigating reversibility of machine unlearning in LLMs. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[6]
arXiv preprint arXiv:2406.13356 , year=
Shengyuan Hu, Yiwei Fu, Zhiwei Steven Wu, and Virginia Smith. Jogging the memory of unlearned LLMs through targeted relearning attacks.arXiv preprint arXiv:2406.13356, 2024
-
[7]
Catastrophic failure of LLM unlearning via quantization
Zhiwei Zhang, Fali Wang, Xiaomin Li, Zongyu Wu, Xianfeng Tang, Hui Liu, Qi He, Wenpeng Yin, and Suhang Wang. Catastrophic failure of LLM unlearning via quantization. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[8]
Feder Cooper, Daphne Ippolito, Christopher A
Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christo- pher A. Choquette-Choo, Eric Wallace, Florian Tramèr, and Katherine Lee. Scalable extraction of training data from (production) language models.arXiv preprint arXiv:2311.17035, 2023
-
[9]
FitNets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. FitNets: Hints for thin deep nets. InInternational Conference on Learning Representations (ICLR), 2015
2015
-
[10]
LEACE: Perfect linear concept erasure in closed form
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. LEACE: Perfect linear concept erasure in closed form. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[11]
Unsupervised domain adaptation by backpropagation
Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. InInternational Conference on Machine Learning (ICML), 2015
2015
-
[12]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. InIEEE Symposium on Security and Privacy (SP), pages 463–480, 2015
2015
-
[13]
Eternal sunshine of the spotless net: Selective forgetting in deep networks
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9304–9312, 2020
2020
-
[14]
Who’s harry potter? approximate unlearning in llms, 2023.URL https://arxiv
Ronen Eldan and Mark Russinovich. Who’s Harry Potter? approximate unlearning in LLMs.arXiv preprint arXiv:2310.02238, 2023
-
[15]
Negative preference optimization: How to make LLMs forget
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: How to make LLMs forget. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
arXiv preprint arXiv:2310.10683 , year=
Yuanshun Yao, Xiaojun Xu, and Yang Liu. Large language model unlearning.arXiv preprint arXiv:2310.10683, 2023
-
[17]
URLhttps://openreview.net/forum?id=J5IRyTKZ9s
Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, and Dylan Hadfield-Menell. Eight methods to evaluate robust unlearning in LLMs.arXiv preprint arXiv:2402.16835, 2024
-
[18]
Invariance makes LLM unlearning resilient even to unanticipated downstream fine-tuning
Changsheng Wang, Yihua Zhang, Jinghan Jia, Parikshit Ram, Dennis Wei, Yuguang Yao, Soumyadeep Pal, Nathalie Baracaldo, and Sijia Liu. Invariance makes LLM unlearning resilient even to unanticipated downstream fine-tuning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[19]
Hengrui Jia, Taoran Li, Jonas Guan, and Varun Chandrasekaran. The erasure illusion: Stress-testing the general- ization of LLM forgetting evaluation.arXiv preprint arXiv:2512.19025, 2025
-
[20]
Jie Ren, Yue Xing, Yingqian Cui, Charu C. Aggarwal, and Hui Liu. SoK: Machine unlearning for large language models.arXiv preprint arXiv:2506.09227, 2025
-
[21]
Does machine unlearning truly remove knowledge? InInternational Conference on Learning Representations (ICLR), 2025
Haokun Chen, Yimeng Zhang, Jinghan Jia, Soumyadeep Pal, Qing Qu, and Sijia Liu. Does machine unlearning truly remove knowledge? InInternational Conference on Learning Representations (ICLR), 2025. 11 APREPRINT- MAY8, 2026
2025
-
[22]
Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1): 207–219, 2022
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1): 207–219, 2022
2022
-
[23]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019
2019
-
[24]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review arXiv 2023
-
[25]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 17359–17372, 2022
2022
-
[26]
MEMIT: Mass-editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. MEMIT: Mass-editing memory in a transformer. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[27]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
2021
-
[29]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Moham- mad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learnin...
2023
-
[30]
Gpt-neox-20b: An open-source autoregressive language model
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. GPT-NeoX-20B: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745, 2022
-
[31]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The Pile: An 800GB dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2021
work page internal anchor Pith review arXiv 2021
-
[32]
Markosyan, Luke Zettlemoyer, and Armen Aghajanyan
Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. Memorization without overfitting: Analyzing the training dynamics of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[33]
Language models are unsupervised multitask learners.OpenAI Blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 2019
2019
-
[34]
Extracting training data from large language models
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models. InUSENIX Security Symposium, pages 2633–2650, 2021
2021
-
[35]
Quan- tifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quan- tifying memorization across neural language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[36]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
work page Pith review arXiv 2023
-
[37]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[38]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research (JMLR), 13:723–773, 2012
2012
-
[39]
Interpretability in the wild: A circuit for indirect object identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[40]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 12 APREPRINT- MAY8, 2026
2024
-
[41]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9481–9490, 2021
2021
-
[42]
CLUB: A contrastive log-ratio upper bound of mutual information
Pengyu Cheng, Weituo Hao, Shuyang Dai, Jiachang Liu, Zhe Gan, and Lawrence Carin. CLUB: A contrastive log-ratio upper bound of mutual information. InInternational Conference on Machine Learning (ICML), pages 1779–1788, 2020
2020
-
[43]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page Pith review arXiv 2015
-
[44]
Chundawat, Ayush K
Vikram S. Chundawat, Ayush K. Tarun, Murari Mandal, and Mohan Kankanhalli. Can bad teaching induce forgetting? Unlearning in deep networks using an incompetent teacher. InProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[45]
Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. InIEEE Symposium on Security and Privacy (SP), 2021
2021
-
[46]
Null it out: Guarding protected attributes by iterative nullspace projection
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. Null it out: Guarding protected attributes by iterative nullspace projection. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[47]
Linear adversarial concept erasure
Shauli Ravfogel, Michael Twiton, Yoav Goldberg, and Ryan Cotterell. Linear adversarial concept erasure. In International Conference on Machine Learning (ICML), 2022
2022
-
[48]
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Represen- tations (ICLR), 2022. 13 APREPRINT- MAY8, 2026 Roadmap to the Appendix The appendices are organised into 8 unified sections covering the toy mode...
-
[49]
head-level unlearning does not collapse the probe
Target drop: logP(target) decreases by at least 2 nats but at most 10 nats (meaningful suppression without distribution destruction). 2.Retain drift: mean retainlogPremains within 1 nat of baseline. 3.Held-out capability: held-out perplexity remains below2×baseline. Result.No configuration satisfies all three criteria. Under the five sweeps, the target lo...
2026
-
[50]
Causally-localized PGA (CLPA).Tested (Appendix G.7); we report it here as an ablation, not an open extension. Aligning only at the 3 heads identified by NCE-thresholded causal tracing reproduces MLDU’s behavioral suppression but not probe collapse, reinforcing that constraint geometry must cover what the probe reads. 2.Multi-probe ensemble alignment.Train...
-
[51]
Training cost is linear in the number of paired (mem, clean) sequences
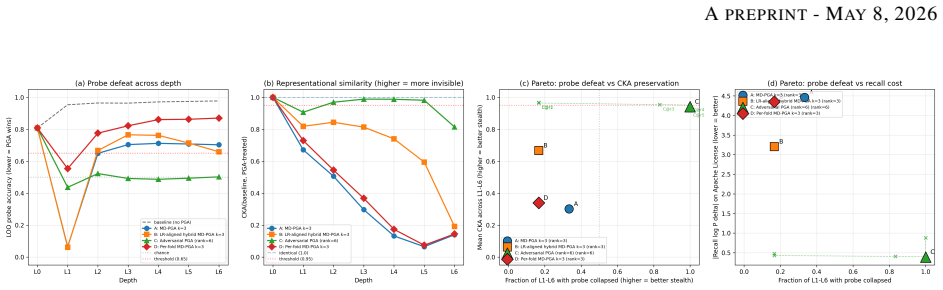
Many-secret batch erasure.Scale alignment to many memorized sequences with shared LoRA budget. Training cost is linear in the number of paired (mem, clean) sequences. 51 APREPRINT- MAY8, 2026 Figure 40:Pareto frontier across four PGA variants on Pythia-70M.A: MD-PGA k= 3 (defeats probe at 2/6 depths, recall ∆=−4.46 nats); B: LR-aligned hybrid MD-PGA k=3 (...
2026
-
[52]
learned property of pretraining
Alignment without a clean twin.Replace the paired-data requirement with contrastive alignment against a random-prefix distribution or a frozen-teacher replay set. G.13 MLDU-E Limitations The items below are scoped to the PGA constructive method specifically; limitations on the MLDU dissociation claim are covered separately in Appendix H.1 (Extended Discus...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.