Recognition: unknown
SignVerse-2M: A Two-Million-Clip Pose-Native Universe of 55+ Sign Languages
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
SignVerse-2M supplies two million pose sequences spanning 55 sign languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
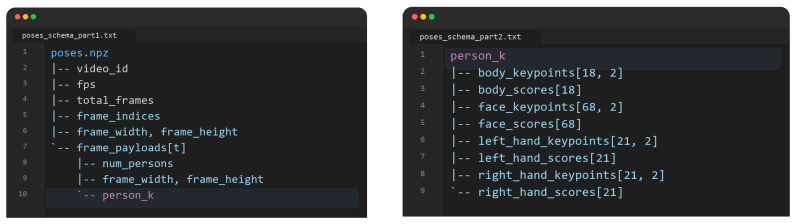
By applying a single DWPose preprocessing step to videos from many sources, the authors produce a consolidated set of roughly two million clips from over 55 sign languages in the form of 2D pose sequences that preserve speaker and recording diversity.
What carries the argument
The DWPose unified preprocessing pipeline that converts raw sign language videos into standardized 2D pose sequences.
If this is right
- Modern pose-guided generation models can use the sequences as direct control input.
- The dataset enables evaluation of sign language systems in open-world settings.
- Multilingual modeling becomes feasible in a shared pose space.
- Appearance variations are reduced without losing linguistic content from real-world sources.
Where Pith is reading between the lines
- Models trained on this data might generalize better to unseen video conditions than those relying on RGB.
- Future work could extend the pipeline to 3D poses or include more languages from additional public sources.
- Combining this with text annotations from the original videos could support end-to-end sign translation pipelines.
Load-bearing premise
That DWPose produces pose sequences that retain all necessary information for sign language understanding without language-specific biases or losses from varying video qualities.
What would settle it
Training a sign language recognition model on the pose data and finding substantially lower accuracy than on the original videos, or visual inspection revealing missing hand configurations critical to signs.
Figures




read the original abstract
Existing large-scale sign language resources typically provide supervision only at the level of raw video-text alignment and are often produced in laboratory settings. While such resources are important for semantic understanding, they do not directly provide a unified interface for open-world recognition and translation, or for modern pose-driven sign language video generation frameworks: 1. RGB-based pretrained recognition models depend heavily on fixed backgrounds or clothing conditions during recording, and are less robust in open-world settings than style-agnostic pose-processing models. 2. Recent pose-guided image/video generation models mostly use a unified keypoint representation such as DWPose as their control interface. At present, the sign language field still lacks a data resource that can directly interface with this modern pose-native paradigm while also targeting real-world open scenarios. We present SignVerse-2M, a large-scale multilingual pose-native dataset for sign language pose modeling and evaluation. Built from publicly available multilingual sign language video resources, it applies DWPose in a unified preprocessing pipeline to convert raw videos into 2D pose sequences that can be used directly for modeling, resulting in a consolidated corpus of about two million clips covering more than 55 sign languages. Unlike many laboratory datasets, this resource preserves the recording conditions and speaker diversity of real-world videos while reducing appearance variation through a unified pose representation. Toward this goal, we further provide the data construction pipeline, task definitions, and a simple SignDW Transformer baseline, demonstrating the feasibility of this resource for multilingual pose-space modeling and its compatibility with modern pose-driven pipelines, while discussing the evaluation claims it can support as well as its current limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SignVerse-2M, a consolidated dataset of approximately two million 2D pose sequences extracted via a unified DWPose pipeline from publicly available videos spanning more than 55 sign languages. It positions the resource as a pose-native alternative to raw-video datasets, suitable for open-world sign-language modeling, recognition, translation, and pose-driven generation, while providing the construction pipeline, task definitions, a SignDW Transformer baseline, and discussion of supported evaluations and limitations.
Significance. If the extracted poses are shown to retain the fine-grained handshapes, non-manual signals, and language-specific kinematics required for sign languages, the dataset would provide a valuable large-scale, multilingual, real-world resource that directly interfaces with modern pose-conditioned models, reducing appearance bias while preserving recording diversity.
major comments (3)
- [Abstract / construction pipeline] Abstract and pipeline description: the central claim that DWPose extraction yields 'information-preserving' 2D pose sequences 'suitable for open-world sign language tasks' is unsupported by any quantitative evidence. No per-keypoint error rates, hand/face failure rates, or cross-language/cross-condition comparisons against manual annotations or alternative estimators are reported, leaving the assumption that semantic content is retained untested.
- [Baseline experiments / evaluation claims] Baseline and evaluation discussion: the SignDW Transformer is presented as demonstrating feasibility for multilingual pose-space modeling, yet no ablation studies, comparisons to RGB baselines or other pose estimators, or metrics on open-world robustness (e.g., viewpoint/lighting variation) are provided to substantiate superiority or usability claims.
- [Data construction pipeline] Data construction: the manuscript states that public videos introduce 'uncontrolled variation in resolution, viewpoint, lighting, clothing, and signer demographics' but does not quantify how these factors affect DWPose output quality or whether any filtering/quality control steps mitigate differential degradation across the 55+ languages.
minor comments (2)
- [Dataset statistics] Clarify the exact number of clips and languages with a breakdown table (by language family or source) to allow readers to assess coverage balance.
- [Task definitions] The abstract mentions 'task definitions' but the manuscript should explicitly list the supported downstream tasks (e.g., pose-to-text, pose-to-video) with example input/output formats.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. We address each major comment below, indicating where we agree that revisions are warranted and where the scope of the current work limits what can be provided.
read point-by-point responses
-
Referee: [Abstract / construction pipeline] Abstract and pipeline description: the central claim that DWPose extraction yields 'information-preserving' 2D pose sequences 'suitable for open-world sign language tasks' is unsupported by any quantitative evidence. No per-keypoint error rates, hand/face failure rates, or cross-language/cross-condition comparisons against manual annotations or alternative estimators are reported, leaving the assumption that semantic content is retained untested.
Authors: We acknowledge that the manuscript provides no new quantitative validation of DWPose specifically on sign-language data. The phrasing 'information-preserving' is intended to reflect the established role of DWPose as the control interface in recent pose-driven generation models rather than a claim of zero information loss. We will revise the abstract and pipeline section to remove the stronger phrasing and instead cite existing evaluations of DWPose on hand and face keypoints from general benchmarks. A new limitations paragraph will be added discussing known challenges of 2D pose estimation for fine handshapes and non-manual signals in sign languages. We cannot supply per-keypoint error rates or cross-language manual-annotation comparisons, as these would require fresh annotation campaigns outside the scope of the dataset release. revision: partial
-
Referee: [Baseline experiments / evaluation claims] Baseline and evaluation discussion: the SignDW Transformer is presented as demonstrating feasibility for multilingual pose-space modeling, yet no ablation studies, comparisons to RGB baselines or other pose estimators, or metrics on open-world robustness (e.g., viewpoint/lighting variation) are provided to substantiate superiority or usability claims.
Authors: The SignDW Transformer is presented strictly as a minimal baseline to show that the pose sequences can be ingested by a standard transformer architecture and support basic multilingual modeling. We do not claim superiority over RGB methods or provide robustness metrics. In revision we will clarify this intent in the baseline section, tone down any implied usability claims, and add an explicit statement that comprehensive ablations and open-world robustness evaluations are left for future work. No new experiments will be added. revision: partial
-
Referee: [Data construction pipeline] Data construction: the manuscript states that public videos introduce 'uncontrolled variation in resolution, viewpoint, lighting, clothing, and signer demographics' but does not quantify how these factors affect DWPose output quality or whether any filtering/quality control steps mitigate differential degradation across the 55+ languages.
Authors: We agree that the manuscript does not quantify the impact of recording variations on pose quality nor describe any per-language quality filtering. The pipeline was deliberately kept lightweight to preserve the real-world diversity of the source videos. We will expand the data-construction section with a short paragraph stating that no aggressive quality filtering was applied and that differential degradation across languages remains an open question. This will be framed as a limitation of the current release. revision: yes
- Quantitative per-keypoint or cross-language validation of DWPose against manual sign-language annotations
Circularity Check
No circularity: dataset construction paper with external pipeline and no derivations
full rationale
This is a data resource paper whose central contribution is the description of a preprocessing pipeline that applies the publicly available DWPose estimator to existing public sign-language video corpora. No mathematical derivations, predictions, fitted parameters, or first-principles results are present. The construction steps are explicitly procedural and reference external tools and sources rather than reducing to self-defined quantities or self-citations. The provided baseline model is described only at a high level without equations or training details that could create circularity. All claims remain grounded in the stated data sources and pipeline, satisfying the criteria for a self-contained, non-circular resource paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DWPose provides sufficiently accurate and consistent 2D pose estimation for sign language videos across diverse real-world conditions and languages.
Reference graph
Works this paper leans on
-
[1]
Matyáš Boháˇcek and Marek Hrúz
URLhttps://arxiv.org/abs/2312.02702. Matyáš Boháˇcek and Marek Hrúz. Sign pose-based transformer for word-level sign language recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, pages 182–191, January
-
[2]
Necati Cihan Camgöz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden
doi: 10.1109/CVPR.2018.00812. Necati Cihan Camgöz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. Neural Sign Language Translation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
-
[3]
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu
URL https://arxiv.org/abs/1808.07371. Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010,
-
[4]
Gang Cheng, Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Ju Li, Dechao Meng, Jinwei Qi, Penchong Qiao, et al. Wan-animate: Unified character animation and replacement with holistic replication.arXiv preprint arXiv:2509.14055,
-
[5]
Signllm: Sign language production large language models
Sen Fang, Chen Chen, Lei Wang, Ce Zheng, Chunyu Sui, and Yapeng Tian. Signllm: Sign language production large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 6622–6634, October 2025a. Sen Fang, Yalin Feng, Hongbin Zhong, Yanxin Zhang, and Dimitris N. Metaxas. Stable signer: Hierarchical si...
-
[6]
Extensions of the sign language recognition and translation corpus rwth-phoenix-weather
Jens Forster, Christoph Schmidt, Oscar Koller, Martin Bellgardt, and Hermann Ney. Extensions of the sign language recognition and translation corpus rwth-phoenix-weather. InProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 1911–1916,
1911
-
[7]
Hamid Reza Vaezi Joze and Oscar Koller. Ms-asl: A large-scale data set and benchmark for understanding american sign language.arXiv preprint arXiv:1812.01053,
-
[8]
Oscar Koller. Quantitative Survey of the State of the Art in Sign Language Recognition.arXiv preprint arXiv:2008.09918,
-
[9]
MediaPipe: A Framework for Building Perception Pipelines
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. Mediapipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172,
work page internal anchor Pith review arXiv 1906
-
[10]
Follow your pose: Pose-guided text-to-video generation using pose-free videos
URL https://arxiv.org/ abs/2304.01186. Wenyi Mo, Tianyu Zhang, Yalong Bai, Ligong Han, Ying Ba, and Dimitris N. Metaxas. Prefgen: Multimodal preference learning for preference-conditioned image generation,
-
[11]
Amit Moryossef and Mathias Müller
URL https://arxiv.org/abs/ 2512.06020. Amit Moryossef and Mathias Müller. Sign language datasets. https://github.com/ sign-language-processing/datasets,
-
[12]
B leu: a method for automatic evaluation of machine translation
Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URLhttps://aclanthology.org/P02-1040. William Peebles and Saining Xie. Scalable diffusion models with transformers,
-
[13]
Scalable Diffusion Models with Transformers
URL https://arxiv. org/abs/2212.09748. Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming-Chang Yang, and Jiaya Jia. Controlnext: Powerful and efficient control for image and video generation,
work page internal anchor Pith review arXiv
-
[14]
URLhttps://arxiv.org/abs/2408.06070. Manny Rayner, Pierrette Bouillon, Sarah Ebling, Johanna Gerlach, Irene Strasly, and Nikos Tsourakis. An open web platform for rule-based speech-to-sign translation. In54th Annual Meeting of the Association for Computational Linguistics, volume 2, pages 162–168,
-
[15]
Everybody sign now: Translating spoken language to photo realistic sign language video, 2020a
11 Ben Saunders, Necati Cihan Camgoz, and Richard Bowden. Everybody sign now: Translating spoken language to photo realistic sign language video, 2020a. URLhttps://arxiv.org/abs/2011.09846. Ben Saunders, Necati Cihan Camgöz, and Richard Bowden. Progressive Transformers for End-to-End Sign Language Production. InProceedings of the European Conference on Co...
-
[16]
Open-domain sign language translation learned from online video.Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing,
Bowen Shi, Diane Brentari, Greg Shakhnarovich, and Karen Livescu. Open-domain sign language translation learned from online video.Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing,
2022
-
[17]
Stephanie Stoll, Necati Cihan Camgöz, Simon Hadfield, and Richard Bowden
URL https://arxiv.org/ abs/2511.22940. Stephanie Stoll, Necati Cihan Camgöz, Simon Hadfield, and Richard Bowden. Text2Sign: Towards Sign Language Production using Neural Machine Translation and Generative Adversarial Networks.International Journal of Computer Vision (IJCV),
-
[18]
URL https://arxiv.org/abs/2512.16776. David Uthus, Garrett Tanzer, and Manfred Georg. YouTube-ASL: A large-scale, open-domain american sign language-english parallel corpus,
-
[19]
Zhendong Yang, Ailing Zeng, Chun Yuan, and Yu Li
URLhttps://arxiv.org/abs/2508.06951. Zhendong Yang, Ailing Zeng, Chun Yuan, and Yu Li. Effective whole-body pose estimation with two-stages distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4210–4220,
-
[20]
Lvmin Zhang and Maneesh Agrawala
URL https://arxiv.org/abs/2406.07119. Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models,
-
[21]
Controlvideo: Training-free controllable text-to-video generation
URLhttps://arxiv.org/abs/2305.13077. 12 Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, and Fangyuan Zou. Mimicmotion: High-quality human motion video generation with confidence-aware pose guidance,
-
[22]
URL https: //arxiv.org/abs/2406.19680. Hao Zhou, Wen gang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. Improving sign language translation with monolingual data by sign back-translation.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1316–1325,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.