Recognition: unknown
Remote Action Generation: Remote Control with Minimal Communication
Pith reviewed 2026-05-09 16:19 UTC · model grok-4.3
The pith
A controller steers remote actors with far less data by sending sparse guidance that lets actors sample actions locally and learn the shared policy over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Guided Remote Action Sampling Policy (GRASP) lets a controller transmit only sparse guidance information instead of full actions; actors then locally sample actions from the controller's evolving target policy via importance sampling and simultaneously use the guidance as supervised data to learn an accurate local copy of that policy, progressively reducing communication volume throughout the interactive learning and control process.
What carries the argument
Guided Remote Action Sampling Policy (GRASP) that combines importance sampling for local action generation with actor-side supervised learning of the controller's policy from the received sparse signals.
If this is right
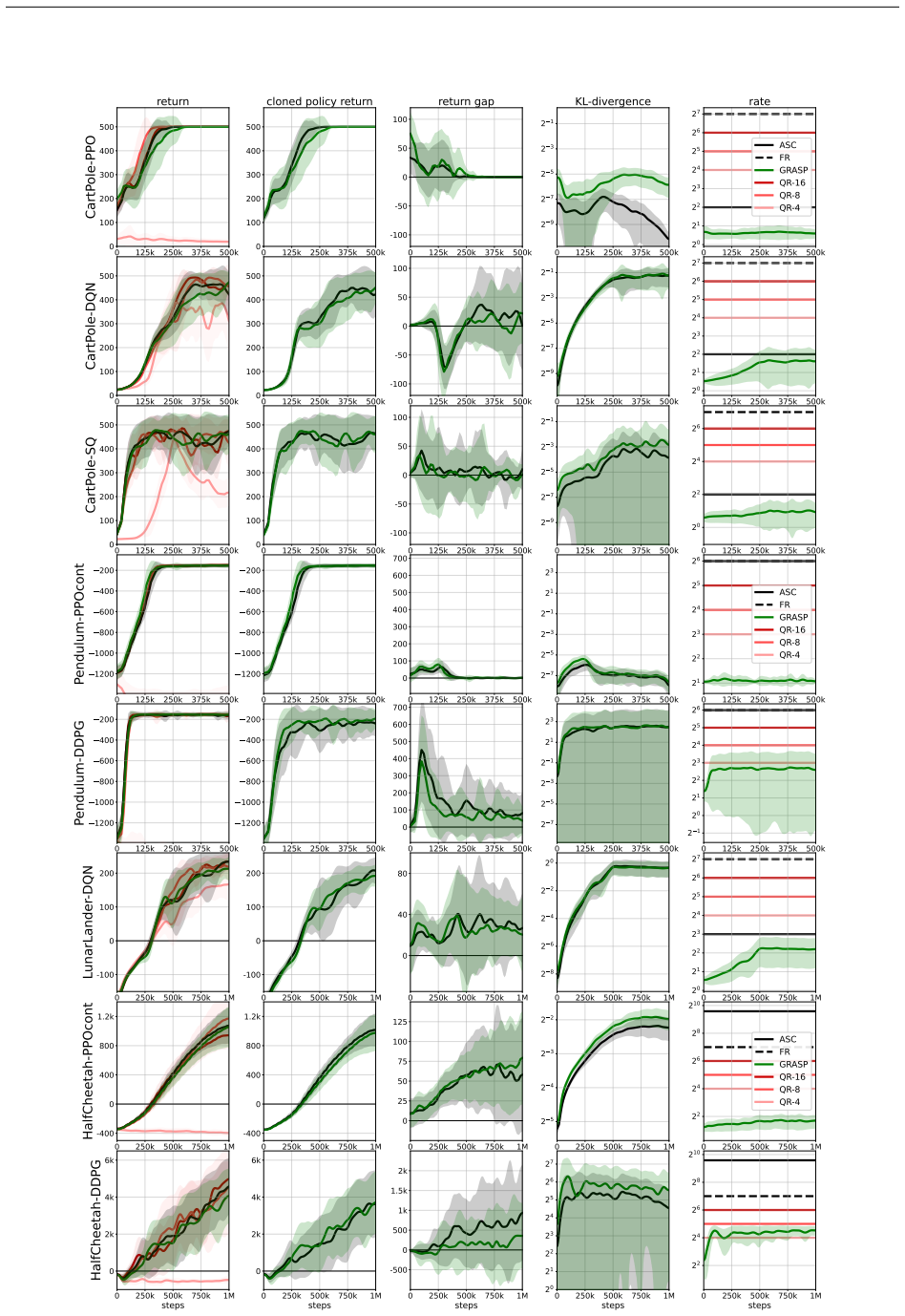
- Average transmitted data drops by a factor of 12 compared with sending full actions directly, reaching 50-fold savings when action spaces are continuous.
- Communication savings increase over time as actors improve their local policy copies and require fewer guidance updates.
- The same framework yields 41-fold reduction relative to transmitting reward values instead of actions.
- Control remains effective even when the channel cannot support direct transmission of high-dimensional or continuous actions.
Where Pith is reading between the lines
- The approach could be extended to multi-actor teams that share one learned policy and therefore need even less per-actor guidance.
- Performance under packet loss or channel noise would be a natural next test, since importance sampling weights might be adjusted for imperfect reception.
- The method may generalize to partially observable environments if the actor-side learner is augmented with local state estimation.
- Combining GRASP with existing rate-distortion or channel-coding techniques could further optimize the guidance signals themselves.
Load-bearing premise
The actors must be able to learn an accurate copy of the controller's policy from the sparse guidance signals without degrading overall control performance.
What would settle it
A controlled experiment in which actors receive the guidance signals yet produce action sequences that deviate enough from the controller's policy to cause measurable drops in task reward or stability.
Figures



read the original abstract
We address the challenge of remote control where one or more actors, lacking direct reward access, are steered by a controller over a communication-constrained channel. The controller learns an optimal policy from observed rewards and communicates action guidance to the actors, which becomes demanding for large or continuous action spaces. To achieve rate-efficient communication throughout this interactive learning and control process, we introduce a novel framework leveraging remote generation. Instead of transmitting full action specifications, the controller sends minimal information, enabling the actors to locally generate actions by sampling from the controller's evolving target policy. This guided sampling is facilitated by an importance sampling approach. Concurrently, the actors use the received guidance as supervised learning data to learn the controller's policy. This actor-side learning improves their local sampling capabilities, progressively reducing future communication needs. Our solution, Guided Remote Action Sampling Policy (GRASP), demonstrates significant communication reduction, achieving an average 12-fold data reduction across all experiments (50-fold for continuous action spaces) compared to direct action transmission, and a 41-fold reduction compared to reward transmission.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Guided Remote Action Sampling Policy (GRASP) framework for remote control over communication-constrained channels. A central controller learns an optimal policy from rewards and transmits minimal guidance packets; actors generate actions locally by importance sampling from an approximation of the controller's evolving target policy and simultaneously use the guidance as supervised learning data to refine their local policy approximation, thereby reducing future communication volume. The authors report that GRASP yields an average 12-fold data reduction versus direct action transmission (50-fold in continuous action spaces) and a 41-fold reduction versus reward transmission across their experiments.
Significance. If the reported reductions prove robust and sustainable without control-performance degradation, the work could meaningfully advance rate-efficient remote reinforcement learning and distributed control in bandwidth-limited settings such as multi-robot systems or edge AI. The combination of importance sampling with online actor-side supervised learning is a conceptually clean way to amortize communication cost as the policy stabilizes.
major comments (2)
- [§3.2] §3.2 (GRASP algorithm and importance-sampling update): the central claim that sparse guidance suffices for sustained 12-fold (or 50-fold) reduction rests on the actor's learned policy remaining a sufficiently accurate approximation of the controller's evolving target policy. No bound, convergence rate, or sample-complexity analysis is supplied for the supervised-learning step relative to the controller's policy-update frequency; without this, it is impossible to verify that importance weights stay bounded or that control performance is preserved at the claimed communication rates.
- [§4] §4 (Experimental evaluation): the headline reduction factors are presented without reported details on the number of independent runs, variance or error bars, exact baseline implementations (direct action vs. reward transmission), or post-hoc hyper-parameter selection for the actor's supervised learner. These omissions make it impossible to assess whether the 12-fold / 50-fold figures are statistically reliable or sensitive to the experimental protocol.
minor comments (2)
- [§3.1] Notation for the importance weights and the supervised-loss term is introduced without an explicit equation reference; adding a numbered display equation would improve traceability.
- [Abstract] The abstract states results 'across all experiments' but does not enumerate the environments or action-space types; a one-sentence summary in the abstract would help readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (GRASP algorithm and importance-sampling update): the central claim that sparse guidance suffices for sustained 12-fold (or 50-fold) reduction rests on the actor's learned policy remaining a sufficiently accurate approximation of the controller's evolving target policy. No bound, convergence rate, or sample-complexity analysis is supplied for the supervised-learning step relative to the controller's policy-update frequency; without this, it is impossible to verify that importance weights stay bounded or that control performance is preserved at the claimed communication rates.
Authors: We acknowledge that the manuscript provides no formal bounds, convergence rates, or sample-complexity guarantees for the actor-side supervised learning relative to the controller's policy updates. GRASP is an empirical framework in which the local policy is trained online on the received guidance packets; as the approximation improves, the importance weights remain moderate in practice, which is why control performance is preserved at the reported rates. We will revise §3.2 to add a discussion of the practical conditions under which the weights stay bounded (including a plot of approximation error versus communication volume) and to state explicitly that a full theoretical analysis is left for future work. revision: partial
-
Referee: [§4] §4 (Experimental evaluation): the headline reduction factors are presented without reported details on the number of independent runs, variance or error bars, exact baseline implementations (direct action vs. reward transmission), or post-hoc hyper-parameter selection for the actor's supervised learner. These omissions make it impossible to assess whether the 12-fold / 50-fold figures are statistically reliable or sensitive to the experimental protocol.
Authors: We agree that these experimental details were insufficiently reported. In the revision we will expand §4 with: (i) all results averaged over 20 independent runs with standard-error bars; (ii) explicit baseline descriptions (direct action transmission sends the full action vector each timestep; reward transmission sends only the scalar reward); (iii) the hyper-parameter selection procedure for the actor's supervised learner (grid search with cross-validation on held-out trajectories). These additions will make the reported reduction factors reproducible and allow assessment of statistical reliability. revision: yes
- A formal bound, convergence rate, or sample-complexity analysis for the supervised-learning step relative to the controller's policy-update frequency.
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces GRASP as an algorithmic framework combining importance sampling for guided remote action generation with actor-side supervised learning from sparse guidance packets. The abstract and description present this as a forward method for reducing communication in remote control, with performance claims (12-fold average reduction, 50-fold for continuous spaces) supported by experimental results rather than any closed-form derivation. No equations, fitted parameters, or self-citations are shown that would make the claimed reductions equivalent to the inputs by construction, nor is there a uniqueness theorem or ansatz smuggled in that collapses the result to a tautology. The derivation chain remains self-contained as an empirical proposal whose validity rests on external benchmarks and assumptions about policy tracking, not internal self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1007/s10462-012-9383-6
ISSN 0269-2821. doi: 10.1007/s10462-012-9383-6. Saurabh Arora and Prashant Doshi. A survey of inverse reinforcement learning: Challenges, methods and progress.Artificial Intelligence, 297:103500, August
-
[2]
ISSN 0004-3702. doi: 10.1016/j.artint.2021. 103500. 11 Tianshu Chu, Jie Wang, Lara Codecà, and Zhaojian Li. Multi-agent deep reinforcement learning for large-scale traffic signal control.IEEE Transactions on Intelligent Transportation Systems, 21(3):1086–1095,
-
[3]
doi: 10.1109/TITS.2019.2901791. Paul Cuff. Communication requirements for generating correlated random variables. In2008 IEEE Inter- national Symposium on Information Theory, pp. 1393–1397, July
-
[4]
doi: 10.1109/ISIT.2008.4595216. ISSN: 2157-8117. Christian Daniel, Malte Viering, Jan Metz, Oliver Kroemer, and Jan Peters. Active reward learning. In Proceedings of Robotics: Science and Systems (RSS ’14), July
-
[5]
doi: 10.1007/s10462-020-09938-y
ISSN 1573-7462. doi: 10.1007/s10462-020-09938-y. André Eberhard, Houssam Metni, Georg Fahland, Alexander Stroh, and Pascal Friederich. Actively learning costly reward functions for reinforcement learning.Machine Learning: Science and Technology, 5(1):015055, mar
-
[6]
Jakob Foerster, Ioannis Alexandros Assael, Nando de Freitas, and Shimon Whiteson
doi: 10.1088/2632-2153/ad33e0. Jakob Foerster, Ioannis Alexandros Assael, Nando de Freitas, and Shimon Whiteson. Learning to Communicate with Deep Multi-Agent Reinforcement Learning. InAdvances in Neural Information Processing Systems, volume
-
[7]
arXiv:1707.02286 [cs]. Jonathan Ho and Stefano Ermon. Generative Adversarial Imitation Learning. InAdvances in Neural Information Processing Systems, volume
-
[8]
Active reinforcement learning: Observing rewards at a cost.arXiv:2011.06709 [cs.LG],
David Krueger, Jan Leike, Owain Evans, and John Salvatier. Active reinforcement learning: Observing rewards at a cost.arXiv:2011.06709 [cs.LG],
-
[9]
Rlaif vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. InProceedings of the 2024 International Conference on Machine Learning (ICML) — Poster Session,
2024
-
[10]
ISSN 1557-9654. doi: 10.1109/TIT.2021.3058842. Cheuk Ting Li and Abbas El Gamal. Strong Functional Representation Lemma and Applications to Coding Theorems.IEEE Transactions on Information Theory, 64(11):6967–6978, November
-
[11]
doi: 10.1109/TIT.2018.2865570. Y. Li, Y. Zhang, X. Li, and C. Sun. Regional multi-agent cooperative reinforcement learning for city- level traffic grid signal control.IEEE/CAA Journal of Automatica Sinica, 11(9):1987–1998,
-
[12]
doi: 10.1109/JAS.2024.124365. Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. InInternational Conference on Learning Representations (ICLR),
-
[13]
Asynchronous Methods for Deep Reinforcement Learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of The 33rd International Conference on Machine Learning, pp. 1928–1937. PMLR, June
1928
-
[14]
Chetan Nadiger, Anil Kumar, and Sherine Abdelhak
ISSN: 1938-7228. Chetan Nadiger, Anil Kumar, and Sherine Abdelhak. Federated Reinforcement Learning for Fast Personaliza- tion. In2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), pp. 123–127, June
1938
-
[15]
Fully Dynamic Maximal Independent Set in Expected Poly-Log Update Time , booktitle =
doi: 10.1109/AIKE.2019.00031. Francesco Pase, Deniz Gündüz, and Michele Zorzi. Rate-constrained remote contextual bandits.IEEE Journal on Selected Areas in Information Theory, 3(4):789–802,
-
[16]
doi: 10.1109/JSAIT.2022.3231459. Dean A. Pomerleau. ALVINN: An Autonomous Land Vehicle in a Neural Network. InAdvances in Neural Information Processing Systems, volume
-
[17]
ISSN 1996-1073. doi: 10.3390/en18102513. Sudeep Salgia and Qing Zhao. Distributed linear bandits under communication constraints. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pp. 29845–29875. PMLR, 23–29 Jul
-
[18]
Proximal Policy Optimization Algorithms
arXiv:1707.06347 [cs]. Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction, volume
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Edge Computing and Its Application in Robotics: A Survey,
ISSN 2224-2708. doi: 10.3390/jsan14040065. J Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Pettingzoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032–15043,
-
[20]
doi: 10.1109/JSAC.2021.3087248
ISSN 1558-0008. doi: 10.1109/JSAC.2021.3087248. Rundong Wang, Xu He, Runsheng Yu, Wei Qiu, Bo An, and Zinovi Rabinovich. Learning Efficient Multi-agent Communication: An Information Bottleneck Approach. InProceedings of the 37th International Conference on Machine Learning, pp. 9908–9918. PMLR, November
-
[21]
doi: 10.1007/s10462-022-10299-x
ISSN 1573-7462. doi: 10.1007/s10462-022-10299-x. 14 A GRASP-ASC comparison Table 3: Detailed performance of action-sending methods (GRASP vs. ASC) in RRL environments environment algorithm training method controller final return actor final return return gap norm. return gap (%) CartPole PPO ASC 500(0) 500(0) 0.0(0.0) 0.0(0.0) GRASP 500(0) 500(0) 0.0(0.0)...
-
[22]
16 C Remote Generation The remote generation method used throughout this work isordered random codingfrom Theis & Yosri (2022), reproduced for convenience in Algorithm
15 0 125k 250k 375k 500k0 100 200 300 400 500CartPole-PPO return 0 125k 250k 375k 500k0 100 200 300 400 500 cloned policy return 0 125k 250k 375k 500k -100 -50 0 50 100 return gap 0 125k 250k 375k 500k 2 9 2 7 2 5 2 3 2 1 KL-divergence 0 125k 250k 375k 500k 20 21 22 23 24 25 26 27 rate ASC FR GRASP QR-16 QR-8 QR-4 0 125k 250k 375k 500k0 100 200 300 400 50...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.