Recognition: 3 theorem links
· Lean TheoremSwiftChannel: Algorithm-Hardware Co-Design for Deep Learning-Based 5G Channel Estimation
Pith reviewed 2026-05-08 19:34 UTC · model grok-4.3
The pith
SwiftChannel delivers a compressed CNN-based channel estimator with parameter-free attention running on FPGA, achieving sub-millisecond latency, 24x speedup, and 33x better energy efficiency than GPU baselines while generalizing across noise and channel profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
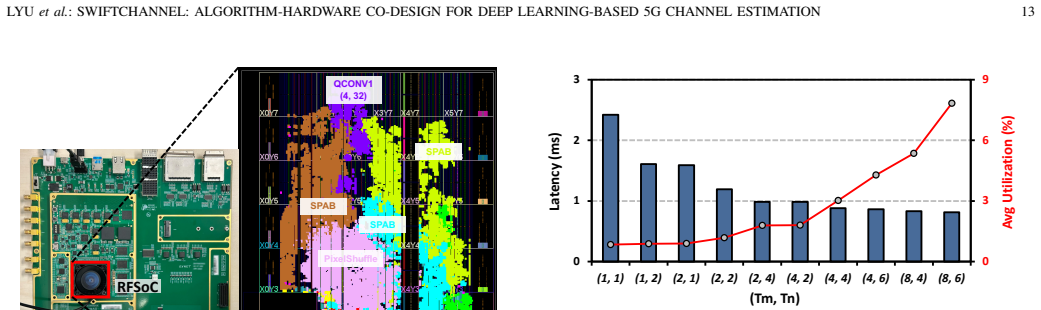
Tested on a Zynq UltraScale+ RFSoC, the accelerator achieves sub-millisecond latency, providing up to 24x speed-up and over 33x improvement in energy efficiency compared to GPU-based solutions. Extensive evaluations demonstrate that the proposed design generalizes not only across various noise levels and user mobilities, but also to a variety of unseen channel profiles, outperforming state-of-the-art baselines.
Load-bearing premise
The multi-stage model compression pipeline (knowledge distillation, convolution re-parameterization, and quantization-aware training) produces substantial size reduction with negligible accuracy loss, and the resulting model plus LS estimator on FPGA generalizes to unseen channel profiles without retraining.
Figures







read the original abstract
Channel estimation is crucial in 5G communication networks for optimizing transmission parameters and ensuring reliable, high-speed communication. However, the use of multiple-input and multiple-output (MIMO) and millimeter-wave (mmWave) in 5G networks presents challenges in achieving accurate estimation under strict latency requirements on resource-limited hardware platforms. To address these challenges, we propose SwiftChannel, an algorithm-hardware co-design framework that integrates a hardware-friendly deep learning-based channel estimator with a dedicated accelerator. Our approach employs a convolutional neural network enhanced with a parameter-free attention mechanism, which effectively reconstructs full-resolution spatial-frequency domain channel matrices from low-resolution least squares (LS) estimates. We further develop a multi-stage model compression pipeline combining knowledge distillation, convolution re-parameterization, and quantization-aware training, resulting in substantial model size reduction with negligible accuracy loss. The hardware accelerator, implementing the compressed model and the LS estimator on FPGA platforms using High-level Synthesis (HLS), features a fine-grained pipeline architecture and optimized dataflow strategies. Tested on a Zynq UltraScale+ RFSoC, the accelerator achieves sub-millisecond latency, providing up to 24x speed-up and over 33x improvement in energy efficiency compared to GPU-based solutions. Extensive evaluations demonstrate that the proposed design generalizes not only across various noise levels and user mobilities, but also to a variety of unseen channel profiles, outperforming state-of-the-art baselines. By unifying algorithmic innovation with hardware-aware design, our work presents a future-proof channel estimation solution for 5G MIMO systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SwiftChannel, an algorithm-hardware co-design framework for deep learning-based channel estimation in 5G MIMO/mmWave systems. It introduces a CNN augmented with a parameter-free attention mechanism to reconstruct full-resolution spatial-frequency channel matrices from low-resolution least-squares (LS) estimates, applies a multi-stage compression pipeline (knowledge distillation, convolution re-parameterization, and quantization-aware training) to reduce model size with negligible accuracy loss, and implements the compressed model plus LS estimator as a fine-grained pipelined accelerator on FPGA using HLS. Evaluated on a Zynq UltraScale+ RFSoC, the design claims sub-millisecond latency, up to 24× speedup and >33× energy-efficiency gains versus GPU baselines, plus generalization across noise levels, user mobilities, and unseen channel profiles while outperforming state-of-the-art methods.
Significance. If the reported hardware gains and generalization hold under rigorous statistical validation, the work would provide a concrete, deployable path toward low-latency, energy-efficient DL channel estimation on resource-limited 5G hardware. The parameter-free attention and staged compression approach, if shown to be robust, represents a useful algorithmic contribution that could influence future co-design efforts.
major comments (3)
- [Abstract] Abstract: the headline claims of 'up to 24x speed-up and over 33x improvement in energy efficiency' are presented without error bars, standard deviations, number of trials, or any indication of variance across runs on the Zynq UltraScale+ RFSoC. Because these quantitative gains constitute the central hardware-performance result, the absence of statistical characterization prevents assessment of whether the improvements are reliable or sensitive to particular test conditions.
- [Abstract] Abstract: the claim that the design 'generalizes … to a variety of unseen channel profiles' without retraining is load-bearing for the overall contribution, yet no evidence is supplied that the test profiles are out-of-distribution relative to training data, nor any analysis of how quantization noise or re-parameterization errors interact with higher-mobility or different scattering statistics. If the compression pipeline introduces distribution-sensitive degradation, the reported outperformance over baselines would not transfer.
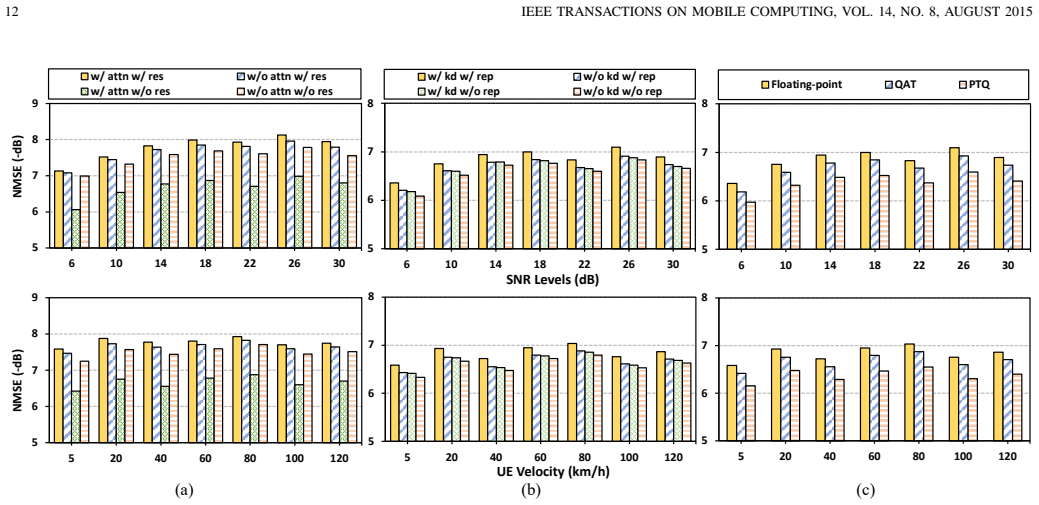
- [Abstract] Abstract: no ablation results, tables, or quantitative breakdowns are referenced for the individual stages of the compression pipeline (knowledge distillation, convolution re-parameterization, quantization-aware training) or for the parameter-free attention mechanism. Without these, the assertion of 'substantial model size reduction with negligible accuracy loss' cannot be verified and remains an unsupported precondition for both the latency and generalization claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A convolutional neural network with parameter-free attention can accurately reconstruct full-resolution channel matrices from low-resolution LS estimates.
- domain assumption Knowledge distillation, convolution re-parameterization, and quantization-aware training can be combined to shrink the model with negligible accuracy loss.
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
parameter-free attention mechanism ... σ_a(x) = sigmoid(x) − 0.5 ... O_i = σ_a(H_i) ⊙ (H_i ⊕ O_{i-1})
-
IndisputableMonolith.Foundation (8-tick period from 2^D=8)DimensionForcing / 8-tick period unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SRS transmitted every 8 slots, the total interval is 1 ms ... sub-millisecond latency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On channel estimation in ofdm systems,
J.-J. Van De Beek, O. Edfors, M. Sandell, S. K. Wilson, and P. O. Borjesson, “On channel estimation in ofdm systems,” inProceedings of the 45th Vehicular Technology Conference (VTC), vol. 2, 1995, pp. 815–819
1995
-
[2]
Robust channel estimation for ofdm systems with rapid dispersive fading channels,
Y . Li, L. J. Cimini, and N. R. Sollenberger, “Robust channel estimation for ofdm systems with rapid dispersive fading channels,”IEEE Trans- actions on Communications (TCOM), vol. 46, no. 7, pp. 902–915, 1998
1998
-
[3]
Intelligent reflecting surface-assisted multi-user miso commu- nication: Channel estimation and beamforming design,
H. Alwazani, A. Kammoun, A. Chaaban, M. Debbah, M.-S. Alouini et al., “Intelligent reflecting surface-assisted multi-user miso commu- nication: Channel estimation and beamforming design,”IEEE Open Journal of the Communications Society, vol. 1, pp. 661–680, 2020
2020
-
[4]
Deep learning-based channel estimation,
M. Soltani, V . Pourahmadi, A. Mirzaei, and H. Sheikhzadeh, “Deep learning-based channel estimation,”IEEE Communications Letters (COMML), vol. 23, no. 4, pp. 652–655, 2019
2019
-
[5]
Deep residual learning meets ofdm channel estimation,
L. Li, H. Chen, H.-H. Chang, and L. Liu, “Deep residual learning meets ofdm channel estimation,”IEEE Wireless Communications Letters (WCL), vol. 9, no. 5, pp. 615–618, 2019
2019
-
[6]
Low complexity channel estimation with neural network solutions,
D. Luan and J. Thompson, “Low complexity channel estimation with neural network solutions,” inProceedings of the 25th International ITG Workshop on Smart Antennas (WSA), 2021, pp. 1–6
2021
-
[7]
Channelformer: Attention based neural solution for wireless channel estimation and effective online training,
D. Luan and J. S. Thompson, “Channelformer: Attention based neural solution for wireless channel estimation and effective online training,” IEEE Transactions on Wireless Communications (TWC), vol. 22, no. 10, pp. 6562–6577, 2023
2023
-
[8]
Deep learning based ofdm channel estimation using frequency-time division and attention mechanism,
A. Yang, P. Sun, T. Rakesh, B. Sun, and F. Qin, “Deep learning based ofdm channel estimation using frequency-time division and attention mechanism,” inProceedings of the IEEE Globecom Workshops, 2021, pp. 1–6
2021
-
[9]
Pay less but get more: A dual-attention-based channel estimation network for massive mimo systems with low-density pilots,
B. Zhou, X. Yang, S. Ma, F. Gao, and G. Yang, “Pay less but get more: A dual-attention-based channel estimation network for massive mimo systems with low-density pilots,”IEEE Transactions on Wireless Communications (TWC), pp. 6061–6076, 2023
2023
-
[10]
Low-overhead channel estimation via 3d extrapolation for tdd mmwave massive mimo systems under high-mobility scenarios,
——, “Low-overhead channel estimation via 3d extrapolation for tdd mmwave massive mimo systems under high-mobility scenarios,”IEEE Transactions on Wireless Communications (TWC), 2025
2025
-
[11]
Low complexity deep learning augmented wireless channel estimation for pilot-based ofdm on zynq system on chip,
A. Sharma, S. A. U. Haq, and S. J. Darak, “Low complexity deep learning augmented wireless channel estimation for pilot-based ofdm on zynq system on chip,”IEEE Transactions on Circuits and Systems I: Regular Papers (TCAS-I), 2024
2024
-
[12]
Deep neural network augmented wireless channel estimation for preamble-based ofdm phy on zynq system on chip,
S. A. U. Haq, A. K. Gizzini, S. Shrey, S. J. Darak, S. Saurabh, and M. Chafii, “Deep neural network augmented wireless channel estimation for preamble-based ofdm phy on zynq system on chip,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 31, no. 7, pp. 1026–1038, 2023
2023
-
[13]
Low complexity high speed deep neural network augmented wireless channel estimation,
S. A. U. Haq, V . Singh, B. T. Tanaji, and S. Darak, “Low complexity high speed deep neural network augmented wireless channel estimation,” in Proceedings of the 37th International Conference on VLSI Design and 23rd International Conference on Embedded Systems (VLSID), 2024, pp. 235–240
2024
-
[14]
Channel estimation using deep learning on an fpga for 5g millimeter-wave communication systems,
P. K. Chundi, X. Wang, and M. Seok, “Channel estimation using deep learning on an fpga for 5g millimeter-wave communication systems,” IEEE Transactions on Circuits and Systems I: Regular Papers (TCAS- I), vol. 69, no. 2, pp. 908–918, 2021
2021
-
[15]
Beamspace channel estimation for massive mimo mmwave systems: Algorithm and vlsi design,
S. H. Mirfarshbafan, A. Gallyas-Sanhueza, R. Ghods, and C. Studer, “Beamspace channel estimation for massive mimo mmwave systems: Algorithm and vlsi design,”IEEE Transactions on Circuits and Systems I: Regular Papers (TCAS-I), vol. 67, no. 12, pp. 5482–5495, 2020
2020
-
[16]
Accurate channel prediction based on transformer: Making mobility negligible,
H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,”IEEE Journal on Selected Areas in Communications (JSAC), vol. 40, no. 9, pp. 2717– 2732, 2022
2022
-
[17]
Deep learning-based channel estimation for wideband hybrid mmwave mas- sive mimo,
J. Gao, C. Zhong, G. Y . Li, J. B. Soriaga, and A. Behboodi, “Deep learning-based channel estimation for wideband hybrid mmwave mas- sive mimo,”IEEE Transactions on Communications (TCOM), vol. 71, no. 6, pp. 3679–3693, 2023
2023
-
[18]
5G; NR; Physical Channels and Modulation,
3GPP, “5G; NR; Physical Channels and Modulation,” Oct. 2024, 3GPP TS 38.211 version 18.4.0 Release 18
2024
-
[19]
Robust channel estimation in multiuser downlink 5g systems under channel uncertainties,
A. Pourkabirian and M. H. Anisi, “Robust channel estimation in multiuser downlink 5g systems under channel uncertainties,”IEEE Transactions on Mobile Computing (TMC), vol. 21, no. 12, pp. 4569– 4582, 2021
2021
-
[20]
Channel estimation for irs- assisted millimeter-wave mimo systems: Sparsity-inspired approaches,
T. Lin, X. Yu, Y . Zhu, and R. Schober, “Channel estimation for irs- assisted millimeter-wave mimo systems: Sparsity-inspired approaches,” IEEE Transactions on Communications (TCOM), vol. 70, no. 6, pp. 4078–4092, 2022
2022
-
[21]
Channel estimation for reconfigurable intelligent surface aided multi-user mmwave mimo sys- tems,
J. Chen, Y .-C. Liang, H. V . Cheng, and W. Yu, “Channel estimation for reconfigurable intelligent surface aided multi-user mmwave mimo sys- tems,”IEEE Transactions on Wireless Communications (TWC), vol. 22, no. 10, pp. 6853–6869, 2023
2023
-
[22]
Spatially common sparsity based adaptive channel estimation and feedback for fdd massive mimo,
Z. Gao, L. Dai, Z. Wang, and S. Chen, “Spatially common sparsity based adaptive channel estimation and feedback for fdd massive mimo,” IEEE Transactions on Signal Processing (TSP), vol. 63, no. 23, pp. 6169–6183, 2015
2015
-
[23]
Deep cnn-based channel estimation for mmwave massive mimo systems,
P. Dong, H. Zhang, G. Y . Li, I. S. Gaspar, and N. NaderiAlizadeh, “Deep cnn-based channel estimation for mmwave massive mimo systems,” IEEE Journal of Selected Topics in Signal Processing (JSTSP), vol. 13, no. 5, pp. 989–1000, 2019
2019
-
[24]
Dual cnn-based channel estimation for mimo-ofdm systems,
P. Jiang, C.-K. Wen, S. Jin, and G. Y . Li, “Dual cnn-based channel estimation for mimo-ofdm systems,”IEEE Transactions on Communi- cations (TCOM), vol. 69, no. 9, pp. 5859–5872, 2021
2021
-
[25]
Learning to reflect and to beamform for intelligent reflecting surface with implicit channel estimation,
T. Jiang, H. V . Cheng, and W. Yu, “Learning to reflect and to beamform for intelligent reflecting surface with implicit channel estimation,”IEEE Journal on Selected Areas in Communications (JSAC), vol. 39, no. 7, pp. 1931–1945, 2021
1931
-
[26]
Comnet: Combination of deep learning and expert knowledge in ofdm receivers,
X. Gao, S. Jin, C.-K. Wen, and G. Y . Li, “Comnet: Combination of deep learning and expert knowledge in ofdm receivers,”IEEE Communications Letters (COMML), vol. 22, no. 12, pp. 2627–2630, 2018
2018
-
[27]
Massive mimo for next generation wireless systems,
E. G. Larsson, O. Edfors, F. Tufvesson, and T. L. Marzetta, “Massive mimo for next generation wireless systems,”IEEE Communications Magazine, vol. 52, no. 2, pp. 186–195, 2014
2014
-
[28]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[29]
Attention-based dropout layer for weakly super- vised object localization,
J. Choe and H. Shim, “Attention-based dropout layer for weakly super- vised object localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 2219– 2228. 16 IEEE TRANSACTIONS ON MOBILE COMPUTING, VOL. 14, NO. 8, AUGUST 2015
2019
-
[30]
Simam: A simple, parameter- free attention module for convolutional neural networks,
L. Yang, R.-Y . Zhang, L. Li, and X. Xie, “Simam: A simple, parameter- free attention module for convolutional neural networks,” inProceedings of the 38th International Conference on Machine Learning (ICML), 2021, pp. 11 863–11 874
2021
-
[31]
Parameter-free similarity-aware attention module for medical image classification and segmentation,
J. Du, K. Guan, Y . Zhou, Y . Li, and T. Wang, “Parameter-free similarity-aware attention module for medical image classification and segmentation,”IEEE Transactions on Emerging Topics in Computational Intelligence (TETCI), vol. 7, no. 3, pp. 845–857, 2022
2022
-
[32]
Parameter-free channel attention for image classification and super-resolution,
Y . Shi, L. Yang, W. An, X. Zhen, and L. Wang, “Parameter-free channel attention for image classification and super-resolution,”arXiv preprint arXiv:2303.11055 (arXiv), 2023
-
[33]
Swift parameter-free attention network for efficient super-resolution,
C. Wan, H. Yu, Z. Li, Y . Chen, Y . Zou, Y . Liu, X. Yin, and K. Zuo, “Swift parameter-free attention network for efficient super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 6246–6256
2024
-
[34]
Distilling the Knowledge in a Neural Network
G. Hinton, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531 (arXiv), 2015
work page Pith review arXiv 2015
-
[35]
Residual distillation: Towards portable deep neural networks without shortcuts,
G. Li, J. Zhang, Y . Wang, C. Liu, M. Tan, Y . Lin, W. Zhang, J. Feng, and T. Zhang, “Residual distillation: Towards portable deep neural networks without shortcuts,”Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), vol. 33, pp. 8935– 8946, 2020
2020
-
[36]
Tailor: Altering skip connections for resource-efficient inference,
O. Weng, G. Marcano, V . Loncar, A. Khodamoradi, N. Sheybani, A. Meza, F. Koushanfar, K. Denolf, J. M. Duarte, and R. Kastner, “Tailor: Altering skip connections for resource-efficient inference,” ACM Transactions on Reconfigurable Technology and Systems (TRETS), vol. 17, no. 1, pp. 1–23, 2024
2024
-
[37]
FitNets: Hints for Thin Deep Nets
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Ben- gio, “Fitnets: Hints for thin deep nets,”arXiv preprint arXiv:1412.6550 (arXiv), 2014
work page internal anchor Pith review arXiv 2014
-
[38]
S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via atten- tion transfer,”arXiv preprint arXiv:1612.03928 (arXiv), 2016
-
[39]
Similarity-preserving knowledge distillation,
F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1365–1374
2019
-
[40]
Repvgg: Mak- ing vgg-style convnets great again,
X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, and J. Sun, “Repvgg: Mak- ing vgg-style convnets great again,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 13 733–13 742
2021
-
[41]
Angel-eye: A complete design flow for mapping cnn onto embedded fpga,
K. Guo, L. Sui, J. Qiu, J. Yu, J. Wang, S. Yao, S. Han, Y . Wang, and H. Yang, “Angel-eye: A complete design flow for mapping cnn onto embedded fpga,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 37, no. 1, pp. 35–47, 2017
2017
-
[42]
Mix and match: A novel fpga-centric deep neural network quantization framework,
S.-E. Chang, Y . Li, M. Sun, R. Shi, H. K.-H. So, X. Qian, Y . Wang, and X. Lin, “Mix and match: A novel fpga-centric deep neural network quantization framework,” inProceedings of the IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2021, pp. 208–220
2021
-
[43]
Film-qnn: Efficient fpga acceleration of deep neural networks with intra-layer, mixed-precision quantization,
M. Sun, Z. Li, A. Lu, Y . Li, S.-E. Chang, X. Ma, X. Lin, and Z. Fang, “Film-qnn: Efficient fpga acceleration of deep neural networks with intra-layer, mixed-precision quantization,” inProceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (ISFPGA), 2022, pp. 134–145
2022
-
[44]
Evaluating fast algorithms for convolutional neural networks on fpgas,
Y . Liang, L. Lu, Q. Xiao, and S. Yan, “Evaluating fast algorithms for convolutional neural networks on fpgas,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 39, no. 4, pp. 857–870, 2019
2019
-
[45]
A unified hardware architecture for convolutions and deconvolutions in cnn,
L. Bai, Y . Lyu, and X. Huang, “A unified hardware architecture for convolutions and deconvolutions in cnn,” inProceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), 2020, pp. 1–5
2020
-
[46]
Imagen: A general framework for generating memory-and power-efficient image processing accelerators,
N. Ujjainkar, J. Leng, and Y . Zhu, “Imagen: A general framework for generating memory-and power-efficient image processing accelerators,” inProceedings of the 50th Annual International Symposium on Com- puter Architecture (ISCA), 2023, pp. 1–13
2023
-
[47]
Optimizing loop oper- ation and dataflow in fpga acceleration of deep convolutional neural networks,
Y . Ma, Y . Cao, S. Vrudhula, and J.-s. Seo, “Optimizing loop oper- ation and dataflow in fpga acceleration of deep convolutional neural networks,” inProceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (ISFPGA), 2017, pp. 45–54
2017
-
[48]
Optimizing fpga-based accelerator design for deep convolutional neural networks,
C. Zhang, P. Li, G. Sun, Y . Guan, B. Xiao, and J. Cong, “Optimizing fpga-based accelerator design for deep convolutional neural networks,” inProceedings of the ACM/SIGDA International Symposium on Field- Programmable Gate Arrays (ISFPGA), 2015, pp. 161–170
2015
-
[49]
Accelerating the super-resolution convolutional neural network,
C. Dong, C. C. Loy, and X. Tang, “Accelerating the super-resolution convolutional neural network,” inProceedings of European Conference on Computer Vision (ECCV), 2016, pp. 391–407. Shengzhe Lyu(Student Member, IEEE) is a Ph.D. candidate in the Department of Computer Science at City University of Hong Kong. Before that, he received the B.Sc. (summa cum la...
2016
-
[50]
He is a senior member of IEEE
His research generally focuses on IoT such as smart sensing, IoT security, IoT+AI, and wireless networks. He is a senior member of IEEE
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.