Recognition: unknown
TRAP: Tail-aware Ranking Attack for World-Model Planning
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
World models can be hijacked by reordering the ranking of a few critical imagined trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
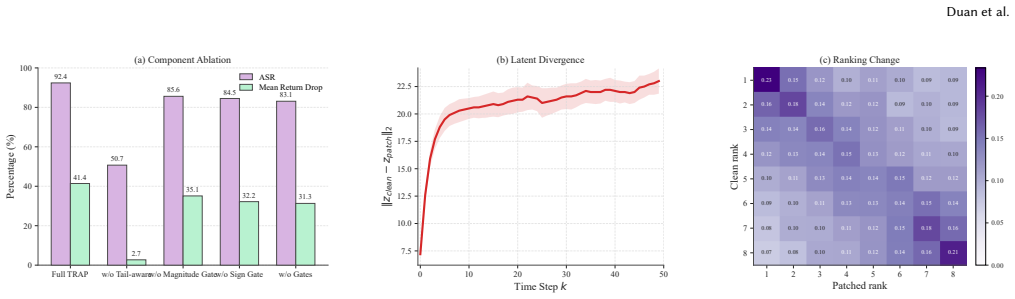
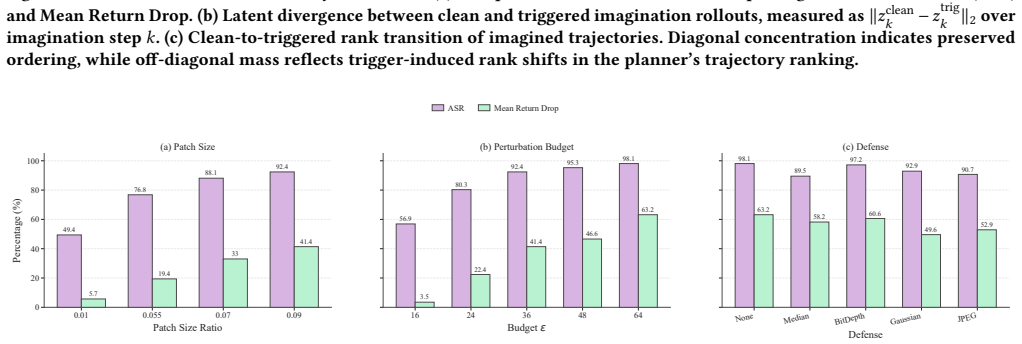
World models exhibit a distinct backdoor vulnerability rooted in the long-tailed ranking structure of imagined trajectories, where disrupting the ordering of a few decision-critical trajectories can systematically hijack planning. TRAP exploits this by combining a tail-aware ranking loss with dual gating mechanisms that stabilize optimization and regulate when the attack penalty is applied, resulting in redirected planning under trigger conditions while largely preserving normal ranking on clean inputs.
What carries the argument
The tail-aware ranking loss that focuses optimization on decision-critical trajectories, together with dual gating mechanisms that stabilize training and control application of the attack penalty.
If this is right
- Under trigger conditions, planning outcomes are redirected toward attacker-chosen behaviors.
- On clean inputs, the original ranking structure and task performance remain largely unchanged.
- The attack produces sustained behavioral deviations and measurable performance drops on DreamerV3 and TD-MPC2 across multiple tasks.
- Existing backdoor techniques aimed at features or one-step predictions are insufficient for world-model planners.
Where Pith is reading between the lines
- Defenses will need to regularize or monitor the internal ranking distribution rather than only the input or final policy.
- Any planning system that selects actions by ranking many generated candidates may inherit similar tail-based vulnerabilities.
- Training procedures that deliberately flatten the trajectory-value distribution could reduce attack surface at the cost of planning efficiency.
- The same ranking-attack pattern could be tested in non-RL generative planners that rely on internal simulation and selection.
Load-bearing premise
The long-tailed ranking structure of imagined trajectories stays stable enough on clean data to preserve performance yet remains fragile enough that a trigger can reorder the critical tail without being absorbed by the learned dynamics.
What would settle it
A test in which the trigger is applied yet the world model still selects and executes the original highest-ranked trajectories, showing that the dynamics prior overrode the ranking change.
Figures


read the original abstract
World models enable long-horizon planning by internally generating and evaluating imagined trajectories, making them a promising foundation for generalist agents. However, this imagination-driven decision process also introduces new security risks. Existing backdoor attacks typically aim to manipulate local features, one-step predictions, or instantaneous policy outputs. While such objectives may suffice for weaker reactive models, they are often ineffective against world models, where the learned dynamics prior and planning process can absorb or wash out the effects of shallow perturbations. More importantly, we find that world models exhibit a distinct backdoor vulnerability rooted in the long-tailed ranking structure of imagined trajectories, where disrupting the ordering of a few decision-critical trajectories can systematically hijack planning. To exploit this vulnerability, we propose TRAP, a backdoor attack framework for world models that targets imagined trajectory ranking. TRAP combines a tail-aware ranking loss to focus optimization on decision-critical trajectories with dual gating mechanisms that stabilize optimization and regulate when and where the attack penalty is applied. Under trigger conditions, TRAP alters the relative ranking of imagined trajectories to redirect planning outcomes, while largely maintaining the normal ranking structure on clean inputs. Experiments on DreamerV3 and TD-MPC2 across diverse tasks show that TRAP consistently induces sustained behavioral deviations and significant performance degradation, highlighting the need for dedicated security evaluation of world-model-based agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that world models for planning exhibit a distinct backdoor vulnerability rooted in the long-tailed ranking structure of imagined trajectories, where reordering a few decision-critical trajectories can hijack planning outcomes. It proposes TRAP, which combines a tail-aware ranking loss focused on critical trajectories with dual gating mechanisms to stabilize optimization and control attack application. Under trigger conditions, the attack redirects planning while largely preserving clean ranking and performance; experiments on DreamerV3 and TD-MPC2 across diverse tasks demonstrate sustained behavioral deviations with limited clean degradation.
Significance. If the results hold, the work is significant for identifying a planning-specific vulnerability in world models that differs from local-feature or one-step attacks on reactive models. The concrete loss formulation, gating logic, and empirical validation on two state-of-the-art algorithms provide reproducible evidence of the vulnerability and underscore the need for dedicated security evaluation of imagination-driven agents.
minor comments (3)
- [Abstract] Abstract: the phrase 'diverse tasks' is used without enumeration; specifying the task suite (e.g., by name or category) would improve immediate readability.
- [§3] §3 (Method): the dual-gating logic is described in prose; inclusion of a compact pseudocode block or flowchart would clarify the timing and scope of the attack penalty.
- [§4] §4 (Experiments): while results are reported, moving key baseline comparisons and trigger-design details from the appendix into the main text would strengthen the central empirical narrative.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on TRAP and for recommending minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity; empirical attack proposal with no reductive derivations
full rationale
The manuscript frames TRAP as an empirical backdoor attack on world-model planners, supported by concrete loss formulations, gating mechanisms, and experimental results on DreamerV3 and TD-MPC2. No equations, uniqueness theorems, or derivation chains are present that reduce the claimed vulnerability or attack success to fitted parameters, self-citations, or ansatzes by construction. The long-tailed ranking observation is presented as an empirical finding rather than a self-defined premise, and clean-performance preservation is validated externally via reported metrics rather than forced by the method definition. This satisfies the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. 2018. Syn- thesizing robust adversarial examples. InInternational conference on machine learning. PMLR, 284–293
2018
-
[2]
Fengshuo Bai, Runze Liu, Yali Du, Ying Wen, and Yaodong Yang. 2025. Rat: Adversarial attacks on deep reinforcement agents for targeted behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 15453–15461
2025
-
[3]
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. 2013. The arcade learning environment: An evaluation platform for general agents.Journal of artificial intelligence research47 (2013), 253–279
2013
-
[4]
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. 2024. Video generation models as world simulators.OpenAI Blog1, 8 (2024), 1
2024
-
[5]
Tom B Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer
- [6]
-
[7]
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. 2024. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning
2024
- [8]
- [9]
-
[10]
Jing Cui, Yufei Han, Yuzhe Ma, Jianbin Jiao, and Junge Zhang. 2024. Badrl: Sparse targeted backdoor attack against reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 11687–11694
2024
-
[11]
Chen Gong, Zhou Yang, Yunpeng Bai, Junda He, Jieke Shi, Kecen Li, Arunesh Sinha, Bowen Xu, Xinwen Hou, David Lo, et al. 2024. Baffle: Hiding backdoors in offline reinforcement learning datasets. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2086–2104
2024
-
[12]
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. 2019. Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access7 (2019), 47230–47244
2019
-
[13]
Chuan Guo, Mayank Rana, Moustapha Cisse, and Laurens Van Der Maaten
- [14]
-
[15]
Ji Guo, Wenbo Jiang, Yansong Lin, Yijing Liu, Ruichen Zhang, Guomin Lu, Aiguo Chen, Xinshuo Han, Hongwei Li, and Dusit Niyato. 2026. State Backdoor: To- wards Stealthy Real-world Poisoning Attack on Vision-Language-Action Model in State Space.arXiv preprint arXiv:2601.04266(2026)
-
[16]
Alexander Gushchin, Khaled Abud, Georgii Bychkov, Ekaterina Shumitskaya, Anna Chistyakova, Sergey Lavrushkin, Bader Rasheed, Kirill Malyshev, Dmitriy Vatolin, and Anastasia Antsiferova. 2024. Guardians of image quality: Bench- marking defenses against adversarial attacks on image quality metrics.arXiv preprint arXiv:2408.01541(2024)
-
[17]
David Ha and Jürgen Schmidhuber. 2018. World models.arXiv preprint arXiv:1803.101222, 3 (2018), 440
work page internal anchor Pith review arXiv 2018
- [18]
-
[19]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2019. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603(2019)
work page internal anchor Pith review arXiv 2019
-
[20]
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. 2019. Learning latent dynamics for planning from pixels. InInternational conference on machine learning. PMLR, 2555–2565
2019
- [21]
-
[22]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2023. Mas- tering diverse domains through world models.arXiv preprint arXiv:2301.04104 (2023)
work page internal anchor Pith review arXiv 2023
-
[23]
Nicklas Hansen, Hao Su, and Xiaolong Wang. 2023. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828(2023)
work page internal anchor Pith review arXiv 2023
- [24]
-
[25]
Haoran He, Yang Zhang, Liang Lin, Zhongwen Xu, and Ling Pan. 2026. Pre- trained video generative models as world simulators. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 4645–4653
2026
-
[26]
Yibin Hu, Xiaolin Sun, and Zizhan Zheng. [n. d.]. Stealthy World Model Manipu- lation via Data Poisoning. ([n. d.])
- [27]
-
[28]
Danny Karmon, Daniel Zoran, and Yoav Goldberg. 2018. Lavan: Localized and visible adversarial noise. InInternational conference on machine learning. PMLR, 2507–2515
2018
-
[29]
Panagiota Kiourti, Kacper Wardega, Susmit Jha, and Wenchao Li. 2020. Trojdrl: evaluation of backdoor attacks on deep reinforcement learning. In2020 57th ACM/IEEE Design Automation Conference (DAC). IEEE, 1–6
2020
- [30]
-
[31]
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. 2022. Backdoor learning: A survey.IEEE transactions on neural networks and learning systems35, 1 (2022), 5–22
2022
- [32]
-
[33]
Fan-Ming Luo, Tian Xu, Hang Lai, Xiong-Hui Chen, Weinan Zhang, and Yang Yu. 2024. A survey on model-based reinforcement learning.Science China Information Sciences67, 2 (2024), 121101
2024
- [34]
- [35]
-
[36]
Pietro Novelli, Marco Pratticò, Massimiliano Pontil, and Carlo Ciliberto. 2024. Op- erator world models for reinforcement learning.Advances in Neural Information Processing Systems37 (2024), 111432–111463
2024
-
[37]
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Hol- sheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, et al . 2024. Genie 2: A large-scale foundation world model. URL: https://deepmind. google/discover/blog/genie-2-a-large-scale-foundation- world-model2 (2024)
2024
-
[38]
Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. 2017. Robust adversarial reinforcement learning. InInternational conference on machine learning. PMLR, 2817–2826
2017
- [39]
-
[40]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al
-
[41]
Deepmind control suite.arXiv preprint arXiv:1801.00690(2018)
work page internal anchor Pith review arXiv 2018
- [42]
- [43]
- [44]
- [45]
-
[46]
Mingfu Xue, Xin Wang, Shichang Sun, Yushu Zhang, Jian Wang, and Weiqiang Liu. 2023. Compression-resistant backdoor attack against deep neural networks. Applied Intelligence53, 17 (2023), 20402–20417. Duan et al
2023
- [47]
-
[48]
Weipu Zhang, Gang Wang, Jian Sun, Yetian Yuan, and Gao Huang. 2023. Storm: Efficient stochastic transformer based world models for reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 27147–27166
2023
- [49]
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.