Recognition: unknown
Moira: Language-driven Hierarchical Reinforcement Learning for Pair Trading
Pith reviewed 2026-05-09 17:04 UTC · model grok-4.3
The pith
Pair trading policies can be adapted at both abstraction and execution levels by updating LLM prompts with textual feedback instead of gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
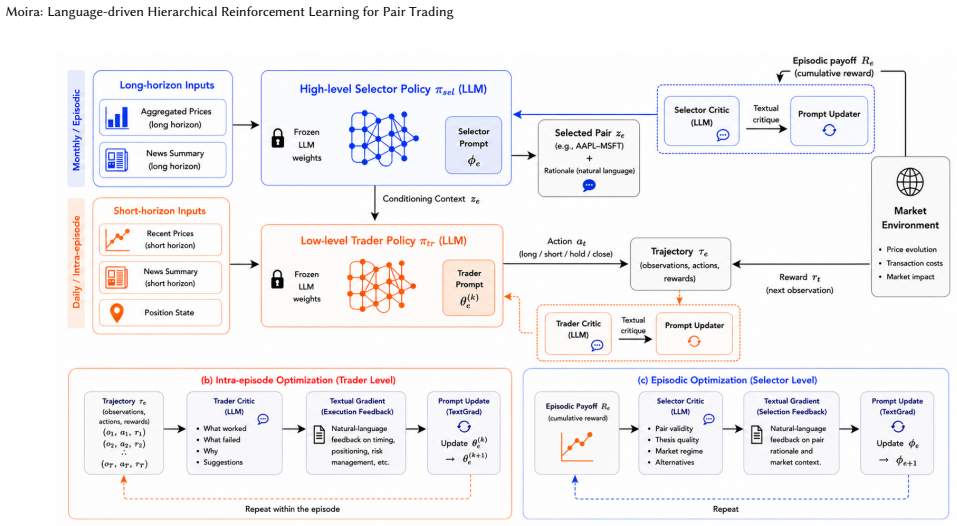
Pair trading is formulated as a hierarchical reinforcement learning problem where high-level policies select asset pairs using semantic reasoning and low-level policies execute trades. Both are implemented as LLMs optimized exclusively via prompt updates driven by textual feedback at trajectory and episode levels, explicitly separating abstraction from execution to mitigate non-stationarity and enable adaptation under delayed feedback.
What carries the argument
The language-driven hierarchical optimization framework that parameterizes high-level and low-level policies as LLMs and adapts them through prompt updates using textual feedback.
If this is right
- Explicit separation of abstraction selection from execution reduces non-stationarity across hierarchical levels.
- Targeted adaptation is possible under delayed and ambiguous feedback without gradient-based fine-tuning.
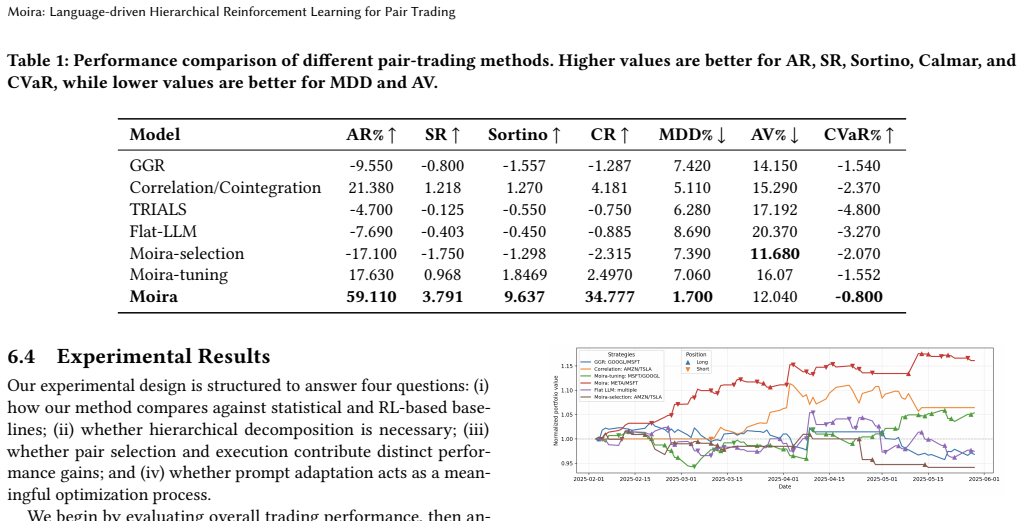
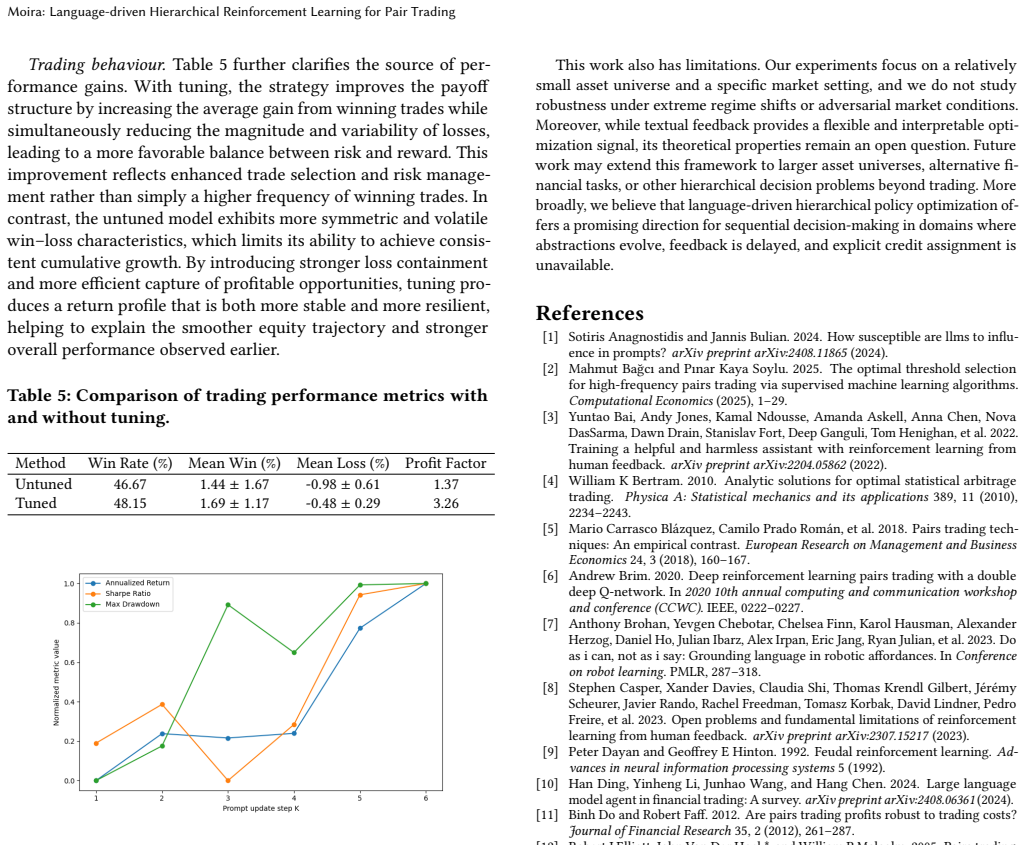
- Consistent performance improvements occur over traditional RL and LLM-based baselines in real-world market data for pair trading.
Where Pith is reading between the lines
- Similar prompt-based adaptation could extend to other hierarchical sequential tasks such as robotic planning where high-level goals and low-level controls need separate tuning.
- Removing the need for gradient updates makes the method more accessible for domains where fine-tuning large models is computationally expensive.
- Textual feedback might allow incorporating human expertise more directly into policy adaptation loops.
Load-bearing premise
Trajectory- and episode-level textual feedback is sufficient to adapt both high-level semantic abstractions and low-level execution policies effectively without any gradient-based fine-tuning.
What would settle it
Running the same experiments but replacing prompt updates with gradient fine-tuning of the LLMs and observing no performance difference or degradation would indicate the textual feedback mechanism is not the key driver.
Figures

read the original abstract
Many sequential decision-making problems exhibit hierarchical structure, where high-level semantic choices constrain downstream actions and feedback is delayed and ambiguous. Learning in such settings is challenging due to credit assignment: performance degradation may arise from flawed abstractions, suboptimal execution, or their interaction. We study this challenge through pair trading, a domain that naturally combines long-horizon semantic reasoning for asset pair selection with short-horizon execution under partial observability. We formulate pair trading as a hierarchical reinforcement learning problem and propose a language-driven optimization framework in which both high-level and low-level policies are parameterized by large language models (LLMs) and optimized exclusively through prompt updates. Our approach leverages pretrained LLMs as hierarchical policies and uses trajectory- and episode-level textual feedback to adapt abstractions and execution without gradient-based fine-tuning. By explicitly separating abstraction selection from execution, the framework reduces non-stationarity across hierarchical levels and enables targeted adaptation under delayed feedback. Experiments on real-world market data show consistent improvements over traditional and LLM-based baselines, demonstrating the effectiveness of language-driven hierarchical reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a language-driven hierarchical reinforcement learning framework called Moira for pair trading. In this setup, large language models serve as both high-level policies for selecting trading pairs based on semantic reasoning and low-level policies for executing trades under partial observability. Policies are adapted exclusively through updates to prompts using textual feedback from trajectories and episodes, without any gradient-based fine-tuning. The separation of levels is argued to reduce non-stationarity, facilitating better credit assignment in the presence of delayed and ambiguous feedback. Experiments using real-world market data are said to demonstrate consistent performance improvements over traditional and LLM-based baselines.
Significance. Should the empirical results prove robust, this contribution could advance the application of LLMs to hierarchical decision-making problems in finance and beyond, particularly where gradient access is limited or undesirable. It highlights a prompt-based method for adapting hierarchical policies, potentially offering a more interpretable alternative to standard RL fine-tuning. The use of real market data adds practical relevance, though the absence of detailed validation for the credit assignment mechanism limits the immediate impact.
major comments (2)
- [Abstract] The statement that experiments 'show consistent improvements' lacks any quantitative details, such as specific performance metrics (e.g., Sharpe ratio, returns), baseline comparisons, number of assets or time periods tested, or statistical significance tests. Without these, it is impossible to evaluate whether the data supports the central claim of effectiveness.
- [Abstract] The assertion that the framework 'enables targeted adaptation under delayed feedback' by separating abstraction selection from execution relies on the unverified assumption that textual feedback can perform level-specific credit assignment. No mechanism is provided for how a textual summary distinguishes high-level semantic errors from low-level execution issues amid market noise and partial observability, which is critical to the hierarchical benefit claimed.
minor comments (1)
- The abstract is dense with technical terms; consider adding a brief overview of pair trading for broader accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications from the full paper and indicating where revisions will strengthen the presentation without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] The statement that experiments 'show consistent improvements' lacks any quantitative details, such as specific performance metrics (e.g., Sharpe ratio, returns), baseline comparisons, number of assets or time periods tested, or statistical significance tests. Without these, it is impossible to evaluate whether the data supports the central claim of effectiveness.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately assess the strength of the empirical claims. The full manuscript's experimental section (Section 5) reports quantitative results on real market data, including comparisons against traditional RL baselines and other LLM-based methods, with metrics such as cumulative returns, Sharpe ratios, and win rates across multiple asset pairs and time periods. In the revised manuscript we will condense key quantitative highlights into the abstract (e.g., average return improvement and number of evaluated pairs/periods) while preserving the high-level summary style. revision: yes
-
Referee: [Abstract] The assertion that the framework 'enables targeted adaptation under delayed feedback' by separating abstraction selection from execution relies on the unverified assumption that textual feedback can perform level-specific credit assignment. No mechanism is provided for how a textual summary distinguishes high-level semantic errors from low-level execution issues amid market noise and partial observability, which is critical to the hierarchical benefit claimed.
Authors: The manuscript does provide a mechanism, described in Section 3.2 and 4: high-level policies receive episode-level textual summaries that focus on pair-selection quality and semantic alignment with market regimes, while low-level policies receive trajectory-level feedback that isolates execution actions (entry/exit timing and sizing) within a fixed pair. Because the LLM reasons over these distinct textual signals, it can attribute performance degradation to either abstraction choice or execution without gradient-based credit assignment. We acknowledge that the abstract is too terse to convey this distinction and that explicit examples of feedback prompts would help readers verify the separation. We will therefore add a short illustrative example and a brief robustness discussion in the revised version. revision: partial
Circularity Check
No significant circularity; derivation and evaluation are self-contained.
full rationale
The paper formulates pair trading as hierarchical RL with LLMs as policies updated exclusively via prompt-based textual feedback at trajectory and episode levels. It claims this separation reduces non-stationarity and enables adaptation without gradients. Evaluation relies on external real-world market data and comparisons to independent baselines. No equations, fitted parameters presented as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work are present in the provided text. The chain from problem statement to empirical results does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained LLMs can serve as effective policies for both high-level and low-level decisions in hierarchical RL when adapted via prompts.
Reference graph
Works this paper leans on
- [1]
-
[2]
Mahmut Bağcı and Pınar Kaya Soylu. 2025. The optimal threshold selection for high-frequency pairs trading via supervised machine learning algorithms. Computational Economics(2025), 1–29
2025
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862(2022)
work page internal anchor Pith review arXiv 2022
-
[4]
William K Bertram. 2010. Analytic solutions for optimal statistical arbitrage trading.Physica A: Statistical mechanics and its applications389, 11 (2010), 2234–2243
2010
-
[5]
Mario Carrasco Blázquez, Camilo Prado Román, et al. 2018. Pairs trading tech- niques: An empirical contrast.European Research on Management and Business Economics24, 3 (2018), 160–167
2018
-
[6]
Andrew Brim. 2020. Deep reinforcement learning pairs trading with a double deep Q-network. In2020 10th annual computing and communication workshop and conference (CCWC). IEEE, 0222–0227
2020
-
[7]
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, et al. 2023. Do as i can, not as i say: Grounding language in robotic affordances. InConference on robot learning. PMLR, 287–318
2023
-
[8]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217(2023)
work page internal anchor Pith review arXiv 2023
-
[9]
Peter Dayan and Geoffrey E Hinton. 1992. Feudal reinforcement learning.Ad- vances in neural information processing systems5 (1992)
1992
- [10]
-
[11]
Binh Do and Robert Faff. 2012. Are pairs trading profits robust to trading costs? Journal of Financial Research35, 2 (2012), 261–287
2012
-
[12]
Robert J Elliott, John Van Der Hoek*, and William P Malcolm. 2005. Pairs trading. Quantitative Finance5, 3 (2005), 271–276
2005
-
[13]
Saeid Fallahpour, Hasan Hakimian, Khalil Taheri, and Ehsan Ramezanifar. 2016. Pairs trading strategy optimization using the reinforcement learning method: a cointegration approach.Soft Computing20, 12 (2016), 5051–5066
2016
-
[14]
George Fatouros, Kostas Metaxas, John Soldatos, and Dimosthenis Kyriazis. 2025. Can Large Language Models beat wall street? Evaluating GPT-4’s impact on financial decision-making with MarketSenseAI.Neural Computing and Applica- tions37, 30 (2025), 24893–24918
2025
-
[15]
Evan Gatev, William N Goetzmann, and K Geert Rouwenhorst. 2006. Pairs trading: Performance of a relative-value arbitrage rule.The review of financial studies19, 3 (2006), 797–827
2006
-
[16]
Minghong Geng, Shubham Pateria, Budhitama Subagdja, Lin Li, Xin Zhao, and Ah-Hwee Tan. 2025. L2m2: A hierarchical framework integrating large language model and multi-agent reinforcement learning. InInternational Joint Conference on Artificial Intelligence
2025
-
[17]
Minjia Guo, Jianhe Liu, Ziping Luo, and Xiao Han. 2024. Deep reinforcement learning for pairs trading: Evidence from China black series futures.International Review of Economics & Finance93 (2024), 981–993
2024
-
[18]
Zihao Guo, Hanqing Jin, Jiaqi Kuang, Zhongmin Qian, and Jinghan Wang. 2025. Signature Decomposition Method Applying to Pair Trading.Journal of Futures Markets(2025)
2025
-
[19]
Weiguang Han, Boyi Zhang, Qianqian Xie, Min Peng, Yanzhao Lai, and Jimin Huang. 2023. Select and trade: Towards unified pair trading with hierarchical reinforcement learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4123–4134
2023
-
[20]
Yifan Hao, Xingyuan Pan, Hanning Zhang, Chenlu Ye, Rui Pan, and Tong Zhang
-
[21]
Understanding Overadaptation in Supervised Fine-Tuning: The Role of Ensemble Methods.arXiv preprint arXiv:2506.01901(2025). Polydoros Giannouris, Yuechen Jiang, Lingfei Qian, Yuyan Wang, Xueqing Peng, Jimin Huang, Guojun Xiong, and Sophia Ananiadou
- [22]
- [23]
-
[24]
Nicolas Huck and Komivi Afawubo. 2015. Pairs trading and selection methods: is cointegration superior?Applied Economics47, 6 (2015), 599–613
2015
-
[25]
Sang-Ho Kim, Deog-Yeong Park, and Ki-Hoon Lee. 2022. Hybrid deep reinforce- ment learning for pairs trading.Applied Sciences12, 3 (2022), 944
2022
-
[26]
Taewook Kim and Ha Young Kim. 2019. Optimizing the Pairs-Trading Strategy Using Deep Reinforcement Learning with Trading and Stop-Loss Boundaries. Complexity2019, 1 (2019), 3582516
2019
-
[27]
Christopher Krauss. 2017. Statistical arbitrage pairs trading strategies: Review and outlook.Journal of Economic Surveys31, 2 (2017), 513–545
2017
-
[28]
Christopher Krauss, Xuan Anh Do, and Nicolas Huck. 2017. Deep neural net- works, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500.European Journal of Operational Research259, 2 (2017), 689–702
2017
-
[29]
Andrew Levy, George Konidaris, Robert Platt, and Kate Saenko. 2019. Learning multi-level hierarchies with hindsight. InProceedings of International Conference on Learning Representations
2019
-
[30]
Xiang Li, Zhenyu Li, Chen Shi, Yong Xu, Qing Du, Mingkui Tan, and Jun Huang
-
[31]
InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024)
Alphafin: Benchmarking financial analysis with retrieval-augmented stock-chain framework. InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024). 773–783
2024
- [32]
-
[33]
Jing-You Lu, Hsu-Chao Lai, Wen-Yueh Shih, Yi-Feng Chen, Shen-Hang Huang, Hao-Han Chang, Jun-Zhe Wang, Jiun-Long Huang, and Tian-Shyr Dai. 2022. Structural break-aware pairs trading strategy using deep reinforcement learning. The Journal of Supercomputing78, 3 (2022), 3843–3882
2022
- [34]
-
[35]
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. 2018. Data- efficient hierarchical reinforcement learning.Advances in neural information processing systems31 (2018)
2018
-
[36]
Shubham Pateria, Budhitama Subagdja, Ah-hwee Tan, and Chai Quek. 2021. Hierarchical reinforcement learning: A comprehensive survey.ACM Computing Surveys (CSUR)54, 5 (2021), 1–35
2021
- [37]
- [38]
-
[39]
Molei Qin, Shuo Sun, Wentao Zhang, Haochong Xia, Xinrun Wang, and Bo An
-
[40]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Earnhft: Efficient hierarchical reinforcement learning for high frequency trading. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 14669–14676
-
[41]
Hossein Rad, Rand Kwong Yew Low, and Robert Faff. 2016. The profitability of pairs trading strategies: distance, cointegration and copula methods.Quantitative Finance16, 10 (2016), 1541–1558
2016
-
[42]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[43]
Francesco Rotondi and Federico Russo. 2024. Machine Learning for Pairs Trading: a Clustering-based Approach.A vailable at SSRN 5080998(2024)
2024
- [44]
-
[45]
Yufei Sun. 2025. A survey of statistical arbitrage pairs trading strategies with non- machine learning methods, 2016-2023.Faculty of Economic Sciences, University of Warsaw Working Papers2025-19 (2025)
2025
-
[46]
Masood Tadi and Jiří Witzany. 2025. Copula-based trading of cointegrated cryptocurrency Pairs.Financial Innovation11, 1 (2025), 40
2025
-
[47]
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. 2017. Feudal networks for hier- archical reinforcement learning. InInternational conference on machine learning. PMLR, 3540–3549
2017
-
[48]
2004.Pairs Trading: quantitative methods and analysis
Ganapathy Vidyamurthy. 2004.Pairs Trading: quantitative methods and analysis. John Wiley & Sons
2004
-
[49]
Cheng Wang, Patrik Sandås, and Peter Beling. 2021. Improving pairs trading strategies via reinforcement learning. In2021 International Conference on Applied Artificial Intelligence (ICAPAI). IEEE, 1–7
2021
- [50]
-
[51]
Saizhuo Wang, Hang Yuan, Leon Zhou, Lionel Ni, Heung Yeung Shum, and Jian Guo. 2025. Alpha-gpt: Human-ai interactive alpha mining for quantitative investment. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 196–206
2025
- [52]
-
[53]
Guojun Xiong, Zhiyang Deng, Keyi Wang, Yupeng Cao, Haohang Li, Yangyang Yu, Xueqing Peng, Mingquan Lin, Kaleb E Smith, Xiao-Yang Liu, et al . 2025. FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading.arXiv preprint arXiv:2502.11433(2025)
-
[54]
Fucui Xu and Shan Tan. 2020. Dynamic portfolio management based on pair trad- ing and deep reinforcement learning. InProceedings of the 2020 3rd International Conference on Computational Intelligence and Intelligent Systems. 50–55
2020
-
[55]
Hongshen Yang and Avinash Malik. 2024. Reinforcement Learning Pair Trading: A Dynamic Scaling Approach.Journal of Risk and Financial Management17, 12 (2024), 555
2024
- [56]
- [57]
-
[58]
Yangyang Yu, Haohang Li, Zhi Chen, Yuechen Jiang, Yang Li, Jordan W Suchow, Denghui Zhang, and Khaldoun Khashanah. 2025. Finmem: A performance- enhanced llm trading agent with layered memory and character design.IEEE Transactions on Big Data(2025)
2025
-
[59]
Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yuechen Jiang, Yupeng Cao, Zhi Chen, Jordan Suchow, Zhenyu Cui, Rong Liu, et al . 2024. Fincon: A synthesized llm multi-agent system with conceptual verbal reinforcement for enhanced financial decision making.Advances in Neural Information Processing Systems37 (2024), 137010–137045
2024
-
[60]
pair ": [
Wentao Zhang, Lingxuan Zhao, Haochong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, et al. 2024. A multimodal founda- tion agent for financial trading: Tool-augmented, diversified, and generalist. In Proceedings of the 30th acm sigkdd conference on knowledge discovery and data mining. 4314–4325. A Stock Universe Our ex...
2024
-
[61]
The previous Trader prompt
-
[62]
POLICY :
Critic feedback Task : - The Trader prompt is composed of an IMMUTABLE section ( everything outside POLICY ) and a MUTABLE section ( the POLICY block content ) . - You MUST propose updates ONLY to the POLICY rules . - You MUST NOT modify any other text from previous Trader prompt . - You MUST NOT introduce rules that depend on signals , features , or fiel...
-
[63]
The previous Selector prompt ( theta_prev )
-
[64]
Critic feedback text ( g_text )
-
[65]
POLICY :
A scalar reward for the last selection Task : - The Selector prompt is composed of an IMMUTABLE section ( everything outside POLICY ) and a MUTABLE section ( the POLICY block content ) . - You MUST propose updates ONLY to the POLICY rules . - You MUST NOT modify any other text from the previous Selector prompt . - You MUST NOT introduce rules that depend ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.