Recognition: 4 theorem links
· Lean TheoremCoopetition-Gym v1: A Formally Grounded Platform for Mixed-Motive Multi-Agent Reinforcement Learning under Strategic Coopetition
Pith reviewed 2026-05-08 18:45 UTC · model grok-4.3
The pith
Coopetition-Gym v1 is the first platform to combine continuous-action mixed-motive environments, parameterized reward mutuality, calibrated interdependence coefficients, game-theoretic oracle baselines, and validated case studies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coopetition-Gym v1 comprises twenty environments organized into four mechanism classes that correspond to four foundational technical reports. Each environment carries a closed-form payoff structure and a calibrated interdependence matrix derived from the corresponding report. Every environment exposes a parameterized reward layer configurable across three structurally distinct modes. Four of the twenty environments are calibrated against historically documented coopetitive relationships and reproduce their outcomes at 98.3, 81.7, 86.7, and 87.3 percent on the validation rubric. The platform exposes Gymnasium, PettingZoo Parallel, and PettingZoo AEC interfaces and ships 126 reference algorit
What carries the argument
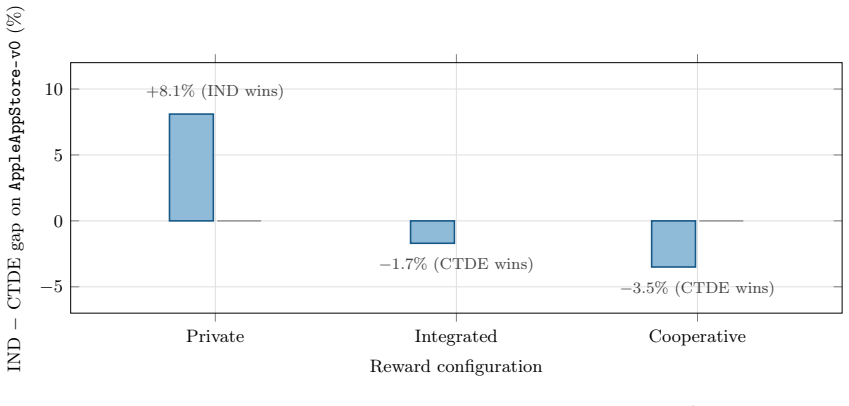
The parameterized reward layer configurable across private, integrated, and cooperative modes, which separates the underlying payoff structure from the observed reward signal to enable reward-type ablation.
If this is right
- Reward-type ablation studies become feasible while holding payoff structures fixed across all environments.
- Learning algorithm performance can be directly compared to game-theoretic oracles in each of the twenty settings.
- Simulated outcomes in four environments can be checked against historical data from documented alliances and platforms.
- The released 25,708-run training corpus and 1,116-run behavioral audit corpus support reproducible analysis of mixed-motive dynamics.
- The four mechanism classes supply a modular foundation for adding further classes of strategic interaction.
Where Pith is reading between the lines
- The platform design may support identification of general conditions under which cooperative equilibria arise in continuous-action spaces without explicit communication.
- The calibrated matrices could be applied to forecast behaviors in untested but structurally similar competitive partnerships outside the four historical cases.
- The payoff-reward separation might be adopted in other multi-agent benchmarks to isolate effects of incentive alignment.
- Dynamic variation of interdependence coefficients during episodes could be tested as a natural extension to study adaptation in changing alliances.
Load-bearing premise
The twenty environments and four mechanism classes, together with the calibrated interdependence matrices derived from the four prior technical reports, sufficiently represent the space of strategic coopetition and allow meaningful generalization beyond the specific cases.
What would settle it
Re-running the sixteen learning algorithms on the four validated environments and obtaining validation percentages below the reported 81.7 percent threshold, or constructing a new environment from an unrepresented mechanism class and finding that learned behaviors deviate systematically from predictions based on the interdependence matrices.
Figures












read the original abstract
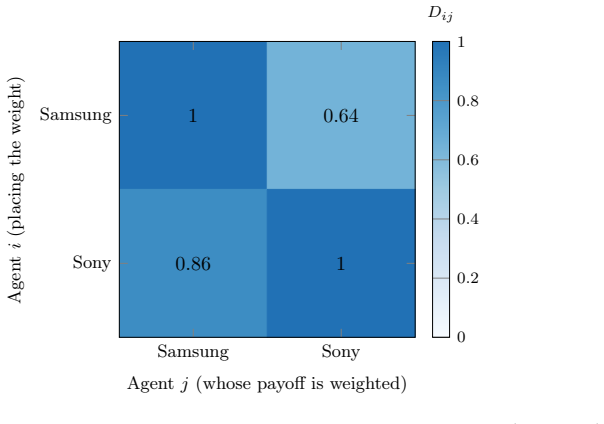
We present Coopetition-Gym v1, a benchmark platform for mixed-motive multi-agent reinforcement learning under strategic coopetition. The platform comprises twenty environments organized into four mechanism classes that correspond to four foundational technical reports: interdependence and complementarity (arXiv:2510.18802), trust and reputation dynamics (arXiv:2510.24909), collective action and loyalty (arXiv:2601.16237), and sequential interaction and reciprocity (arXiv:2604.01240). Each environment carries a closed-form payoff structure and a calibrated interdependence matrix derived from the corresponding report. Every environment exposes a parameterized reward layer configurable across three structurally distinct modes (private, integrated, cooperative). This separation of payoff from reward enables reward-type ablation, the platform's principal methodological apparatus. Four of the twenty environments are calibrated against historically documented coopetitive relationships and reproduce their outcomes at 98.3, 81.7, 86.7, and 87.3 percent on the validation rubric (Samsung-Sony LCD, Renault-Nissan Alliance, Apache HTTP Server, Apple iOS App Store). The platform exposes Gymnasium, PettingZoo Parallel, and PettingZoo AEC interfaces and ships 126 reference algorithms: 16 learning algorithms, 7 game-theoretic oracles, 2 heuristic baselines, and 101 constant-action policies. A reference experimental study trained the 16 learning algorithms on every environment under every reward configuration with seven random seeds, producing a 25,708-run training corpus and a 1,116-run behavioral audit corpus, both released under CC-BY-4.0 with Croissant 1.0 metadata. Coopetition-Gym v1 is the first platform to combine continuous-action mixed-motive environments, parameterized reward mutuality, calibrated interdependence coefficients, game-theoretic oracle baselines, and validated case studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Coopetition-Gym v1, a benchmark platform for mixed-motive multi-agent reinforcement learning under strategic coopetition. It comprises 20 environments across four mechanism classes drawn from prior technical reports on interdependence/complementarity, trust/reputation, collective action/loyalty, and sequential interaction/reciprocity. Each environment has closed-form payoffs and calibrated interdependence matrices, with a parameterized reward layer offering private, integrated, and cooperative modes. The platform provides Gymnasium and PettingZoo interfaces, 126 reference algorithms (including 7 game-theoretic oracles), and releases a 25,708-run training corpus plus behavioral audit data, with four historical case validations reproducing outcomes at 98.3%, 81.7%, 86.7%, and 87.3% fidelity. It claims to be the first platform combining continuous-action mixed-motive environments, parameterized reward mutuality, calibrated coefficients, oracle baselines, and validated case studies.
Significance. If the platform construction and historical validations hold, this provides a valuable standardized benchmark for mixed-motive MARL research, enabling controlled ablation of reward structures and reproducible comparisons via oracles and baselines. Credit is due for the release of the full training corpus under CC-BY-4.0 with Croissant metadata, support for standard Gymnasium/PettingZoo interfaces, and the scale of the 25,708-run experimental study, which together facilitate community adoption and systematic study of coopetition beyond purely competitive or cooperative settings.
major comments (1)
- [Abstract] Abstract: the reported reproduction accuracies (98.3%, 81.7%, 86.7%, 87.3%) for the four historical cases (Samsung-Sony LCD, Renault-Nissan Alliance, Apache HTTP Server, Apple iOS App Store) are presented without specifying the validation rubric, exact metrics, or error analysis. This detail is load-bearing for substantiating the 'validated case studies' component of the central novelty claim.
minor comments (2)
- A summary table enumerating all 20 environments by mechanism class, action space dimensionality, and source report would improve clarity and allow readers to quickly assess coverage of the coopetition space.
- The interdependence matrices are imported from the four prior reports; adding a brief appendix with their numerical values or a sensitivity check would enhance standalone reproducibility without altering the platform's integration focus.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of Coopetition-Gym v1's potential as a benchmark and for the constructive comment on the abstract. We address the single major comment below and will incorporate the requested clarification.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported reproduction accuracies (98.3%, 81.7%, 86.7%, 87.3%) for the four historical cases (Samsung-Sony LCD, Renault-Nissan Alliance, Apache HTTP Server, Apple iOS App Store) are presented without specifying the validation rubric, exact metrics, or error analysis. This detail is load-bearing for substantiating the 'validated case studies' component of the central novelty claim.
Authors: We agree that the abstract would benefit from an explicit statement of the validation rubric to better support the novelty claim. The full manuscript details the rubric in the validation section as a fidelity metric that quantifies the percentage match between simulated agent behaviors (strategic choices, cooperation levels, and payoff outcomes) and the documented historical records for each case, with supporting error analysis via parameter sensitivity checks. In the revised version we will update the abstract sentence to read: 'Four of the twenty environments are calibrated against historically documented coopetitive relationships and reproduce their outcomes at 98.3%, 81.7%, 86.7%, and 87.3% fidelity on a validation rubric that compares simulated strategic interactions and payoffs against historical records (detailed metrics and error analysis appear in the main text).' This addition directly addresses the concern while preserving the reported accuracies. revision: yes
Circularity Check
No significant circularity; platform is an integration of externally grounded components
full rationale
The manuscript presents a benchmark platform whose environments and matrices are drawn from four prior technical reports by the same authors, but the central contribution is the new Gymnasium/PettingZoo implementation, the three reward modes, the 126 reference algorithms, and the released 25,708-run corpus. No derivation chain, prediction, or first-principles result is claimed that reduces by construction to fitted parameters or self-citations inside the paper. The four historical validations (98.3–81.7 % fidelity) are performed against external documented relationships, supplying independent grounding. The 'first to combine' statement follows directly from the enumerated feature list rather than from any self-referential equation or ansatz. Self-citations supply the foundational environments but do not bear the load of proving a new mathematical result; the platform itself is the novel artifact.
Axiom & Free-Parameter Ledger
free parameters (1)
- interdependence matrices =
derived per environment from prior reports
axioms (1)
- domain assumption The four mechanism classes (interdependence, trust, collective action, reciprocity) adequately span strategic coopetition.
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
U_i(a) = π_i(a) + Σ_{j≠i} D_ij · π_j(a) + M_i(a, h_t)
-
Cost.JcostJcost_unit0 / J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
g(a) = (∏ a_i)^{1/n}; V(a|γ) = Σ f_i(a_i) + γ·g(a) with γ=0.65 calibrated for S-LCD case study
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. P. Agapiou, A. S. Vezhnevets, E. A. Duéñez-Guzmán, J. Matyas, Y. Mao, P. Sunehag, R. Koster, U. Madhushani, K. Kopparapu, R. Comanescu, D. J. Strouse, M. B. Johanson, S. Singh, J. Haas, I. Mordatch, D. Mobbs, and J. Z. Leibo. Melting Pot 2.0.arXiv preprint arXiv:2211.13746, 2022
-
[2]
Axelrod.The Evolution of Cooperation
R. Axelrod.The Evolution of Cooperation. Basic Books, 1984
1984
-
[3]
N. Bard, J. N. Foerster, S. Chandar, N. Burch, M. Lanctot, H. F. Song, E. Parisotto, V. Dumoulin, S. Moitra, E. Hughes, I. Dunning, S. Mourad, H. Larochelle, M. G. Bellemare, and M. Bowling. The Hanabi challenge: A new frontier for AI research.Artificial Intelligence, 280:103216, 2020
2020
-
[4]
Coopetition
M. Bengtsson and S. Kock. “Coopetition” in business networks — to cooperate and compete simultaneously.Industrial Marketing Management, 29(5):411–426, 2000
2000
-
[5]
R. B. Bouncken, J. Gast, S. Kraus, and M. Bogers. Coopetition: a systematic review, synthesis, and future research directions.Review of Managerial Science, 9(3):577–601, 2015
2015
-
[6]
A. M. Brandenburger and B. J. Nalebuff.Co-opetition. Currency Doubleday, 1996
1996
-
[7]
Carroll, R
M. Carroll, R. Shah, M. K. Ho, T. L. Griffiths, S. A. Seshia, P. Abbeel, and A. Dragan. On the utility of learning about humans for human-AI coordination. InAdvances in Neural Information Processing Systems 32, 2019
2019
-
[8]
Ellis, J
B. Ellis, J. Cook, S. Moalla, M. Samvelyan, M. Sun, A. Mahajan, J. N. Foerster, and S. Whiteson. SMACv2: An improved benchmark for cooperative multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems 36, Datasets and Benchmarks Track, 2023
2023
-
[9]
Fehr and S
E. Fehr and S. Gächter. Cooperation and punishment in public goods experiments.American Economic Review, 90(4):980–994, 2000. 79
2000
-
[10]
Foerster, G
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson. Counterfactual multi-agent policy gradients. InProc. AAAI, 2018
2018
-
[11]
J. N. Foerster, R. Y. Chen, M. Al-Shedivat, S. Whiteson, P. Abbeel, and I. Mordatch. Learning with opponent-learning awareness. InProc. AAMAS, 2018
2018
-
[12]
Co-opetitionbetweengiants: Collaborationwithcompetitors for technological innovation.Research Policy, 40(5):650–663, 2011
D.R.GnyawaliandB.-J.R.Park. Co-opetitionbetweengiants: Collaborationwithcompetitors for technological innovation.Research Policy, 40(5):650–663, 2011
2011
-
[13]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProc. ICML, 2018
2018
-
[14]
Bayesian
J. C. Harsanyi. Games with incomplete information played by “Bayesian” players, parts I–III. Management Science, 14(3,5,7):159–182, 320–334, 486–502, 1967
1967
-
[15]
J. A. Hartigan and P. M. Hartigan. The dip test of unimodality.The Annals of Statistics, 13(1):70–84, 1985
1985
-
[16]
Henderson, R
P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger. Deep reinforcement learning that matters. InProc. AAAI, 2018
2018
-
[17]
Untanglingtheriseofcoopetition: theintrusionofcompetitionin a cooperative game structure.International Studies of Management & Organization, 37(2):32– 52, 2007
G.PadulaandG.B.Dagnino. Untanglingtheriseofcoopetition: theintrusionofcompetitionin a cooperative game structure.International Studies of Management & Organization, 37(2):32– 52, 2007
2007
-
[18]
Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453, 2019
M. Lanctot, E. Lockhart, J.-B. Lespiau, V. Zambaldi, S. Upadhyay, J. Pérolat, S. Srinivasan, F. Timbers, K. Tuyls, S. Omidshafiei, D. Hennes, D. Morrill, P. Muller, T. Ewalds, R. Faulkner, J. Kramar, B. De Vylder, B. Saeta, J. Bradbury, D. Ding, S. Borgeaud, M. Lai, J. Schrittwieser, T. Anthony, E. Hughes, I. Danihelka, and J. Ryan-Davis. OpenSpiel: A fra...
-
[19]
J. Z. Leibo, V. Zambaldi, M. Lanctot, J. Marecki, and T. Graepel. Multi-agent reinforcement learning in sequential social dilemmas. InProc. AAMAS, 2017
2017
-
[20]
Hughes, J
E. Hughes, J. Z. Leibo, M. Phillips, K. Tuyls, E. Dueñez-Guzmán, A. García Castañeda, I. Dunning, T. Zhu, K. McKee, R. Koster, H. Roff, and T. Graepel. Inequity aversion improves cooperation in intertemporal social dilemmas. InAdvances in Neural Information Processing Systems 31, 2018
2018
-
[21]
Y. Luo. A coopetition perspective of global competition.Journal of World Business, 42(2):129– 144, 2007
2007
-
[22]
Bengtsson and S
M. Bengtsson and S. Kock. Coopetition—Quo vadis? Past accomplishments and future challenges.Industrial Marketing Management, 43(2):180–188, 2014
2014
-
[23]
J. Dahl. Conceptualizing coopetition as a process: An outline of change in cooperative and competitive interactions.Industrial Marketing Management, 43(2):272–279, 2014
2014
-
[24]
Ritala, A
P. Ritala, A. Golnam, and A. Wegmann. Coopetition-based business models: The case of Amazon.com.Industrial Marketing Management, 43(2):236–249, 2014
2014
-
[25]
M. A. Nowak and K. Sigmund. Evolution of indirect reciprocity.Nature, 437(7063):1291–1298, 2005. 80
2005
-
[26]
Czakon and K
W. Czakon and K. Czernek. The role of trust-building mechanisms in entering into network coopetition: The case of tourism networks in Poland.Industrial Marketing Management, 57:64– 74, 2016
2016
-
[27]
A. A. Lado, N. G. Boyd, and S. C. Hanlon. Competition, cooperation, and the search for economic rents: A syncretic model.Academy of Management Review, 22(1):110–141, 1997
1997
-
[28]
J. Z. Leibo, E. A. Dueñez-Guzmán, A. Vezhnevets, J. P. Agapiou, P. Sunehag, R. Koster, J. Matyas, C. Beattie, I. Mordatch, and T. Graepel. Scalable evaluation of multi-agent reinforcement learning with Melting Pot. InProc. ICML, 2021
2021
-
[29]
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. InAdvances in Neural Information Processing Systems 30, 2017
2017
-
[30]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis. Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
2015
-
[31]
J. F. Nash. Equilibrium points inn-person games.Proceedings of the National Academy of Sciences, 36(1):48–49, 1950
1950
-
[32]
M. A. Nowak. Five rules for the evolution of cooperation.Science, 314(5805):1560–1563, 2006
2006
-
[33]
Ostrom.Governing the Commons: The Evolution of Institutions for Collective Action
E. Ostrom.Governing the Commons: The Evolution of Institutions for Collective Action. Cambridge University Press, 1990
1990
-
[34]
V. Pant and E. Yu. Computational foundations for strategic coopetition: Formalizing interdependence and complementarity.arXiv preprint arXiv:2510.18802, 2025
-
[35]
V. Pant and E. Yu. Computational foundations for strategic coopetition: Formalizing trust and reputation dynamics.arXiv preprint arXiv:2510.24909, 2025
-
[36]
V. Pant and E. Yu. Computational foundations for strategic coopetition: Formalizing collective action and loyalty.arXiv preprint arXiv:2601.16237, 2026
-
[37]
V.PantandE.Yu. Computationalfoundationsforstrategiccoopetition: Formalizingsequential interaction and reciprocity.arXiv preprint arXiv:2604.01240, 2026
-
[38]
Pant and E
V. Pant and E. Yu.Coopetition-Gym v1: reproducibility package for the Coopetition-Gym benchmark. Software, version 1.0.0 (git tagv1.0.0), released under MIT license, 2026. Source: https://github.com/vikpant/strategic- coopetition. Archival deposit: persistent identifier to be minted via Zenodo–GitHub integration at v1.0.0 release
2026
-
[39]
Papoudakis, F
G. Papoudakis, F. Christianos, L. Schäfer, and S. V. Albrecht. Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. InAdvances in Neural Information Processing Systems 34, Datasets and Benchmarks Track, 2021
2021
-
[40]
D. G. Rand and M. A. Nowak. Human cooperation.Trends in Cognitive Sciences, 17(8):413– 425, 2013. 81
2013
-
[41]
Rashid, M
T. Rashid, M. Samvelyan, C. Schroeder de Witt, G. Farquhar, J. Foerster, and S. Whiteson. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proc. ICML, 2018
2018
-
[42]
Samvelyan, T
M. Samvelyan, T. Rashid, C. Schroeder de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C.-M. Hung, P. H. S. Torr, J. Foerster, and S. Whiteson. The StarCraft multi-agent challenge. InProc. AAMAS, 2019
2019
-
[43]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[44]
L. S. Shapley. Stochastic games.Proceedings of the National Academy of Sciences, 39(10):1095– 1100, 1953
1953
-
[45]
Shoham and K
Y. Shoham and K. Leyton-Brown.Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations. Cambridge University Press, 2008
2008
-
[46]
Silver, A
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalch- brenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of Go with deep neural networks and tree search.Nature, 529(75...
2016
-
[47]
D. J. Strouse, K. McKee, M. Botvinick, E. Hughes, and R. Everett. Collaborating with humans without human data. InAdvances in Neural Information Processing Systems 34, 2021
2021
-
[48]
Sunehag, G
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V. Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuyls, and T. Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. InProc. AAMAS, 2018
2018
-
[49]
Tampuu, T
A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Korjus, J. Aru, J. Aru, and R. Vicente. Multiagent cooperation and competition with deep reinforcement learning.PLOS ONE, 12(4):e0172395, 2017
2017
-
[50]
J. K. Terry, B. Black, N. Grammel, M. Jayakumar, A. Hari, R. Sullivan, L. Santos, R. Perez- Vicente, C. Horsch, C. Dieffendahl, N. L. Williams, Y. Lokesh, and P. Ravi. PettingZoo: Gym for multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems 34, 2021
2021
-
[51]
Thesurprisingeffectiveness of PPO in cooperative multi-agent games
C.Yu, A.Velu, E.Vinitsky, J.Gao, Y.Wang, A.Bayen, andY.Wu. Thesurprisingeffectiveness of PPO in cooperative multi-agent games. InAdvances in Neural Information Processing Systems 35, Datasets and Benchmarks Track, 2022. 82
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.