Recognition: no theorem link
Heterogeneous Model Fusion for Privacy-Aware Multi-Camera Surveillance via Synthetic Domain Adaptation
Pith reviewed 2026-05-12 01:48 UTC · model grok-4.3
The pith
HeroCrystal fuses heterogeneous models for privacy-preserving multi-camera object detection by generating synthetic data from one target image, reaching 33.4% mAP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HeroCrystal claims that a one-shot target-aware diffusion generator, combined with probabilistic Faster R-CNN, dynamic contrastive federated fusion, and an inconsistent-categories integration algorithm, produces accurate multi-class detections across heterogeneous cameras while keeping all raw data local and private.
What carries the argument
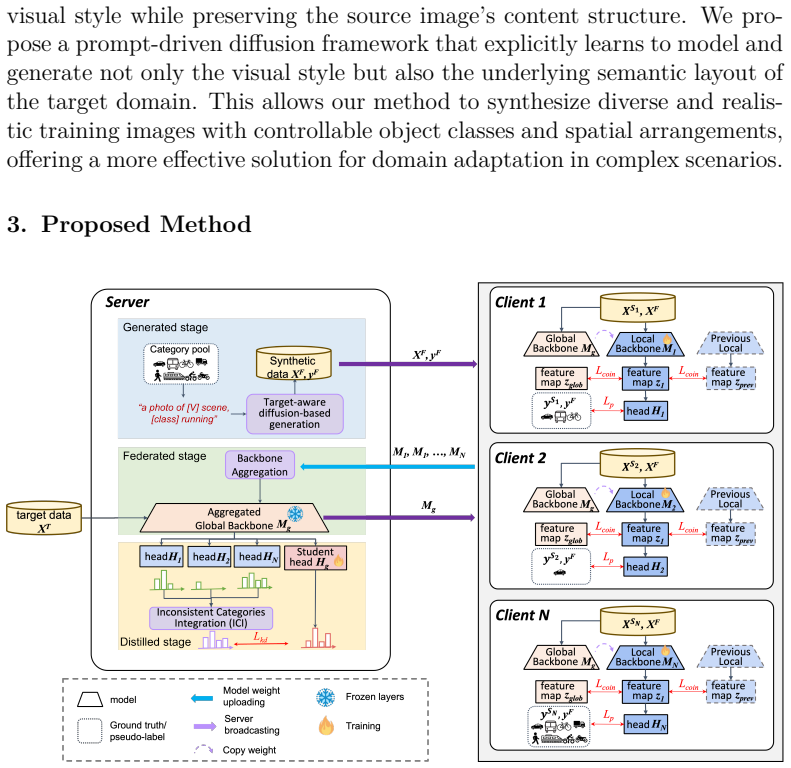
The three-stage HeroCrystal pipeline: one-shot diffusion generation for style-matched and rare-object synthesis, client-side probabilistic detection with contrastive debiasing, and server-side heterogeneous model fusion with label reconciliation.
If this is right
- Rare-object synthesis directly counters long-tailed category degradation in surveillance scenes.
- Dynamic contrastive training on the client side reduces domain-specific bias before fusion.
- Inconsistent-categories integration resolves label mismatches caused by different client architectures.
- The overall pipeline supports multi-source domain adaptation under strict privacy constraints.
Where Pith is reading between the lines
- The same one-shot generation step could be tested on other privacy-sensitive tasks such as person re-identification or action recognition.
- Removing the need for large target datasets may lower labeling costs in any federated vision setting.
- Real-time deployment on edge cameras would reveal whether the reported mAP gains survive compression and latency constraints.
Load-bearing premise
A single target-domain image supplies enough visual information for the diffusion model to produce semantically correct rare objects without adding new biases that lower detection accuracy.
What would settle it
If replacing the single-image input with either zero images or several images produces a statistically significant mAP change or a measurable shift in per-class bias on the same benchmarks, the one-shot sufficiency claim would be refuted.
Figures







read the original abstract
We propose HeroCrystal, a novel privacy-preserving framework for multi-camera domain-adaptive object detection, addressing challenges such as data privacy, class imbalance, and heterogeneous architectures. Our framework consists of three key stages. In the Generated Stage, we introduce a one-shot, target-aware diffusion-based generation module that learns visual style from a single target-domain image while leveraging prompt-based control to synthesize specific object instances. Unlike conventional style transfer-based methods that require large target datasets and ignore semantic-level discrepancies, our approach enables privacy-preserving augmentation to reduce ethical concerns, and introduces controllable rare object generation to mitigate long-tailed category degradation. In the Federated Stage, we employ probabilistic Faster R-CNN on the client side to improve localization accuracy, and a dynamic model contrastive strategy to suppress domain-specific bias. The server side performs model fusion across heterogeneous architectures without accessing raw data. Finally, in the Distilled Stage, we propose an inconsistent categories integration algorithm to resolve label inconsistency and architecture heterogeneity across clients. Extensive experiments on multiple cross-domain detection benchmarks demonstrate that our method outperforms existing multi-source domain adaptation and federated learning baselines under multi-class, privacy-preserving settings. Our method improves mAP by +2.1% over prior privacy-preserving approaches and achieves a new state-of-the-art mAP of 33.4%, highlighting the effectiveness of HeroCrystal in enabling practical multi-camera AI surveillance systems. The source code is publicly available at https://github.com/ccuvislab/HeroCrystal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HeroCrystal, a privacy-preserving framework for multi-camera domain-adaptive object detection consisting of three stages: (1) a Generated Stage with a one-shot target-aware diffusion module that learns style from a single target image and uses prompt control to synthesize rare objects; (2) a Federated Stage using probabilistic Faster R-CNN on clients with dynamic model contrastive learning and server-side heterogeneous model fusion without raw data access; (3) a Distilled Stage with an inconsistent categories integration algorithm. Extensive experiments on cross-domain detection benchmarks are reported to yield +2.1% mAP over prior privacy-preserving methods and a new SOTA mAP of 33.4%. Public code is released.
Significance. If the empirical claims hold after validation, the work offers a practical advance in privacy-aware surveillance by enabling synthetic augmentation from minimal target data while handling heterogeneous models via federated fusion. The public code release supports reproducibility, and the focus on controllable rare-object synthesis addresses a real long-tailed class issue in detection. The combination of diffusion-based generation with probabilistic detection and distillation is a coherent engineering contribution, though its impact depends on confirming the one-shot module's robustness.
major comments (3)
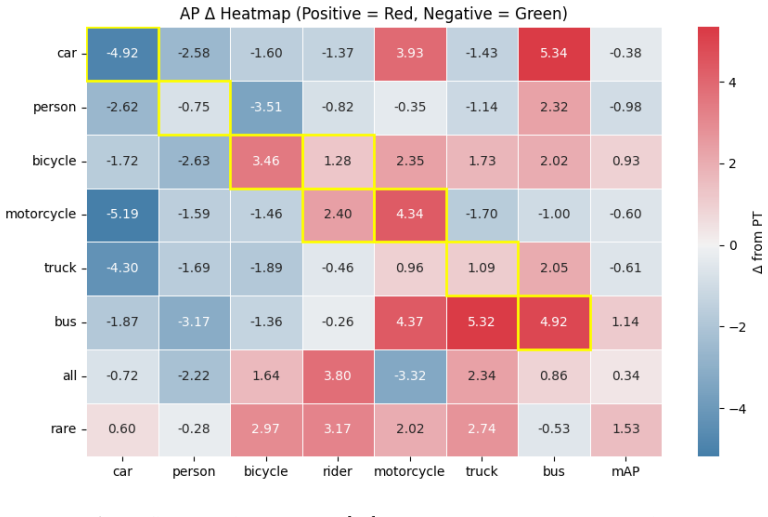
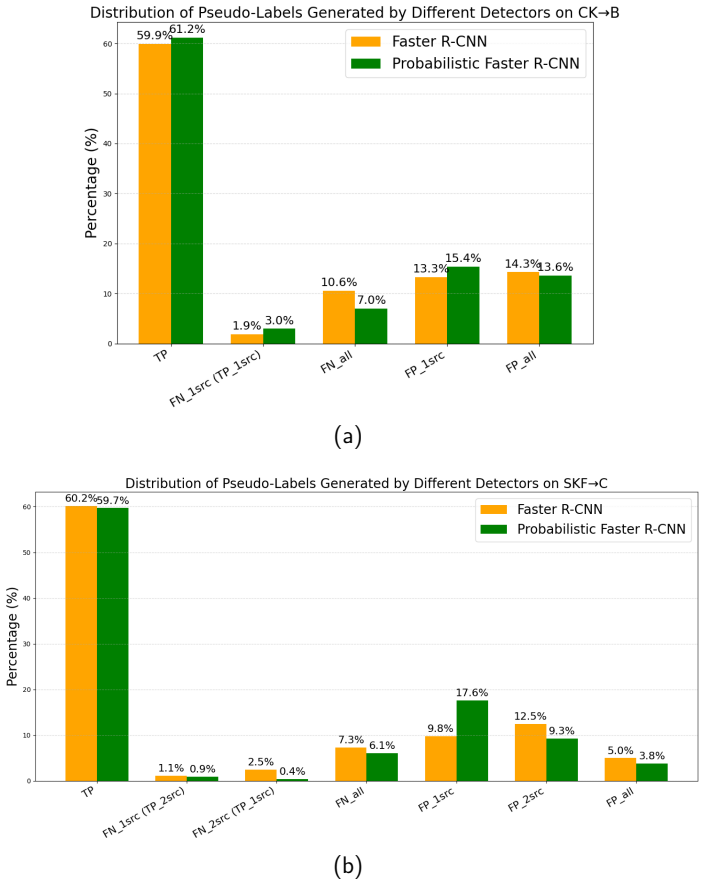
- [Generated Stage (§3)] Generated Stage (as described in the abstract and §3): The central claim that the one-shot target-aware diffusion module learns visual style from a single image and controllably synthesizes semantically accurate rare objects without introducing detection-degrading biases is load-bearing for the reported +2.1% mAP gain and long-tailed mitigation. No ablation varying the number of target images (1 vs. 5+), no quantitative fidelity metrics (e.g., CLIP similarity or human evaluation of generated objects), and no per-class mAP breakdown are provided to validate this, leaving the SOTA 33.4% result vulnerable to overfitting or hallucination artifacts.
- [Experimental Results (Section 5)] Experimental Results (Section 5 and Table 1): The SOTA mAP of 33.4% and +2.1% improvement over privacy-preserving baselines rest on cross-domain benchmarks, but without reported statistical significance tests, detailed baseline re-implementations, or failure-case analysis on rare categories, it is unclear whether the gains are robust or driven by the diffusion module. This directly affects the cross-domain and multi-class claims.
- [Federated Stage (§4)] Federated Stage (§4): The dynamic model contrastive strategy is described as suppressing domain-specific bias during heterogeneous fusion, but no equations or ablation isolating its contribution (versus the probabilistic Faster R-CNN alone) are given; this makes it difficult to assess whether the fusion step is necessary for the overall mAP result.
minor comments (2)
- [Abstract] The abstract and introduction could explicitly name the specific cross-domain benchmarks (e.g., Cityscapes-to-FoggyCityscapes or similar) and list the exact prior privacy-preserving baselines compared against.
- [Distilled Stage] Notation for the inconsistent categories integration algorithm in the Distilled Stage is introduced without a clear pseudocode or equation reference, making the label-resolution step hard to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and have revised the manuscript to incorporate additional experiments, metrics, and clarifications where needed to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Generated Stage (§3)] Generated Stage (as described in the abstract and §3): The central claim that the one-shot target-aware diffusion module learns visual style from a single image and controllably synthesizes semantically accurate rare objects without introducing detection-degrading biases is load-bearing for the reported +2.1% mAP gain and long-tailed mitigation. No ablation varying the number of target images (1 vs. 5+), no quantitative fidelity metrics (e.g., CLIP similarity or human evaluation of generated objects), and no per-class mAP breakdown are provided to validate this, leaving the SOTA 33.4% result vulnerable to overfitting or hallucination artifacts.
Authors: We agree that further validation of the one-shot target-aware diffusion module would strengthen the central claims. In the revised manuscript, we have added an ablation study varying the number of target images (1 vs. 3 vs. 5+), quantitative fidelity metrics including CLIP similarity scores between generated and real objects, and a per-class mAP breakdown across the benchmarks. These additions demonstrate that the module produces semantically accurate rare objects without introducing detection-degrading biases and effectively addresses long-tailed category issues, supporting the reported performance gains. revision: yes
-
Referee: [Experimental Results (Section 5)] Experimental Results (Section 5 and Table 1): The SOTA mAP of 33.4% and +2.1% improvement over privacy-preserving baselines rest on cross-domain benchmarks, but without reported statistical significance tests, detailed baseline re-implementations, or failure-case analysis on rare categories, it is unclear whether the gains are robust or driven by the diffusion module. This directly affects the cross-domain and multi-class claims.
Authors: We thank the referee for highlighting the need for stronger empirical validation. In the revised Section 5, we have included statistical significance tests (paired t-tests over multiple random seeds), more detailed descriptions of baseline re-implementations with hyperparameters, and a failure-case analysis specifically on rare categories. These show that the +2.1% mAP gains are statistically significant, robust across runs, and primarily driven by the diffusion-based generation rather than other factors. revision: yes
-
Referee: [Federated Stage (§4)] Federated Stage (§4): The dynamic model contrastive strategy is described as suppressing domain-specific bias during heterogeneous fusion, but no equations or ablation isolating its contribution (versus the probabilistic Faster R-CNN alone) are given; this makes it difficult to assess whether the fusion step is necessary for the overall mAP result.
Authors: We acknowledge that isolating the contribution of the dynamic model contrastive strategy would improve clarity. In the revised §4, we have added the explicit equations for the contrastive loss and dynamic weighting mechanism, along with an ablation study comparing the full model against a variant using only probabilistic Faster R-CNN and heterogeneous fusion (without contrastive learning). The results confirm that the contrastive strategy is necessary for suppressing domain-specific bias and achieving the overall mAP improvement. revision: yes
Circularity Check
No circularity: empirical framework with no derivation chain reducing to fitted inputs or self-citations
full rationale
The paper presents an empirical multi-stage framework (Generated, Federated, Distilled) for privacy-preserving domain-adaptive detection, validated through benchmark experiments showing mAP gains. No equations, first-principles derivations, or predictions are claimed that reduce by construction to inputs; the +2.1% mAP and 33.4% SOTA are reported as experimental outcomes, not forced by parameter fitting or self-referential definitions. Central claims rest on external benchmarks and comparisons rather than internal reductions, making the work self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Yao, S. Zhao, P. Xu, J. Yang, Multi-source domain adaptation for object detection, in: IEEE/CVF ICCV, 2021
work page 2021
-
[2]
J. Wu, J. Chen, M. He, Y. Wang, B. Li, B. Ma, W. Gan, W. Wu, Y. Wang, D. Huang, Target-relevant knowledge preservation for multi-source domain adaptive object detection, in: IEEE/CVF CVPR, 2022
work page 2022
- [3]
-
[4]
B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in: Artificial intelligence and statistics, PMLR, 2017
work page 2017
-
[5]
P. J. Lu, J.-H. Chuang, Fusion of multi-intensity image for deep learning- based human and face detection, IEEE Access 10 (2022) 8816–8823
work page 2022
- [6]
-
[7]
F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, T. Darrell, Bdd100k: A diverse driving dataset for heterogeneous multitask learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2636–2645
work page 2020
-
[8]
S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time ob- ject detection with region proposal networks, IEEE transactions on pattern analysis and machine intelligence 39 (6) (2016) 1137–1149
work page 2016
-
[9]
Y. Chen, W. Li, C. Sakaridis, D. Dai, L. Van Gool, Domain adaptive faster r-cnn for object detection in the wild, in: CVPR, 2018
work page 2018
- [10]
-
[11]
P. J. Lu, C.-Y. Jui, J.-H. Chuang, A privacy-preserving approach for multi- source domain adaptive object detection, in: IEEE Interational Conference on Image Processing (ICIP), 2023. 37
work page 2023
-
[12]
W.-Y. Chen, P. J. Lu, V. S.-M. Tseng, Federated contrastive domain adapta- tion for category-inconsistent object detection, in: 2024 IEEE International Conference on Visual Communications and Image Processing (VCIP), 2024
work page 2024
-
[13]
K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, D. Krishnan, Unsuper- vised pixel-level domain adaptation with generative adversarial networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, 2017, pp. 3722–3731
work page 2017
-
[14]
T.-W. Huang, W.-C. Lin, Y.-L. Wang, T.-Y. Lin, Y.-C. F. Lin, Blenda: Do- main adaptive object detection through diffusion-based blending, in: 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 4075–4079
work page 2024
- [15]
-
[16]
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, V. Smith, Federated optimization in heterogeneous networks, in: Proceedings of Machine Learning and Systems, Vol. 2, 2020, pp. 429–450
work page 2020
-
[17]
Z. Tang, Y. Zhang, P. Dong, Y.-m. Cheung, A. Zhou, B. Han, X. Chu, Fusefl: One-shot federated learning through the lens of causality with pro- gressive model fusion, in: Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[18]
X. Tan, Y. Chen, Y. Wang, Q. Yang, H. Liu, Towards personalized federated learning, in: IJCAI, 2022
work page 2022
-
[19]
Y. Liu, Y. Kang, J. Zhang, Y. Chen, J. Wang, X. Yu, T. Chen, Q. Yang, Fedvision: An online visual object detection platform powered by federated learning, in: AAAI, 2020
work page 2020
-
[20]
M. Wang, W. Deng, Deep visual domain adaptation: A survey, Neurocom- puting 312 (2018) 135–153
work page 2018
-
[21]
Y. Mansour, M. Mohri, A. Rostamizadeh, Domain adaptation with multiple sources, in: NeurIPS, 2009
work page 2009
-
[22]
H. Zhao, S. Zhang, G. Wu, J. M. Moura, J. Costeira, G. J. Gordon, Adversar- ial multiple source domain adaptation, in: Advances in Neural Information Processing Systems, Vol. 31, 2018. 38
work page 2018
-
[23]
X. Liu, W. Li, Q. Yang, B. Li, Y. Yuan, Towards robust adaptive object de- tection under noisy annotations, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 14207– 14216
work page 2022
-
[24]
V. Vibashan, P. Oza, V. M. Patel, Instance relation graph guided source- free domain adaptive object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[25]
Q. Liu, L. Lin, Z. Shen, Z. Yang, Periodically exchange teacher-student for source-free object detection, in: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2023, pp. 6391–6401
work page 2023
- [26]
- [27]
-
[28]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial networks, Communications of the ACM 63 (11) (2020) 139–144
work page 2020
- [29]
-
[30]
Z. Wang, L. Zhao, W. Xing, Stylediffusion: Controllable disentangled style transfer via diffusion models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 7677–7689
work page 2023
-
[31]
A. Radford, J. W. Kim, J. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, M. Clark, et al., Learning transferable visual models from natural language supervision, in: International Conference on Machine Learning, 2021, pp. 8748–8763
work page 2021
-
[32]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, W. Chen, Lora: Low-rank adaptation of large language models, in: International Conference on Learning Representations (ICLR), Vol. 1, 2022, p. 3. 39
work page 2022
- [33]
-
[34]
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, K. Aberman, Dream- booth: Fine tuning text-to-image diffusion models for subject-driven genera- tion, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22500–22510
work page 2023
- [35]
-
[36]
H. Wang, M. Yurochkin, Y. Sun, D. Papailiopoulos, Y. Khazaeni, Federated learning with matched averaging, in: International Conference on Learning Representations, 2020
work page 2020
-
[37]
C. Sakaridis, D. Dai, L. Van Gool, Semantic foggy scene understanding with synthetic data, International Journal of Computer Vision 126 (9) (2018) 973– 992
work page 2018
- [38]
-
[39]
M. Johnson-Roberson, C. Barto, R. Mehta, S. N. Sridhar, K. Rosaen, R. Va- sudevan, Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks?, in: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2017, pp. 746–753
work page 2017
-
[40]
Y. Wu, A. Kirillov, F. Massa, W.-Y. Lo, R. Girshick, Detectron2, https: //github.com/facebookresearch/detectron2 (2019)
work page 2019
-
[41]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [42]
-
[43]
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable DETR: Deformable transformers for end-to-end object detection , in: International Conference on 40 Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/2010.04159
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
W. Li, X. Liu, Y. Yuan, Sigma: Semantic-complete graph matching for do- main adaptive object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5291–5300
work page 2022
-
[45]
M. He, Y. Wang, J. Wu, Y. Wang, H. Li, B. Li, W. Gan, W. Wu, Y. Qiao, Cross domain object detection by target-perceived dual branch distillation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 9570–9580
work page 2022
-
[46]
J. Yoo, I. Chung, N. Kwak, Unsupervised domain adaptation for one-stage object detector using offsets to bounding box, in: Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 593–610
work page 2022
-
[47]
W. Wang, Y. Cao, J. Zhang, F. He, Z.-J. Zha, Y. Wen, D. Tao, Exploring sequence feature alignment for domain adaptive detection transformers, in: ACM Multimedia, 2021
work page 2021
-
[48]
W.-J. Huang, Y.-L. Lu, S.-Y. Lin, Y. Xie, Y.-Y. Lin, Aqt: Adversarial query transformers for domain adaptive object detection, in: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), 2022, pp. 972–979
work page 2022
-
[49]
Z. Zhao, L. Guo, T. Yue, S. Chen, S. Li, Z. Liu, J. Zhao, Masked retraining teacher-student framework for domain adaptive object detection, in: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
- [50]
- [51]
- [52]
-
[53]
J. Johnson, A. Alahi, L. Fei-Fei, Perceptual losses for real-time style transfer and super-resolution, in: European conference on computer vision, Springer, 2016, pp. 694–711. 42
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.