Recognition: unknown
EdgeLPR: On the Deep Neural Network trade-off between Precision and Performance in LiDAR Place Recognition
Pith reviewed 2026-05-09 15:59 UTC · model grok-4.3
The pith
LiDAR place recognition networks can use 16-bit precision to match full accuracy at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
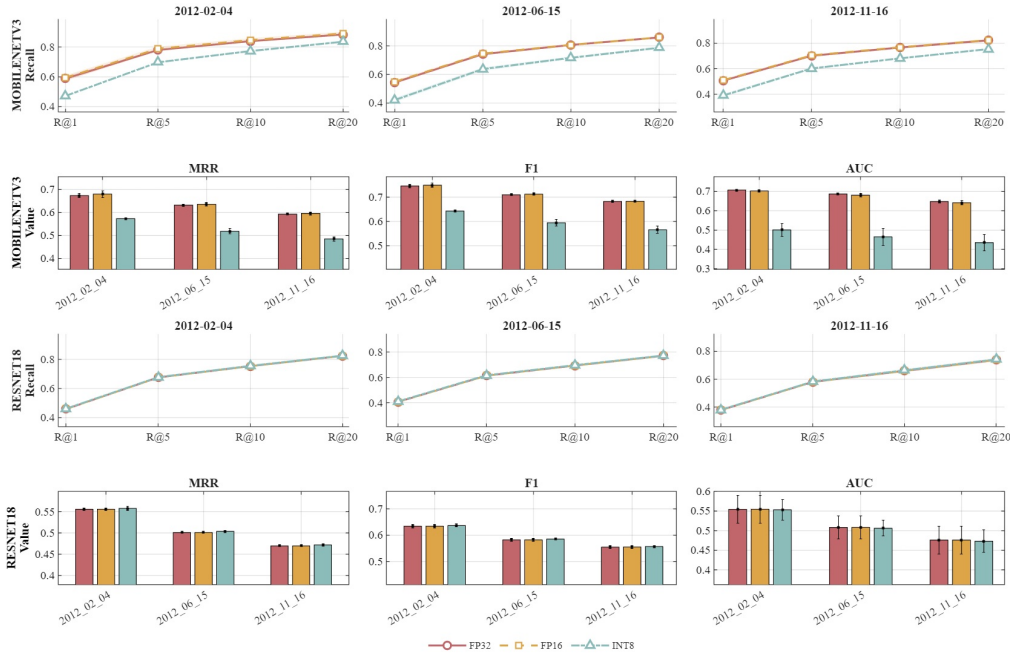
Experiments on representative architectures reveal that FP16 quantization maintains place recognition accuracy and robustness comparable to FP32 while reducing computational demands, whereas INT8 quantization results in degradations that depend on the specific architecture, providing a basis for use-case-aware quantization in EdgeAI applications.
What carries the argument
Benchmarking of image-based neural networks on bird's eye view LiDAR representations using a unified global pooling and linear projection descriptor, tested under FP32, FP16, and INT8 quantization levels.
If this is right
- FP16 precision offers a practical balance for efficient edge deployment in long-term autonomous navigation.
- INT8 quantization effects vary by architecture, requiring selection based on performance needs.
- The unified descriptor scheme enables direct comparison of quantization impacts across different backbones.
- Results form a foundation for tailoring precision choices to specific robotic use cases.
Where Pith is reading between the lines
- Similar trade-offs might appear in other sensor-based place recognition tasks beyond LiDAR.
- Hardware-specific testing could quantify actual power savings and speedups from FP16.
- Automated tools for choosing quantization levels per architecture could build on these findings.
- Extending the study to include aggregation heads might reveal different quantization behaviors.
Load-bearing premise
The quantization effects seen in the chosen networks without aggregation heads will generalize to the broader range of LiDAR place recognition pipelines.
What would settle it
A study showing that INT8 quantization achieves FP32-level accuracy across multiple additional architectures or that FP16 significantly reduces recall rates in standard benchmarks.
Figures

read the original abstract
Place recognition is essential for long-term autonomous navigation, enabling loop closure and consistent mapping. Although deep learning has improved performance, deploying such models on resource-constrained platforms remains challenging. This work explores efficient LiDAR-based place recognition for EdgeAI by leveraging Bird's Eye View representations to enable lightweight image-based networks. We benchmark representative architectures without aggregation heads using a unified descriptor scheme based on global pooling and linear projection, and evaluate performance under FP32, FP16, and INT8 quantization. Experiments reveal trade-offs between accuracy, robustness, and efficiency: FP16 matches FP32 with lower cost, while INT8 introduces architecture-dependent degradation. Overall, the presented results are a strong basis for future research on 'use-case'-aware quantisation of Neural Networks for Edge deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper explores efficient LiDAR-based place recognition for EdgeAI by converting point clouds to Bird's Eye View images and applying lightweight image-based CNNs. It benchmarks representative architectures without aggregation heads under a unified global-pooling-plus-linear-projection descriptor scheme, evaluating accuracy, robustness, and efficiency under FP32, FP16, and INT8 quantization. The central empirical claim is that FP16 matches FP32 performance at lower cost while INT8 exhibits architecture-dependent degradation; the results are presented as a basis for use-case-aware quantization in resource-constrained autonomous navigation.
Significance. If the reported trade-offs prove robust across datasets and metrics, the work supplies concrete empirical guidance for selecting quantization levels in edge-deployed LiDAR place recognition, identifying FP16 as a practical sweet spot and flagging INT8 risks for certain backbones. This could inform deployment decisions on embedded platforms where memory and compute are limited, though the absence of aggregation stages restricts immediate transfer to standard LiDAR PR pipelines.
major comments (1)
- [Abstract and experimental evaluation] The experimental evaluation (described in the abstract and methods) restricts all benchmarks to architectures without aggregation heads and employs only a unified global-pooling + linear-projection descriptor. Because typical LiDAR place-recognition pipelines rely on aggregation modules (NetVLAD, GeM, or attention-based pooling) that interact with the descriptor before matching, the observed architecture-dependent INT8 degradation could be an artifact of the global-pool choice rather than a general property; this directly limits the load-bearing claim that the results support broader 'use-case'-aware quantization recommendations.
minor comments (1)
- [Abstract] The abstract states clear experimental outcomes but does not name the datasets, recall@1 / recall@5 metrics, or any error bars / statistical tests used to support the FP16/INT8 comparisons; adding these details would improve immediate assessability even if they appear in the full results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and propose targeted revisions to clarify the scope of our claims.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The experimental evaluation (described in the abstract and methods) restricts all benchmarks to architectures without aggregation heads and employs only a unified global-pooling + linear-projection descriptor. Because typical LiDAR place-recognition pipelines rely on aggregation modules (NetVLAD, GeM, or attention-based pooling) that interact with the descriptor before matching, the observed architecture-dependent INT8 degradation could be an artifact of the global-pool choice rather than a general property; this directly limits the load-bearing claim that the results support broader 'use-case'-aware quantization recommendations.
Authors: We thank the referee for highlighting this consideration. Our experimental design explicitly isolates the quantization behavior of the backbone CNNs by using a minimal, unified descriptor (global pooling followed by linear projection) without aggregation heads. This choice enables fair, architecture-to-architecture comparison and direct attribution of any INT8 degradation to the interaction between network structure and quantization, rather than to variable aggregation strategies. The abstract and methods sections already state this restriction, and our conclusions are framed as supplying empirical guidance and a basis for future research on use-case-aware quantization, not as universal claims for full pipelines. While we acknowledge that aggregation modules (NetVLAD, GeM, attention) are standard in deployed LiDAR PR systems and could interact with the observed effects, the controlled baseline we provide remains valuable for understanding the core feature extractors. In revision we will (i) strengthen the abstract wording to foreground the absence of aggregation heads and (ii) add a dedicated paragraph in the discussion that explicitly discusses potential interactions with common aggregation techniques and positions our results as a starting point for full-pipeline studies. revision: partial
Circularity Check
Empirical benchmarking paper with no derivation chain or self-referential predictions
full rationale
The paper conducts direct experimental comparisons of quantization levels (FP32, FP16, INT8) on representative LiDAR place recognition networks using a fixed global-pooling descriptor scheme. No equations, fitted parameters, uniqueness theorems, or predictions are presented that could reduce to the inputs by construction. All central claims are observational results from the reported runs, with no load-bearing self-citations or ansatzes that close a loop back to the same data or assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A roadmap for ai in robotics,
A. Billard, A. Albu-Schaeffer, M. Beetz, W. Burgard, P. Corke, M. Ciocarlie, R. Dahiya, D. Kragic, K. Goldberg, Y . Nagaiet al., “A roadmap for ai in robotics,”Nature Machine Intelligence, vol. 7, no. 6, pp. 818–824, 2025
2025
-
[2]
Artificial intel- ligence in agri-robotics: A systematic review of trends and emerging directions leveraging bibliometric tools,
S. Casini, P. Ducange, F. Marcelloni, and L. Pollini, “Artificial intel- ligence in agri-robotics: A systematic review of trends and emerging directions leveraging bibliometric tools,”Robotics, vol. 15, no. 1, p. 24, 2026
2026
-
[3]
A mentalistic interface for probing folk-psychological attribution to non-humanoid robots,
G. Pisaneschi, P. Serio, E. Gerbier, A. D. Ryals, L. Pollini, and M. G. C. A. Cimino, “A mentalistic interface for probing folk-psychological attribution to non-humanoid robots,” 2026. [Online]. Available: https://arxiv.org/abs/2603.25646
-
[4]
The role of machine learning in improving robotic perception and decision making,
S.-C. Chen, R. S. Pamungkas, and D. Schmidt, “The role of machine learning in improving robotic perception and decision making,”In- ternational Transactions on Artificial Intelligence, vol. 3, no. 1, pp. 32–43, 2024
2024
-
[5]
Sift, surf & seasons: Appearance- based long-term localization in outdoor environments,
C. Valgren and A. J. Lilienthal, “Sift, surf & seasons: Appearance- based long-term localization in outdoor environments,”Robotics and Autonomous Systems, vol. 58, no. 2, pp. 149–156, 2010
2010
-
[6]
Bags of binary words for fast place recognition in image sequences,
D. G ´alvez-L´opez and J. D. Tardos, “Bags of binary words for fast place recognition in image sequences,”IEEE Transactions on robotics, vol. 28, no. 5, pp. 1188–1197, 2012
2012
-
[7]
Netvlad: Cnn architecture for weakly supervised place recognition,
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” inPro- ceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5297–5307
2016
-
[8]
Lidar-based place recognition for autonomous driving: A survey,
Y . Zhang, P. Shi, and J. Li, “Lidar-based place recognition for autonomous driving: A survey,”ACM Computing Surveys, vol. 57, no. 4, pp. 1–36, 2024
2024
-
[9]
Lidar-based global localization using histogram of orientations of principal normals,
L. Luo, S.-Y . Cao, Z. Sheng, and H.-L. Shen, “Lidar-based global localization using histogram of orientations of principal normals,” IEEE Transactions on Intelligent Vehicles, vol. 7, no. 3, pp. 771–782, 2022
2022
-
[10]
Scan context: Egocentric spatial descriptor for place recognition within 3d point cloud map,
G. Kim and A. Kim, “Scan context: Egocentric spatial descriptor for place recognition within 3d point cloud map,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 4802–4809
2018
-
[11]
Scan context++: Structural place recog- nition robust to rotation and lateral variations in urban environments,
G. Kim, S. Choi, and A. Kim, “Scan context++: Structural place recog- nition robust to rotation and lateral variations in urban environments,” IEEE Transactions on Robotics, vol. 38, no. 3, pp. 1856–1874, 2021
2021
-
[12]
Intensity scan context: Coding intensity and geometry relations for loop closure detection,
H. Wang, C. Wang, and L. Xie, “Intensity scan context: Coding intensity and geometry relations for loop closure detection,” in2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 2095–2101
2020
-
[13]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
2017
-
[14]
Sonata: Self-supervised learn- ing of reliable point representations,
X. Wu, D. DeTone, D. Frost, T. Shen, C. Xie, N. Yang, J. Engel, R. Newcombe, H. Zhao, and J. Straub, “Sonata: Self-supervised learn- ing of reliable point representations,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 193–22 204
2025
- [15]
-
[16]
Imlpr: Image-based lidar place recognition using vision foundation models,
M. Jung, L. F. T. Fu, M. Fallon, and A. Kim, “Imlpr: Image-based lidar place recognition using vision foundation models,”arXiv preprint arXiv:2505.18364, 2025
-
[17]
Bevplace: Learning lidar-based place recognition using bird’s eye view images,
L. Luo, S. Zheng, Y . Li, Y . Fan, B. Yu, S.-Y . Cao, J. Li, and H.-L. Shen, “Bevplace: Learning lidar-based place recognition using bird’s eye view images,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 8700–8709
2023
-
[18]
Bevplace++: Fast, robust, and lightweight lidar global localization for unmanned ground vehicles,
L. Luo, S.-Y . Cao, X. Li, J. Xu, R. Ai, Z. Yu, and X. Chen, “Bevplace++: Fast, robust, and lightweight lidar global localization for unmanned ground vehicles,”IEEE Transactions on Robotics, 2025
2025
-
[19]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[20]
Shufflenet: An extremely effi- cient convolutional neural network for mobile devices,
X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely effi- cient convolutional neural network for mobile devices,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6848–6856
2018
-
[21]
Post training 4-bit quanti- zation of convolutional networks for rapid-deployment,
R. Banner, Y . Nahshan, and D. Soudry, “Post training 4-bit quanti- zation of convolutional networks for rapid-deployment,”Advances in neural information processing systems, vol. 32, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.