Recognition: 3 theorem links
· Lean TheoremWhen Stress Becomes Signal: Detecting Antifragility-Compatible Regimes in Multi-Agent LLM Systems
Pith reviewed 2026-05-08 18:26 UTC · model grok-4.3
The pith
Semantic stress lowers immediate quality in multi-agent LLM systems by about one third but produces positive distributional Jensen Gaps across all tested architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
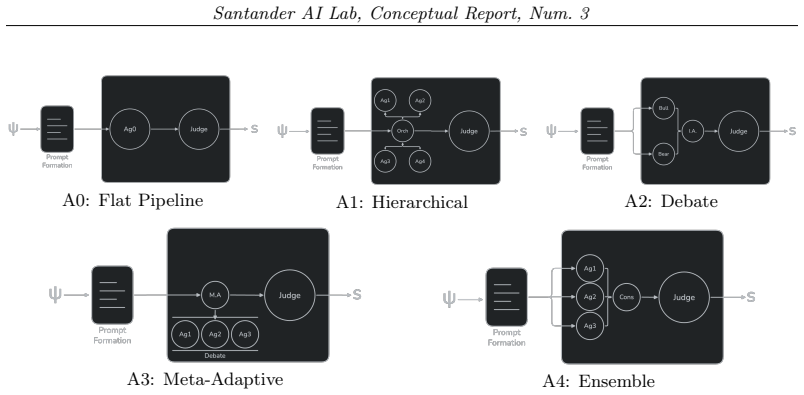
Immediate quality degradation from semantic stress can coexist with statistically detectable antifragility-compatible stress geometry in multi-agent LLM systems, shown by positive distributional Jensen Gaps under a convex stress potential in the CAFE framework across flat, hierarchical, debate, meta-adaptive, and ensemble architectures.
What carries the argument
The distributional Jensen Gap under a convex stress potential, which compares a controlled expected distribution of semantic stressors to the architecture-specific observed effective stress distribution reconstructed from judge signals.
If this is right
- Stress exposure can be treated as a potential signal rather than pure noise in multi-agent LLM evaluation.
- Architectures can be ranked by the magnitude of their Jensen Gap to prioritize those with greater apparent antifragility potential.
- CAFE provides a measurement layer that could guide where to invest in antifragile training methods.
- Quality drops under stress do not rule out long-term improvement if the stress distribution expands convexly.
Where Pith is reading between the lines
- The framework could be extended to track whether positive gaps actually predict measurable learning gains when agents are allowed to adapt over repeated stress episodes.
- Similar stress-geometry analysis might apply to single-agent systems or non-LLM multi-agent setups to test generality beyond the banking benchmark.
- If the gap reliably signals learnable structure, designers might deliberately introduce calibrated semantic stress instead of minimizing it.
Load-bearing premise
A positive distributional Jensen Gap under a convex stress potential indicates antifragility-compatible regimes that could support future learning rather than reflecting only modeling choices or judge artifacts.
What would settle it
An experiment that applies an antifragility learning procedure to architectures with positive versus zero or negative Jensen Gaps and finds no difference in subsequent adaptation rates.
Figures






read the original abstract
Multi-agent LLM systems are increasingly used to solve complex tasks through decomposition, debate, specialization, and ensemble reasoning. However, these systems are usually evaluated in terms of robustness: whether performance is preserved under perturbation. This paper studies a different question: whether semantic stress exposes structured variation that could support future antifragile learning. We introduce CAFE (Cognitive Antifragility Framework for Evaluation), a statistical framework for detecting antifragility-compatible regimes in multi-agent architectures. CAFE models a controlled expected distribution of semantic stressors, reconstructs an architecture-specific observed effective stress distribution from multi-dimensional judge signals, and compares both distributions using a distributional Jensen Gap under a convex stress potential. A positive gap does not imply immediate performance improvement; instead, it indicates a convex-expansive deformation of the observed stress distribution, suggesting that the architecture exposes learnable stress structure. We evaluate CAFE on a banking-risk analysis benchmark with five multi-agent architectures: flat, hierarchical, debate, meta-adaptive, and ensemble. Across all architectures, semantic stress reduces average judged quality by roughly one third. Yet all architectures exhibit positive distributional Jensen Gaps with bootstrap confidence intervals above zero. These results show that immediate quality degradation can coexist with statistically detectable antifragility-compatible stress geometry. CAFE is therefore not an antifragile learner itself, but a measurement layer for identifying when and where antifragility learning may be worth applying.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CAFE (Cognitive Antifragility Framework for Evaluation) statistical framework for detecting antifragility-compatible regimes in multi-agent LLM systems. It models a controlled expected distribution of semantic stressors, reconstructs an architecture-specific observed effective stress distribution from multi-dimensional judge signals, and compares them via a distributional Jensen Gap under a convex stress potential. On a banking-risk analysis benchmark with five architectures (flat, hierarchical, debate, meta-adaptive, ensemble), semantic stress reduces average judged quality by roughly one third, yet all architectures exhibit positive Jensen Gaps with bootstrap confidence intervals above zero. The central claim is that this indicates convex-expansive deformation exposing learnable stress structure, even without immediate performance gains.
Significance. If the central claim holds after addressing modeling details, the work offers a useful measurement layer for identifying when multi-agent LLM systems may support future antifragile learning, distinguishing this from standard robustness checks. The evaluation across multiple architectures and the explicit separation of quality degradation from positive gap geometry are strengths that could guide adaptive system design. However, significance is tempered by the need to demonstrate that the gap is not reducible to choices in distribution reconstruction or potential selection.
major comments (2)
- [Abstract / CAFE framework] Abstract and CAFE framework section: The positive distributional Jensen Gap is the load-bearing result for the antifragility-compatible claim, but it depends on the specific convex stress potential and the reconstruction of the observed distribution from judge signals; without shown robustness to alternative potentials or explicit exclusion rules for the bootstrap intervals, the gap risks being an artifact of these modeling choices rather than evidence of learnable structure.
- [Results] Results section on Jensen Gaps: The interpretation that a positive gap indicates 'convex-expansive deformation' exposing learnable stress structure requires a direct link to adaptation or learning gains; the current evidence (quality drop of ~1/3 coexisting with gaps >0) does not yet rule out that the gap arises from aggregation/normalization of judge signals or post-hoc fitting of the expected vs. observed distributions.
minor comments (2)
- [Abstract] Abstract: Bootstrap confidence intervals are mentioned without specifying the number of resamples, the underlying data distribution, or how judge signal definitions are operationalized.
- [Evaluation] Evaluation setup: More detail is needed on the banking-risk benchmark task decomposition and how multi-dimensional judge signals are aggregated into the observed distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important considerations for the robustness of the Jensen Gap results and the interpretation of antifragility-compatible regimes. We address each major comment below, indicating where we will incorporate revisions to strengthen the work while preserving the paper's focus on detection rather than direct learning demonstrations.
read point-by-point responses
-
Referee: [Abstract / CAFE framework] Abstract and CAFE framework section: The positive distributional Jensen Gap is the load-bearing result for the antifragility-compatible claim, but it depends on the specific convex stress potential and the reconstruction of the observed distribution from judge signals; without shown robustness to alternative potentials or explicit exclusion rules for the bootstrap intervals, the gap risks being an artifact of these modeling choices rather than evidence of learnable structure.
Authors: We agree that robustness to modeling choices is essential for the claim. The quadratic convex stress potential was selected for its consistency with convex-expansive deformation in the antifragility literature, and the observed distribution reconstruction follows directly from the multi-dimensional judge signals as specified in Section 3.2 without additional post-hoc fitting. In the revision, we will add a sensitivity analysis subsection testing two alternative convex potentials (exponential and piecewise-linear) and report the resulting Jensen Gaps with updated bootstrap intervals. We will also document explicit outlier exclusion rules (e.g., 2.5 standard deviations from the resampled mean) in the bootstrap procedure. These additions will clarify that the positive gaps persist under reasonable variations. revision: partial
-
Referee: [Results] Results section on Jensen Gaps: The interpretation that a positive gap indicates 'convex-expansive deformation' exposing learnable stress structure requires a direct link to adaptation or learning gains; the current evidence (quality drop of ~1/3 coexisting with gaps >0) does not yet rule out that the gap arises from aggregation/normalization of judge signals or post-hoc fitting of the expected vs. observed distributions.
Authors: The manuscript explicitly states that positive gaps indicate exposure of learnable structure without claiming immediate performance gains or completed adaptation (see abstract and Section 4). The expected distribution is constructed from controlled semantic stressors prior to observing the data (Section 3.1), and the observed distribution is reconstructed from raw judge signals with only standard normalization; no post-hoc fitting aligns the two. To further address potential aggregation artifacts, the revision will include an ablation comparing Jensen Gaps computed on raw versus normalized signals across architectures. While we cannot demonstrate subsequent learning gains in this work—as CAFE is positioned as a measurement framework rather than an adaptive learner—the coexistence of quality degradation with positive gaps across five distinct architectures provides evidence against the gap being a pure artifact of the chosen reconstruction. revision: partial
Circularity Check
No significant circularity; empirical measurement framework with data-driven results
full rationale
The paper introduces the CAFE framework to model an expected stressor distribution, reconstruct an observed distribution from judge signals, and compute a distributional Jensen Gap under a convex potential. It then reports concrete empirical outcomes from a banking-risk benchmark run on five distinct multi-agent architectures: average quality drops by roughly one third under stress, yet all five yield positive Jensen Gaps whose bootstrap confidence intervals lie above zero. These are presented as observed statistical facts rather than derived predictions. No equations reduce the gap positivity to a tautology, no parameters are fitted on the target data and then relabeled as predictions, and no load-bearing claims rest on self-citations. The interpretive link between positive gap and 'antifragility-compatible regimes' is definitional to the proposed metric but does not collapse the reported measurements into their own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- convex stress potential
axioms (1)
- domain assumption Semantic stressors admit a controlled expected distribution that can be compared to an architecture-specific observed distribution via judge signals.
invented entities (1)
-
CAFE framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J(x)=½(x+x⁻¹)−1, convex, ratio-symmetric)Cost.FunctionalEquation.washburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
compares both distributions using a distributional Jensen Gap under a convex stress potential. A positive gap ... indicates a convex-expansive deformation of the observed stress distribution
-
Foundation/AlphaCoordinateFixation.lean (J fixed by 4th-derivative calibration, not arbitrary quadratic potential)AlphaCoordinateFixation.J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
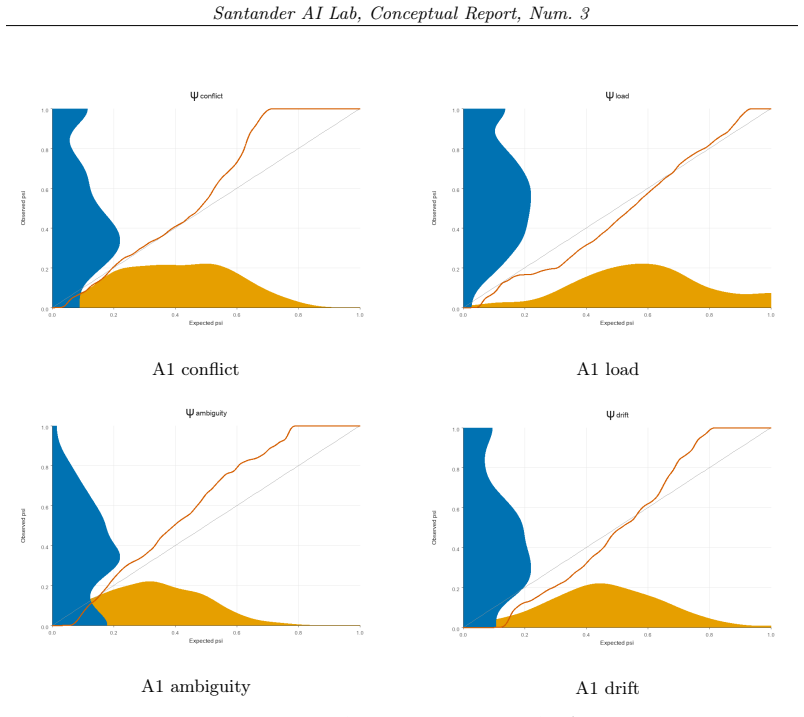
In the experiments we use ϕ(x) = ‖x‖₂², so the statistic measures total dispersion around the mean stress vector.
-
Foundation/AlexanderDuality.lean (D=3 forced by linking topology) — paper's 4-D stress cube has no relation to RS's spatial-dimension forcingAlexanderDuality.alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
stress vector ψ = (ψ_conflict, ψ_load, ψ_ambiguity, ψ_drift) ∈ [0,1]⁴
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mathematical definition, mapping, and detec- tion of (anti) fragility
Nassim Nicholas Taleb and Raphael Douady. “Mathematical definition, mapping, and detec- tion of (anti) fragility”. In:Quantitative Finance13.11 (2013), pp. 1677–1689
2013
-
[2]
’Antifragility’as a mathematical idea
Nassim N Taleb. “’Antifragility’as a mathematical idea”. In:Nature494.7438 (2013), pp. 430– 430
2013
-
[3]
Working with convex responses: Antifragility from finance to oncology
Nassim Nicholas Taleb and Jeffrey West. “Working with convex responses: Antifragility from finance to oncology”. In:Entropy25.2 (2023), p. 343
2023
-
[4]
Antifragility analysis and measurement framework for systems of systems
John Johnson and Adrian V Gheorghe. “Antifragility analysis and measurement framework for systems of systems”. In:International journal of disaster risk science4.4 (2013), pp. 159– 168
2013
-
[5]
Towards antifragile software architectures
Daniel Russo and Paolo Ciancarini. “Towards antifragile software architectures”. In: vol. 109. Elsevier, 2017, pp. 929–934
2017
-
[6]
Towards antifragility of cloudsystems:Anadaptivechaosdrivenframework
Joseph S Botros, Lamis F Al-Qora’n, and Amro Al-Said Ahmad. “Towards antifragility of cloudsystems:Anadaptivechaosdrivenframework”.In:Information and Software Technology 174 (2024), p. 107519
2024
-
[7]
Design and analysis of computer experiments
Jerome Sacks, William J Welch, Toby J Mitchell, and Henry P Wynn. “Design and analysis of computer experiments”. In:Statistical science4.4 (1989), pp. 409–423. 14 Santander AI Lab, Conceptual Report, Num. 3
1989
-
[8]
Divergence measures based on the Shannon entropy
Jianhua Lin. “Divergence measures based on the Shannon entropy”. In:IEEE Transactions on Information theory37.1 (2002), pp. 145–151
2002
-
[9]
A kernel two-sample test
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. “A kernel two-sample test”. In:The journal of machine learning research13.1 (2012), pp. 723–773
2012
-
[10]
Energy statistics: A class of statistics based on dis- tances
Gábor J Székely and Maria L Rizzo. “Energy statistics: A class of statistics based on dis- tances”. In:Journal of statistical planning and inference143.8 (2013), pp. 1249–1272
2013
-
[11]
Autogen: Enabling next-gen LLM applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xi- aoyun Zhang, Shaokun Zhang, Jiale Liu, et al. “Autogen: Enabling next-gen LLM applications via multi-agent conversations”. In:First conference on language modeling. 2024
2024
-
[12]
Camel: Communicative agents for
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. “Camel: Communicative agents for" mind" exploration of large language model society”. In:Advances in neural information processing systems36 (2023), pp. 51991–52008
2023
-
[13]
MetaGPT: Meta program- ming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. “MetaGPT: Meta program- ming for a multi-agent collaborative framework”. In:The twelfth international conference on learning representations. 2023
2023
-
[14]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest,andXiangliangZhang.“Largelanguagemodelbasedmulti-agents:Asurveyofprogress and challenges”. In:arXiv preprint arXiv:2402.01680(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. “Improv- ing factuality and reasoning in language models through multiagent debate”. In:Forty-first international conference on machine learning. 2024
2024
-
[16]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. “Self-consistency improves chain of thought reasoning in lan- guage models”. In:arXiv preprint arXiv:2203.11171(2022)
work page Pith review arXiv 2022
-
[17]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegr- effe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. “Self-refine: Iterative refinement with self-feedback, 2023”. In:URL https://arxiv. org/abs/2303.176512303 (2023)
work page internal anchor Pith review arXiv 2023
-
[18]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. “Reflexion: Language agents with verbal reinforcement learning”. In:Advances in neural in- formation processing systems36 (2023), pp. 8634–8652
2023
-
[19]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. “Tree of thoughts: Deliberate problem solving with large language models”. In: Advances in neural information processing systems36 (2023), pp. 11809–11822
2023
-
[20]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. “React: Synergizing reasoning and acting in language models”. In:arXiv preprint arXiv:2210.03629(2022)
work page internal anchor Pith review arXiv 2022
-
[21]
Beyond accuracy: Behavioral testing of NLP models with CheckList
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. “Beyond accuracy: Behavioral testing of NLP models with CheckList”. In:Proceedings of the 58th annual meeting of the association for computational linguistics. 2020, pp. 4902–4912
2020
-
[22]
Robustness gym: Unifying the NLP evaluation landscape
Karan Goel, Nazneen Fatema Rajani, Jesse Vig, Zachary Taschdjian, Mohit Bansal, and Christopher Ré. “Robustness gym: Unifying the NLP evaluation landscape”. In:Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations. 2021, pp. 42–55
2021
-
[23]
Dynabench: Re- thinking benchmarking in NLP
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. “Dynabench: Re- thinking benchmarking in NLP”. In:Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies. 2021, p...
2021
-
[24]
Holistic Evaluation of Language Models
PercyLiang,RishiBommasani,TonyLee,DimitrisTsipras,DilaraSoylu,MichihiroYasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. “Holistic evaluation of language models”. In:arXiv preprint arXiv:2211.09110(2022)
work page internal anchor Pith review arXiv 2022
-
[25]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. “FEVER: a large-scale dataset for fact extraction and VERification”. In:Proceedings of the 2018 Con- ference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018, pp. 809–819
2018
-
[26]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. “Truthfulqa: Measuring how models mimic human falsehoods”. In:Proceedings of the 60th annual meeting of the association for compu- tational linguistics (volume 1: long papers). 2022, pp. 3214–3252
2022
-
[27]
AmbigQA: Answer- ing ambiguous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. “AmbigQA: Answer- ing ambiguous open-domain questions”. In:Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 2020, pp. 5783–5797
2020
-
[28]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. “LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding”. In:arXiv preprint arXiv:2308.14508(2023)
work page internal anchor Pith review arXiv 2023
-
[29]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. “Red Teaming Language Models with Language Models”. In:Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022, pp. 3419–3448.doi:10.18653/v1/2022.emnlp-main.225
-
[30]
G- eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. “G- eval: NLG evaluation using gpt-4 with better human alignment”. In:Proceedings of the 2023 conference on empirical methods in natural language processing. 2023, pp. 2511–2522
2023
-
[31]
Judging llm-as-a-judge with mt-bench and chatbot arena
LianminZheng,Wei-LinChiang,YingSheng,SiyuanZhuang,ZhanghaoWu,YonghaoZhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena”. In:Advances in neural information processing systems36 (2023), pp. 46595– 46623
2023
-
[32]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. “Chat- bot arena: An open platform for evaluating llms by human preference”. In:arXiv preprint arXiv:2403.04132(2024). 16 Santander AI Lab, Conceptual Report, Num. 3 A Marginal Stress Deformat...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.