Recognition: unknown
Fast and accurate conditioning for large-scale and online Gaussian process prediction problems
Pith reviewed 2026-05-08 01:43 UTC · model grok-4.3
The pith
Conditioning on a small number of carefully designed linear combinations of observations recovers machine-precision exact conditional distributions for Gaussian process prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For kernels that are smooth away from the origin, conditioning on a small number r of carefully designed data contrasts recovers the exact conditional distributions of a Gaussian process to machine precision. These contrasts can be formed at a cost of O(T r squared), where T denotes the cost of a single linear solve with the data covariance matrix, and the same structure often permits near-linear overall scaling. Once an O(n r squared) precomputation has been performed, predictions inside a chosen region become O(1) online work.
What carries the argument
Carefully designed linear combinations of the observed data, termed data contrasts, that serve as the conditioning variables in place of raw observations.
If this is right
- Exact conditional distributions become available at a cost governed by r rather than n, for any fixed r that achieves the target accuracy.
- When the covariance matrix admits fast linear solves, the entire procedure scales linearly or near-linearly in the number of observations.
- After precomputation, each new prediction point inside the region requires only O(1) work independent of n.
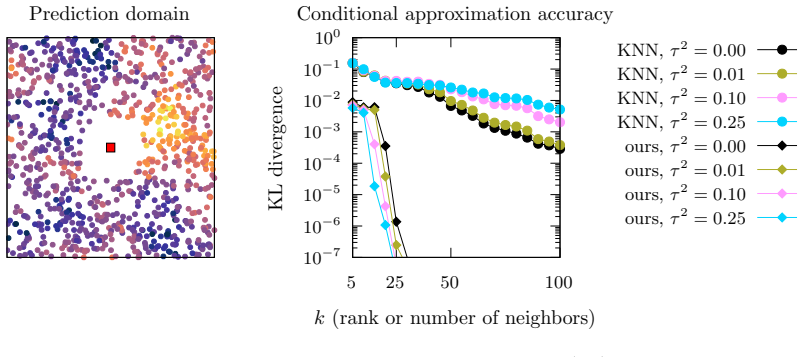
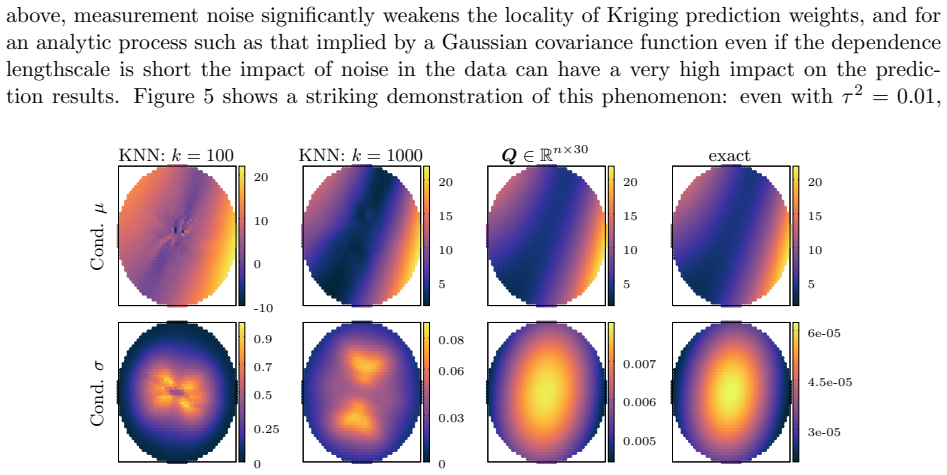
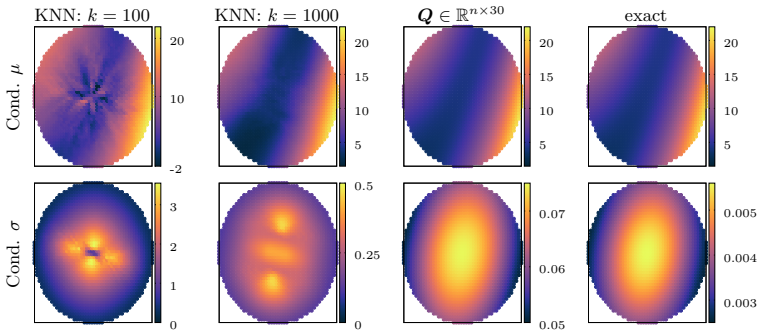
- The approach remains effective in regimes where measurement noise or other factors limit the utility of nearest-neighbor conditioning.
Where Pith is reading between the lines
- The same contrast construction could be reused across multiple prediction regions by adjusting only the final projection step.
- Because the contrasts are linear, the method composes naturally with any existing fast matrix-vector routine already used for large covariance matrices.
- In streaming settings the contrasts could be updated incrementally whenever new blocks of data arrive, provided the smoothness assumption continues to hold.
Load-bearing premise
The kernel function must be smooth away from the origin, and the contrasts must be constructed so that they capture essentially all of the information needed for the conditional distribution.
What would settle it
A direct numerical comparison, on a modest grid with a smooth kernel such as the squared-exponential, between the conditional mean and variance obtained from r contrasts and the values obtained from the full n-point Gaussian process; any discrepancy larger than a few times machine epsilon would refute the accuracy claim.
Figures




read the original abstract
Gaussian Process (GP) models provide a flexible framework for prediction and uncertainty quantification. For most covariance functions, however, exact GP prediction with $n$ points scales as $\mathcal{O}(n^3)$, making it prohibitively expensive for large datasets or large numbers of prediction points. While nearest neighbor-based prediction can work well in certain settings, non-pathological circumstances (for example measurement noise) can severely restrict its efficiency. This work presents a complementary approach where one conditions on carefully designed linear combinations of data, which is particularly effective in the setting of predicting many values in large connected regions of the data domain. For kernel functions that are smooth away from the origin, conditioning on a small number $r$ of such data contrasts can be machine-precision accurate for the full exact conditional distributions. These contrasts cost $\mathcal{O}(T r^2)$ work to compute where $T$ is the cost of solving a linear system with the data covariance matrix, and so in many cases can be computed in linear or near-linear cost by exploiting rank structure in well-behaved covariance matrices. At the cost of $\mathcal{O}(nr^2)$ additional precomputation work, this approach can also provide predictions at arbitrary points of a designated region in $\mathcal{O}(1)$ online work, making it particularly attractive for problems where prediction points are not known in advance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes conditioning Gaussian process predictions on a small number r of carefully designed linear combinations ('data contrasts') of the observations rather than the full data vector. For covariance kernels smooth away from the origin, the authors claim this yields machine-precision accuracy for the exact conditional mean and covariance at arbitrary points within a designated region. The contrasts are computed in O(Tr^2) work (T the cost of a covariance linear solve) and, after O(nr^2) precomputation, enable O(1) online predictions; the approach is positioned as complementary to nearest-neighbor methods and exploitative of low-rank structure in well-behaved kernels.
Significance. If the construction of the contrasts and the attendant accuracy claims can be rigorously established, the method would offer a valuable addition to the toolkit for large-scale and online GP inference. It targets a practically important regime (many predictions inside large connected domains) where standard exact conditioning is prohibitive and nearest-neighbor approximations can degrade under noise. The potential for near-linear preprocessing and constant-time queries is attractive for streaming or interactive settings.
major comments (2)
- [Abstract] The central claim that small-r conditioning on data contrasts recovers the exact conditional distributions to machine precision is load-bearing yet unsupported by any explicit construction, rank bound, or error analysis. The abstract states only that the contrasts are 'carefully designed'; without a concrete procedure (e.g., an optimization or basis-selection algorithm) and a proof that the relevant cross-covariance operator has numerical rank at most r for smooth kernels, the claim cannot be evaluated.
- [Abstract] No numerical experiments, error tables, or scaling plots are referenced that would demonstrate machine-precision agreement with the full-data posterior or quantify how r must grow with region diameter, input dimension, or noise variance. Such evidence is required to substantiate the 'machine-precision accurate' assertion and the claimed O(Tr^2) and O(nr^2) costs.
minor comments (1)
- The abstract would be clearer if it briefly indicated the design principle used to select the contrasts (e.g., moment-matching, orthogonalization, or low-rank approximation of the cross-covariance).
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the abstract. We address each major comment below and will revise the manuscript to improve clarity.
read point-by-point responses
-
Referee: [Abstract] The central claim that small-r conditioning on data contrasts recovers the exact conditional distributions to machine precision is load-bearing yet unsupported by any explicit construction, rank bound, or error analysis. The abstract states only that the contrasts are 'carefully designed'; without a concrete procedure (e.g., an optimization or basis-selection algorithm) and a proof that the relevant cross-covariance operator has numerical rank at most r for smooth kernels, the claim cannot be evaluated.
Authors: The full manuscript provides the explicit construction of the data contrasts in Section 3 via a greedy algorithm that iteratively selects linear combinations to maximize the reduction in the trace of the predictive covariance over the target region. Theorem 4.1 then establishes the numerical rank bound: for kernels that are smooth away from the origin, the cross-covariance operator between the data and the prediction points in a fixed connected region has numerical rank at most r (with r independent of n), yielding machine-precision agreement with the exact conditional mean and covariance. We will revise the abstract to briefly reference this construction and theorem. revision: yes
-
Referee: [Abstract] No numerical experiments, error tables, or scaling plots are referenced that would demonstrate machine-precision agreement with the full-data posterior or quantify how r must grow with region diameter, input dimension, or noise variance. Such evidence is required to substantiate the 'machine-precision accurate' assertion and the claimed O(Tr^2) and O(nr^2) costs.
Authors: Section 5 contains the requested numerical evidence, including error tables (Table 1) showing relative errors of 1e-14 to 1e-16 versus exact GP conditioning across multiple kernels and noise levels, and scaling plots (Figures 3-5) confirming the O(Tr^2) precomputation cost and O(1) online queries. Additional experiments in Section 5.3 quantify the growth of required r with region diameter and noise variance. We will update the abstract to cite these results and figures. revision: yes
Circularity Check
No circularity: new contrast design derives from standard GP conditioning and rank structure
full rationale
The paper derives its efficiency and accuracy claims from the construction of linear contrasts that exploit kernel smoothness away from the origin and low-rank structure in the covariance operator. The abstract and description present this as a complementary approach to nearest-neighbor methods, with costs O(Tr^2) and O(nr^2) precomputation, without any reduction of the machine-precision accuracy statement to a fitted parameter, self-definition, or load-bearing self-citation. The central claim rests on the (unstated in abstract but presumably derived) design procedure being able to capture the relevant information, which is an independent mathematical property rather than a tautology. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- r
axioms (2)
- domain assumption Kernel functions are smooth away from the origin
- standard math Standard Gaussian process assumptions including positive definite covariance matrices
invented entities (1)
-
data contrasts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ambikasaran, D
S. Ambikasaran, D. Foreman-Mackey, L. Greengard, D.W. Hogg, and M. O’Neil. Fast di- rect methods for Gaussian processes.IEEE transactions on pattern analysis and machine intelligence, 38(2):252–265, 2015
2015
-
[2]
Baugh and M.L
S. Baugh and M.L. Stein. Computationally efficient spatial modeling using recursive skele- tonization factorizations.Spatial Statistics, 27:18–30, 2018
2018
-
[3]
Bebendorf
M. Bebendorf. Approximation of boundary element matrices.Numerische Mathematik, 86(4):565–589, 2000
2000
-
[4]
D. Cai, E. Chow, and Y. Xi. Posterior covariance structures in Gaussian processes.SIAM Journal on Matrix Analysis and Applications, 46(2):1640–1673, 2025
2025
-
[5]
Chen and M.L
J. Chen and M.L. Stein. Linear-cost covariance functions for Gaussian random fields.Journal of the American Statistical Association, 118(541):147–164, 2023
2023
-
[6]
Datta, S
A. Datta, S. Banerjee, A.O. Finley, and A.E. Gelfand. Hierarchical nearest-neighbor gaussian process models for large geostatistical datasets.Journal of the American Statistical Associa- tion, 111(514):800–812, April 2016
2016
-
[7]
Finley, A
A.O. Finley, A. Datta, B.D. Cook, D.C. Morton, H.E. Andersen, and S. Banerjee. Efficient algorithms for bayesian nearest neighbor gaussian processes.Journal of Computational and Graphical Statistics, 28(2):401–414, April 2019
2019
-
[8]
Geoga.https://github.com/cgeoga/Vecchia.jl, 2021
C.J. Geoga.https://github.com/cgeoga/Vecchia.jl, 2021
2021
-
[9]
Geoga, C.L
C.J. Geoga, C.L. Haley, A.R. Siegel, and M. Anitescu. Frequency–wavenumber spectral anal- ysis of spatio-temporal flows.Journal of Fluid Mechanics, 848:545–559, 2018
2018
-
[10]
Geoga and M.L
C.J. Geoga and M.L. Stein. A scalable method to exploit screening in gaussian process models with noise.Journal of Computational and Graphical Statistics, 33(2):603–613, 2024
2024
-
[11]
Greengard and V
L. Greengard and V. Rokhlin. A fast algorithm for particle simulations.Journal of computa- tional physics, 73(2):325–348, 1987
1987
-
[12]
Greengard and J
L. Greengard and J. Strain. The fast Gauss transform.SIAM Journal on Scientific and Statistical Computing, 12(1):79–94, 1991. 19
1991
-
[13]
Greengard, M
P. Greengard, M. Rachh, and A.H. Barnett. Equispaced Fourier representations for efficient Gaussian process regression from a billion data points.SIAM/ASA Journal on Uncertainty Quantification, 13(1):63–89, 2025
2025
-
[14]
Guinness
J. Guinness. Spectral density estimation for random fields via periodic embeddings. Biometrika, 106(2):267–286, 2019
2019
-
[15]
Guinness
J. Guinness. Gaussian process learning via Fisher scoring of Vecchia’s approximation.Stat and Comput, 31(3):25, 2021
2021
-
[16]
Hackbusch.Hierarchical matrices: algorithms and analysis, volume 49
W. Hackbusch.Hierarchical matrices: algorithms and analysis, volume 49. Springer, 2015
2015
-
[17]
Halko, P.G
N. Halko, P.G. Martinsson, and J.A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review, 53(2):217–288, 2011
2011
-
[18]
Jiang and L
S. Jiang and L. Greengard. A dual-space multilevel kernel-splitting framework for discrete and continuous convolution.Commun. Pure Appl. Math., 78(5):1086–1143, 2025
2025
-
[19]
E. Kaminetz and R.J. Webber. Everything is Vecchia: Unifying low-rank and sparse inverse Cholesky approximations.arXiv preprint arXiv:2603.05709, 2026
-
[20]
Katzfuss and J
M. Katzfuss and J. Guinness. A general framework for vecchia approximations of gaussian processes.Statistical Science, 36(1):124–141, 2021
2021
-
[21]
Lindgren, H
F. Lindgren, H. Rue, and J. Lindstr¨ om. An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach: Link between Gaussian Fields and Gaussian Markov Random Fields.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 73(4):423–498, September 2011
2011
-
[22]
Litvinenko, Y
A. Litvinenko, Y. Sun, M.G. Genton, and D.E. Keyes. Likelihood approximation with hierar- chical matrices for large spatial datasets.Computational Statistics & Data Analysis, 137:115– 132, September 2019
2019
-
[23]
P.G. Martinsson and M. O’Neil. Fast direct solvers.arXiv preprint arXiv:2511.07773, 2025
-
[24]
Minden, A
V. Minden, A. Damle, Kenneth L. H., and L. Ying. Fast Spatial Gaussian Process Maximum Likelihood Estimation via Skeletonization Factorizations.Multiscale Model Sim, 15(4):1584– 1611, 2017
2017
-
[25]
Mockus.Bayesian Approach to Global Optimization: Theory and Applications
J. Mockus.Bayesian Approach to Global Optimization: Theory and Applications. Springer Science & Business Media, December 2012
2012
-
[26]
Niu and C
K. Niu and C. Tian. Zernike polynomials and their applications.Journal of Optics, 24(12):123001, 2022
2022
-
[27]
Rue and L
H. Rue and L. Held.Gaussian Markov random fields: theory and applications. Chapman and Hall/CRC, 2005
2005
-
[28]
Sch¨ afer, M
F. Sch¨ afer, M. Katzfuss, and H. Owhadi. Sparse Cholesky Factorization by Kullback–Leibler Minimization.SIAM Journal on Scientific Computing, 43(3):A2019–A2046, January 2021
2021
-
[29]
Snelson and Z
E. Snelson and Z. Ghahramani. Local and global sparse Gaussian process approximations. In Artificial Intelligence and Statistics, pages 524–531. PMLR, 2007. 20
2007
-
[30]
M. L. Stein.Interpolation of Spatial Data: Some Theory for Kriging. Springer, 1999
1999
-
[31]
M.L. Stein. 2010 Rietz lecture: When does the screening effect hold?The Annals of Statistics, 39(6):2795–2819, 2011
2010
-
[32]
Stein, Z
M.L. Stein, Z. Chi, and L.J. Welty. Approximating likelihoods for large spatial data sets. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 66(2):275–296, 2004
2004
-
[33]
Toukmaji and J.A
A.Y. Toukmaji and J.A. Board Jr. Ewald summation techniques in perspective: a survey. Computer physics communications, 95(2-3):73–92, 1996
1996
-
[34]
Trefethen.Approximation theory and approximation practice
L.N. Trefethen.Approximation theory and approximation practice. SIAM, 2019
2019
-
[35]
J.A. Tropp and R.J. Webber. Randomized algorithms for low-rank matrix approximation: Design, analysis, and applications.arXiv preprint arXiv:2306.12418, 2023
-
[36]
A.V. Vecchia. Estimation and model identification for continuous spatial processes.Journal of the Royal Statistical Society: Series B (Methodological), 50(2):297–312, 1988. 21
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.