Recognition: 3 theorem links
· Lean TheoremAnchorD: Metric Grounding of Monocular Depth Using Factor Graphs
Pith reviewed 2026-05-08 18:14 UTC · model grok-4.3
The pith
A training-free factor graph method aligns monocular depth priors patch-wise to raw sensor readings to recover accurate metric depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that monocular depth estimation priors from foundation models contain sufficiently accurate local geometric structure to be grounded in metric real-world depth via patch-wise affine alignment performed through factor graph optimization. This process anchors the predictions to raw sensor depth without requiring any training, preserves fine-grained structure and discontinuities, and yields improved depth maps suitable for robotic tasks. The paper supports the claim with evaluations across diverse sensors and domains plus a new benchmark dataset that provides dense scene-wide ground truth depth even in the presence of non-Lambertian objects, obtained via matte reflection sp
What carries the argument
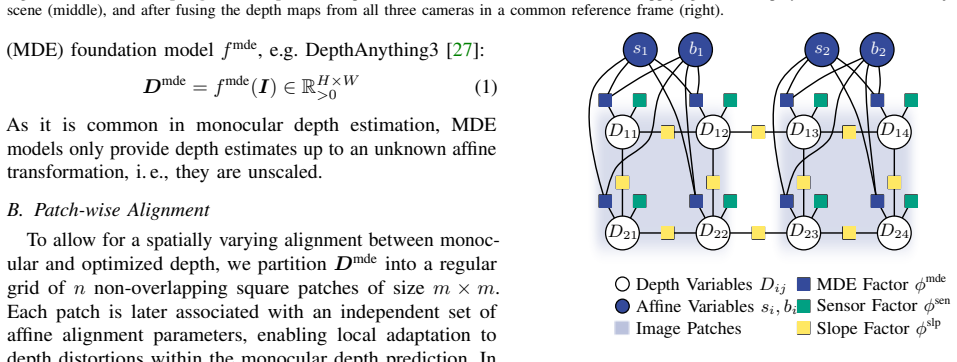
Factor graph optimization performing patch-wise affine alignment between monocular depth priors and raw sensor measurements
If this is right
- Robotic manipulation and navigation systems gain usable metric depth from monocular models without any model retraining.
- Depth accuracy improves specifically on transparent, specular, and other surfaces where sensors fail but monocular priors retain structure.
- The new benchmark enables direct comparison of depth methods under realistic non-Lambertian conditions using dense ground truth.
- The alignment step works with a variety of existing depth sensors and foundation models across indoor and outdoor domains.
Where Pith is reading between the lines
- The same patch-wise grounding idea could be applied to correct other visual priors such as surface normals or semantic labels when paired with sparse sensor cues.
- Inserting the factor graph step into existing SLAM or visual odometry pipelines would likely increase robustness to sensor failures on reflective objects.
- Because the method is training-free and modular, it offers a lightweight way to adapt future depth foundation models to new sensor hardware without re-optimization.
Load-bearing premise
Monocular depth priors from foundation models contain local geometric structures accurate enough that a simple affine transform per patch can align them to sensor data without introducing new distortions or erasing discontinuities.
What would settle it
Applying the patch-wise alignment on the introduced benchmark and measuring that the resulting depth maps match the matte-sprayed multi-camera ground truth no better than the unaligned monocular predictions or the raw sensor data alone.
Figures





read the original abstract
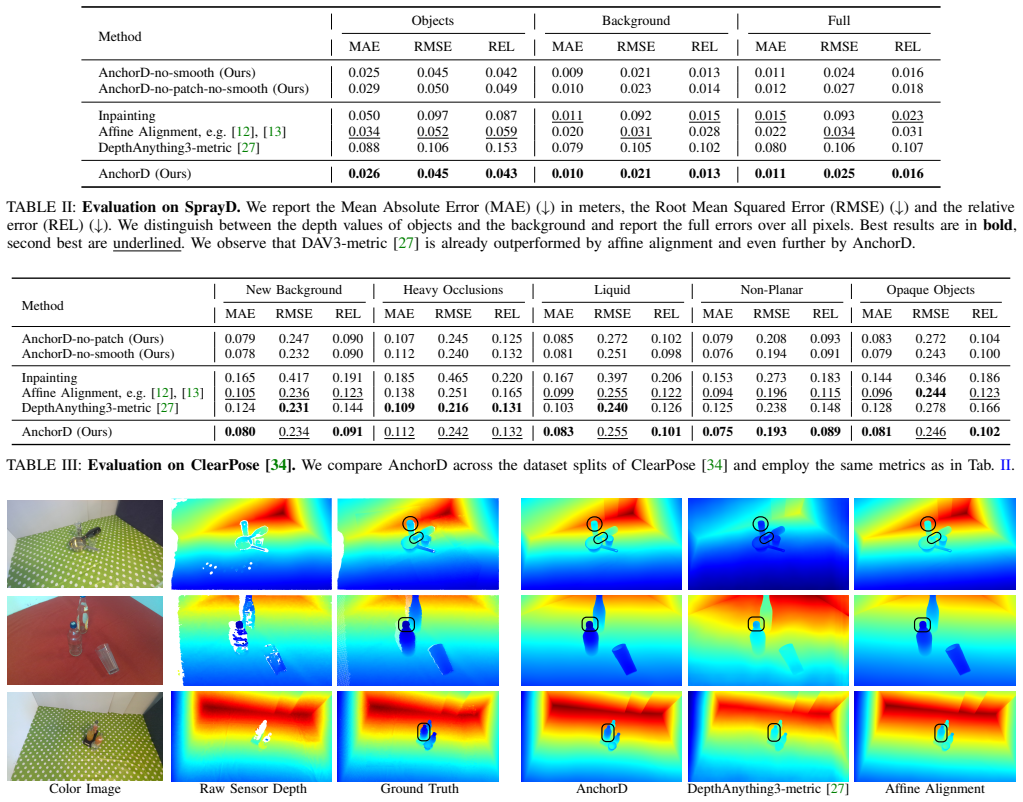
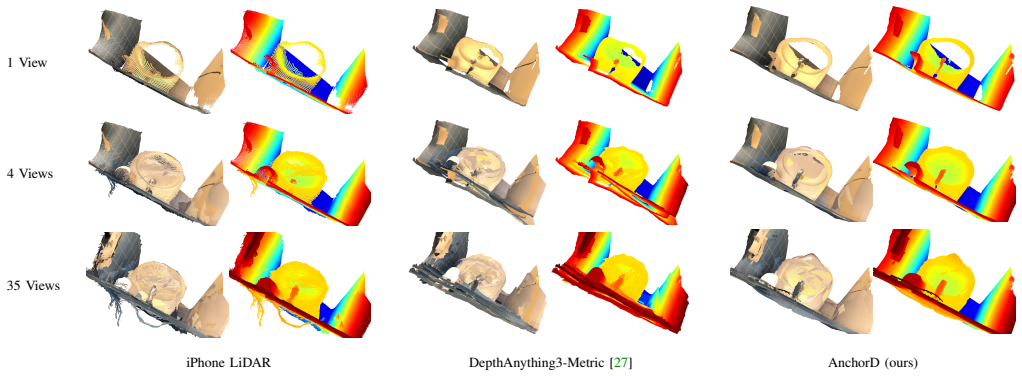
Dense and accurate depth estimation is essential for robotic manipulation, grasping, and navigation, yet currently available depth sensors are prone to errors on transparent, specular, and general non-Lambertian surfaces. To mitigate these errors, large-scale monocular depth estimation approaches provide strong structural priors, but their predictions can be potentially skewed or mis-scaled in metric units, limiting their direct use in robotics. Thus, in this work, we propose a training-free depth grounding framework that anchors monocular depth estimation priors from a depth foundation model in raw sensor depth through factor graph optimization. Our method performs a patch-wise affine alignment, locally grounding monocular predictions in metric real-world depth while preserving fine-grained geometric structure and discontinuities. To facilitate evaluation in challenging real-world conditions, we introduce a benchmark dataset with dense scene-wide ground truth depth in the presence of non-Lambertian objects. Ground truth is obtained via matte reflection spray and multi-camera fusion, overcoming the reliance on object-only CAD-based annotations used in prior datasets. Extensive evaluations across diverse sensors and domains demonstrate consistent improvements in depth performance without any (re-)training. We make our implementation publicly available at https://anchord.cs.uni-freiburg.de.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnchorD, a training-free framework for metric grounding of monocular depth estimates. It anchors priors from depth foundation models to raw sensor depth via factor graph optimization using patch-wise affine alignment, with the goal of preserving fine-grained geometric structure and discontinuities. The authors introduce a new benchmark dataset providing dense scene-wide ground truth depth for non-Lambertian objects, constructed via matte reflection spray and multi-camera fusion. They report consistent depth performance improvements across diverse sensors and domains without retraining and release the implementation publicly.
Significance. If the central claims hold, the work addresses a practical robotics challenge by fusing metric sensor data with structural priors from foundation models without requiring retraining or fine-tuning. This could enable more reliable depth for manipulation and navigation on challenging surfaces. The new benchmark with dense GT is a notable contribution over prior object-only CAD annotations, and the public code supports reproducibility. The approach's training-free nature is a strength for rapid deployment.
major comments (3)
- [§3.2] §3.2 (Factor Graph Optimization): The patch-wise affine alignment formulation does not specify the exact factors or regularization terms used to couple overlapping patches while respecting depth discontinuities. This is load-bearing for the central claim, as non-affine local errors common in foundation models on specular surfaces could introduce distortions unless edge-aware constraints are explicitly enforced.
- [§4.3] §4.3 (Quantitative Evaluation): The reported consistent improvements lack region-specific error analysis (e.g., on discontinuities or non-Lambertian patches) and convergence diagnostics for the factor graph optimization. Without these, it is unclear whether the alignment preserves structure or merely averages errors, undermining the guarantee of no new artifacts.
- [§5] §5 (Benchmark Construction): The matte spray + multi-camera fusion method for dense GT may smooth fine discontinuities, as the spray alters surface properties. Validation against unsprayed high-resolution references or ablation on discontinuity preservation is needed to confirm the benchmark's superiority for evaluating the method's claims.
minor comments (2)
- [Figure 4] Figure 4: Add zoomed insets on discontinuity regions to visually support the preservation claim.
- [Related Work] Related Work: Include recent comparisons to other sensor-fusion depth methods (e.g., those using similar optimization frameworks) to better contextualize novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the existing formulation where possible and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Factor Graph Optimization): The patch-wise affine alignment formulation does not specify the exact factors or regularization terms used to couple overlapping patches while respecting depth discontinuities. This is load-bearing for the central claim, as non-affine local errors common in foundation models on specular surfaces could introduce distortions unless edge-aware constraints are explicitly enforced.
Authors: Section 3.2 presents the factor graph with unary factors that minimize the affine alignment error between each monocular patch and the corresponding sensor depth measurements, and binary factors that enforce consistency of the affine parameters across overlapping patches. An additional regularization term penalizes deviations from the identity affine transform while being modulated by image gradients to respect discontinuities. We acknowledge that the exact factor definitions and the gradient-based weighting were described at a high level rather than with full equations. In the revised manuscript we will insert the precise mathematical expressions for all factors, the overlap consistency term, and the edge-aware regularization, ensuring the formulation is fully specified and reproducible. revision: yes
-
Referee: [§4.3] §4.3 (Quantitative Evaluation): The reported consistent improvements lack region-specific error analysis (e.g., on discontinuities or non-Lambertian patches) and convergence diagnostics for the factor graph optimization. Without these, it is unclear whether the alignment preserves structure or merely averages errors, undermining the guarantee of no new artifacts.
Authors: We agree that aggregate metrics alone leave open the question of whether structure is preserved. The revised evaluation section will report separate error statistics on non-Lambertian regions (identified via intensity variance and sensor confidence) and on depth discontinuity boundaries (extracted via Canny edges on the reference depth). We will also add convergence plots showing the factor-graph cost and per-iteration depth change, together with a qualitative comparison of edge sharpness before and after optimization. These additions will demonstrate that the method reduces error without smoothing or introducing new artifacts. revision: yes
-
Referee: [§5] §5 (Benchmark Construction): The matte spray + multi-camera fusion method for dense GT may smooth fine discontinuities, as the spray alters surface properties. Validation against unsprayed high-resolution references or ablation on discontinuity preservation is needed to confirm the benchmark's superiority for evaluating the method's claims.
Authors: The spray is applied in a minimal, uniform layer specifically chosen to reduce specular reflection while preserving macroscopic geometry; the multi-camera fusion further recovers fine detail through photometric consistency across views. Direct unsprayed high-resolution ground truth for the identical real-world scenes is not available, as the non-Lambertian surfaces prevent reliable capture without the spray. In the revision we will expand the benchmark description with a limitations paragraph acknowledging this trade-off and will add a synthetic ablation that applies an analogous surface modification to rendered scenes, quantifying discontinuity preservation before and after the simulated spray. This will support the claim that the benchmark remains superior to prior CAD-only annotations for evaluating metric grounding on challenging surfaces. revision: partial
Circularity Check
No circularity: independent optimization on external priors and sensor data
full rationale
The derivation consists of a factor-graph optimization that takes two independent inputs—monocular depth priors from a foundation model and raw metric sensor depths—and produces an aligned output via patch-wise affine transforms. No equation or claim reduces to a tautology, a fitted parameter renamed as prediction, or a self-citation chain. The benchmark construction (matte spray + multi-camera fusion) is a data-acquisition procedure external to the algorithm. All load-bearing steps remain falsifiable against held-out sensor measurements and are not self-referential by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Factor graph optimization can locally align monocular depth structure to sensor measurements via affine transforms without global distortion.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (Jcost = ½(x+x⁻¹)−1)washburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
ϕ_slp(D_p, D_q) = ρ_δ2( [log D_p − log D_q] − [log D'^mde_p − log D'^mde_q] )
-
RS framework as a whole — zero adjustable parametersreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
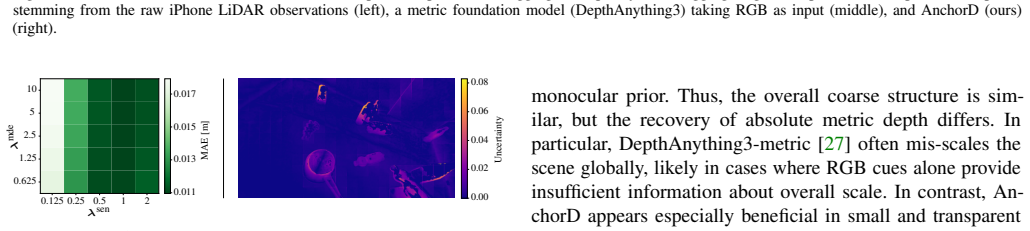
λ_mde = 2.5, λ_sen = 0.5, λ_slp = 1.0, δ_1 = 0.002, δ_2 = 0.01, k=64; hyperparameter sensitivity matrix in Fig. 9
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Clear grasp: 3d shape estimation of transparent objects for manipulation,
S. Sajjan, M. Moore, M. Pan, G. Nagaraja, J. Lee, A. Zeng, and S. Song, “Clear grasp: 3d shape estimation of transparent objects for manipulation,” inIEEE Int. Conf. on Rob. and Auto., 2020
2020
-
[2]
Depthgrasp: Depth completion of transparent objects using self-attentive adversarial network with spectral residual for grasping,
Y . Tang, J. Chen, Z. Yang, Z. Lin, Q. Li, and W. Liu, “Depthgrasp: Depth completion of transparent objects using self-attentive adversarial network with spectral residual for grasping,” inIEEE Int. Conf. on Intel. Rob. and Syst., 2021
2021
-
[3]
Transcg: A large-scale real- world dataset for transparent object depth completion and a grasping baseline,
H. Fang, H.-S. Fang, S. Xu, and C. Lu, “Transcg: A large-scale real- world dataset for transparent object depth completion and a grasping baseline,”IEEE Robotics and Automation Letters, 2022
2022
-
[4]
Contact- graspnet: Efficient 6-dof grasp generation in cluttered scenes,
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox, “Contact- graspnet: Efficient 6-dof grasp generation in cluttered scenes,” inIEEE Int. Conf. on Rob. and Auto., 2021
2021
-
[5]
Ditto: Demonstration imitation by trajectory transformation,
N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada, “Ditto: Demonstration imitation by trajectory transformation,” inIEEE Int. Conf. on Intel. Rob. and Syst., 2024
2024
-
[6]
The art of imitation: Learning long-horizon manipulation tasks from few demonstrations,
J. O. von Hartz, T. Welschehold, A. Valada, and J. Boedecker, “The art of imitation: Learning long-horizon manipulation tasks from few demonstrations,”IEEE Robotics and Automation Letters, 2024
2024
-
[7]
Cmrnet++: Map and camera agnostic monocular visual localization in lidar maps,
D. Cattaneo, D. G. Sorrenti, and A. Valada, “Cmrnet++: Map and camera agnostic monocular visual localization in lidar maps,”arXiv preprint arXiv:2004.13795, 2020
-
[8]
Dynamic object removal and spatio-temporal rgb-d inpainting via geometry-aware adversarial learning,
B. Beˇsi´c and A. Valada, “Dynamic object removal and spatio-temporal rgb-d inpainting via geometry-aware adversarial learning,”IEEE Transactions on Intelligent Vehicles, vol. 7, no. 2, pp. 170–185, 2022
2022
-
[9]
arXiv preprint arXiv:2602.16356 (2026) 4
M. Buechner, A. Roefer, T. Engelbracht, T. Welschehold, Z. Bauer, H. Blum, M. Pollefeys, and A. Valada, “Articulated 3d scene graphs for open-world mobile manipulation,”arXiv preprint arXiv:2602.16356, 2026
-
[10]
Towards robust semantic segmentation using deep fusion,
A. Valada, G. Oliveira, T. Brox, and W. Burgard, “Towards robust semantic segmentation using deep fusion,” inRSS Workshop, are the sceptics right? Limits and potentials of deep learning in robotics, vol. 114, 2016
2016
-
[11]
Articulated object estimation in the wild,
A. Werby, M. B¨uchner, A. R¨ofer, C. Huang, W. Burgard, and A. Valada, “Articulated object estimation in the wild,” inConf. on Rob. Learn., 2025
2025
-
[12]
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
S. Patel, S. Mohan, H. Mai, U. Jain, S. Lazebnik, and Y . Li, “Robotic manipulation by imitating generated videos without physical demonstrations,”arXiv preprint arXiv:2507.00990, 2025
work page Pith review arXiv 2025
-
[13]
NovaFlow: Zero- shot manipulation via actionable flow from generated videos
H. Li, L. Sun, Y . Hu, D. Ta, J. Barry, G. Konidaris, and J. Fu, “Novaflow: Zero-shot manipulation via actionable flow from generated videos,” arXiv preprint arXiv:2510.08568, 2025
-
[14]
Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation,
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger, “Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2025
2025
-
[15]
Rgb-d local implicit function for depth completion of transparent objects,
L. Zhu, A. Mousavian, Y . Xiang, H. Mazhar, J. van Eenbergen, S. Debnath, and D. Fox, “Rgb-d local implicit function for depth completion of transparent objects,” inIEEE Conf. Comput. Vis. Pattern Recog., 2021
2021
-
[16]
Seeing glass: Joint point-cloud and depth completion for transparent objects,
H. Xu, Y . R. Wang, S. Eppel, A. Aspuru-Guzik, F. Shkurti, and A. Garg, “Seeing glass: Joint point-cloud and depth completion for transparent objects,” in5th Annual Conference on Robot Learning, 2021
2021
-
[17]
Tcrnet: Transparent object depth completion with cascade refinements,
D.-H. Zhai, S. Yu, W. Wang, Y . Guan, and Y . Xia, “Tcrnet: Transparent object depth completion with cascade refinements,”IEEE Transactions on Automation Science and Engineering, 2025
2025
-
[18]
Completionformer: Depth completion with convolutions and vision transformers,
Y . Zhang, X. Guo, M. Poggi, Z. Zhu, G. Huang, and S. Mattoccia, “Completionformer: Depth completion with convolutions and vision transformers,” inIEEE Conf. Comput. Vis. Pattern Recog., 2023
2023
-
[19]
Costdcnet: Cost volume based depth completion for a single rgb-d image,
J. Kam, J. Kim, S. Kim, J. Park, and S. Lee, “Costdcnet: Cost volume based depth completion for a single rgb-d image,” inEurop. Conf. on Computer Vision, 2022
2022
-
[20]
Depth estimation via affinity learned with convolutional spatial propagation network,
X. Cheng, P. Wang, and R. Yang, “Depth estimation via affinity learned with convolutional spatial propagation network,” inEurop. Conf. on Computer Vision, 2018
2018
-
[21]
Dynamic spatial propagation network for depth completion,
Y . Lin, T. Cheng, Q. Zhong, W. Zhou, and H. Yang, “Dynamic spatial propagation network for depth completion,” inProceedings of the aaai conference on artificial intelligence, 2022
2022
-
[22]
Non-local spatial propagation network for depth completion,
J. Park, K. Joo, Z. Hu, C.-K. Liu, and I. So Kweon, “Non-local spatial propagation network for depth completion,” inEurop. Conf. on Computer Vision, 2020
2020
-
[23]
Self-supervised sparse- to-dense: Self-supervised depth completion from lidar and monocular camera,
F. Ma, G. V . Cavalheiro, and S. Karaman, “Self-supervised sparse- to-dense: Self-supervised depth completion from lidar and monocular camera,” inIEEE Int. Conf. on Rob. and Auto., 2019
2019
-
[24]
Keypose: Multi-view 3d labeling and keypoint estimation for transparent objects,
X. Liu, R. Jonschkowski, A. Angelova, and K. Konolige, “Keypose: Multi-view 3d labeling and keypoint estimation for transparent objects,” inIEEE Conf. Comput. Vis. Pattern Recog., 2020
2020
-
[25]
Depth prompting for sensor-agnostic depth estimation,
J.-H. Park, C. Jeong, J. Lee, and H.-G. Jeon, “Depth prompting for sensor-agnostic depth estimation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024
2024
-
[26]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,
M. Hu, W. Yin, C. Zhang, Z. Cai, X. Long, H. Chen, K. Wang, G. Yu, C. Shen, and S. Shen, “Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[29]
Depth pro: Sharp monocular metric depth in less than a second,
A. Bochkovskiy, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. Richter, and V . Koltun, “Depth pro: Sharp monocular metric depth in less than a second,” inInt. Conf. on Learn. Repr., Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., 2025
2025
-
[30]
Unidepth: Universal monocular metric depth estimation,
L. Piccinelli, Y .-H. Yang, C. Sakaridis, M. Segu, S. Li, L. V . Gool, and F. Yu, “Unidepth: Universal monocular metric depth estimation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024
2024
-
[31]
Unidepthv2: Universal monocular metric depth estimation made simpler,
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. Van Gool, “Unidepthv2: Universal monocular metric depth estimation made simpler,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[32]
Indoor segmentation and support inference from rgbd images,
P. K. Nathan Silberman, Derek Hoiem and R. Fergus, “Indoor segmentation and support inference from rgbd images,” inEurop. Conf. on Computer Vision, 2012
2012
-
[33]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”Int. J. Rob. Res., 2013
2013
-
[34]
Clearpose: Large-scale transparent object dataset and benchmark,
X. Chen, H. Zhang, Z. Yu, A. Opipari, and O. C. Jenkins, “Clearpose: Large-scale transparent object dataset and benchmark,” inEurop. Conf. on Computer Vision, 2022
2022
-
[35]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEurop. Conf. on Computer Vision, 2024
2024
-
[36]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Girshick, “Segment anything,” inInt. Conf. Comput. Vis., 2023
2023
-
[37]
SAM 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryaliet al., “SAM 2: Segment anything in images and videos,” inInt. Conf. on Learn. Repr., 2025
2025
-
[38]
Robust Estimation of a Location Parameter,
P. J. Huber, “Robust Estimation of a Location Parameter,”The Annals of Mathematical Statistics, vol. 35, 1964
1964
-
[39]
Robust regression using iteratively reweighted least-squares,
P. W. Holland and R. E. Welsch, “Robust regression using iteratively reweighted least-squares,”Communications in Statistics-theory and Methods, vol. 6, no. 9, 1977
1977
-
[40]
Scannet++: A high-fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high-fidelity dataset of 3d indoor scenes,” inInt. Conf. Comput. Vis., 2023
2023
-
[41]
Navier-stokes, fluid dynamics, and image and video inpainting,
M. Bertalmio, A. L. Bertozzi, and G. Sapiro, “Navier-stokes, fluid dynamics, and image and video inpainting,” inIEEE Conf. Comput. Vis. Pattern Recog., 2001
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.