Recognition: unknown
Dimensionality-Aware Anomaly Detection in Learned Representations of Self-Supervised Speech Models
Pith reviewed 2026-05-08 02:12 UTC · model grok-4.3
The pith
Local intrinsic dimensionality rises in speech model layers under perturbations and tracks ASR degradation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
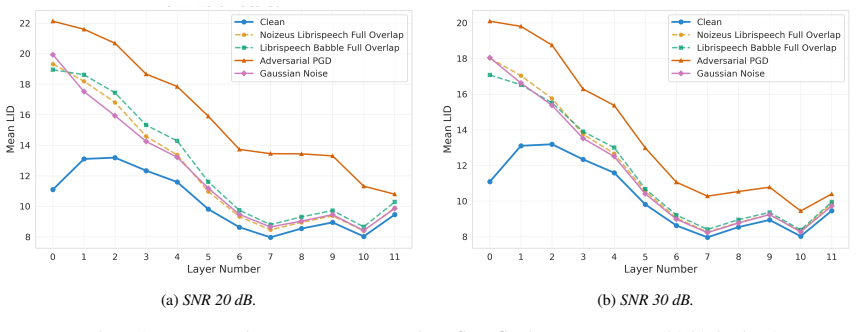
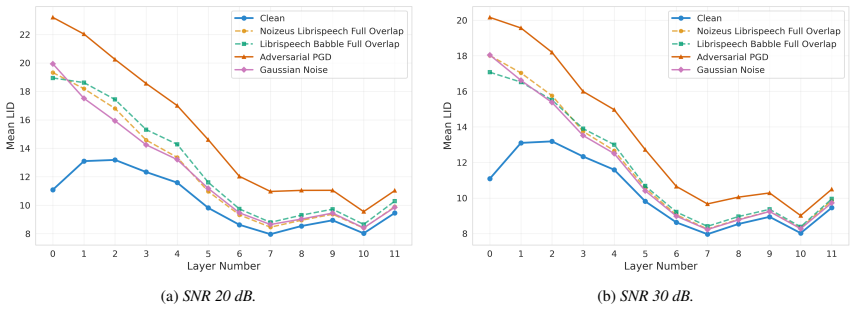
Perturbations deform local geometry in the learned representations of self-supervised speech models, visible as elevated Local Intrinsic Dimensionality across layers. Low-SNR conditions raise LID uniformly; at high SNR, benign noise converges to the clean LID profile while adversarial inputs preserve early-layer elevation. LID elevation co-occurs with increased word error rate, and the layer-wise LID features enable anomaly detection with AUROC 0.78-1.00.
What carries the argument
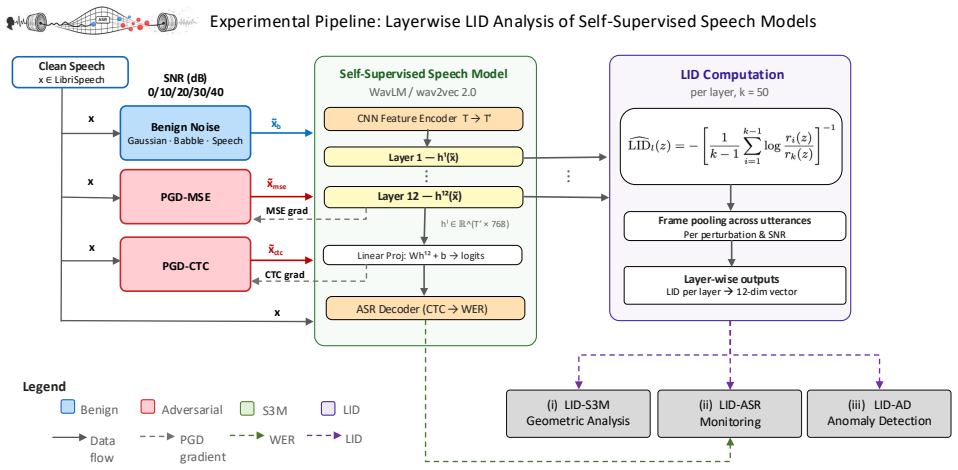
Local Intrinsic Dimensionality (LID) computed on layer-wise representations, which quantifies local geometric complexity and reveals perturbation-induced shifts.
If this is right
- LID elevation supplies a transcript-free indicator of ASR degradation under both natural and adversarial perturbations.
- Benign noise and adversarial inputs produce distinguishable layer-wise LID profiles at high SNR.
- Layer-wise LID features support anomaly detection across WavLM and wav2vec 2.0 representations.
- The approach opens transcript-free monitoring of self-supervised speech models under varying acoustic conditions.
Where Pith is reading between the lines
- The same layer-wise LID approach could be tested on other self-supervised audio or multimodal models to detect geometric anomalies without task-specific labels.
- Real-time LID monitoring might be integrated into deployed speech systems to flag inputs likely to produce high error rates before transcription.
- Extending the method to continuous streams of natural acoustic variations would test whether the observed LID-WER link holds outside controlled perturbations.
Load-bearing premise
The chosen perturbations and LID estimator capture the local geometry changes that actually drive real-world ASR degradation without post-hoc layer or threshold selection.
What would settle it
Measuring no correlation between LID elevation and increased WER, or AUROC below 0.7, on a fresh set of natural perturbations applied to the same or similar models.
Figures


read the original abstract
Self-supervised speech models (S3Ms) achieve strong downstream performance, yet their learned representations remain poorly understood under natural and adversarial perturbations. Prior studies rely on representation similarity or global dimensionality, offering limited visibility into local geometric changes. We ask: how do perturbations deform local geometry, and do these shifts track downstream automatic speech recognition (ASR) degradation? To address this, we present GRIDS, a framework using Local Intrinsic Dimensionality (LID) across layer-wise representations in WavLM and wav2vec 2.0. We find that LID increases for all low signal-to noise ratio (SNR) perturbations and diverges at high SNR: benign noise converges toward the clean profile, while adversarial inputs retain early-layer LID elevation. We show LID elevation co-occurs with increased WER, and that layer-wise LID features enable anomaly detection (AUROC 0.78-1.00), opening the door to transcript-free monitoring in S3Ms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GRIDS, a framework applying Local Intrinsic Dimensionality (LID) to layer-wise representations of self-supervised speech models (WavLM, wav2vec 2.0) under natural and adversarial perturbations. It reports that LID rises for all low-SNR inputs, diverges at high SNR (benign noise converges to clean profiles while adversarial retains early-layer elevation), that LID elevation co-occurs with elevated WER, and that layer-wise LID features support anomaly detection with AUROC 0.78–1.00, enabling transcript-free monitoring.
Significance. If the LID–WER link and anomaly-detection results prove robust to SNR confounding and post-hoc layer selection, the work would supply a geometric lens on representation robustness in S3Ms and a practical, transcript-free monitoring tool. The high-SNR divergence between benign and adversarial cases is a concrete, falsifiable observation that could guide defense design. The absence of error bars, exact estimator parameters, and stratified controls currently limits the strength of these claims.
major comments (1)
- [Abstract] Abstract: the claim that LID elevation 'tracks downstream ASR degradation' rests on co-occurrence with WER, yet both quantities are known to depend strongly on SNR. No analysis stratified by fixed-SNR bins is described, leaving open the possibility that the reported correlation is largely explained by shared dependence on noise intensity rather than LID capturing local geometric changes that causally affect transcription.
minor comments (3)
- [Abstract] Abstract and methods: no error bars, confidence intervals, or exact LID estimator parameters (k, distance metric, neighborhood size) are provided, making it impossible to assess the stability of the reported AUROC range and layer-wise trends.
- The manuscript does not state data exclusion rules, perturbation generation details, or whether layer selection for the anomaly detector was performed post-hoc on the test set, which would inflate the reported AUROC values.
- No mention of multiple-testing correction across layers, perturbation types, and SNR levels, which is relevant given the large number of reported comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and commit to revisions that strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LID elevation 'tracks downstream ASR degradation' rests on co-occurrence with WER, yet both quantities are known to depend strongly on SNR. No analysis stratified by fixed-SNR bins is described, leaving open the possibility that the reported correlation is largely explained by shared dependence on noise intensity rather than LID capturing local geometric changes that causally affect transcription.
Authors: We agree that SNR confounding must be ruled out for a robust claim. Our existing high-SNR results already provide partial evidence against pure intensity dependence: at matched high SNR, benign perturbations cause LID to converge toward the clean profile while adversarial perturbations retain early-layer elevation. This divergence at comparable SNR levels indicates that LID reflects perturbation-specific geometric structure rather than SNR alone. Nevertheless, the referee is correct that no explicit within-bin stratification is reported. In the revision we will add a stratified analysis: samples will be grouped into low-SNR (<0 dB), medium-SNR (0–10 dB), and high-SNR (>10 dB) bins; LID–WER Spearman correlations and partial correlations (controlling for SNR) will be computed and reported within each bin. These results will appear in the main results section on the LID–WER relationship and will be summarized in an updated abstract. revision: yes
Circularity Check
No circularity: empirical measurements of LID, WER, and AUROC are independent quantities
full rationale
The paper computes Local Intrinsic Dimensionality (LID) directly from layer-wise representations of S3Ms using a standard estimator, then measures word error rate (WER) on downstream ASR tasks and AUROC for anomaly detection on held-out perturbations. These are separate computations on the same inputs; LID is not defined in terms of WER or AUROC, nor is any 'prediction' obtained by fitting to the target metric. No self-definitional equations, fitted-input renamings, or load-bearing self-citations appear in the provided abstract or description. The observed co-occurrence and detection performance are reported as empirical findings, not derived tautologically from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local intrinsic dimensionality computed on layer activations faithfully reflects local geometric deformation under input perturbations.
Reference graph
Works this paper leans on
-
[1]
Existing work has sought to enhance the noise robustness of self-supervised speech models (S3Ms), as well as characterize their adversarial vulnerability [2–6]
Introduction Self-supervised speech representations are an active area of re- search, with prior work motivating a deeper analysis of informa- tion encoding in model layers and understanding the behavior of representations under distributional shifts [1]. Existing work has sought to enhance the noise robustness of self-supervised speech models (S3Ms), as ...
-
[2]
Dimensionality-Aware Anomaly Detection in Learned Representations of Self-Supervised Speech Models
where each input yields a single feature vector, S3Ms generate variable-length frame-level embeddings per utterance. This requires careful aggregation of the embeddings to ensure a stable and reliable LID estimation. Furthermore, S3M features are learned via self-supervision and remain task-agnostic [1]. Whether LID is equally effective in S3Ms as shown i...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Related Work 2.1. Representation Analysis and Dimensionality in Self- Supervised Models Recent work on transformer representation geometry has shown that learned features organize on low-dimensional curved man- ifolds within a model’s hidden layers, and that attention heads manipulate this manifold structure as a computational mecha- nism [24]. This provi...
-
[4]
Methodology 3.1. LID Layer-wise Analysis in WavLM and wav2vec 2.0 Our goal is to quantify how benign and adversarial perturba- tions deform the local geometry of S3M representations across transformer layers, and to test whether these geometric shifts track downstream ASR degradation and support anomaly de- tection. Figure 1 summarizes ourGRIDSframework. ...
-
[5]
We follow this approach to reduce variance and stabilize kNN-based LID estimation on a number of utterances across different speakers
Experimental Configuration We draw utterances from LibriSpeechtest-clean[41], se- lecting 40 speakers at random retaining only utterances of 5-10 s duration (16 kHz sampling frequency). We follow this approach to reduce variance and stabilize kNN-based LID estimation on a number of utterances across different speakers. We further restrict this set to the ...
-
[6]
Results and Analysis We report results for the following three analyses aligned to our GRIDSframework: (i)LID-S3M geometric analysisfor layer- wise LID under benign and adversarial perturbations; (ii)LID- ASR monitoringthrough empirical evidence that supports the co-occurrence of∆LID–WER under a range of target SNRs and perturbation types; and (iii)LID-AD...
-
[7]
Conclusion We have shown that layer-wise LID is an effective diagnostic for local geometric changes in WavLM and wav2vec 2.0 under benign and adversarial perturbations. Across both models, and despite distinct pretraining objectives, our analysis reveals that the clearest divergence between adversarial and benign profiles occurs in early transformer layer...
-
[8]
Acknowledgments This research was supported by the Australian Gov- ernment Research Training Program Scholarship [DOI: https://doi.org/10.82133/C42F-K220]
-
[9]
All technical claims, metrics, and artifact references were manually verified
Declaration on Generative AI The author(s) used ChatGPT and Claude to edit, check gram- mar, spelling, and minor paraphrasing. All technical claims, metrics, and artifact references were manually verified
-
[10]
Self-supervised speech representation learning: A review,
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløeet al., “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, 2022
2022
-
[11]
Robust wav2vec 2.0: Analyzing Domain Shift in Self- Supervised Pre-Training,
W.-N. Hsu, A. Sriram, A. Baevski, T. Likhomanenko, Q. Xu, V . Pratap, J. Kahn, A. Lee, R. Collobert, G. Synnaeve, and M. Auli, “Robust wav2vec 2.0: Analyzing Domain Shift in Self- Supervised Pre-Training,” inProc. Interspeech, 2021, pp. 721– 725
2021
-
[12]
Improving distortion ro- bustness of self-supervised speech processing tasks with domain adaptation,
K. Huang, Y . Fu, Y . Zhang, and H. Lee, “Improving distortion ro- bustness of self-supervised speech processing tasks with domain adaptation,” inProc. Interspeech, 2022, pp. 2193–2197
2022
-
[13]
Improving noise robustness of con- trastive speech representation learning with speech reconstruc- tion,
H. Wang, Y . Qian, X. Wang, Y . Wang, C. Wang, S. Liu, T. Yosh- ioka, J. Li, and D. Wang, “Improving noise robustness of con- trastive speech representation learning with speech reconstruc- tion,” inProc. ICASSP. IEEE, 2022, pp. 6062–6066
2022
-
[14]
A noise-robust self-supervised pre-training model based speech rep- resentation learning for automatic speech recognition,
Q. Zhu, J. Zhang, Z. Zhang, M. Wu, X. Fang, and L. Dai, “A noise-robust self-supervised pre-training model based speech rep- resentation learning for automatic speech recognition,” inProc. ICASSP. IEEE, 2022, pp. 3174–3178
2022
-
[15]
Char- acterizing the adversarial vulnerability of speech self-supervised learning,
H. Wu, B. Zheng, X. Li, X. Wu, H. Lee, and H. Meng, “Char- acterizing the adversarial vulnerability of speech self-supervised learning,” inProc. ICASSP. IEEE, 2022, pp. 3164–3168
2022
-
[16]
Extreme-value-theoretic estima- tion of local intrinsic dimensionality,
L. Amsaleg, O. Chelly, T. Furon, S. Girard, M. E. Houle, K.-i. Kawarabayashi, and M. Nett, “Extreme-value-theoretic estima- tion of local intrinsic dimensionality,”Data Mining and Knowl- edge Discovery, vol. 32, no. 6, pp. 1768–1805, Nov. 2018
2018
-
[17]
Relationships between lo- cal intrinsic dimensionality and tail entropy,
J. Bailey, M. E. Houle, and X. Ma, “Relationships between lo- cal intrinsic dimensionality and tail entropy,” inLecture Notes in Computer Science, ser. Lecture Notes in Computer Science. Springer International Publishing, 2021, pp. 186–200
2021
-
[18]
On the correlation between local intrinsic dimensionality and outlierness,
M. E. Houle, E. Schubert, and A. Zimek, “On the correlation between local intrinsic dimensionality and outlierness,” in11th International Conference of Similarity Search and Applications. Springer-Verlag, 2018, pp. 177–191
2018
-
[19]
Intrinsic dimension of data representations in deep neural networks,
A. Ansuini, A. Laio, J. H. Macke, and D. Zoccolan, “Intrinsic dimension of data representations in deep neural networks,” in Proc. NeurIPS. Curran Associates Inc., 2019
2019
-
[20]
Intrinsic dimension of data representations in deep neural networks,
——, “Intrinsic dimension of data representations in deep neural networks,” inProceedings of the 33rd International Conference on Neural Information Processing Systems, 2019
2019
-
[21]
Detecting backdoor samples in contrastive language image pretraining,
H. Huang, S. M. Erfani, Y . Li, X. Ma, and J. Bailey, “Detecting backdoor samples in contrastive language image pretraining,” in Proc. ICLR, 2025
2025
-
[22]
The intrinsic dimension of images and its impact on learn- ing,
P. E. Pope, C. Zhu, A. Abdelkader, M. Goldblum, and T. Gold- stein, “The intrinsic dimension of images and its impact on learn- ing,” inProc. ICLR, 2021
2021
-
[23]
Dimensionality-driven learning with noisy labels,
X. Ma, Y . Wang, M. E. Houle, S. Zhou, S. M. Erfani, S.-T. Xia, S. Wijewickrema, and J. Bailey, “Dimensionality-driven learning with noisy labels,” inProc. ICML, 2018
2018
-
[24]
On the intrinsic dimensionality of image representations,
S. Gong, V . Boddeti, and A. Jain, “On the intrinsic dimensionality of image representations,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 3982–3991
2019
-
[25]
Local intrinsic dimensionality signals adversarial perturbations,
S. Weerasinghe, T. Abraham, T. Alpcan, S. M. Erfani, C. Leckie, and B. I. P. Rubinstein, “Local intrinsic dimensionality signals adversarial perturbations,” in61st IEEE Conference on Decision and Control, CDC 2022, Cancun, Mexico, December 6-9, 2022. IEEE, 2022, pp. 6118–6125. [Online]. Available: https://doi.org/10.1109/CDC51059.2022.9992383
-
[26]
Less is more: Local intrinsic dimensions of contextual language models,
B. M. Ruppik, J. von Rohrscheidt, C. van Niekerk, M. Heck, R. Vukovic, S. Feng, H. chin Lin, N. Lubis, B. Rieck, M. Zi- browius, and M. Gasic, “Less is more: Local intrinsic dimensions of contextual language models,” inProc. NeurIPS, 2025
2025
-
[27]
Sample complexity of testing the manifold hypothesis,
H. Narayanan and S. Mitter, “Sample complexity of testing the manifold hypothesis,” inProc. NeurIPS, J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta, Eds., vol. 23, 2010
2010
-
[28]
Testing the mani- fold hypothesis,
C. Fefferman, S. Mitter, and H. Narayanan, “Testing the mani- fold hypothesis,”Journal of the American Mathematical Society, vol. 29, no. 4, pp. 983–1049, 2016
2016
-
[29]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” inProc. ASRU. IEEE, 2021, pp. 914–921
2021
-
[30]
Character- izing adversarial subspaces using local intrinsic dimensionality,
X. Ma, B. Li, Y . Wang, S. M. Erfani, S. Wijewickrema, G. Schoenebeck, D. Song, M. E. Houle, and J. Bailey, “Character- izing adversarial subspaces using local intrinsic dimensionality,” inProc. ICLR, 2018
2018
-
[31]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[32]
wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: a framework for self-supervised learning of speech representa- tions,” inProc. NeurIPS. Curran Associates Inc., 2020
2020
-
[33]
When models manipulate manifolds: The geometry of a counting task, 2026
W. Gurnee, E. Ameisen, I. Kauvar, J. Tarng, A. Pearce, C. Olah, and J. Batson, “When models manipulate manifolds: The geometry of a counting task,” 2026. [Online]. Available: https://arxiv.org/abs/2601.04480
-
[34]
Comparative layer-wise analy- sis of self-supervised speech models,
A. Pasad, B. Shi, and K. Livescu, “Comparative layer-wise analy- sis of self-supervised speech models,” inProc. ICASSP, 2023, pp. 1–5
2023
-
[35]
Svcca: singular vector canonical correlation analysis for deep learning dynamics and interpretability,
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein, “Svcca: singular vector canonical correlation analysis for deep learning dynamics and interpretability,” inProc. NeurIPS, 2017, pp. 6078– 6087
2017
-
[36]
Insights on representa- tional similarity in neural networks with canonical correlation,
A. S. Morcos, M. Raghu, and S. Bengio, “Insights on representa- tional similarity in neural networks with canonical correlation,” in Proc. NeurIPS, 2018, pp. 5732–5741
2018
-
[37]
Deep canonical correlation analysis,
G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonical correlation analysis,” inProc. ICML. PMLR, 2013, pp. 1247– 1255
2013
-
[38]
On deep multi- view representation learning,
W. Wang, R. Arora, K. Livescu, and J. Bilmes, “On deep multi- view representation learning,” inProc. ICML. PMLR, 2015, pp. 1083–1092
2015
-
[39]
Nonlinear feature extrac- tion using generalized canonical correlation analysis,
T. Melzer, M. Reiter, and H. Bischof, “Nonlinear feature extrac- tion using generalized canonical correlation analysis,” inInterna- tional Conference on Artificial Neural Networks, 2001, pp. 353– 360
2001
-
[40]
Kernel and nonlinear canonical correlation analysis,
P. L. Lai and C. Fyfe, “Kernel and nonlinear canonical correlation analysis,”International Journal of Neural Systems, vol. 10, no. 5, pp. 365–377, 2000
2000
-
[41]
A neural implementation of canonical correlation analy- sis,
——, “A neural implementation of canonical correlation analy- sis,”Neural Networks, vol. 12, no. 10, pp. 1391–1397, 1999
1999
-
[42]
Unsupervised learning of acoustic features via deep canonical correlation anal- ysis,
W. Wang, R. Arora, K. Livescu, and J. A. Bilmes, “Unsupervised learning of acoustic features via deep canonical correlation anal- ysis,” inProc. ICASSP. IEEE, Apr. 2015, pp. 4590–4594
2015
-
[43]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inProc. ICML. PMLR, 2019, pp. 3519–3529
2019
-
[44]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 29, pp. 3451–3460, 2021
2021
-
[45]
Rankme: assessing the downstream performance of pretrained self- supervised representations by their rank,
Q. Garrido, R. Balestriero, L. Najman, and Y . LeCun, “Rankme: assessing the downstream performance of pretrained self- supervised representations by their rank,” 2023
2023
-
[46]
Towards automatic assessment of self-supervised speech models using rank,
Z. Aldeneh, V . Thilak, T. Higuchi, B. Theobald, and T. Likhoma- nenko, “Towards automatic assessment of self-supervised speech models using rank,” inProc. ICASSP. IEEE, 2025, pp. 1–5
2025
-
[47]
Application of local intrinsic di- mension for acoustical analysis of voice signal components,
B. Liu, E. Polce, and J. Jiang, “Application of local intrinsic di- mension for acoustical analysis of voice signal components,”An- nals of Otology, Rhinology & Laryngology, vol. 127, no. 9, pp. 588–597, 2018
2018
-
[48]
A robust approach for securing audio classification against adversarial at- tacks,
M. Esmaeilpour, P. Cardinal, and A. Lameiras Koerich, “A robust approach for securing audio classification against adversarial at- tacks,”IEEE Transactions on Information Forensics and Security, vol. 15, pp. 2147–2159, 2020
2020
-
[49]
Maximum likelihood estimation of intrinsic dimension,
E. Levina and P. J. Bickel, “Maximum likelihood estimation of intrinsic dimension,” inProc. NeurIPS. MIT Press, 2004, pp. 777–784
2004
-
[50]
Lib- rispeech: An asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An asr corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
2015
-
[51]
Subjective comparison and evalua- tion of speech enhancement algorithms,
Y . Hu and P. C. Loizou, “Subjective comparison and evalua- tion of speech enhancement algorithms,”Speech Communication, vol. 49, no. 7, pp. 588–601, 2007, special issue on Speech En- hancement
2007
-
[52]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inProc. ICLR, 2018
2018
-
[53]
Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inProc. ICML, 2006, pp. 369–376
2006
-
[54]
Towards early prediction of self-supervised speech model perfor- mance,
R. Whetten, L. Maison, T. Parcollet, M. Dinarelli, and Y . Est `eve, “Towards early prediction of self-supervised speech model perfor- mance,” inProc. Interspeech, 2025, pp. 1228–1232
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.