Recognition: 2 theorem links
When Audio-Language Models Fail to Leverage Multimodal Context for Dysarthric Speech Recognition
Pith reviewed 2026-05-08 18:01 UTC · model grok-4.3
The pith
Audio-language models do not meaningfully use clinical context to improve recognition of dysarthric speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that current audio-language models fail to leverage multimodal clinical context at inference time for dysarthric speech recognition. Diagnosis-informed and richer clinical prompts yield negligible improvements and often degrade word error rate across nine tested models. In contrast, context-dependent fine-tuning via LoRA adaptation using a mixture of clinical prompt formats achieves a WER of 0.066, representing a 52% relative reduction over the frozen baseline, with preserved performance when context is unavailable and notable gains for certain subgroups like Down syndrome and mild-severity cases.
What carries the argument
The benchmark that varies the richness of clinical prompts (from diagnosis labels to detailed descriptions) applied to nine audio-language models on the SAP dataset, combined with LoRA fine-tuning experiments that mix prompt formats.
If this is right
- Diagnosis-informed prompts yield negligible improvements in transcription accuracy.
- Clinically detailed prompts often degrade word error rate.
- LoRA adaptation with mixed clinical prompts reduces WER to 0.066, a 52% relative improvement.
- Performance is preserved when context is unavailable after fine-tuning.
- Significant gains occur for Down syndrome speakers and those with mild severity.
Where Pith is reading between the lines
- Models may require architectural changes rather than just better prompts to integrate clinical information effectively.
- The fine-tuning strategy could generalize to other forms of atypical or accented speech.
- Real-world deployment might benefit from always-on context integration during training rather than optional prompting.
- Subgroup-specific improvements suggest tailoring models to particular clinical populations could be fruitful.
Load-bearing premise
That the specific clinical descriptions and prompt formats tested here represent how such context would be supplied in actual clinical or assistive applications.
What would settle it
A new audio-language model or prompting technique that consistently lowers word error rate when given the same detailed clinical descriptions on the SAP dataset splits would falsify the claim.
Figures




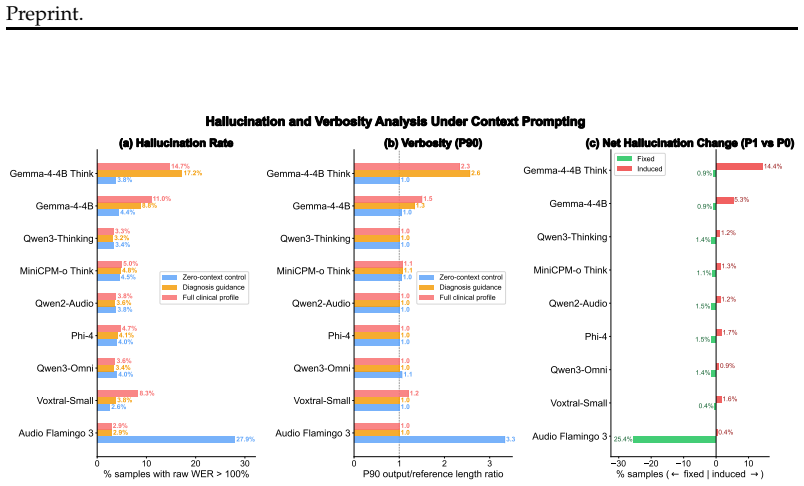
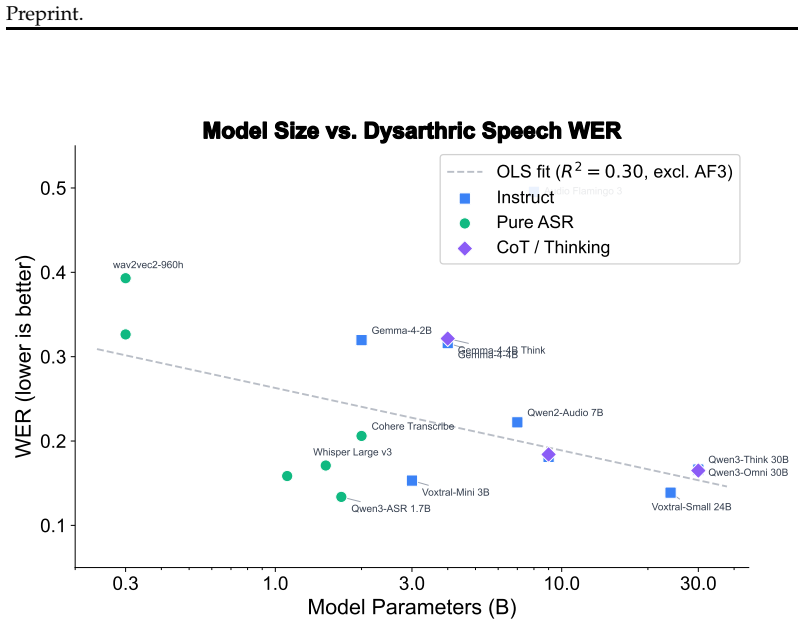
read the original abstract
Automatic speech recognition (ASR) systems remain brittle on dysarthric and other atypical speech. Recent audio-language models raise the possibility of improving performance by conditioning on additional clinical context at inference time, but it is unclear whether these models can make use of such information. We introduce a benchmark built on the Speech Accessibility Project (SAP) dataset that tests whether diagnosis labels, clinician-derived speech ratings, and progressively richer clinical descriptions improve transcription accuracy for dysarthric speech. Across matched comparisons on nine models, we find that current models do not meaningfully use this context: diagnosis-informed and clinically detailed prompts yield negligible improvements and often degrade word error rate. We complement the prompting analysis with context-dependent fine-tuning, showing that LoRA adaptation with a mixture of clinical prompt formats achieves a WER of 0.066, a 52% relative reduction over the frozen baseline, while preserving performance when context is unavailable. Subgroup analyses reveal significant gains for Down syndrome and mild-severity speakers. These results clarify where current models fall short and provide a testbed for measuring progress toward more inclusive ASR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a benchmark on the Speech Accessibility Project (SAP) dataset to test whether audio-language models can leverage multimodal clinical context—such as diagnosis labels, clinician speech ratings, and richer descriptions—to improve automatic transcription of dysarthric speech. Across matched zero-shot prompting experiments on nine models, it reports that such context yields negligible WER improvements and often degrades performance. Complementary LoRA fine-tuning on mixed prompt formats achieves a WER of 0.066 (52% relative reduction over frozen baseline), with notable subgroup gains for Down syndrome and mild-severity speakers, while preserving performance without context.
Significance. If the empirical findings hold under more detailed scrutiny, the work is significant for highlighting a concrete limitation in current audio-language models' ability to utilize provided multimodal context for atypical speech, while demonstrating that targeted adaptation can mitigate it. The multi-model comparison and the provision of a reproducible testbed (with fine-tuning results) are strengths that could guide future inclusive ASR research.
major comments (3)
- [§4] §4 (Prompting Experiments) and associated tables: The central claim that models 'do not meaningfully use this context' rests on the specific prompt templates and insertion methods for diagnosis labels and clinical descriptions, yet the manuscript provides insufficient detail on exact phrasing, formatting, or model-specific input construction; this makes it impossible to determine whether the observed negligible/negative WER changes reflect inherent model limitations or suboptimal prompt design.
- [§5] §5 (Fine-tuning Results) and Table reporting 0.066 WER: The 52% relative reduction is presented without error bars, confidence intervals, or statistical significance tests across runs or data splits; given the reader's note on missing details, this weakens the strength of evidence for the adaptation success and its contrast to the zero-shot findings.
- [§3] §3 (Benchmark Construction) and data split description: The SAP splits and model selections are not analyzed for potential correlations between speaker traits (e.g., severity, diagnosis) and prompt content, which could introduce bias favoring the no-improvement conclusion; the skeptic's concern about representativeness of clinical descriptions is load-bearing for the claim that models inherently fail to leverage context.
minor comments (2)
- [Abstract] Abstract and §2: Clarify the exact nine models evaluated and their parameter counts or architectures for reproducibility.
- [Results] Figure captions and results tables: Ensure all WER values include the number of speakers or utterances per condition to allow assessment of subgroup analyses.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify areas where the manuscript can be strengthened. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (Prompting Experiments) and associated tables: The central claim that models 'do not meaningfully use this context' rests on the specific prompt templates and insertion methods for diagnosis labels and clinical descriptions, yet the manuscript provides insufficient detail on exact phrasing, formatting, or model-specific input construction; this makes it impossible to determine whether the observed negligible/negative WER changes reflect inherent model limitations or suboptimal prompt design.
Authors: We agree that the manuscript would benefit from greater transparency on prompt construction. In the revised version, we will add a new appendix that lists the exact prompt templates for all nine models, including the precise phrasing, formatting, and insertion methods for diagnosis labels, clinician ratings, and clinical descriptions. This will allow readers to assess whether the results reflect model limitations or the prompting approach used. revision: yes
-
Referee: [§5] §5 (Fine-tuning Results) and Table reporting 0.066 WER: The 52% relative reduction is presented without error bars, confidence intervals, or statistical significance tests across runs or data splits; given the reader's note on missing details, this weakens the strength of evidence for the adaptation success and its contrast to the zero-shot findings.
Authors: We acknowledge the value of statistical reporting for strengthening the claims. We will rerun the LoRA fine-tuning experiments across multiple random seeds, report mean WER with standard deviations, and add paired statistical significance tests (e.g., Wilcoxon signed-rank) comparing the fine-tuned model to the frozen baseline. These results and tests will be included in the revised §5 and tables. revision: yes
-
Referee: [§3] §3 (Benchmark Construction) and data split description: The SAP splits and model selections are not analyzed for potential correlations between speaker traits (e.g., severity, diagnosis) and prompt content, which could introduce bias favoring the no-improvement conclusion; the skeptic's concern about representativeness of clinical descriptions is load-bearing for the claim that models inherently fail to leverage context.
Authors: We will add an analysis in the revised §3 that examines correlations between speaker traits (severity, diagnosis) and the clinical description content across the data splits. The clinical descriptions are taken directly from SAP clinician annotations; we will expand the text to discuss their scope and limitations explicitly. While these additions address the concern about potential bias, we maintain that the benchmark evaluates models using the context actually available in the dataset. revision: partial
Circularity Check
Purely empirical evaluation with no derivations or self-referential reductions
full rationale
The paper introduces an empirical benchmark on the SAP dataset, runs matched comparisons of nine audio-language models under varying prompt conditions (diagnosis labels, clinical ratings, detailed descriptions), reports WER changes, and performs LoRA fine-tuning experiments. No equations, first-principles derivations, or predictions are claimed; all results are direct measurements on external data splits and model outputs. No self-citation chains or fitted parameters are presented as independent predictions. The central claim (models do not meaningfully use multimodal context in zero-shot prompting) is grounded in observable WER deltas rather than any construction that reduces to the inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models , author=. arXiv preprint arXiv:2311.07919 , year=
work page internal anchor Pith review arXiv
-
[3]
2024 , eprint=
Qwen2-Audio Technical Report , author=. 2024 , eprint=
2024
-
[4]
2022 , eprint=
Robust Speech Recognition via Large-Scale Weak Supervision , author=. 2022 , eprint=
2022
-
[5]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[6]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[7]
Huang and Kenneth Watkin and Simone Frame , year =
Heejin Kim and Mark Hasegawa-Johnson and Adrienne Perlman and Jon Gunderson and Thomas S. Huang and Kenneth Watkin and Simone Frame , year =. doi:10.21437/Interspeech.2008-480 , issn =
-
[8]
The TORGO database of acoustic and articulatory speech from speakers with dysarthria , volume =
Rudzicz, Frank and Namasivayam, Aravind and Wolff, Talya , year =. The TORGO database of acoustic and articulatory speech from speakers with dysarthria , volume =. Language Resources and Evaluation , doi =
-
[9]
2025 , eprint=
The Interspeech 2025 Speech Accessibility Project Challenge , author=. 2025 , eprint=
2025
-
[10]
Robust Speech Recognition via Large-Scale Weak Supervision
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. 2022 , copyright =. doi:10.48550/ARXIV.2212.04356 , url =
-
[11]
Advances in Neural Information Processing Systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2104.01027 , year=
Robust wav2vec 2.0: Analyzing domain shift in self-supervised pre-training , author=. arXiv preprint arXiv:2104.01027 , year=
-
[13]
Qwen2-Audio Technical Report , author=. arXiv preprint arXiv:2407.10759 , year=
work page internal anchor Pith review arXiv
-
[14]
Qwen3-Omni Technical Report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review arXiv
-
[15]
Qwen3-ASR Technical Report , author=. arXiv preprint arXiv:2601.21337 , year=
work page internal anchor Pith review arXiv
-
[16]
Cohere Transcribe: State-of-the-Art Open-Source Speech Recognition , year =
-
[17]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[18]
2026 , howpublished=
Gemma 4: Byte for byte, the most capable open models , author=. 2026 , howpublished=
2026
-
[19]
2025 , eprint=
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models , author=. 2025 , eprint=
2025
- [20]
-
[21]
2026 , eprint=
Voxtral Realtime , author=. 2026 , eprint=
2026
-
[22]
2025 , eprint=
Voxtral , author=. 2025 , eprint=
2025
-
[23]
2023 , eprint=
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition , author=. 2023 , eprint=
2023
-
[24]
Ultravox: An Open, Fast, and Extensible Multimodal Model for Audio Understanding , year =
-
[25]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[26]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[27]
2025 , eprint=
Aligning ASR Evaluation with Human and LLM Judgments: Intelligibility Metrics Using Phonetic, Semantic, and NLI Approaches , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Zero-Shot Recognition of Dysarthric Speech Using Commercial Automatic Speech Recognition and Multimodal Large Language Models , author=. 2025 , eprint=
2025
-
[29]
2020 , eprint=
Adversarial NLI: A New Benchmark for Natural Language Understanding , author=. 2020 , eprint=
2020
-
[30]
State-transition interpolation and map adaptation for HMM-based dysarthric speech recognition
Sharma, \ Harsh Vardhan\ and Mark Hasegawa-Johnson. State-transition interpolation and map adaptation for HMM-based dysarthric speech recognition. 2010
2010
-
[31]
Estimation of Phoneme-Specific HMM Topologies for the Automatic Recognition of Dysarthric Speech , volume =
Caballero, Omar , year =. Estimation of Phoneme-Specific HMM Topologies for the Automatic Recognition of Dysarthric Speech , volume =. Computational and mathematical methods in medicine , doi =
-
[32]
Proceedings of Interspeech 2016 , pages =
Recognition of Dysarthric Speech Using Voice Parameters for Speaker Adaptation and Multi-Taper Spectral Estimation , author =. Proceedings of Interspeech 2016 , pages =. 2016 , doi =
2016
-
[33]
Proceedings of Interspeech 2023 , pages =
Few-shot Dysarthric Speech Recognition with Text-to-Speech Data Augmentation , author =. Proceedings of Interspeech 2023 , pages =. 2023 , doi =
2023
-
[34]
Two-stage data augmentation for improved ASR performance for dysarthric speech , journal =
Chitralekha Bhat and Helmer Strik , keywords =. Two-stage data augmentation for improved ASR performance for dysarthric speech , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.compbiomed.2025.109954 , url =
-
[35]
2025 , eprint=
Personalized Fine-Tuning with Controllable Synthetic Speech from LLM-Generated Transcripts for Dysarthric Speech Recognition , author=. 2025 , eprint=
2025
-
[36]
2024 , eprint=
A Survey on In-context Learning , author=. 2024 , eprint=
2024
-
[37]
2024 , eprint=
Visual In-Context Learning for Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
In-Context Learning Boosts Speech Recognition via Human-like Adaptation to Speakers and Language Varieties , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Understanding and Mitigating the Bias Inheritance in LLM-based Data Augmentation on Downstream Tasks , author=. 2025 , eprint=
2025
-
[40]
Jacob T. Urbina and Peter D. Vu and Michael V. Nguyen , keywords =. Disability Ethics and Education in the Age of Artificial Intelligence: Identifying Ability Bias in ChatGPT and Gemini , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.apmr.2024.08.014 , url =
-
[41]
Overcoming Speech Barriers: Non-Verbal Voice Cue Interaction Technique for Enhancing Smart Voice Assistant Accessibility for Individuals with Dysarthria , author=. 2025 , howpublished=. doi:10.1145/3726874 , url=
-
[42]
Documentation of Disability Status and Accommodation Needs in the Electronic Health Record: A Qualitative Study of Health Care Organizations' Current Practices , author=. 2024 , howpublished=. doi:10.1016/j.jcjq.2023.10.006 , url=
-
[43]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[44]
2025 , eprint=
Adapting Foundation Speech Recognition Models to Impaired Speech: A Semantic Re-chaining Approach for Personalization of German Speech , author=. 2025 , eprint=
2025
-
[45]
Zhang, Yu and Park, Daniel S. and Han, Wei and Qin, James and Gulati, Anmol and Shor, Joel and Jansen, Aren and Xu, Yuanzhong and Huang, Yanping and Wang, Shibo and Zhou, Zongwei and Li, Bo and Ma, Min and Chan, William and Yu, Jiahui and Wang, Yongqiang and Cao, Liangliang and Sim, Khe Chai and Ramabhadran, Bhuvana and Sainath, Tara N. and Beaufays, Fran...
-
[46]
, title =
Rabiner, Lawrence R. , title =. Proceedings of the IEEE , year =
-
[47]
Tobin, J. and Nelson, P. and MacDonald, B. and Heywood, R. and Cave, R. and Seaver, K. and Desjardins, A. and Jiang, P. P. and Green, J. R. , title =. Journal of Speech, Language, and Hearing Research , year =. doi:10.1044/2024_JSLHR-24-00045 , pmid =
-
[48]
Population: The 2012 National Health Interview Survey (NHIS) , author =
Voice, Speech, and Language Disorders in the U.S. Population: The 2012 National Health Interview Survey (NHIS) , author =. Abstracts of the 47th Annual Meeting of the Society for Epidemiologic Research , address =. 2014 , month =
2012
-
[49]
Variational Low-Rank Adaptation for Personalized Impaired Speech Recognition , year=
Pokel, Niclas and Moure, Pehuén and Boehringer, Roman and Liu, Shih-Chii and Gao, Yingqiang , booktitle=. Variational Low-Rank Adaptation for Personalized Impaired Speech Recognition , year=
-
[50]
2012 , publisher=
Rudzicz, Frank and Namasivayam, Aravind Kumar and Wolff, Talya , journal=. 2012 , publisher=
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.