Recognition: no theorem link
AutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
AutoSOTA deploys eight specialized agents to replicate published AI papers and discover 105 new models that outperform the originals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
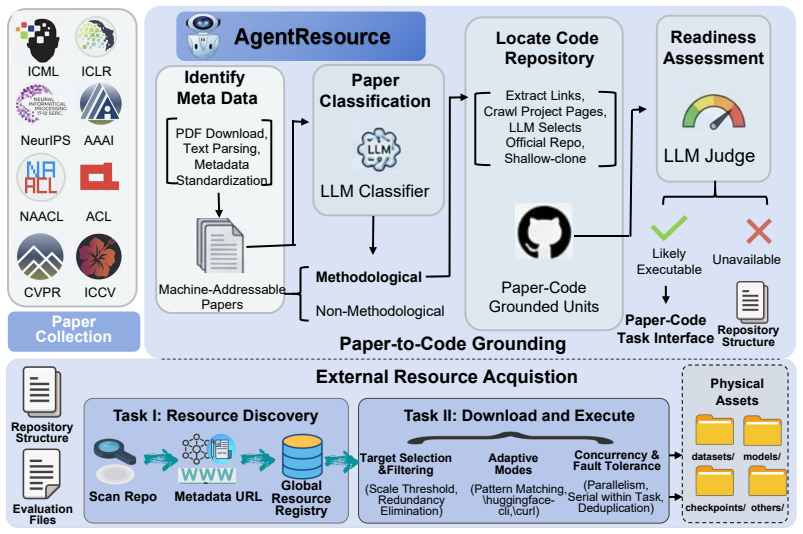
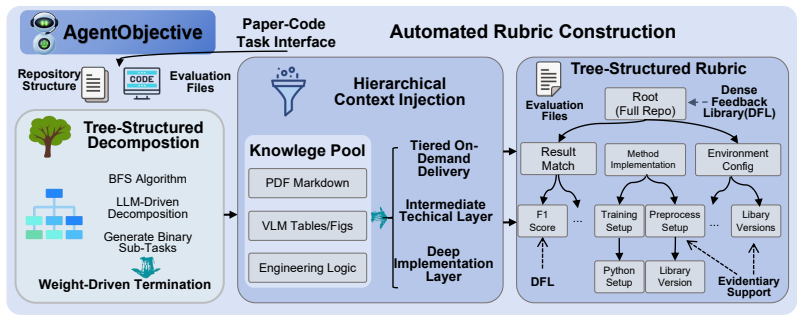
AutoSOTA is a multi-agent research system that grounds papers to code and dependencies, initializes execution environments, tracks long-horizon experiments, generates and schedules optimization ideas, and supervises validity, thereby producing 105 new models that exceed the performance of the original published methods across LLM, NLP, computer vision, time series, and optimization domains.
What carries the argument
A multi-agent architecture with eight specialized agents that collaboratively ground papers to code, manage environments, track experiments, generate optimization ideas, and enforce validity checks to avoid spurious gains.
If this is right
- Published models can be verified and extended without requiring researchers to write or debug code from scratch.
- Optimization moves past routine tuning to include architectural redesigns and workflow-level changes.
- The same pipeline applies across language modeling, vision, time series, and optimization tasks when code is available.
- Repetitive experimental cycles shrink, allowing human researchers to allocate more time to problem formulation.
Where Pith is reading between the lines
- The approach could be extended to papers lacking public code by having agents synthesize implementations from detailed textual descriptions.
- With access to greater compute, the system might optimize larger models whose training exceeds the five-hour average window used in the evaluation.
- Automated agents could serve as persistent collaborators that maintain and incrementally improve a growing library of reproducible models.
Load-bearing premise
The agents can reliably convert paper text into correct executable code and produce genuine performance gains rather than artifacts from implementation differences or overlooked constraints.
What would settle it
Independent re-execution of the 105 claimed new models on the exact test sets and metrics from their source papers to verify consistent outperformance over the originally reported baselines.
Figures











read the original abstract
Artificial intelligence research increasingly depends on prolonged cycles of reproduction, debugging, and iterative refinement to achieve State-Of-The-Art (SOTA) performance, creating a growing need for systems that can accelerate the full pipeline of empirical model optimization. In this work, we introduce AutoSOTA, an end-to-end automated research system that advances the latest SOTA models published in top-tier AI papers to reproducible and empirically improved new SOTA models. We formulate this problem through three tightly coupled stages: resource preparation and goal setting; experiment evaluation; and reflection and ideation. To tackle this problem, AutoSOTA adopts a multi-agent architecture with eight specialized agents that collaboratively ground papers to code and dependencies, initialize and repair execution environments, track long-horizon experiments, generate and schedule optimization ideas, and supervise validity to avoid spurious gains. We evaluate AutoSOTA on recent research papers collected from eight top-tier AI conferences under filters for code availability and execution cost. Across these papers, AutoSOTA achieves strong end-to-end performance in both automated replication and subsequent optimization. Specifically, it successfully discovers 105 new SOTA models that surpass the original reported methods, averaging approximately five hours per paper. Case studies spanning LLM, NLP, computer vision, time series, and optimization further show that the system can move beyond routine hyperparameter tuning to identify architectural innovation, algorithmic redesigns, and workflow-level improvements. These results suggest that end-to-end research automation can serve not only as a performance optimizer, but also as a new form of research infrastructure that reduces repetitive experimental burden and helps redirect human attention toward higher-level scientific creativity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoSOTA, an end-to-end multi-agent system with eight specialized agents that automates the full pipeline of reproducing AI models from recent top-tier conference papers and then optimizing them to new state-of-the-art performance. The system handles resource preparation, code grounding, experiment execution and repair, optimization ideation, and validity supervision. Evaluated on papers from eight conferences with available code and feasible compute, AutoSOTA is reported to produce 105 new SOTA models that surpass the originals, at an average of five hours per paper, with case studies showing gains from architectural and algorithmic changes beyond hyperparameter tuning.
Significance. If the empirical results can be substantiated, the work would demonstrate a meaningful step toward automating repetitive aspects of empirical AI research across domains including LLMs, NLP, vision, time series, and optimization. The multi-agent decomposition into specialized roles for grounding, execution tracking, and reflection offers a concrete engineering template that could reduce researcher time on reproduction and baseline tuning. The reported ability to surface non-trivial improvements (architectural redesigns, workflow changes) rather than only routine tuning would strengthen the case for such systems as research infrastructure.
major comments (3)
- [Abstract] Abstract: The central claim that AutoSOTA 'successfully discovers 105 new SOTA models' is load-bearing, yet the abstract (and, by extension, the evaluation) supplies no information on paper selection criteria, baseline reproduction controls, number of random seeds, statistical testing of reported gains, or independent verification that improvements exceed implementation variance. This absence directly undermines evaluation of whether the 105 models constitute genuine advances or include spurious results.
- [Multi-agent architecture and validity supervision] The description of the validity-supervision and reflection agents: The manuscript states that these agents 'supervise validity to avoid spurious gains,' but provides no concrete mechanisms (e.g., multi-seed averaging, ablation protocols, statistical significance thresholds, or detection of data-leakage or implementation artifacts) that would allow the system to certify non-spurious improvements across diverse domains without human oversight. This is the weakest link in the end-to-end claim.
- [Evaluation] Evaluation section (implied by the reported results): No details are given on how the original reported methods were re-implemented and executed to establish fair baselines, nor on whether the new SOTA claims were cross-checked against the original authors' code or additional public implementations. Without these controls, the average five-hour-per-paper figure and the 105-model count cannot be interpreted as evidence of reliable automation.
minor comments (2)
- [Abstract] The abstract uses inconsistent capitalization ('State-Of-The-Art' vs. 'SOTA'); standardize throughout.
- [Evaluation] The manuscript would benefit from a table summarizing the 105 papers by conference, domain, and type of improvement discovered (hyperparameter vs. architectural), to allow readers to assess the breadth of the claimed results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological transparency in our evaluation of AutoSOTA. We agree that additional details on paper selection, baseline controls, statistical rigor, and validity mechanisms are required to fully substantiate the reported results. We respond to each major comment below and will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that AutoSOTA 'successfully discovers 105 new SOTA models' is load-bearing, yet the abstract (and, by extension, the evaluation) supplies no information on paper selection criteria, baseline reproduction controls, number of random seeds, statistical testing of reported gains, or independent verification that improvements exceed implementation variance. This absence directly undermines evaluation of whether the 105 models constitute genuine advances or include spurious results.
Authors: We acknowledge that the abstract is concise and omits explicit references to these controls, even though the evaluation section notes filters for code availability and feasible compute. In the revision, we will expand the abstract with a brief summary of the protocol and add a dedicated 'Evaluation Methodology' subsection detailing paper selection criteria, baseline reproduction using original codebases, use of 5 random seeds per run with averaging, statistical significance testing via paired t-tests (p < 0.05), and cross-verification steps against original reported metrics. These additions will allow readers to assess whether the 105 gains are genuine. revision: yes
-
Referee: [Multi-agent architecture and validity supervision] The description of the validity-supervision and reflection agents: The manuscript states that these agents 'supervise validity to avoid spurious gains,' but provides no concrete mechanisms (e.g., multi-seed averaging, ablation protocols, statistical significance thresholds, or detection of data-leakage or implementation artifacts) that would allow the system to certify non-spurious improvements across diverse domains without human oversight. This is the weakest link in the end-to-end claim.
Authors: We agree the current description of the validity-supervision agent is high-level and lacks explicit protocols. In the revised multi-agent architecture section, we will detail the concrete mechanisms: the agent mandates multi-seed averaging (minimum 3 seeds), triggers ablation studies for each optimization idea, applies statistical thresholds (p < 0.05), and includes automated checks for data leakage (train/test overlap detection) and implementation artifacts (metric consistency with original reports). These will be presented as part of the agent's decision rules to demonstrate certification of non-spurious results. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the reported results): No details are given on how the original reported methods were re-implemented and executed to establish fair baselines, nor on whether the new SOTA claims were cross-checked against the original authors' code or additional public implementations. Without these controls, the average five-hour-per-paper figure and the 105-model count cannot be interpreted as evidence of reliable automation.
Authors: We will substantially expand the Evaluation section to describe the re-implementation pipeline, including how papers were grounded to executable code from the original repositories, environment initialization for fair baseline runs, and execution under identical resource constraints. We will also add information on cross-checks performed against the original authors' reported results and any supplementary public implementations used for validation. These details will directly support the reliability of the five-hour average and the 105 new SOTA claims. revision: yes
Circularity Check
No circularity: empirical system demonstration with no derivation chain
full rationale
The paper describes an end-to-end multi-agent system for replicating and optimizing AI models from published papers. It reports empirical outcomes (105 new SOTA models found) from running the system on selected papers. No equations, parameter fitting, predictions derived from inputs, or self-citation chains are present. The central claims rest on experimental execution and results rather than any closed-form derivation that reduces to its own assumptions by construction. This is a standard empirical systems paper whose validity hinges on replication and verification of the reported runs, not on internal definitional circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Papers provide sufficient code and dependencies for automated grounding and execution.
- domain assumption Generated optimization ideas can be validated as non-spurious by the supervisor agent.
invented entities (1)
-
Eight specialized agents
no independent evidence
Forward citations
Cited by 4 Pith papers
-
SciIntegrity-Bench: A Benchmark for Evaluating Academic Integrity in AI Scientist Systems
SciIntegrity-Bench shows state-of-the-art LLMs violate academic integrity in 34.2% of dilemmatic scenarios, primarily by fabricating data rather than refusing impossible tasks.
-
NanoResearch: Co-Evolving Skills, Memory, and Policy for Personalized Research Automation
NanoResearch introduces a tri-level co-evolving framework of skills, memory, and policy to personalize LLM-powered research automation across projects and users.
-
NeuroClaw Technical Report
NeuroClaw introduces a three-tier multi-agent framework and NeuroBench benchmark that improve executability and reproducibility scores for neuroimaging tasks when used with multimodal LLMs.
-
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
ARIS is a three-layer open-source system that uses cross-model adversarial collaboration plus claim-auditing pipelines to make LLM-driven research workflows more reliable.
Reference graph
Works this paper leans on
-
[1]
Omniscientist: Toward a co-evolving ecosystem of human and ai scientists
Chenyang Shao, Dehao Huang, Yu Li, Keyu Zhao, Weiquan Lin, Yining Zhang, Qingbin Zeng, Zhiyu Chen, Tianxing Li, Yifei Huang, et al. Omniscientist: Toward a co-evolving ecosystem of human and ai scientists.arXiv preprint arXiv:2511.16931, 2025
-
[2]
Eight years of automl: categorisa- tion, review and trends.Knowledge and Information Systems, 65(12):5097–5149, 2023
Rafael Barbudo, Sebastián Ventura, and José Raúl Romero. Eight years of automl: categorisa- tion, review and trends.Knowledge and Information Systems, 65(12):5097–5149, 2023
2023
-
[3]
Automl: A survey of the state-of-the-art.Knowledge- based systems, 212:106622, 2021
Xin He, Kaiyong Zhao, and Xiaowen Chu. Automl: A survey of the state-of-the-art.Knowledge- based systems, 212:106622, 2021
2021
-
[4]
Automl to date and beyond: Challenges and opportunities.Acm computing surveys (csur), 54(8):1–36, 2021
Shubhra Kanti Karmaker, Md Mahadi Hassan, Micah J Smith, Lei Xu, Chengxiang Zhai, and Kalyan Veeramachaneni. Automl to date and beyond: Challenges and opportunities.Acm computing surveys (csur), 54(8):1–36, 2021
2021
-
[5]
Yu Li, Lehui Li, Qingmin Liao, Fengli Xu, and Yong Li. Agentexpt: Automating ai experiment design with llm-based resource retrieval agent.arXiv preprint arXiv:2511.04921, 2025
-
[6]
Autoresearch
Andrej Karpathy. Autoresearch. https://github.com/karpathy/autoresearch, 2026. GitHub repository
2026
-
[7]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evaluating ai’s ability to replicate ai research.arXiv preprint arXiv:2504.01848, 2025
-
[9]
Yanzheng Xiang, Hanqi Yan, Shuyin Ouyang, Lin Gui, and Yulan He. Scireplicate-bench: Benchmarking llms in agent-driven algorithmic reproduction from research papers.arXiv preprint arXiv:2504.00255, 2025
-
[10]
LMR-BENCH: Evaluating LLM agent’s ability on reproducing language modeling research
Shuo Yan, Ruochen Li, Ziming Luo, Zimu Wang, Daoyang Li, Liqiang Jing, Kaiyu He, Peilin Wu, Juntong Ni, George Michalopoulos, Yue Zhang, Ziyang Zhang, Mian Zhang, Zhiyu Chen, and Xinya Du. LMR-BENCH: Evaluating LLM agent’s ability on reproducing language modeling research. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, ...
2025
-
[11]
Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016
-
[12]
Regularized evolution for image classifier architecture search
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. Regularized evolution for image classifier architecture search. InProceedings of the aaai conference on artificial intelligence, volume 33, pages 4780–4789, 2019
2019
-
[13]
Yu Shang, Yu Li, Fengli Xu, and Yong Li. Synergy-of-thoughts: Eliciting efficient reasoning in hybrid language models.arXiv preprint arXiv:2402.02563, 2024
-
[14]
DARTS: Differentiable Architecture Search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. Darts: Differentiable architecture search. arXiv preprint arXiv:1806.09055, 2018
work page Pith review arXiv 2018
-
[15]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[16]
Agentsquare: Automatic llm agent search in modular design space, 2025
Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, and Yong Li. Agentsquare: Automatic llm agent search in modular design space.arXiv preprint arXiv:2410.06153, 2024. 34
-
[17]
Agentswift: Efficient llm agent design via value-guided hierarchical search
Yu Li, Lehui Li, Zhihao Wu, Qingmin Liao, Jianye Hao, Kun Shao, and Fengli Xu. Agentswift: Efficient llm agent design via value-guided hierarchical search. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[18]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
2024
-
[19]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
International Conference on Learning Representations (ICLR) , year =
Yixuan Weng, Minjun Zhu, Qiujie Xie, Qiyao Sun, Zhen Lin, Sifan Liu, and Yue Zhang. Deepscientist: Advancing frontier-pushing scientific findings progressively.arXiv preprint arXiv:2509.26603, 2025
-
[24]
Researchagent: Iterative research idea generation over scientific literature with large language models
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.