Recognition: unknown
RAG over Thinking Traces Can Improve Reasoning Tasks
Pith reviewed 2026-05-07 14:29 UTC · model grok-4.3
The pith
Retrieving thinking traces from problem-solving attempts improves reasoning performance on math and code benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
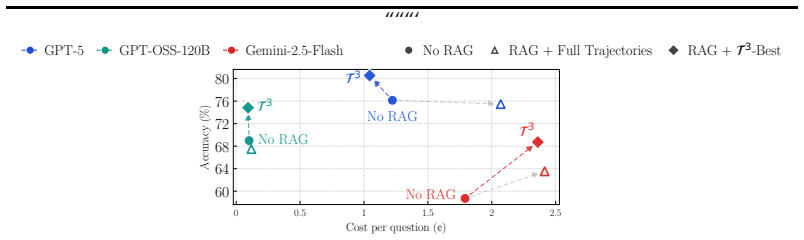
Retrieving from a corpus of thinking traces generated during problem-solving attempts enables a simple retrieve-then-generate pipeline to improve reasoning performance across benchmarks including AIME 2025-2026, LiveCodeBench, and GPQA-Diamond. The approach outperforms both non-RAG methods and retrieval over web documents, with further gains from the T3 offline transformation that produces structured representations of the traces. Relative improvements reach 56.3 percent on AIME when using traces from Gemini-2-thinking with Gemini-2.5-Flash, and the method works even when the trace-generating model differs from the one answering new queries.
What carries the argument
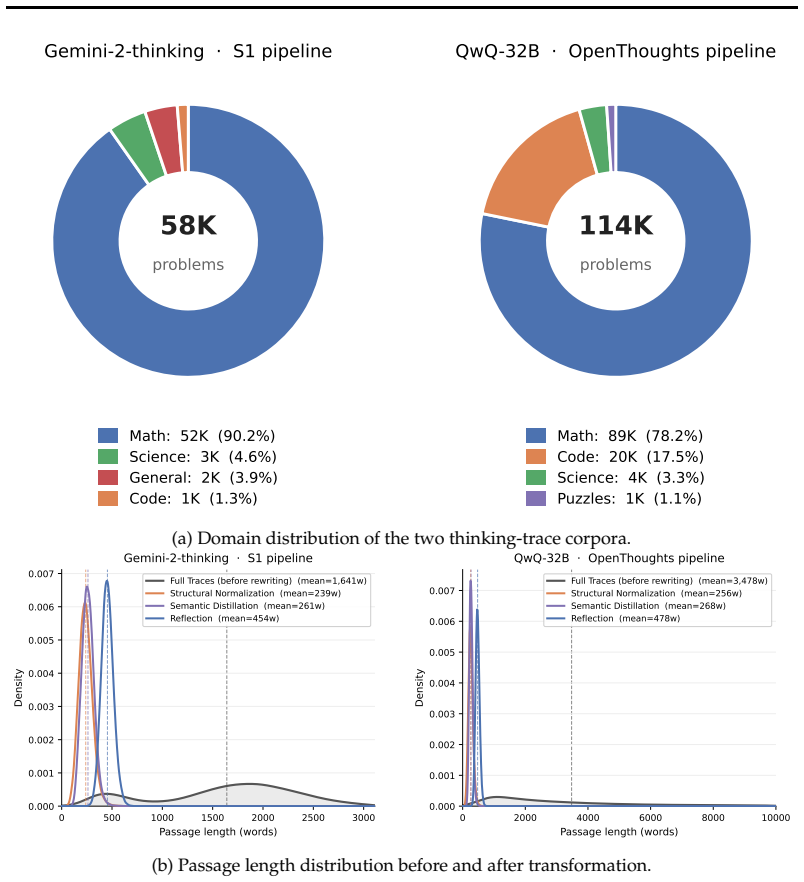
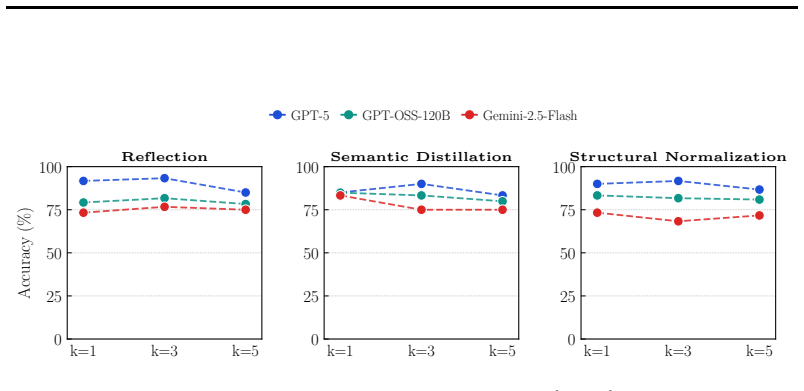
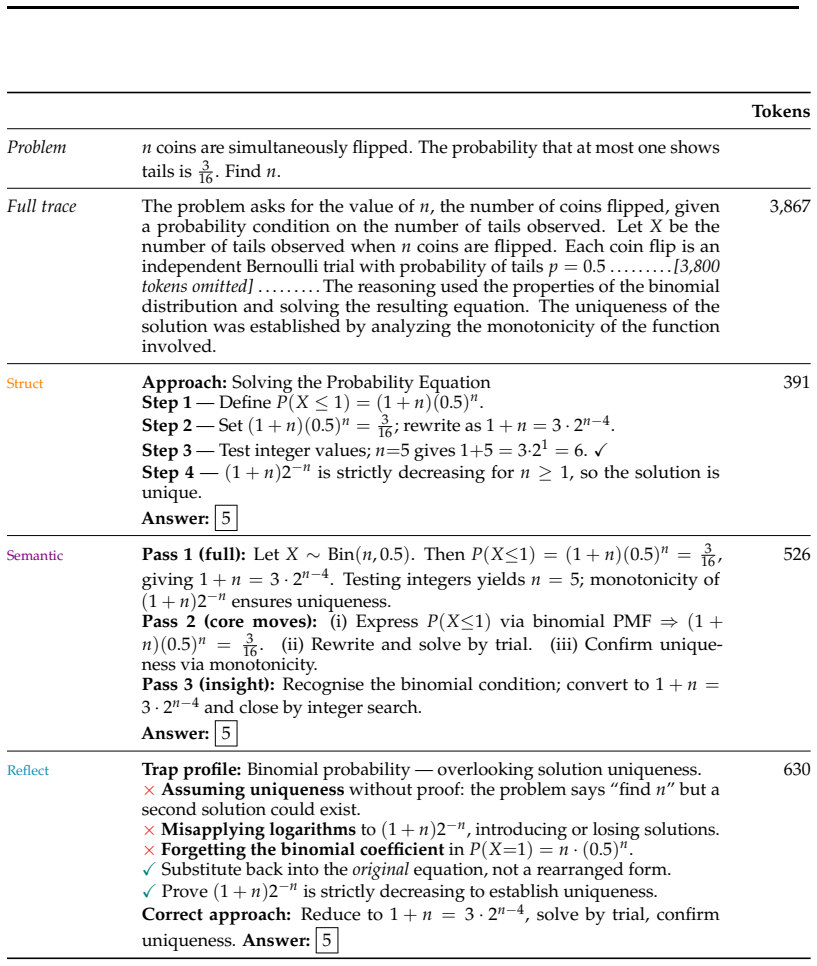
Thinking traces, the intermediate reasoning trajectories produced while attempting to solve problems, used directly as the retrieval corpus in a RAG pipeline, together with the T3 offline method that converts raw traces into structured, compact, and diagnostic representations for improved matching and usability.
If this is right
- RAG over thinking traces outperforms retrieval from standard web corpora on reasoning benchmarks.
- Gains persist even when traces come from an earlier model and are applied to more recent models.
- The T3-structured version of the corpus can reduce inference cost by up to 15 percent while raising accuracy.
- Consistent improvements appear across model scales and across math, code, and science benchmarks.
Where Pith is reading between the lines
- If traces carry reusable reasoning patterns, then curating large shared libraries of high-quality thinking traces could become a practical way to augment future models without retraining.
- The results suggest that external retrieval of intermediate steps may sometimes be cheaper and more reliable than forcing a model to regenerate every reasoning path from scratch.
- This technique could be tested on domains outside math and code, such as scientific hypothesis generation, where intermediate reasoning steps are also recorded.
Load-bearing premise
Thinking traces generated during problem-solving attempts contain generalizable, high-quality reasoning signals that transfer usefully to new problems and different models without introducing systematic errors or biases from the trace-generation process itself.
What would settle it
Running the same retrieve-then-generate experiments on AIME or LiveCodeBench but replacing the thinking-traces corpus with either randomly ordered traces or traces drawn from unrelated problem domains, and observing whether performance gains disappear or reverse.
Figures








read the original abstract
Retrieval-augmented generation (RAG) has proven effective for knowledge-intensive tasks, but is widely believed to offer limited benefit for reasoning-intensive problems such as math and code generation. We challenge this assumption by showing that the limitation lies not in RAG itself, but in the choice of corpus. Instead of retrieving documents, we propose retrieving thinking traces, i.e., intermediate thinking trajectories generated during problem solving attempts. We show that thinking traces are already a strong retrieval source, and further introduce T3, an offline method that transforms them into structured, retrieval-friendly representations, to improve usability. Using these traces as a corpus, a simple retrieve-then-generate pipeline consistently improves reasoning performance across strong models and benchmarks such as AIME 2025--2026, LiveCodeBench, and GPQA-Diamond, outperforming both non-RAG baselines and retrieval over standard web corpora. For instance, on AIME, RAG with traces generated by Gemini-2-thinking achieves relative gains of +56.3%, +8.6%, and +7.6% for Gemini-2.5-Flash, GPT-OSS-120B, and GPT-5, respectively, even though these are more recent models. Interestingly, RAG on T3 also incurs little or no extra inference cost, and can even reduce inference cost by up to $15%$. Overall, our results suggest that thinking traces are an effective retrieval corpus for reasoning tasks, and transforming them into structured, compact, or diagnostic representations unlocks even stronger gains. Code available at https://github.com/Narabzad/t3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that retrieval-augmented generation (RAG) over thinking traces—intermediate reasoning trajectories generated during problem-solving attempts—can substantially improve performance on reasoning-intensive tasks such as mathematics and code generation, contrary to the common view that RAG is ineffective for such problems. The authors introduce T3, an offline method to convert raw traces into structured, retrieval-friendly representations, and report that a simple retrieve-then-generate pipeline using these traces as the corpus yields consistent gains over non-RAG baselines and standard web-document RAG on benchmarks including AIME 2025-2026, LiveCodeBench, and GPQA-Diamond. Specific results include relative improvements of +56.3% on AIME for Gemini-2.5-Flash, +8.6% for GPT-OSS-120B, and +7.6% for GPT-5 when using traces from Gemini-2-thinking, with little or no added inference cost and sometimes up to 15% cost reduction. Code is released at the provided GitHub repository.
Significance. If the results hold without data leakage or other confounds, the work is significant because it provides concrete empirical evidence that the choice of corpus, rather than RAG itself, limits its utility on reasoning tasks. Demonstrating that thinking traces contain transferable, high-quality reasoning signals that can be retrieved to augment even strong models without extra cost could influence how reasoning systems are built, shifting focus toward curating and structuring intermediate reasoning data. The release of code supports reproducibility and further exploration in the IR and LLM reasoning communities.
major comments (2)
- [Abstract and §3] Abstract and §3 (trace corpus construction): The headline empirical claim—that retrieve-then-generate over thinking traces produces generalizable reasoning augmentation—requires that the trace corpus was built exclusively on problems disjoint from the test sets (AIME 2025-2026, LiveCodeBench, GPQA-Diamond). The manuscript describes traces only as coming from “problem solving attempts” without stating or verifying a hold-out split. If any test problem appears in the corpus, retrieval can surface its own solution trajectory, converting the pipeline into answer lookup rather than reasoning transfer. This directly undermines the interpretation of the reported gains (e.g., +56.3% relative on AIME).
- [§4] §4 (experimental results): The reported relative improvements are given without accompanying absolute accuracies, standard deviations across runs, or statistical significance tests. This makes it difficult to assess whether the gains are robust or driven by benchmark-specific variance, especially when comparing across models of different strengths.
minor comments (2)
- [Abstract] The T3 transformation is described at a high level in the abstract; a concise pseudocode or diagram in the main text would improve clarity on how raw traces are turned into structured representations.
- The manuscript could add a short related-work paragraph contrasting this approach with prior uses of chain-of-thought or self-generated data for retrieval or distillation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have incorporated revisions to improve clarity and completeness of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (trace corpus construction): The headline empirical claim—that retrieve-then-generate over thinking traces produces generalizable reasoning augmentation—requires that the trace corpus was built exclusively on problems disjoint from the test sets (AIME 2025-2026, LiveCodeBench, GPQA-Diamond). The manuscript describes traces only as coming from “problem solving attempts” without stating or verifying a hold-out split. If any test problem appears in the corpus, retrieval can surface its own solution trajectory, converting the pipeline into answer lookup rather than reasoning transfer. This directly undermines the interpretation of the reported gains (e.g., +56.3% relative on AIME).
Authors: We agree this is a crucial clarification for interpreting the results as reasoning transfer rather than leakage. The thinking traces were generated exclusively from problem-solving attempts on problems drawn from training splits of MATH, GSM8K, and other sources that have no overlap with AIME 2025-2026, LiveCodeBench, or GPQA-Diamond; we verified this by checking problem IDs and content hashes. We have revised §3 to explicitly document the corpus sources, the disjointness verification procedure, and a statement confirming zero overlap with the evaluation sets. This addition directly addresses the concern without altering any experimental results. revision: yes
-
Referee: [§4] §4 (experimental results): The reported relative improvements are given without accompanying absolute accuracies, standard deviations across runs, or statistical significance tests. This makes it difficult to assess whether the gains are robust or driven by benchmark-specific variance, especially when comparing across models of different strengths.
Authors: We acknowledge that absolute numbers and statistical details improve interpretability. In the revised manuscript we have updated all tables in §4 to report absolute accuracies alongside the relative gains, included standard deviations computed over 5 independent runs for each condition, and added paired statistical significance tests (McNemar’s test for binary correctness and t-tests on accuracy) with p-values. These changes allow readers to evaluate robustness directly while preserving the original claims. revision: yes
Circularity Check
No circularity; purely empirical evaluation with independent benchmark comparisons.
full rationale
The paper advances an empirical claim that RAG over thinking traces improves reasoning performance. It describes generating traces from problem-solving attempts, applying an offline T3 transformation, and running retrieve-then-generate experiments on public benchmarks (AIME 2025-2026, LiveCodeBench, GPQA-Diamond). All reported gains are direct outcome measurements against non-RAG and web-corpus baselines; no equations, fitted parameters, or derivations appear that could reduce to self-definition or prior self-citations. The methodology is externally replicable via the released code and stated benchmarks, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Thinking traces generated by LLMs during problem solving contain useful, retrievable signals for improving reasoning on new problems.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
OpenThoughts: Data Recipes for Reasoning Models , author=. 2025 , eprint=
2025
-
[2]
Unsupervised Dense Information Retrieval with Contrastive Learning
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
work page internal anchor Pith review arXiv
-
[3]
DS SERVE: A Framework for Efficient and Scalable Neural Retrieval , author=
-
[4]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[5]
2024 , eprint=
Great Memory, Shallow Reasoning: Limits of k NN-LMs , author=. 2024 , eprint=
2024
-
[6]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling reasoning capabilities into smaller language models , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[7]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Teaching small language models to reason , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[8]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Large language models are reasoning teachers , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[9]
2024 , eprint=
Scaling Retrieval-Based Language Models with a Trillion-Token Datastore , author=. 2024 , eprint=
2024
-
[10]
2024 , month = nov, howpublished =
2024
-
[11]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Can retriever-augmented language models reason? the blame game between the retriever and the language model , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[13]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[14]
2023 , eprint=
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
2023
-
[15]
arXiv preprint arXiv:1911.10470 , year=
Learning to retrieve reasoning paths over wikipedia graph for question answering , author=. arXiv preprint arXiv:1911.10470 , year=
-
[16]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review arXiv
-
[17]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[18]
2026 , eprint=
CompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering , author=. 2026 , eprint=
2026
-
[19]
2024 , eprint=
Retrieval Augmented Thought Process for Private Data Handling in Healthcare , author=. 2024 , eprint=
2024
-
[20]
2024 , eprint=
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation , author=. 2024 , eprint=
2024
-
[21]
2025 , eprint=
Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts , author=. 2025 , eprint=
2025
-
[22]
Fang, Jinyuan and Meng, Zaiqiao and MacDonald, Craig. TRACE the Evidence: Constructing Knowledge-Grounded Reasoning Chains for Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.496
-
[23]
arXiv preprint arXiv:2603.10600 , year=
Trajectory-Informed Memory Generation for Self-Improving Agent Systems , author=. arXiv preprint arXiv:2603.10600 , year=
-
[24]
2026 , eprint=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. 2026 , eprint=
2026
-
[25]
2025 , eprint=
Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. 2024 , eprint=
2024
-
[27]
2025 , eprint=
s1: Simple test-time scaling , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
Frustratingly Simple Retrieval Improves Challenging, Reasoning-Intensive Benchmarks , author=. 2025 , eprint=
2025
-
[29]
DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis , author=. arXiv preprint arXiv:2508.20033 , year=
-
[30]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review arXiv
-
[31]
2021 , eprint=
NaturalProofs: Mathematical Theorem Proving in Natural Language , author=. 2021 , eprint=
2021
-
[32]
IEEE Transactions on Big Data , volume=
Billion-scale similarity search with GPUs , author=. IEEE Transactions on Big Data , volume=. 2019 , publisher=
2019
-
[33]
2023 , eprint=
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text , author=. 2023 , eprint=
2023
-
[34]
Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data
Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data , author=. arXiv preprint arXiv:2410.01560 , year=
-
[35]
2022 , eprint=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. 2022 , eprint=
2022
-
[36]
How much knowledge can you pack into the parameters of a language model? , author=. arXiv preprint arXiv:2002.08910 , year=
-
[37]
2023 , eprint=
Retrieval-augmented Generation to Improve Math Question-Answering: Trade-offs Between Groundedness and Human Preference , author=. 2023 , eprint=
2023
-
[38]
arXiv preprint arXiv:2402.14594 , year=
Improving assessment of tutoring practices using retrieval-augmented generation , author=. arXiv preprint arXiv:2402.14594 , year=
-
[39]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
A survey on rag meeting llms: Towards retrieval-augmented large language models , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[40]
Openwebmath: An open dataset of high-quality mathematical web text , author=. arXiv preprint arXiv:2310.06786 , year=
-
[41]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[42]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author =. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review arXiv
-
[43]
International conference on machine learning , pages=
Improving language models by retrieving from trillions of tokens , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[44]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review arXiv
-
[45]
arXiv preprint arXiv:2504.14858 , year=
Retrieval is Not Enough: Enhancing RAG Reasoning through Test-Time Critique and Optimization , author=. arXiv preprint arXiv:2504.14858 , year=
-
[46]
How much can RAG help the reasoning of llm? CoRR, abs/2410.02338, 2024
How much can rag help the reasoning of llm? , author=. arXiv preprint arXiv:2410.02338 , year=
-
[47]
International Conference on Machine Learning , pages=
Large language models can be easily distracted by irrelevant context , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[48]
arXiv preprint arXiv:2405.20834 , year=
Retrieval meets reasoning: Even high-school textbook knowledge benefits multimodal reasoning , author=. arXiv preprint arXiv:2405.20834 , year=
-
[49]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Can we further elicit reasoning in llms? critic-guided planning with retrieval-augmentation for solving challenging tasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[51]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review arXiv
-
[52]
2023 , eprint=
Are Emergent Abilities of Large Language Models a Mirage? , author=. 2023 , eprint=
2023
-
[53]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[54]
2023 , eprint=
Teaching Small Language Models to Reason , author=. 2023 , eprint=
2023
-
[55]
2023 , eprint=
Large Language Models Are Reasoning Teachers , author=. 2023 , eprint=
2023
-
[56]
2024 , eprint=
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. 2024 , eprint=
2024
-
[57]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review arXiv
-
[58]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[59]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[60]
Paperqa: Retrieval-augmented generative agent for scientific research , author=. arXiv preprint arXiv:2312.07559 , year=
-
[61]
Scientific Reports , volume=
The sciqa scientific question answering benchmark for scholarly knowledge , author=. Scientific Reports , volume=. 2023 , publisher=
2023
-
[62]
arXiv preprint arXiv:2407.03203 , year=
Theoremllama: Transforming general-purpose llms into lean4 experts , author=. arXiv preprint arXiv:2407.03203 , year=
-
[63]
2025 , eprint=
A Survey on Large Language Models for Mathematical Reasoning , author=. 2025 , eprint=
2025
-
[64]
2025 , eprint=
OLMES: A Standard for Language Model Evaluations , author=. 2025 , eprint=
2025
-
[65]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[66]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. CoRR , volume =. 2021 , url =. 2103.03874 , timestamp =
work page internal anchor Pith review arXiv 2021
-
[67]
2024 , eprint=
Code Llama: Open Foundation Models for Code , author=. 2024 , eprint=
2024
-
[68]
Proceedings of the annual international acm sigir conference on research and development in information retrieval in the Asia Pacific region , pages=
Retrieving supporting evidence for generative question answering , author=. Proceedings of the annual international acm sigir conference on research and development in information retrieval in the Asia Pacific region , pages=
-
[69]
Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER) , pages=
Evidence-backed fact checking using RAG and few-shot in-context learning with LLMs , author=. Proceedings of the Seventh Fact Extraction and VERification Workshop (FEVER) , pages=
-
[70]
Machine Learning and Knowledge Extraction , volume=
Investigating the performance of retrieval-augmented generation and domain-specific fine-tuning for the development of AI-driven knowledge-based systems , author=. Machine Learning and Knowledge Extraction , volume=. 2025 , publisher=
2025
-
[71]
Transactions of the Association for Computational Linguistics , volume=
Improving the domain adaptation of retrieval augmented generation (RAG) models for open domain question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[72]
2025 , eprint=
MemR ^3 : Memory Retrieval via Reflective Reasoning for LLM Agents , author=. 2025 , eprint=
2025
-
[73]
ACM Computing Surveys , volume=
A survey on large language models for mathematical reasoning , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[74]
2025 , eprint=
ReasonIR: Training Retrievers for Reasoning Tasks , author=. 2025 , eprint=
2025
-
[75]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[76]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.