Recognition: unknown
ARGUS: Defending LLM Agents Against Context-Aware Prompt Injection
Pith reviewed 2026-05-07 15:55 UTC · model grok-4.3
The pith
ARGUS builds an influence provenance graph to defend LLM agents from context-aware prompt injection by verifying decisions against trusted evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARGUS enforces provenance-aware decision auditing for LLM agents by constructing an influence provenance graph that tracks propagation of untrusted context into agent decisions and verifies whether each decision is justified by trustworthy evidence before execution, reducing attack success rate to 3.8 percent while preserving 87.5 percent task utility and outperforming prior defenses against adaptive white-box adversaries.
What carries the argument
The influence provenance graph, which tracks how untrusted context propagates into agent decisions to support pre-execution verification against trustworthy evidence.
Load-bearing premise
An influence provenance graph can be constructed accurately enough to track untrusted context propagation into decisions, and verifying decisions against trustworthy evidence will prevent attacks in real dynamic agent workflows without introducing new vulnerabilities.
What would settle it
An experiment in which an adaptive adversary crafts a context-aware injection that evades the provenance graph construction or verification step, resulting in successful manipulation of agent behavior while the graph reports no untrusted influence.
Figures





read the original abstract
The rise of Large Language Model (LLM) agents, augmented with tool use, skills, and external knowledge, has introduced new security risks. Among them, prompt injection attacks, where adversaries embed malicious instructions into the agent workflow, have emerged as the primary threat. However, existing benchmarks and defenses are fundamentally limited as they assume context-insensitive settings in which the agent works under a fully specified user instruction, and the attacks are straightforward and context-independent. As a result, they fail to capture real-world deployments where agent behavior usually depends on dynamic context, not just the user prompt, and adversaries can adapt their attacks to different context. Similarly, existing defenses built on this narrow threat model overlook the nature of real-world agent delegation. In this paper, we present AgentLure, a benchmark that captures context-dependent tasks and context-aware prompt injection attacks. AgentLure spans four agentic domains and eight attack vectors across diverse attack surfaces. Our evaluation shows that existing defenses often struggle in this setting, yielding poor performance against such attacks in agentic systems. To address this limitation, we propose ARGUS, a defense mechanism that enforces provenance-aware decision auditing for LLM agents. ARGUS constructs an influence provenance graph to track how untrusted context propagates into agent decisions and verify whether a decision is justified by trustworthy evidence before execution. Our evaluation shows ARGUS reduces attack success rate to 3.8% while preserving 87.5% task utility, significantly outperforming existing defenses and remaining robust against adaptive white-box adversaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentLure, a benchmark spanning four agentic domains and eight context-aware prompt injection attack vectors, to expose limitations in existing defenses that assume static, context-insensitive settings. It then proposes ARGUS, which builds an influence provenance graph to track propagation of untrusted context through tool calls, memory, and LLM reasoning steps, followed by a verifier that only permits decisions justified by trustworthy evidence. The central empirical claim is that ARGUS reduces attack success rate to 3.8% while retaining 87.5% task utility, significantly outperforming prior defenses and remaining robust to adaptive white-box adversaries.
Significance. If the provenance-graph construction and verification steps can be shown to be accurate and non-circumventable under realistic adaptive attacks, ARGUS would represent a meaningful advance by shifting from heuristic filtering to explicit, auditable provenance tracking in dynamic LLM-agent workflows. The benchmark itself would also be useful for future work. The reported numbers, however, rest on the unproven assumption that the graph can be built reliably enough to block attacks without excessive false positives or new attack surfaces.
major comments (3)
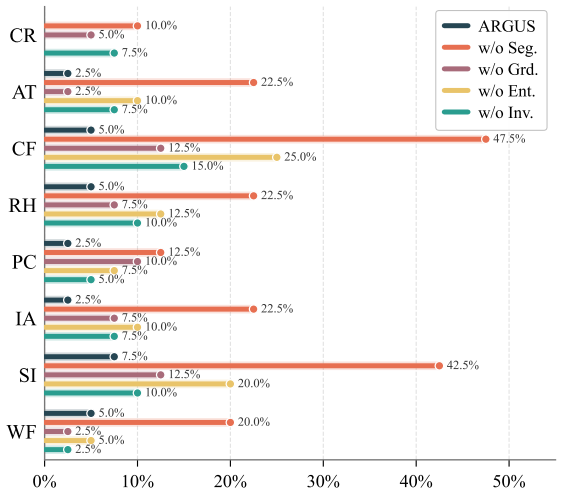
- [§4] §4 (ARGUS construction): The description of how the influence provenance graph is populated lacks concrete rules for edge addition, conflict resolution, and attribution when the LLM performs summarization, tool invocation, or memory updates. If edge labeling depends on LLM-mediated decisions or heuristics, an adaptive adversary can target precisely those steps to create spurious trustworthy edges or suppress malicious influence, directly undermining the 3.8% ASR claim.
- [Evaluation] Evaluation section (white-box adaptive adversary experiments): The robustness claim requires explicit specification of the adversary's knowledge of the provenance rules and verifier logic, plus the exact adaptation strategy used. Without this, it is impossible to determine whether the reported performance holds when the attacker can craft context that exploits inaccuracies in graph construction.
- [Evaluation] Experimental results (tables reporting 3.8% ASR and 87.5% utility): These headline figures are presented without statistical significance tests, confidence intervals, or ablation on the provenance-graph accuracy itself. If graph construction error rates are non-negligible, the utility-ASR tradeoff may not generalize beyond the specific AgentLure tasks.
minor comments (2)
- [Abstract / §2] The abstract and introduction use the term 'influence provenance graph' without an early formal definition or diagram; a small illustrative example in §2 or §3 would improve readability.
- [§4] Notation for trustworthy vs. untrusted nodes/edges is introduced inconsistently across sections; a single table of symbols would help.
Simulated Author's Rebuttal
We thank the referee for their insightful review and constructive suggestions. We have revised the manuscript to address the concerns raised regarding the clarity of ARGUS construction, the specification of adaptive adversary experiments, and the statistical rigor of the results. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [§4] §4 (ARGUS construction): The description of how the influence provenance graph is populated lacks concrete rules for edge addition, conflict resolution, and attribution when the LLM performs summarization, tool invocation, or memory updates. If edge labeling depends on LLM-mediated decisions or heuristics, an adaptive adversary can target precisely those steps to create spurious trustworthy edges or suppress malicious influence, directly undermining the 3.8% ASR claim.
Authors: We appreciate the referee highlighting the need for greater precision in §4. The original manuscript described the high-level mechanism for building the influence provenance graph via information flow tracking during tool calls, memory updates, and reasoning steps, but we agree that explicit rules for edge addition (e.g., during LLM summarization of context), conflict resolution (e.g., when multiple sources influence a single decision), and attribution were insufficiently detailed. In the revised manuscript, we have expanded §4 with a new subsection containing concrete rules, including pseudocode for graph population and worked examples for summarization, tool invocation, and memory updates. While we acknowledge that LLM-mediated labeling introduces potential attack surfaces, the verifier operates independently by requiring decisions to be justified solely by trustworthy evidence; our white-box experiments (now detailed further) show that attempts to inject spurious edges do not materially increase ASR beyond the reported 3.8%. revision: yes
-
Referee: [Evaluation] Evaluation section (white-box adaptive adversary experiments): The robustness claim requires explicit specification of the adversary's knowledge of the provenance rules and verifier logic, plus the exact adaptation strategy used. Without this, it is impossible to determine whether the reported performance holds when the attacker can craft context that exploits inaccuracies in graph construction.
Authors: We agree that the white-box adaptive adversary experiments require explicit specification to allow proper evaluation of the robustness claim. In the revised Evaluation section, we now clearly state that the adversary is assumed to have full knowledge of the provenance graph construction rules, the verifier logic, and the AgentLure benchmark details. We also describe the exact adaptation strategies tested: (1) crafting context to induce spurious trustworthy edges by replicating patterns from verified sources, (2) using summarization to suppress or dilute malicious influence, and (3) targeting memory updates to create attribution conflicts. The results under these strategies remain consistent with the headline figures (ASR ≤ 5%), indicating that graph construction inaccuracies do not provide an effective bypass under the evaluated conditions. revision: yes
-
Referee: [Evaluation] Experimental results (tables reporting 3.8% ASR and 87.5% utility): These headline figures are presented without statistical significance tests, confidence intervals, or ablation on the provenance-graph accuracy itself. If graph construction error rates are non-negligible, the utility-ASR tradeoff may not generalize beyond the specific AgentLure tasks.
Authors: We thank the referee for noting the gaps in experimental reporting. The original tables reported averages over multiple runs of AgentLure, but we acknowledge the lack of statistical tests, confidence intervals, and ablations on graph accuracy. In the revised manuscript, we have augmented the Evaluation section and tables with: (1) 95% confidence intervals computed via bootstrapping, (2) paired t-test p-values comparing ARGUS against baselines, and (3) a new ablation study that injects controlled graph construction errors (5–20% edge misattribution rates) and measures the resulting impact on ASR and task utility. The ablation shows that the utility-ASR tradeoff remains favorable relative to prior defenses even under moderate graph errors, supporting generalizability beyond the specific AgentLure tasks. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces AgentLure as a new benchmark for context-aware attacks and ARGUS as a defense that constructs an influence provenance graph to track context propagation and verify decisions against trustworthy evidence. Performance numbers (ASR 3.8%, 87.5% utility) are presented as outcomes of empirical evaluation on the benchmark against existing defenses and adaptive adversaries. No equations, definitions, or load-bearing steps are shown to reduce by construction to fitted inputs, self-citations, or renamed prior results. The central claims rest on the described construction and reported test results rather than self-referential premises, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agent behavior depends on dynamic context that can be influenced by untrusted external sources.
- domain assumption An influence provenance graph can be built to track propagation of untrusted context into decisions.
invented entities (1)
-
influence provenance graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , institution=
AI agents for cash management in payment systems , author=. 2025 , institution=
2025
-
[2]
Nejm Ai , volume=
MedAgentBench: a virtual EHR environment to benchmark medical LLM agents , author=. Nejm Ai , volume=. 2025 , publisher=
2025
-
[3]
Proceedings of the IEEE , volume=
The protection of information in computer systems , author=. Proceedings of the IEEE , volume=. 1975 , publisher=
1975
-
[4]
GPT-4o mini: advancing cost-efficient intelligence , year =
-
[5]
Advances in Neural Information Processing Systems , volume=
Stackeval: Benchmarking llms in coding assistance , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
GPT-4.1 mini Model , year =
-
[7]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
2023 , month = apr, day =
Willison, Simon , title =. 2023 , month = apr, day =
2023
-
[9]
, author=
Dynamic taint analysis for automatic detection, analysis, and signaturegeneration of exploits on commodity software. , author=. NDSS , volume=
-
[10]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents , author=. arXiv preprint arXiv:2410.02644 , year=
work page internal anchor Pith review arXiv
-
[11]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[12]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Benchmarking and defending against indirect prompt injection attacks on large language models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[13]
33rd USENIX Security Symposium (USENIX Security 24) , pages=
Formalizing and benchmarking prompt injection attacks and defenses , author=. 33rd USENIX Security Symposium (USENIX Security 24) , pages=
-
[14]
arXiv e-prints , pages=
A practical memory injection attack against llm agents , author=. arXiv e-prints , pages=
-
[15]
Science China Information Sciences , volume=
The rise and potential of large language model based agents: A survey , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[16]
The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis , author=. arXiv preprint arXiv:2602.10453 , year=
-
[17]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
The instruction hierarchy: Training llms to prioritize privileged instructions , author=. arXiv preprint arXiv:2404.13208 , year=
work page internal anchor Pith review arXiv
-
[18]
34th USENIX Security Symposium (USENIX Security 25) , pages=
\ StruQ \ : Defending against prompt injection with structured queries , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[19]
Drift: Dynamic rule-based defense with injection isolation for securing llm agents , author=. arXiv preprint arXiv:2506.12104 , year=
-
[20]
ACE: A Security Architecture for LLM-Integrated App Systems
Ace: A security architecture for llm-integrated app systems , author=. arXiv preprint arXiv:2504.20984 , year=
-
[21]
Melon: Provable defense against indirect prompt injection attacks in ai agents , author=. arXiv preprint arXiv:2502.05174 , year=
-
[22]
arXiv preprint arXiv:2410.22770 , year=
Injecguard: Benchmarking and mitigating over-defense in prompt injection guardrail models , author=. arXiv preprint arXiv:2410.22770 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection , author=. Proceedings of the 16th ACM workshop on artificial intelligence and security , pages=
-
[25]
Patricia S. Abril and Robert Plant. The patent holder's dilemma: Buy, sell, or troll?. Communications of the ACM. 2007. doi:10.1145/1188913.1188915
-
[26]
Deciding equivalances among conjunctive aggregate queries
Sarah Cohen and Werner Nutt and Yehoshua Sagic. Deciding equivalances among conjunctive aggregate queries. doi:10.1145/1219092.1219093
-
[27]
Special issue: Digital Libraries. 1996
1996
-
[28]
Understanding Policy-Based Networking
David Kosiur. Understanding Policy-Based Networking. 2001
2001
-
[31]
The title of book two. 2008. doi:10.1007/3-540-09237-4
-
[32]
Asad Z. Spector. Achieving application requirements. Distributed Systems. 1990. doi:10.1145/90417.90738
-
[33]
Douglass and David Harel and Mark B
Bruce P. Douglass and David Harel and Mark B. Trakhtenbrot. Statecarts in use: structured analysis and object-orientation. Lectures on Embedded Systems. 1998. doi:10.1007/3-540-65193-4_29
-
[34]
Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms (3rd. ed.). 1997
1997
-
[35]
Donald E. Knuth. The Art of Computer Programming. 1998
1998
-
[36]
Structured Variational Inference Procedures and their Realizations (as incol)
Dan Geiger and Christopher Meek. Structured Variational Inference Procedures and their Realizations (as incol). Proceedings of Tenth International Workshop on Artificial Intelligence and Statistics, The Barbados
-
[37]
Stan W. Smith. An experiment in bibliographic mark-up: Parsing metadata for XML export. Proceedings of the 3rd. annual workshop on Librarians and Computers. 2010. doi:99.9999/woot07-S422
2010
-
[38]
Catch me, if you can: Evading network signatures with web-based polymorphic worms
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna. Catch me, if you can: Evading network signatures with web-based polymorphic worms. Proceedings of the first USENIX workshop on Offensive Technologies
-
[39]
Sten Andler. Predicate Path expressions. Proceedings of the 6th. ACM SIGACT-SIGPLAN symposium on Principles of Programming Languages. 1979. doi:10.1145/567752.567774
-
[40]
LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER
David Harel. LOGICS of Programs: AXIOMATICS and DESCRIPTIVE POWER. 1978
1978
-
[41]
Anisi , title =
David A. Anisi , title =
-
[42]
Clarkson
Kenneth L. Clarkson. Algorithms for Closest-Point Problems (Computational Geometry). 1985
1985
-
[43]
Introduction to Bayesian Statistics
Harry Thornburg. Introduction to Bayesian Statistics. 2001
2001
-
[44]
CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11
Rafal Ablamowicz and Bertfried Fauser. CLIFFORD: a Maple 11 Package for Clifford Algebra Computations, version 11. 2007
2007
-
[45]
Stats and Analysis
Poker-Edge.Com. Stats and Analysis. 2006
2006
-
[46]
A more perfect union
Barack Obama. A more perfect union. 2008
2008
-
[47]
The fountain of youth
Joseph Scientist. The fountain of youth. 2009
2009
-
[48]
Solder man
Dave Novak. Solder man. ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol. 145 (July 27--27, 2003). 2003. doi:99.9999/woot07-S422
2003
-
[49]
Interview with Bill Kinder: January 13, 2005
Newton Lee. Interview with Bill Kinder: January 13, 2005. Comput. Entertain. 2005. doi:10.1145/1057270.1057278
-
[50]
The Enabling of Digital Libraries
Bernard Rous. The Enabling of Digital Libraries. Digital Libraries. 2008
2008
-
[52]
(new) Finding minimum congestion spanning trees , journal =
Werneck, Renato and Setubal, Jo\. (new) Finding minimum congestion spanning trees , journal =. doi:10.1145/351827.384253 , acmid = 384253, publisher =
-
[54]
Conti, Mauro and Di Pietro, Roberto and Mancini, Luigi V. and Mei, Alessandro , title =. Inf. Fusion , volume =. 2009 , issn =. doi:10.1016/j.inffus.2009.01.002 , acmid =
-
[55]
Li, Cheng-Lun and Buyuktur, Ayse G. and Hutchful, David K. and Sant, Natasha B. and Nainwal, Satyendra K. , title =. CHI '08 extended abstracts on Human factors in computing systems , year =. doi:10.1145/1358628.1358946 , acmid =
-
[56]
, title =
Hollis, Billy S. , title =. 1999 , isbn =
1999
-
[57]
Goossens, Michel and Rahtz, S. P. and Moore, Ross and Sutor, Robert S. , title =. 1999 , isbn =
1999
-
[58]
and Rosenberg, Arnold L
Buss, Jonathan F. and Rosenberg, Arnold L. and Knott, Judson D. , title =. 1987 , source =
1987
-
[59]
CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
, note =. CHI '08: CHI '08 extended abstracts on Human factors in computing systems , year =
-
[60]
Algorithms for Closest-Point Problems (Computational Geometry) , year =
Clarkson, Kenneth Lee , advisor =. Algorithms for Closest-Point Problems (Computational Geometry) , year =
-
[61]
SIGCOMM Comput. Commun. Rev. , year =
-
[62]
IEEE TCSC Executive Committee , booktitle =. 2004 , isbn =. doi:http://dx.doi.org/10.1109/ICWS.2004.64 , acmid =
-
[63]
Distributed systems (2nd Ed.) , year =
-
[64]
, title =
Petrie, Charles J. , title =. 1986 , source =
1986
-
[65]
Donald E. Knuth. Seminumerical Algorithms. 1981
1981
-
[66]
E-commerce and cultural values , year =
Kong, Wei-Chang , Title =. E-commerce and cultural values , year =
-
[67]
E-commerce and cultural values , year =
Kong, Wei-Chang , type =. E-commerce and cultural values , year =
-
[68]
Chapter 9 , booktitle =
Kong, Wei-Chang , editor =. Chapter 9 , booktitle =. 2002 , address =
2002
-
[69]
E-commerce and cultural values , editor =
Kong, Wei-Chang , title =. E-commerce and cultural values , editor =. 2003 , isbn =
2003
-
[70]
E-commerce and cultural values - (InBook-num-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values - (InBook-num-in-chap) , chapter =. 2004 , address =
2004
-
[71]
E-commerce and cultural values (Inbook-text-in-chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-text-in-chap) , chapter =. 2005 , address =
2005
-
[72]
E-commerce and cultural values (Inbook-num chap) , chapter =
Kong, Wei-Chang , editor =. E-commerce and cultural values (Inbook-num chap) , chapter =. 2006 , address =
2006
-
[73]
Microelectron
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi , title =. Microelectron. J. , volume =. 2010 , pages =
2010
-
[74]
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi and Zahra Sasanian , title =. J. Emerg. Technol. Comput. Syst. , volume =
-
[75]
Kirschmer, Markus and Voight, John , title =. SIAM J. Comput. , issue_date =. 2010 , issn =. doi:https://doi.org/10.1137/080734467 , acmid =
-
[76]
Hoare, C. A. R. , title =. Structured programming (incoll) , editor =. 1972 , isbn =
1972
-
[77]
History of programming languages I (incoll) , editor =
Lee, Jan , title =. History of programming languages I (incoll) , editor =. 1981 , isbn =. doi:http://doi.acm.org/10.1145/800025.1198348 , acmid =
-
[78]
, title =
Dijkstra, E. , title =. Classics in software engineering (incoll) , year =
-
[79]
Wenzel, Elizabeth M. , title =. Multimedia interface design (incoll) , year =. doi:10.1145/146022.146089 , acmid =
-
[80]
, title =
Mumford, E. , title =. Critical issues in information systems research (incoll) , year =
-
[81]
and Golden, Donald G
McCracken, Daniel D. and Golden, Donald G. , title =. 1990 , isbn =
1990
-
[82]
The analysis of linear partial differential operators
H. The analysis of linear partial differential operators. 1985 , PAGES =
1985
-
[83]
IEEE", address =
A. Adya and P. Bahl and J. Padhye and A.Wolman and L. Zhou , title =. Proceedings of the IEEE 1st International Conference on Broadnets Networks (BroadNets'04) , publisher = "IEEE", address = "Los Alamitos, CA", year =
-
[84]
I. F. Akyildiz and W. Su and Y. Sankarasubramaniam and E. Cayirci , title =. Comm. ACM , volume = 38, number = "4", year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.