Recognition: unknown
Enhancing Self-Supervised Talking Head Forgery Detection via a Training-Free Dual-System Framework
Pith reviewed 2026-05-08 01:19 UTC · model grok-4.3
The pith
Existing self-supervised talking head forgery detectors can be improved without training by using a dual-system framework that refines anomaly scores on uncertain samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
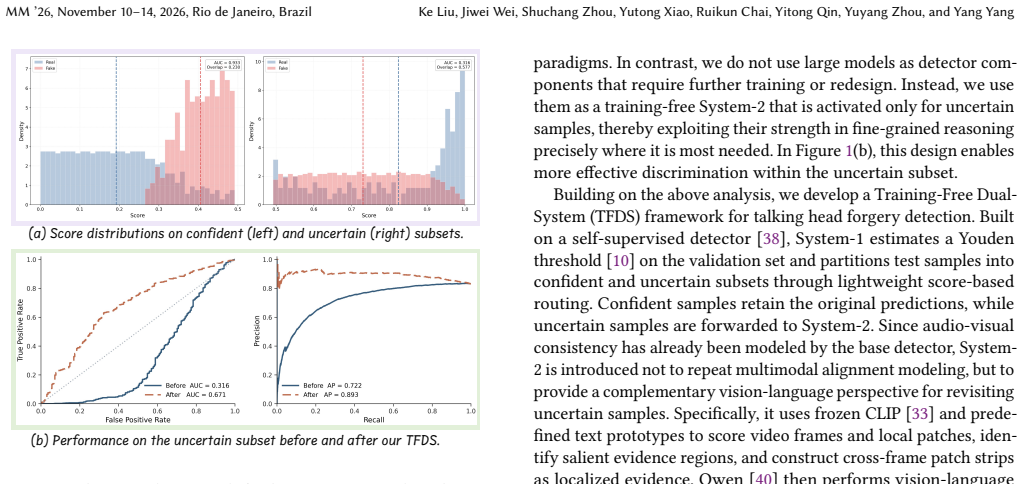
By modeling anomaly-like scores as the fast System-1 and restricting fine-grained evidence-guided reasoning to the uncertain subset identified by threshold routing, the Training-Free Dual-System framework refines the relative ordering of ambiguous samples, yielding consistent gains in forgery detection metrics that stem primarily from improved discrimination within the hard cases.
What carries the argument
The TFDS framework's threshold-based routing that partitions inputs into confident and uncertain subsets based on anomaly scores, combined with evidence-guided reasoning applied only to the uncertain subset to adjust their ordering.
If this is right
- Consistent improvements in detection performance across multiple datasets and perturbation settings.
- The performance gains come mainly from corrected ordering of samples in the uncertain subset.
- Existing self-supervised detectors contain underexploited discriminative cues that training-free methods can access.
- Reducing reliance on generator-specific patterns while enhancing discriminative capacity on ambiguous cases.
Where Pith is reading between the lines
- This method could be tested on other self-supervised anomaly detection tasks in video or image forensics to see if similar gains occur.
- Future work might explore combining the dual-system with other post-hoc techniques to further exploit model capacities.
- The routing thresholds might need tuning per detector, suggesting a direction for adaptive variants without full retraining.
Load-bearing premise
The anomaly scores from existing self-supervised detectors are reliable enough to accurately partition samples into confident and uncertain subsets, allowing the evidence-guided reasoning to improve ordering without adding errors.
What would settle it
Applying the TFDS framework to several self-supervised talking head forgery detectors and finding no measurable increase in detection accuracy or AUC, particularly no improvement in the ranking of uncertain samples.
Figures




read the original abstract
Supervised talking head forgery detection faces severe generalization challenges due to the continuous evolution of generators. By reducing reliance on generator-specific forgery patterns, self-supervised detectors offer stronger cross-generator robustness. However, existing research has mainly focused on building stronger detectors, while the discriminative capacity of trained detectors remains insufficiently exploited. In particular, for score-based self-supervised detectors, the limited discriminative ability on hard cases is often reflected in unreliable anomaly ordering, leaving room for further refinement. Motivated by this observation, we draw inspiration from the dual-system theory of human cognition and propose a Training-Free Dual-System (TFDS) framework to further exploit the latent discriminative capacity of existing score-based self-supervised detectors. TFDS treats anomaly-like scores as the basis of System-1, using lightweight threshold-based routing to partition samples into confident and uncertain subsets. System-2 then revisits only the uncertain subset, performing fine-grained evidence-guided reasoning to refine the relative ordering of ambiguous samples within the original score distribution. Extensive experiments demonstrate consistent improvements across datasets and perturbation settings, with the gains arising mainly from corrected ordering within the uncertain subset. These findings show that existing self-supervised talking head forgery detectors still contain underexploited discriminative cues that can be effectively unlocked through training-free dual-system reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Training-Free Dual-System (TFDS) framework for self-supervised talking head forgery detection. It treats anomaly-like scores from existing detectors as System-1, applies lightweight threshold-based routing to split samples into confident and uncertain subsets, and uses System-2 for evidence-guided reasoning only on the uncertain subset to refine relative ordering within the original score distribution. The central claim is that this unlocks latent discriminative capacity in pre-trained detectors, yielding consistent improvements across datasets and perturbations without any training or fine-tuning, with gains attributed primarily to corrected ordering on ambiguous samples.
Significance. If validated with detailed evidence, the result would show that existing score-based self-supervised detectors retain underexploited cues that can be accessed via a simple, training-free dual-process mechanism. This is a practical strength for cross-generator robustness in forgery detection, as it avoids the need for new labeled data or retraining while targeting the known weakness on hard cases. The training-free nature and focus on refining uncertain samples are positive features that could be adopted as a post-processing step for other anomaly-based detectors.
major comments (2)
- [Abstract] Abstract: The abstract asserts 'consistent improvements across datasets and perturbation settings' and states that 'gains arising mainly from corrected ordering within the uncertain subset,' yet supplies no quantitative metrics, ablation results, or implementation details for the evidence-guided reasoning step in System-2. This omission prevents verification that the data support the central claim that improvements are due to the proposed routing and refinement mechanism rather than other factors.
- [Abstract] The framework description (abstract and §3 implied): The routing step assumes anomaly-like scores from self-supervised detectors are sufficiently reliable to partition samples via a lightweight threshold into confident vs. uncertain subsets. However, the abstract itself notes that 'limited discriminative ability on hard cases is often reflected in unreliable anomaly ordering,' which creates a direct risk that hard samples are misrouted, either bypassing refinement or receiving it inappropriately; this threatens attribution of any observed gains to the dual-system design.
minor comments (2)
- The single free parameter (routing threshold) is noted but its selection procedure and sensitivity analysis are not described, which would aid reproducibility.
- Clarify the precise form of 'evidence-guided reasoning' in System-2 (e.g., what constitutes evidence and how it adjusts the original scores) to make the method fully reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, offering clarifications based on the content of the full paper and indicating revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts 'consistent improvements across datasets and perturbation settings' and states that 'gains arising mainly from corrected ordering within the uncertain subset,' yet supplies no quantitative metrics, ablation results, or implementation details for the evidence-guided reasoning step in System-2. This omission prevents verification that the data support the central claim that improvements are due to the proposed routing and refinement mechanism rather than other factors.
Authors: We acknowledge that the abstract's brevity precludes inclusion of specific metrics or implementation details. The full manuscript (Sections 4 and 5) provides these elements, including quantitative AUC improvements across multiple datasets and perturbation settings, along with ablations isolating the contribution of the evidence-guided reasoning in System-2. To improve verifiability directly from the abstract, we will revise it to incorporate concise references to the key performance gains and a high-level description of the System-2 reasoning step. revision: yes
-
Referee: [Abstract] The framework description (abstract and §3 implied): The routing step assumes anomaly-like scores from self-supervised detectors are sufficiently reliable to partition samples via a lightweight threshold into confident vs. uncertain subsets. However, the abstract itself notes that 'limited discriminative ability on hard cases is often reflected in unreliable anomaly ordering,' which creates a direct risk that hard samples are misrouted, either bypassing refinement or receiving it inappropriately; this threatens attribution of any observed gains to the dual-system design.
Authors: We appreciate this observation on the potential for routing errors. The framework intentionally routes based on score extremity to flag ambiguous cases for refinement, recognizing that extreme scores tend to be more reliable while mid-range scores indicate uncertainty. The paper's experiments (Section 4) show that observed gains are localized to the uncertain subset after refinement, supporting attribution to the dual-system approach rather than artifacts of routing. We will add a dedicated discussion paragraph in Section 3 to explicitly analyze routing robustness and the impact of potential misrouting on overall performance. revision: partial
Circularity Check
No circularity: training-free post-processing on external detector scores
full rationale
The TFDS framework applies threshold routing and evidence-guided reordering to anomaly scores produced by pre-existing self-supervised detectors. No parameters are fitted to the evaluation data, no equations reduce the output ordering to the input scores by algebraic identity, and no load-bearing premise rests on self-citation of the authors' prior uniqueness results. The derivation chain consists of an external cognitive analogy plus lightweight heuristics whose correctness is tested empirically rather than assumed by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- routing threshold
axioms (1)
- domain assumption Anomaly-like scores from self-supervised detectors provide a usable basis for initial confident/uncertain partitioning.
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
- [2]
-
[3]
Hejia Chen, Haoxian Zhang, Shoulong Zhang, Xiaoqiang Liu, Sisi Zhuang, Pengfei Wan, Di ZHANG, Shuai Li, et al. 2025. Cafe-Talk: Generating 3D Talk- ing Face Animation with Multimodal Coarse-and Fine-grained Control. InThe Thirteenth International Conference on Learning Representations
2025
- [4]
-
[5]
Komal Chugh, Parul Gupta, Abhinav Dhall, and Ramanathan Subramanian. 2020. Not made for each other-audio-visual dissonance-based deepfake detection and localization. InProceedings of the 28th ACM international conference on multimedia. 439–447
2020
-
[6]
Davide Alessandro Coccomini, Nicola Messina, Claudio Gennaro, and Fabrizio Falchi. 2022. Combining efficientnet and vision transformers for video deepfake detection. InInternational conference on image analysis and processing. Springer, 219–229
2022
-
[7]
Davide Cozzolino, Giovanni Poggi, Matthias Nießner, and Luisa Verdoliva. 2024. Zero-shot detection of ai-generated images. InEuropean conference on computer vision. Springer, 54–72
2024
-
[8]
Biao Dong and Lei Zhang. 2025. Talking Head Generation via Viewpoint and Lighting Simulation Based on Global Representation. InProceedings of the 33rd ACM International Conference on Multimedia. 10258–10267
2025
-
[9]
Chao Feng, Ziyang Chen, and Andrew Owens. 2023. Self-supervised video forensics by audio-visual anomaly detection. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10491–10503
2023
-
[10]
Ronen Fluss, David Faraggi, and Benjamin Reiser. 2005. Estimation of the Youden Index and its associated cutoff point.Biometrical Journal: Journal of Mathematical Methods in Biosciences47, 4 (2005), 458–472
2005
-
[11]
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. 2024. Clip-adapter: Better vision-language models with feature adapters.International journal of computer vision132, 2 (2024), 581–595
2024
-
[12]
Hao Gu, Jiangyan Yi, Chenglong Wang, Jianhua Tao, Zheng Lian, Jiayi He, Yong Ren, Yujie Chen, and Zhengqi Wen. 2025. Allm4add: Unlocking the capabilities of audio large language models for audio deepfake detection. InProceedings of the 33rd ACM International Conference on Multimedia. 11736–11745
2025
-
[13]
Midou Guo, Qilin Yin, Wei Lu, and Xiangyang Luo. 2025. Towards open-world generalized deepfake detection: General feature extraction via unsupervised domain adaptation. InProceedings of the 33rd ACM International Conference on Multimedia. 11572–11580
2025
-
[14]
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. 2022. Leveraging real talking faces via self-supervision for robust forgery detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14950–14962
2022
- [15]
-
[16]
Baojin Huang, Zhongyuan Wang, Jifan Yang, Jiaxin Ai, Qin Zou, Qian Wang, and Dengpan Ye. 2023. Implicit identity driven deepfake face swapping detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4490–4499
2023
-
[17]
Zhenglin Huang, Jinwei Hu, Xiangtai Li, Yiwei He, Xingyu Zhao, Bei Peng, Baoyuan Wu, Xiaowei Huang, and Guangliang Cheng. 2025. Sida: Social media image deepfake detection, localization and explanation with large multimodal model. InProceedings of the Computer Vision and Pattern Recognition Conference. 28831–28841
2025
-
[18]
Adilbek Karmanov, Dayan Guan, Shijian Lu, Abdulmotaleb El Saddik, and Eric Xing. 2024. Efficient test-time adaptation of vision-language models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14162–14171
2024
- [19]
-
[20]
Ivan Kukanov and Jun Wah Ng. 2025. KLASSify to Verify: Audio-Visual Deepfake Detection Using SSL-based Audio and Handcrafted Visual Features. InProceedings of the 33rd ACM International Conference on Multimedia. 13707–13713
2025
-
[21]
Jinyuan Li, Han Li, Di Sun, Jiahao Wang, Wenkun Zhang, Zan Wang, and Gang Pan. 2024. LLMs as bridges: Reformulating grounded multimodal named entity recognition. InFindings of the Association for Computational Linguistics: ACL
2024
- [22]
-
[23]
Weifeng Liu, Tianyi She, Jiawei Liu, Boheng Li, Dongyu Yao, and Run Wang. 2024. Lips are lying: Spotting the temporal inconsistency between audio and visual in lip-syncing deepfakes.Advances in Neural Information Processing Systems37 (2024), 91131–91155
2024
-
[24]
Yang Liu, Zhaoyang Xia, Mengyang Zhao, Donglai Wei, Yuzheng Wang, Siao Liu, Bobo Ju, Gaoyun Fang, Jing Liu, and Liang Song. 2023. Learning causality- inspired representation consistency for video anomaly detection. InProceedings of the 31st ACM international conference on multimedia. 203–212
2023
- [25]
-
[26]
Trisha Mittal, Uttaran Bhattacharya, Rohan Chandra, Aniket Bera, and Dinesh Manocha. 2020. Emotions don’t lie: An audio-visual deepfake detection method using affective cues. InProceedings of the 28th ACM international conference on multimedia. 2823–2832
2020
-
[27]
Changdae Oh, Zhen Fang, Shawn Im, Xuefeng Du, and Yixuan Li. 2025. Under- standing Multimodal LLMs Under Distribution Shifts: An Information-Theoretic Approach. InInternational Conference on Machine Learning. PMLR, 46943–46970
2025
-
[28]
Ziqiao Peng, Wentao Hu, Yue Shi, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Jun He, Hongyan Liu, and Zhaoxin Fan. 2024. Synctalk: The devil is in the synchro- nization for talking head synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 666–676
2024
-
[29]
Sarah Pratt, Ian Covert, Rosanne Liu, and Ali Farhadi. 2023. What does a platypus look like? generating customized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF international conference on computer vision. 15691– 15701
2023
- [30]
-
[31]
Xiangyan Qu, Gaopeng Gou, Jiamin Zhuang, Jing Yu, Kun Song, Qihao Wang, Yili Li, and Gang Xiong. 2025. Proapo: Progressively automatic prompt optimiza- tion for visual classification. InProceedings of the Computer Vision and Pattern Recognition Conference. 25145–25155
2025
-
[32]
Yassine Rachidy, Youssef Hmamouche, Faissal Sehbaoui, and Amal El Fallah Seghrouchni. 2025. Domain Adaptive Document Reranking for Retrieval Aug- mented Generation. In2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 1381–1387
2025
-
[33]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763. MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Ke Liu,...
2021
-
[34]
Zhiyuan Ren, Yiyang Su, and Xiaoming Liu. 2023. ChatGPT-powered hierarchical comparisons for image classification.Advances in neural information processing systems36 (2023), 69706–69718
2023
-
[35]
Jonas Ricker, Denis Lukovnikov, and Asja Fischer. 2024. Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9130–9140
2024
-
[36]
Katharine Sanderson. 2023. GPT-4 is here: what scientists think.Nature615, 7954 (2023), 773
2023
- [37]
-
[38]
Stefan Smeu, Dragos-Alexandru Boldisor, Dan Oneata, and Elisabeta Oneata. 2025. Circumventing shortcuts in audio-visual deepfake detection datasets with unsu- pervised learning. InProceedings of the Computer Vision and Pattern Recognition Conference. 18815–18825
2025
- [39]
-
[40]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review arXiv 2024
-
[41]
Tianyi Wang, Mengxiao Huang, Harry Cheng, Xiao Zhang, and Zhiqi Shen
-
[42]
InProceedings of the 32nd ACM International Conference on Multimedia
Lampmark: Proactive deepfake detection via training-free landmark per- ceptual watermarks. InProceedings of the 32nd ACM International Conference on Multimedia. 10515–10524
-
[43]
Jiwei Wei, Yang Yang, Xing Xu, Jingkuan Song, Guoqing Wang, and Heng Tao Shen. 2023. Less is better: Exponential loss for cross-modal matching.IEEE Transactions on Circuits and Systems for Video Technology33, 9 (2023), 5271–5280
2023
- [44]
-
[45]
Xinqi Xiong, Prakrut Patel, Qingyuan Fan, Amisha Wadhwa, Sarathy Selvam, Xiao Guo, Luchao Qi, Xiaoming Liu, and Roni Sengupta. 2026. Talkingheadbench: A multi-modal benchmark & analysis of talking-head deepfake detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 4139–4149
2026
-
[46]
Wenyuan Yang, Xiaoyu Zhou, Zhikai Chen, Bofei Guo, Zhongjie Ba, Zhihua Xia, Xiaochun Cao, and Kui Ren. 2023. Avoid-df: Audio-visual joint learning for detecting deepfake.IEEE Transactions on Information Forensics and Security18 (2023), 2015–2029
2023
-
[47]
Yutong Yang, Lifu Huang, Yijie Lin, Xi Peng, and Mouxing Yang. 2026. Endowing Vision-Language Models with System 2 Thinking for Fine-grained Visual Recog- nition. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 11802–11810
2026
-
[48]
Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, et al. 2024. Gaussiantalker: Speaker-specific talking head synthesis via 3d gaussian splatting. InProceedings of the 32nd ACM International Conference on Multimedia. 3548–3557
2024
-
[49]
Peipeng Yu, Jianwei Fei, Hui Gao, Xuan Feng, Zhihua Xia, and Chip Hong Chang
- [50]
-
[51]
Zhaoyang Zeng, Daniel McDuff, Yale Song, et al. 2021. Contrastive learning of global and local video representations.Advances in Neural Information Processing Systems34 (2021), 7025–7040
2021
-
[52]
Duzhen Zhang, Zhong-Zhi Li, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Xiuyi Chen, Yingying Zhang, et al. 2025. From system 1 to system 2: a survey of reasoning large language models.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
-
[53]
Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. 2022. Tip-adapter: Training-free adaption of clip for few-shot classification. InEuropean conference on computer vision. Springer, 493–510
2022
-
[54]
Yabin Zhang, Wenjie Zhu, Hui Tang, Zhiyuan Ma, Kaiyang Zhou, and Lei Zhang
-
[55]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dual memory networks: A versatile adaptation approach for vision- language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 28718–28728
-
[56]
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. 2021. Ex- ploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF international conference on computer vision. 15044– 15054
2021
-
[57]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2022. Learning to prompt for vision-language models.International journal of computer vision 130, 9 (2022), 2337–2348
2022
-
[58]
Yipin Zhou and Ser-Nam Lim. 2021. Joint audio-visual deepfake detection. In Proceedings of the IEEE/CVF international conference on computer vision. 14800– 14809
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.