Recognition: unknown
FUS3DMaps: Scalable and Accurate Open-Vocabulary Semantic Mapping by 3D Fusion of Voxel- and Instance-Level Layers
Pith reviewed 2026-05-07 15:42 UTC · model grok-4.3
The pith
Fusing semantic embeddings from dense and instance layers at the voxel level improves accuracy of both and enables scalable 3D mapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that maintaining dense and instance-level open-vocabulary layers in a shared voxel map and performing voxel-level semantic fusion of their embeddings improves the quality of both layers. This same design permits restricting the dense layer and cross-layer fusion to a spatial sliding window, thereby producing a scalable yet highly accurate instance-level map suitable for large environments.
What carries the argument
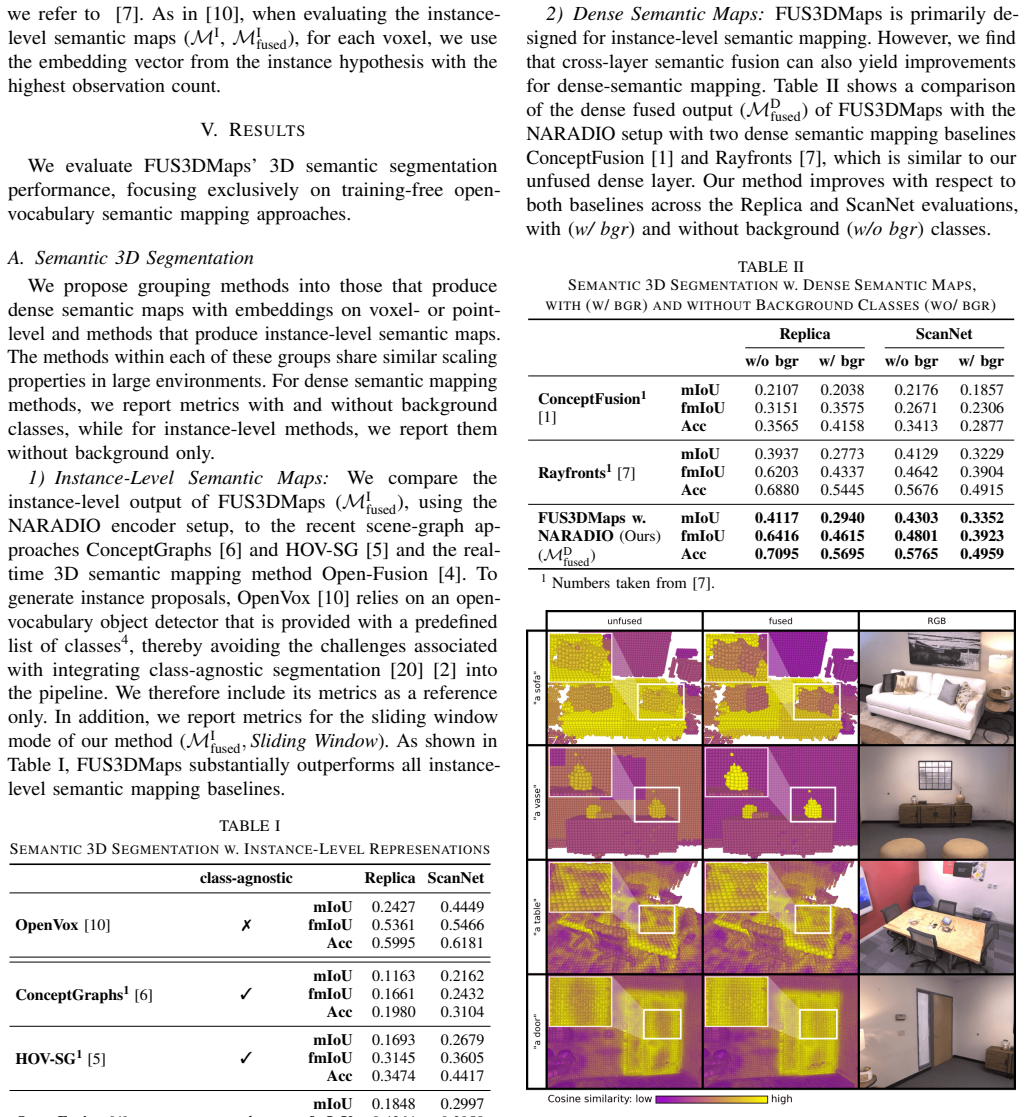
The semantic cross-layer fusion mechanism that combines embeddings from the dense voxel projections and the instance-level encodings at each voxel to refine the overall semantic representation.
If this is right
- The accuracy of the dense semantic layer increases because it receives corrective signals from the instance layer.
- The instance-level map gains precision from the dense layer's broader context while remaining computationally light through windowing.
- Open-vocabulary semantic mapping becomes feasible online at the scale of multi-story buildings without predefined object classes.
- Robots can query the map for arbitrary concepts using either dense or instance representations.
Where Pith is reading between the lines
- This layered fusion idea might apply to other perception tasks where dense and sparse representations can be aligned in 3D space.
- Future work could test whether the same fusion improves performance when the input comes from different sensors or under changing lighting.
- Navigation or manipulation tasks that rely on semantic grounding would likely benefit from the higher label consistency the method produces.
Load-bearing premise
The assumption that combining the embeddings from the dense and instance layers at each voxel will raise overall accuracy rather than introduce errors when the two sources disagree.
What would settle it
Measure semantic segmentation accuracy on a benchmark scene where the initial dense and instance predictions differ substantially; if the fused result is worse than the better of the two separate layers, the fusion benefit does not hold.
Figures



read the original abstract
Open-vocabulary semantic mapping enables robots to spatially ground previously unseen concepts without requiring predefined class sets. Current training-free methods commonly rely on multi-view fusion of semantic embeddings into a 3D map, either at the instance-level via segmenting views and encoding image crops of segments, or by projecting image patch embeddings directly into a dense semantic map. The latter approach sidesteps segmentation and 2D-to-3D instance association by operating on full uncropped image frames, but existing methods remain limited in scalability. We present FUS3DMaps, an online dual-layer semantic mapping method that jointly maintains both dense and instance-level open-vocabulary layers within a shared voxel map. This design enables further voxel-level semantic fusion of the layer embeddings, combining the complementary strengths of both semantic mapping approaches. We find that our proposed semantic cross-layer fusion approach improves the quality of both the instance-level and dense layers, while also enabling a scalable and highly accurate instance-level map where the dense layer and cross-layer fusion are restricted to a spatial sliding window. Experiments on established 3D semantic segmentation benchmarks as well as a selection of large-scale scenes show that FUS3DMaps achieves accurate open-vocabulary semantic mapping at multi-story building scales. Additional material and code will be made available: https://githanonymous.github.io/FUS3DMaps/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FUS3DMaps, a scalable online semantic mapping system for open-vocabulary concepts. It maintains a dual-layer voxel map consisting of a dense layer from full-frame embeddings and an instance-level layer from segmented crops. These layers are fused at the voxel level to improve both, with dense processing limited to a sliding window for scalability to large environments like multi-story buildings. Experiments on 3D semantic segmentation benchmarks and large-scale scenes are reported to demonstrate accurate mapping.
Significance. If the claimed improvements from cross-layer fusion hold, this method could provide a practical advance in robotic semantic mapping by combining the scalability of instance-level approaches with the accuracy of dense methods. The sliding window restriction addresses a key scalability issue in dense semantic mapping. The authors' commitment to releasing code and additional material is commendable for enabling further research. The stress-test concern regarding potential accuracy loss from fusing disagreeing embeddings does not appear to land, as the paper reports empirical improvements on benchmarks.
minor comments (2)
- The abstract refers to 'a selection of large-scale scenes' without specifying which scenes or datasets; providing names would improve clarity.
- The GitHub link uses 'githanonymous' which is likely a placeholder; this should be updated to the actual repository in the final version.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of FUS3DMaps and the recommendation for minor revision. The referee's summary accurately captures our dual-layer voxel map design, the benefits of cross-layer fusion at the voxel level, the sliding-window restriction for scalability, and the experimental validation on both benchmarks and large-scale scenes. We are pleased that the referee recognizes the practical potential of combining instance-level scalability with dense accuracy. No specific major comments were raised in the report, so we have no point-by-point revisions to detail. We reaffirm our commitment to releasing code and additional material upon acceptance.
Circularity Check
No circularity: empirical architectural proposal with independent experimental validation
full rationale
The paper proposes a dual-layer voxel-based semantic mapping architecture with cross-layer fusion as a design choice, then reports empirical improvements on standard 3D semantic segmentation benchmarks and large-scale scenes. No equations, fitted parameters, or predictions are defined such that the claimed accuracy gains reduce to the inputs by construction. The central claim rests on experimental results rather than any self-referential derivation, self-citation chain, or renamed known result. This is a standard non-circular engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Conceptfusion: Open-set multimodal 3d mapping.arXiv preprint arXiv:2302.07241, 2023
K. M. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, T. Chen, A. Maalouf, S. Li, G. Iyer, S. Saryazdi, N. Keetha, A. Tewari, J. B. Tenenbaum, C. M. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba, “Conceptfusion: Open-set multimodal 3d mapping,” 2023. [Online]. Available: https://arxiv.org/abs/2302.07241
-
[2]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick, “Segment anything,”arXiv:2304.02643, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,”
-
[4]
Learning Transferable Visual Models From Natural Language Supervision
[Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review arXiv
-
[5]
Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,
K. Yamazaki, T. Hanyu, K. V o, T. Pham, M. Tran, G. Doretto, A. Nguyen, and N. Le, “Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation,” 2023. [Online]. Available: https://arxiv.org/abs/2310.03923
-
[6]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,”Robotics: Science and Systems, 2024
2024
-
[7]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C. M. de Melo, J. B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull, “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” 2023. [Online]. Available: https://arxiv.org/abs/2309.16650
-
[8]
Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,
O. Alama, A. Bhattacharya, H. He, S. Kim, Y . Qiu, W. Wang, C. Ho, N. Keetha, and S. Scherer, “Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,” 2025. [Online]. Available: https://arxiv.org/abs/2504.06994
-
[9]
Habitat-matterport 3d semantics dataset,
K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervet, J. Turner, A. Gokaslan, N. Maestre, A. X. Chang, D. Batra, M. Savvaet al., “Habitat-matterport 3d semantics dataset,” arXiv preprint arXiv:2210.05633, 2022. [Online]. Available: https: //arxiv.org/abs/2210.05633
-
[10]
Open-vocabulary online semantic mapping for slam,
T. B. Martins, M. R. Oswald, and J. Civera, “Open-vocabulary online semantic mapping for slam,”IEEE Robotics and Automation Letters, 2025
2025
-
[11]
Openvox: Real-time instance-level open-vocabulary probabilistic voxel representation,
Y . Deng, B. Yao, Y . Tang, Y . Yang, and Y . Yue, “Openvox: Real-time instance-level open-vocabulary probabilistic voxel representation,”
-
[12]
Available: https://arxiv.org/abs/2502.16528
[Online]. Available: https://arxiv.org/abs/2502.16528
-
[13]
Openscene: 3d scene understanding with open vocab- ularies,
S. Peng, K. Genova, C. M. Jiang, A. Tagliasacchi, M. Pollefeys, and T. Funkhouser, “Openscene: 3d scene understanding with open vocab- ularies,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[14]
Radiov2.5: Improved baselines for agglomerative vision foundation models,
G. Heinrich, M. Ranzinger, Hongxu, Yin, Y . Lu, J. Kautz, A. Tao, B. Catanzaro, and P. Molchanov, “Radiov2.5: Improved baselines for agglomerative vision foundation models,” 2025. [Online]. Available: https://arxiv.org/abs/2412.07679
-
[15]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11 997– 12 008
2023
-
[16]
Radseg: Unleashing parameter and compute efficient zero-shot open-vocabulary segmentation using agglomerative models,
O. Alama, D. Jariwala, A. Bhattacharya, S. Kim, W. Wang, and S. Scherer, “Radseg: Unleashing parameter and compute efficient zero-shot open-vocabulary segmentation using agglomerative models,”
-
[17]
[Online]. Available: https://arxiv.org/abs/2511.19704
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation,
S. Hajimiri, I. Ben Ayed, and J. Dolz, “Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
2025
-
[19]
Clip-dinoiser: Teaching clip a few dino tricks for open-vocabulary semantic segmentation,
M. Wysocza ´nska, O. Sim ´eoni, M. Ramamonjisoa, A. Bursuc, T. Trzci´nski, and P. P ´erez, “Clip-dinoiser: Teaching clip a few dino tricks for open-vocabulary semantic segmentation,” 2024. [Online]. Available: https://arxiv.org/abs/2312.12359
-
[20]
Extract free dense labels from clip,
C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from clip,” inEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[21]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,”
-
[22]
Emerging Properties in Self-Supervised Vision Transformers.arXiv:2104.14294 [cs], May 2021
[Online]. Available: https://arxiv.org/abs/2104.14294
-
[23]
G. Ilharco, M. Wortsman, R. Wightman, C. Gordon, N. Carlini, R. Taori, A. Dave, V . Shankar, H. Namkoong, J. Miller, H. Hajishirzi, A. Farhadi, and L. Schmidt, “Openclip,” Jul. 2021, if you use this software, please cite it as below. [Online]. Available: https://doi.org/10.5281/zenodo.5143773
-
[24]
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,” 2023. [Online]. Available: https://arxiv.org/abs/2306.12156
-
[25]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, A. Clarkson, M. Yan, B. Budge, Y . Yan, X. Pan, J. Yon, Y . Zou, K. Leon, N. Carter, J. Briales, T. Gillingham, E. Mueggler, L. Pesqueira, M. Savva, D. Batra, H. M. Strasdat, R. D. Nardi, M. Goesele, S. Lovegrove, and R. Newcombe, “The Replica dataset...
work page internal anchor Pith review arXiv 1906
-
[26]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017
2017
-
[27]
NVIDIA TensorRT SDK,
NVIDIA, “NVIDIA TensorRT SDK,” 2025. [Online]. Available: https://developer.nvidia.com/tensorrt
2025
-
[28]
M. Patel, F. Yang, Y . Qiu, C. Cadena, S. Scherer, M. Hutter, and W. Wang, “Tartanground: A large-scale dataset for ground robot perception and navigation,”arXiv preprint arXiv:2505.10696, 2025
-
[29]
Odin1 Spatial Memory Module,
Manifold Tech, “Odin1 Spatial Memory Module,” Available online, 2025, accessed: 2026-02-06. [Online]. Available: https: //www.manifoldtech.cn/
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.