Recognition: unknown
SOAR: Real-Time Joint Optimization of Order Allocation and Robot Scheduling in Robotic Mobile Fulfillment Systems
Pith reviewed 2026-05-07 16:22 UTC · model grok-4.3
The pith
A deep reinforcement learning system unifies order allocation and robot scheduling to cut warehouse makespan by 7.5 percent and order completion time by 15.4 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
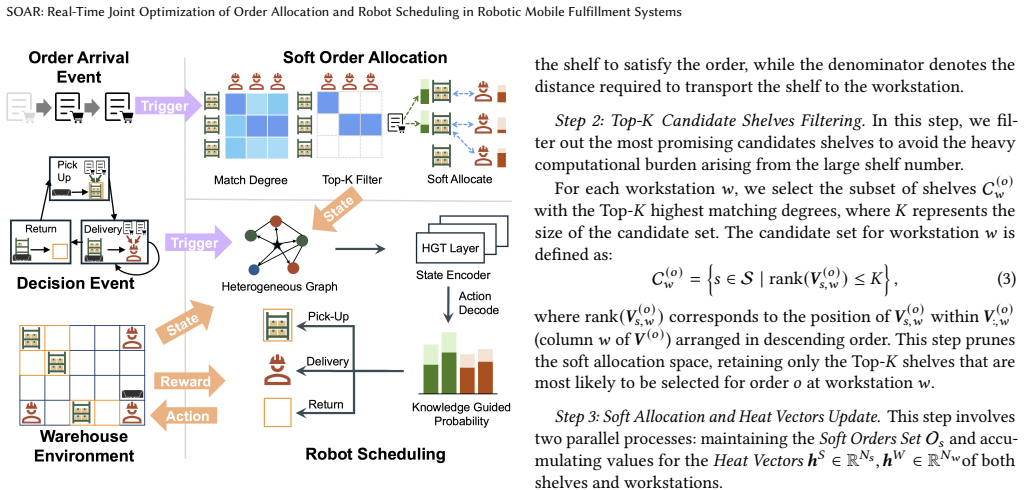
SOAR formulates order allocation and robot scheduling as a single event-driven Markov decision process that accepts soft order allocations as observations, encodes the full warehouse state with a heterogeneous graph transformer that incorporates domain knowledge, and applies reward shaping to manage sparse long-horizon signals, thereby enabling real-time joint optimization that delivers lower global makespan and shorter average order completion times.
What carries the argument
The event-driven Markov decision process that accepts soft order allocations as observations and encodes warehouse state with a heterogeneous graph transformer.
If this is right
- The unified process avoids the loss of global optimality that occurs when order allocation and robot scheduling are solved as separate sub-problems.
- Event-driven updates let the system react immediately to asynchronous arrivals or completions instead of using fixed time steps.
- Reward shaping supplies intermediate guidance that helps the learner complete long sequences of coupled decisions.
- Sub-100 ms decision latency satisfies the real-time requirements of industrial robotic fleets.
- Successful sim-to-real transfer indicates the method can move from simulation training into actual production warehouses.
Where Pith is reading between the lines
- The same soft-allocation and event-driven structure could be tested on related coupled scheduling tasks such as coordinating autonomous vehicles in a port or hospital delivery robots.
- Adding explicit battery or priority constraints into the observation and reward would be a direct next step that keeps the existing MDP and graph encoder intact.
- The heterogeneous graph transformer might serve as a reusable state encoder for other multi-agent systems that must represent both static layout and dynamic agent positions.
Load-bearing premise
The policy learned on the training warehouse event patterns will keep its performance advantage when the system encounters new order volumes, robot counts, or layout changes it has not seen before.
What would settle it
Deploy the trained system in a live warehouse whose daily order arrival rates or robot fleet size differ markedly from the training data and check whether the reported reductions in makespan and completion time disappear.
Figures





read the original abstract
Robotic Mobile Fulfillment Systems (RMFS) rely on mobile robots for automated inventory transportation, coordinating order allocation and robot scheduling to enhance warehousing efficiency. However, optimizing RMFS is challenging due to strict real-time constraints and the strong coupling of multi-phase decisions. Existing methods either decompose the problem into isolated sub-tasks to guarantee responsiveness at the cost of global optimality, or rely on computationally expensive global optimization models that are unsuitable for dynamic industrial environments. To bridge this gap, we propose SOAR, a unified Deep Reinforcement Learning framework for real-time joint optimization. SOAR transforms order allocation and robot scheduling into a unified process by utilizing soft order allocations as observations. We formulate this as an Event-Driven Markov Decision Process, enabling the agent to perform simultaneous scheduling in response to asynchronous system events. Technically, we employ a Heterogeneous Graph Transformer to encode the warehouse state and integrate phased domain knowledge. Additionally, we incorporate a reward shaping strategy to address sparse feedback in long-horizon tasks. Extensive experiments on synthetic and real-world industrial datasets, in collaboration with Geekplus, demonstrate that SOAR reduces global makespan by 7.5\% and average order completion time by 15.4\% with sub-100ms latency. Furthermore, sim-to-real deployment confirms its practical viability and significant performance gains in production environments. The code is available at https://github.com/200815147/SOAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SOAR, a unified deep reinforcement learning framework for real-time joint optimization of order allocation and robot scheduling in Robotic Mobile Fulfillment Systems. It formulates the problem as an Event-Driven Markov Decision Process using soft order allocations as observations, encodes the state with a Heterogeneous Graph Transformer incorporating phased domain knowledge, and applies reward shaping for sparse long-horizon feedback. Experiments on synthetic and real-world industrial datasets (in collaboration with Geekplus) report 7.5% reduction in global makespan, 15.4% reduction in average order completion time, sub-100 ms latency, and successful sim-to-real deployment confirming practical viability.
Significance. If the performance gains and real-time guarantees hold under broader conditions, the work offers a practical advance over decomposed sub-task methods or expensive global optimizers for coupled decisions in dynamic warehouses. The open availability of code at https://github.com/200815147/SOAR is a clear strength supporting reproducibility.
major comments (2)
- [Evaluation] Evaluation section: The headline claims of 7.5% makespan reduction and 15.4% order completion time improvement are reported without specification of the baselines used, any statistical significance tests, or analysis of potential confounding factors (e.g., order arrival intensity or robot availability variations), which are load-bearing for validating the joint-optimization advantage over existing approaches.
- [Sim-to-real and generalization] Generalization discussion and sim-to-real section: No explicit distribution-shift experiments (e.g., altered order-arrival rates, robot failure rates, or layout changes) are presented to test whether the event-driven MDP with soft allocations and Heterogeneous Graph Transformer generalizes beyond the synthetic and Geekplus training distributions, leaving the weakest assumption unaddressed despite the production deployment claim.
minor comments (1)
- [Abstract] Abstract: The description of the real-world datasets and exact experimental protocol could be expanded for clarity on how the sub-100 ms latency was measured across varying system scales.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point by point below, providing clarifications and outlining the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline claims of 7.5% makespan reduction and 15.4% order completion time improvement are reported without specification of the baselines used, any statistical significance tests, or analysis of potential confounding factors (e.g., order arrival intensity or robot availability variations), which are load-bearing for validating the joint-optimization advantage over existing approaches.
Authors: We appreciate the referee highlighting the need for clearer presentation of the evaluation results. The manuscript compares SOAR against relevant baselines including decomposed sub-task methods and global optimization approaches discussed in the introduction and related work. However, we agree that explicit specification of the baselines, statistical significance testing, and analysis of confounding factors would strengthen the claims. In the revised manuscript, we will add a detailed table specifying all baselines, include statistical tests such as paired t-tests to confirm the significance of the reported improvements, and provide additional analysis by varying order arrival intensities and robot availability to address potential confounders. These changes will be incorporated in the Evaluation section. revision: yes
-
Referee: [Sim-to-real and generalization] Generalization discussion and sim-to-real section: No explicit distribution-shift experiments (e.g., altered order-arrival rates, robot failure rates, or layout changes) are presented to test whether the event-driven MDP with soft allocations and Heterogeneous Graph Transformer generalizes beyond the synthetic and Geekplus training distributions, leaving the weakest assumption unaddressed despite the production deployment claim.
Authors: We thank the referee for this important observation regarding generalization. While the current manuscript includes experiments on both synthetic and real-world industrial datasets from Geekplus, along with a successful sim-to-real deployment that demonstrates practical viability, we acknowledge the absence of explicit distribution-shift experiments. To address this, we will add new experiments in the revised version that simulate distribution shifts, such as changes in order-arrival rates, robot failure rates, and layout variations. These will evaluate the robustness of the event-driven MDP formulation and the Heterogeneous Graph Transformer under out-of-distribution conditions, further supporting the generalization claims. revision: yes
Circularity Check
No circularity: SOAR's joint optimization claims rest on empirical DRL training and evaluation against external baselines.
full rationale
The paper defines an Event-Driven MDP with soft allocations, encodes states via Heterogeneous Graph Transformer, and applies reward shaping to train an agent end-to-end. Reported gains (7.5% makespan, 15.4% completion time, sub-100 ms latency) are measured on held-out synthetic and Geekplus industrial test instances plus sim-to-real deployment. No equation or claim reduces by construction to a fitted parameter renamed as prediction, no load-bearing self-citation chain, and no uniqueness theorem imported from prior author work. The derivation is self-contained against external benchmarks and does not invoke any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- DRL training hyperparameters
axioms (1)
- domain assumption Warehouse dynamics can be modeled as an event-driven MDP with soft order allocations as sufficient observations.
Reference graph
Works this paper leans on
-
[1]
Maria Torcoroma Benavides-Robles, Jorge M Cruz-Duarte, José Carlos Ortiz- Bayliss, and Ivan Amaya. 2025. Algorithm Selection for Allocating Pods Within Robotic Mobile Fulfillment Systems: A Hyper-Heuristic Approach.IEEE Access (2025)
2025
-
[2]
Cruz-Duarte, Iván Amaya, and José Carlos Ortiz-Bayliss
Maria Torcoroma Benavides-Robles, Gerardo Humberto Valencia-Rivera, Jorge M. Cruz-Duarte, Iván Amaya, and José Carlos Ortiz-Bayliss. 2024. Robotic Mobile Fulfillment System: A Systematic Review.IEEE Access12 (2024), 16767–16782
2024
-
[3]
Hualing Bi, Guangpu Yang, Zhe Wang, and Fuqiang Lu. 2025. Enhancing E- Commerce RMFS Order Fulfillment Through Pod Positioning with Jointly Opti- mized Task Allocation.Systems13, 11 (2025), 995
2025
- [4]
-
[5]
Byoungho Choi, Minkyu Kim, and Heungseob Kim. 2025. An Optimization Framework for Allocating and Scheduling Multiple Tasks of Multiple Logistics Robots.Mathematics13, 11 (2025), 1770
2025
-
[6]
Filippos Christianos, Lukas Schäfer, and Stefano Albrecht. 2020. Shared expe- rience actor-critic for multi-agent reinforcement learning.Advances in neural information processing systems33 (2020), 10707–10717
2020
-
[7]
Ítalo Renan da Costa Barros and Tiago Pereira Nascimento. 2021. Robotic mobile fulfillment systems: A survey on recent developments and research opportunities. Robotics and Autonomous Systems137 (2021), 103729
2021
-
[8]
Dingxiong Deng, Cyrus Shahabi, Ugur Demiryurek, and Linhong Zhu. 2016. Task selection in spatial crowdsourcing from worker’s perspective.GeoInformatica 20, 3 (2016), 529–568
2016
-
[9]
Marko Filipović and Kristijan Rogić. 2025. Robotic Mobile Fulfilment System: A Literature Review.Transportation Research Procedia91 (2025), 465–472
2025
-
[10]
Amir Gharehgozli and Nima Zaerpour. 2020. Robot scheduling for pod retrieval in a robotic mobile fulfillment system.Transportation Research Part E: Logistics and Transportation Review142 (2020), 102087
2020
-
[11]
Aleksandar Krnjaic, Raul D Steleac, Jonathan D Thomas, Georgios Papoudakis, Lukas Schäfer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter Börsting, et al. 2024. Scalable multi-agent reinforcement learning for warehouse logistics with robotic and human co-workers. In2024 IEEE/RSJ International Conference on Intelligent Robots and ...
2024
-
[13]
Kunpeng Li, Tengbo Liu, PN Ram Kumar, and Xuefang Han. 2024. A rein- forcement learning-based hyper-heuristic for AGV task assignment and route planning in parts-to-picker warehouses.Transportation research part E: logistics and transportation review185 (2024), 103518
2024
-
[14]
Yafei Li, Huiling Li, Xin Huang, Jianliang Xu, Yu Han, and Mingliang Xu. 2022. Utility-aware dynamic ridesharing in spatial crowdsourcing.IEEE Transactions on Mobile Computing23, 2 (2022), 1066–1079
2022
-
[15]
parts to picker
Kaibo Liang, Li Zhou, Jianglong Yang, Huwei Liu, Yakun Li, Fengmei Jing, Man Shan, and Jin Yang. 2023. Research on a dynamic task update assignment strategy based on a “parts to picker” picking system.Mathematics11, 7 (2023), 1684
2023
- [16]
-
[17]
James Munkres. 1957. Algorithms for the assignment and transportation prob- lems.Journal of the society for industrial and applied mathematics5, 1 (1957), 32–38
1957
-
[18]
Andrew Y Ng, Daishi Harada, and Stuart Russell. 1999. Policy invariance under reward transformations: Theory and application to reward shaping. InIcml, Vol. 99. Citeseer, 278–287
1999
-
[21]
Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V Albrecht
- [22]
-
[23]
Xiaoran Qin, Hai Yang, Yinghui Wu, and Hongtu Zhu. 2021. Multi-party ride- matching problem in the ride-hailing market with bundled option services. Transportation Research Part C: Emerging Technologies131 (2021), 103287
2021
-
[24]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel
-
[25]
High-dimensional continuous control using generalized advantage estima- tion.arXiv preprint arXiv:1506.02438(2015)
work page internal anchor Pith review arXiv 2015
-
[26]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[27]
Proximal Policy Optimization Algorithms.CoRRabs/1707.06347 (2017)
work page internal anchor Pith review arXiv 2017
-
[28]
Xiang Shi, Fang Deng, Miao Guo, Jiachen Zhao, Lin Ma, Bin Xin, and Jie Chen
-
[29]
A novel fulfillment-focused simultaneous assignment method for large- scale order picking optimization problem in RMFS.IEEE Transactions on Systems, Man, and Cybernetics: Systems54, 2 (2023), 1226–1238
2023
-
[30]
Huiheng Suo, Qiang Hu, Jian Wu, Xie Ma, Youxuan Cai, Shiai Bi, Jingwen Zhang, and Xiushui Ma. 2023. Multi-AGV Task Scheduling Method for Intelligent Warehousing. (2023)
2023
-
[31]
Giorgi Tadumadze, Julia Wenzel, Simon Emde, Felix Weidinger, and Ralf Elbert
-
[32]
Assigning orders and pods to picking stations in a multi-level robotic mobile fulfillment system.Flexible Services and Manufacturing Journal35, 4 (2023), 1038–1075
2023
-
[33]
Sander Teck and Reginald Dewil. 2022. A bi-level memetic algorithm for the integrated order and vehicle scheduling in a RMFS.Applied Soft Computing121 (2022), 108770
2022
-
[34]
Yongxin Tong, Libin Wang, Zhou Zimu, Bolin Ding, Lei Chen, Jieping Ye, and Ke Xu. 2017. Flexible online task assignment in real-time spatial data.Proceedings of the VLDB Endowment10, 11 (2017), 1334–1345
2017
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[36]
Jingwen Wu, Zhiyuan Yang, Lu Zhen, Wenxin Li, and Yiran Ren. 2025. Joint optimization of order picking and replenishment in robotic mobile fulfillment systems.Transportation Research Part E: Logistics and Transportation Review194 (2025), 103930
2025
- [37]
-
[38]
Shaohui Zhang, Qiuying Han, Hai Zhu, Hongfeng Wang, Huiling Li, and Ke Wang. 2025. Real time task planning for order picking in intelligent logistics warehousing.Scientific Reports15, 1 (2025), 7331
2025
-
[39]
Junpeng Zhao and Chu Zhang. 2025. Order Allocation Strategy Optimization in a Goods-to-Person Robotic Mobile Fulfillment System with Multiple Picking Stations.Applied Sciences15, 16 (2025), 9173
2025
-
[40]
Ziyan Zhao, Bingchen Cao, Jiaqi Liang, Shixin Liu, and Mengchu Zhou. 2025. Learning-Based Approach to Integrated Operational Optimization Problems in Robot-Assisted Multistation Warehouse Systems.IEEE Transactions on Systems, Man, and Cybernetics: Systems(2025)
2025
-
[41]
Xuan Zhou, Xiang Shi, Wenqing Chu, Jingchen Jiang, Lele Zhang, and Fang Deng. 2024. Learning to Solve Multi-AGV Scheduling Problem with Pod Reposi- tioning Optimization in RMFS. In2024 IEEE International Conference on Industrial Technology (ICIT). IEEE, 1–8
2024
-
[42]
Xuan Zhou, Xiang Shi, Lele Zhang, Chen Chen, Hongbo Li, Lin Ma, Fang Deng, and Jie Chen. 2024. Scalable Hierarchical Reinforcement Learning for Hyper Scale Multi-Robot Task Planning.arXiv preprint arXiv:2412.19538(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
few large, many small
Yanling Zhuang, Yun Zhou, Elkafi Hassini, Yufei Yuan, and Xiangpei Hu. 2022. Rack retrieval and repositioning optimization problem in robotic mobile ful- fillment systems.Transportation Research Part E: Logistics and Transportation Review167 (2022), 102920. Tang and Yang, et al. A Dataset Details Table 4: Summary of Dataset Parameters (a) Warehouse Settin...
2022
-
[44]
Order Assignment Constraint:Each order must be assigned to exactly one workstation to be processed.∑︁ 𝑤∈𝑊 𝑦𝑜,𝑤 =1,∀𝑜∈𝑂(35)
-
[45]
Demand Satisfaction Constraint:For every order and every required item, the total quantity picked from all shelves must equal the order’s requirement.∑︁ 𝑠∈𝑆 𝑥𝑜,𝑘,𝑠 =𝑅 𝑜,𝑘,∀𝑜∈𝑂,∀𝑘∈𝐾where𝑅 𝑜,𝑘 >0(36)
-
[46]
Inventory Capacity Constraint:The total quantity of a specific item picked from a shelf by all orders cannot exceed the shelf’s available inventory.∑︁ 𝑜∈𝑂 𝑥𝑜,𝑘,𝑠 ≤𝐼 𝑠,𝑘,∀𝑠∈𝑆,∀𝑘∈𝐾where𝐼 𝑠,𝑘 >0(37)
-
[47]
It ensures that if an order𝑜 assigned to workstation 𝑤 picks any item from shelf 𝑠, then shelf 𝑠 must visit workstation 𝑤
Shelf-Workstation Coupling Constraint:This constraint links the picking variable 𝑥, the order assignment 𝑦, and the shelf move- ment 𝑧. It ensures that if an order𝑜 assigned to workstation 𝑤 picks any item from shelf 𝑠, then shelf 𝑠 must visit workstation 𝑤 . In the CP-SAT model, this is implemented using logical implication: if shelf 𝑠 does not visit wor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.