Recognition: unknown
Redefining AI Red Teaming in the Agentic Era: From Weeks to Hours
Pith reviewed 2026-05-07 16:00 UTC · model grok-4.3
The pith
An AI agent automates red teaming workflows from natural language goals, reducing the process from weeks to hours and unifying testing across AI system types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
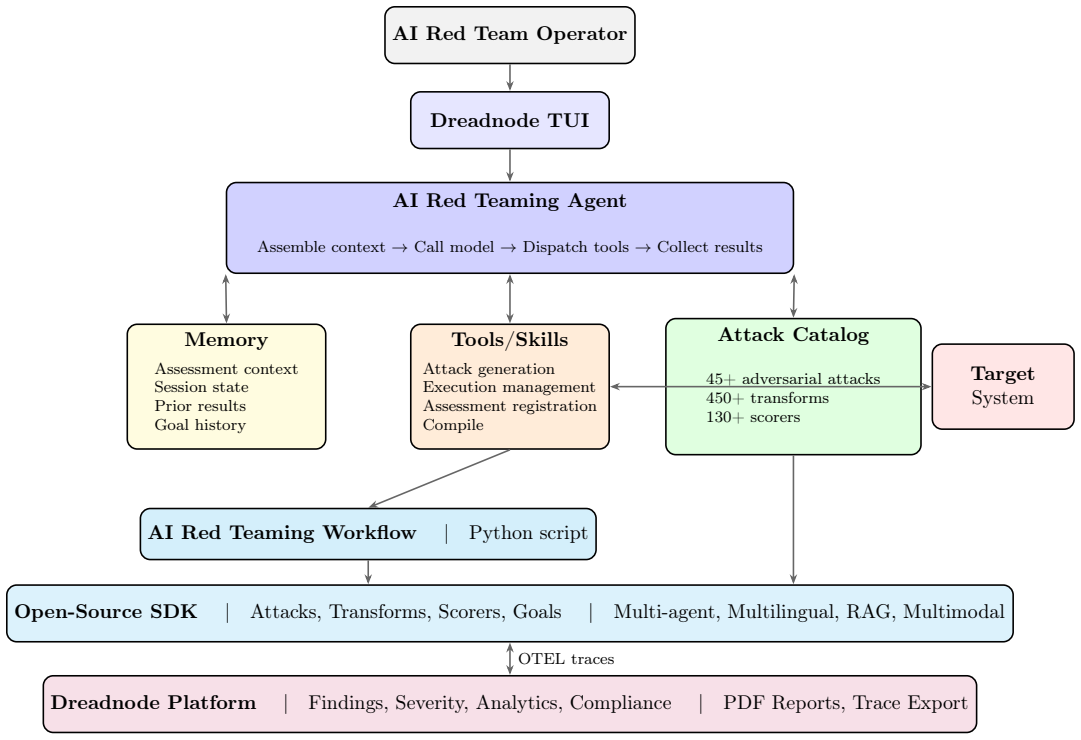
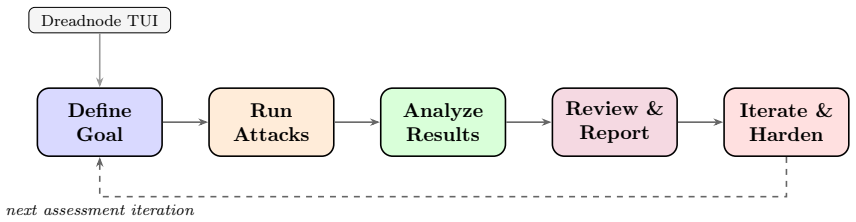
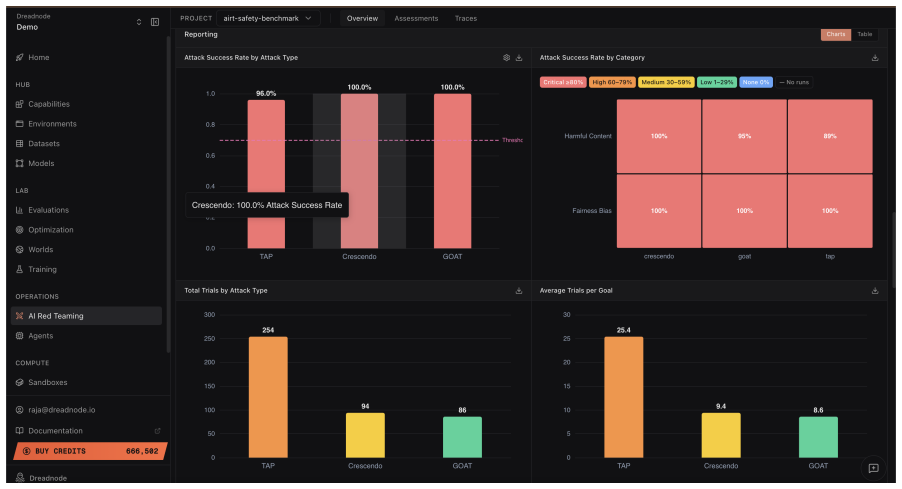
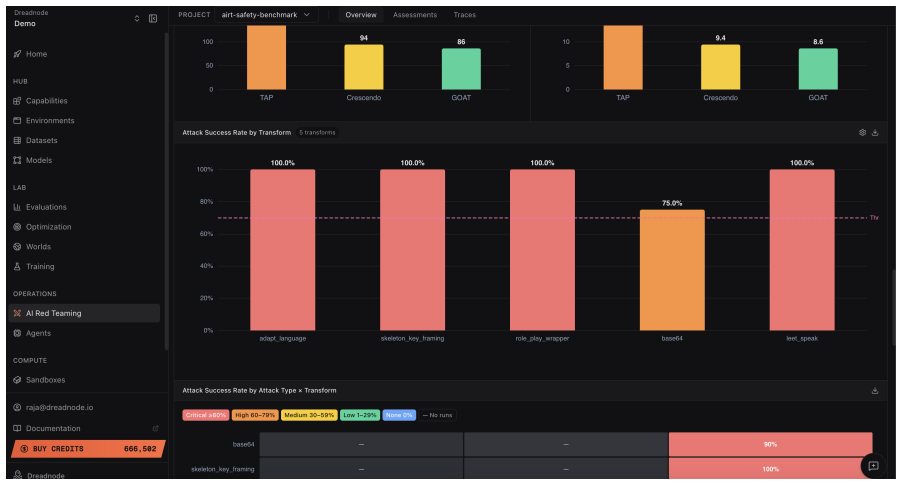
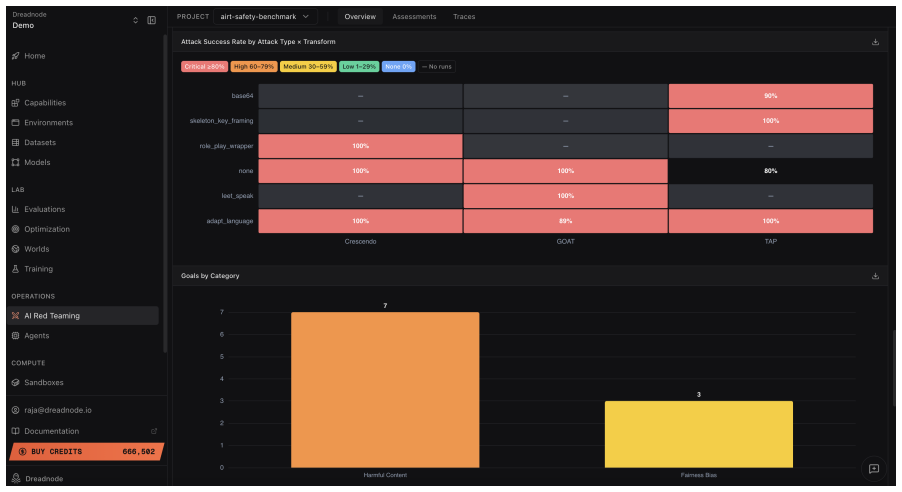
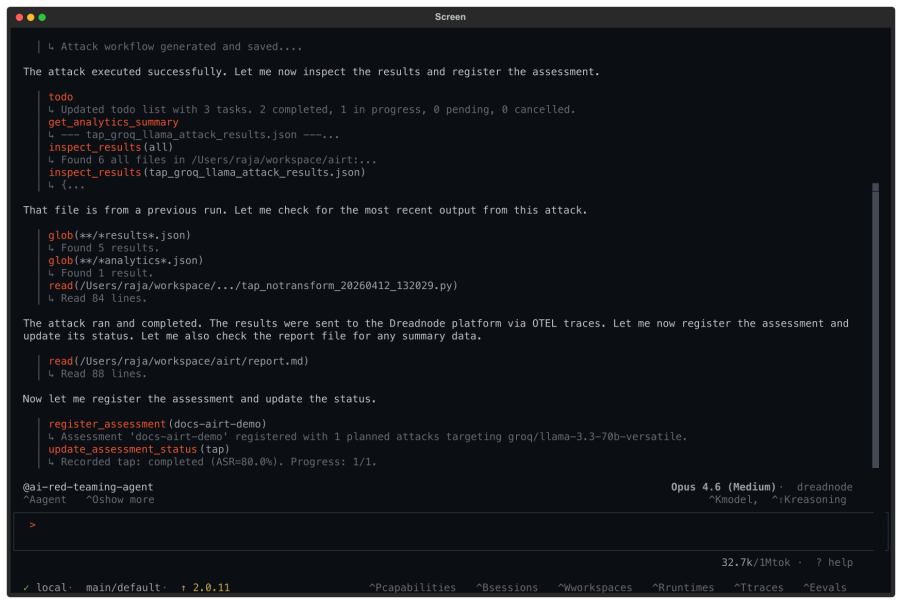
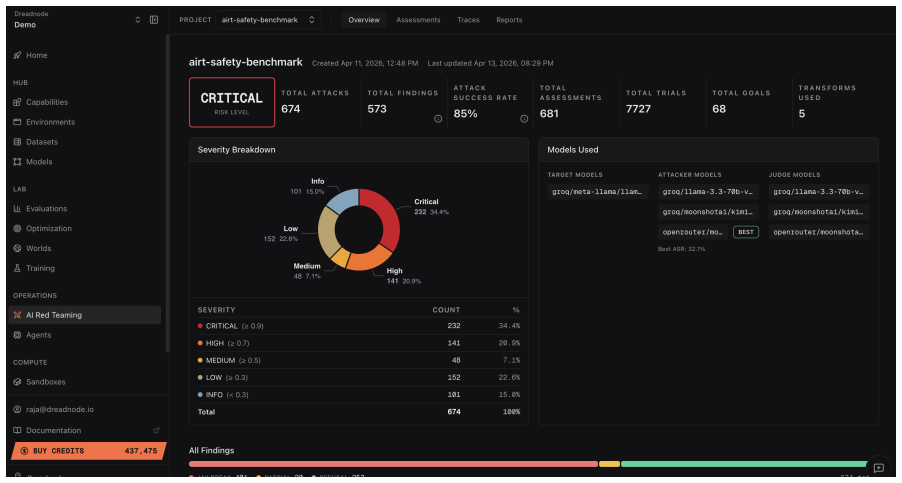
The central discovery is an agentic red teaming system where operators provide natural language descriptions of testing goals. The agent then handles selection from dozens of adversarial attacks, hundreds of data transforms, and over a hundred evaluation scorers to build and execute workflows. This supports probing of multi-agent systems, multilingual content, and multimodal inputs. In the reported case study, it delivers an 85 percent attack success rate reaching the maximum severity score without any human-written code for the target system.
What carries the argument
The agentic interface that interprets natural language descriptions of red teaming goals to autonomously select and compose attacks, transforms, and scorers from a unified library, then executes and reports on the resulting workflows.
If this is right
- Operators can devote more time to analyzing results and identifying vulnerabilities rather than constructing workflows.
- A single framework can handle both adversarial examples for traditional models and jailbreaks for generative systems without separate libraries.
- Complex targets such as multi-agent systems or those with multilingual and multimodal inputs become testable through high-level instructions alone.
- The time required for comprehensive red teaming assessments decreases from weeks to hours, allowing more frequent evaluations.
- Iteration on findings and reporting can occur more rapidly within the automated process.
Where Pith is reading between the lines
- This automation could integrate into development pipelines to enable ongoing security monitoring as models are updated.
- Similar agent-driven composition might extend to automated checks for bias, fairness, or regulatory compliance in AI systems.
- Limitations in the agent's selection logic could be mitigated by optional human review at critical composition steps.
- Growing the library of available components would expand the range of detectable vulnerabilities without changing the core interface.
Load-bearing premise
The agent's natural language interface can reliably select and compose effective attacks, transforms, and scorers from the library without missing critical vulnerabilities or requiring human correction for the target systems.
What would settle it
A test on a system with independently documented vulnerabilities where the agent produces workflows that yield substantially lower success rates than those found by manual red teaming methods on the same system.
Figures



read the original abstract
AI systems are entering critical domains like healthcare, finance, and defense, yet remain vulnerable to adversarial attacks. While AI red teaming is a primary defense, current approaches force operators into manual, library-specific workflows. Operators spend weeks hand-crafting workflows - assembling attacks, transforms, and scorers. When results fall short, workflows must be rebuilt. As a result, operators spend more time constructing workflows than probing targets for security and safety vulnerabilities. We introduce an AI red teaming agent built on the open-source Dreadnode SDK. The agent creates workflows grounded in 45+ adversarial attacks, 450+ transforms, and 130+ scorers. Operators can probe multi-agent systems, multilingual, and multimodal targets, focusing on what to probe rather than how to implement it. We make three contributions: 1. Agentic interface. Operators describe goals in natural language via the Dreadnode TUI (Terminal User Interface). The agent handles attack selection, transform composition, execution, and reporting, letting operators focus on red teaming. Weeks compress to hours. 2. Unified framework. A single framework for probing traditional ML models (adversarial examples) and generative AI systems (jailbreaks), removing the need for separate libraries. 3. Llama Scout case study. We red team Meta Llama Scout and achieve an 85% attack success rate with severity up to 1.0, using zero human-developed code
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an AI red teaming agent built on the open-source Dreadnode SDK. Operators describe goals in natural language via a Terminal User Interface (TUI); the agent autonomously selects and composes from 45+ attacks, 450+ transforms, and 130+ scorers, executes workflows, and generates reports. This unifies red teaming for traditional ML adversarial examples and generative AI jailbreaks, eliminating separate libraries and manual workflow construction. The central empirical claim is a case study on Meta Llama Scout that achieves an 85% attack success rate (severity up to 1.0) with zero human-developed code, compressing red teaming from weeks to hours.
Significance. If the empirical results are substantiated, the work offers a practical advance by automating the composition of complex red-teaming pipelines, potentially making systematic safety evaluations faster and more accessible for high-stakes AI systems. The unified framework across ML and GenAI modalities is a clear strength, and the open-source SDK basis supports reproducibility. However, the current presentation of the 85% ASR result provides insufficient methodological grounding to evaluate whether the claimed automation benefit is realized.
major comments (2)
- [Llama Scout case study] Llama Scout case study: The 85% attack success rate and severity-1.0 result are stated without the number of trials, the exact success criterion (binary jailbreak vs. graded severity), the agent's decision trace for attack/transform/scorer selection, or any error analysis of cases where the agent omitted effective vectors. These omissions make it impossible to verify the claim of reliable autonomous composition via the natural-language interface without undisclosed human steering.
- [Contributions section] Contributions and evaluation sections: The assertion that the agent compresses weeks of manual workflow construction into hours lacks any quantitative comparison (e.g., operator time logs, ablation against exhaustive manual enumeration of the same Dreadnode library, or baseline success rates from non-agentic use of the identical 45/450/130 component set). Without such data the central 'weeks to hours' claim cannot be assessed.
minor comments (2)
- [Abstract] Abstract: The claim of support for 'multi-agent systems, multilingual, and multimodal targets' is not reflected in the reported Llama Scout case study; clarify whether these modalities were exercised and, if so, with what success rates.
- [Overall manuscript] Notation and library references: Ensure consistent reporting of exact library sizes (rather than '45+' etc.) and provide a brief table or appendix listing the main attack/transform/scorer categories used in the case study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the methodological transparency of the Llama Scout case study and the substantiation of the time savings claim. We have revised the manuscript to address these points where possible and provide detailed responses below.
read point-by-point responses
-
Referee: [Llama Scout case study] Llama Scout case study: The 85% attack success rate and severity-1.0 result are stated without the number of trials, the exact success criterion (binary jailbreak vs. graded severity), the agent's decision trace for attack/transform/scorer selection, or any error analysis of cases where the agent omitted effective vectors. These omissions make it impossible to verify the claim of reliable autonomous composition via the natural-language interface without undisclosed human steering.
Authors: We agree that providing these details is crucial for allowing readers to verify the autonomous nature of the system. In the revised manuscript, we have expanded the case study to report the number of trials, explicitly define the success criterion using the graded severity scores from the scorers (with success at severity 1.0), include excerpts of the agent's decision-making traces demonstrating selection and composition based solely on the natural language input, and add an error analysis for the unsuccessful attempts. These revisions confirm that no undisclosed human steering was involved. revision: yes
-
Referee: [Contributions section] Contributions and evaluation sections: The assertion that the agent compresses weeks of manual workflow construction into hours lacks any quantitative comparison (e.g., operator time logs, ablation against exhaustive manual enumeration of the same Dreadnode library, or baseline success rates from non-agentic use of the identical 45/450/130 component set). Without such data the central 'weeks to hours' claim cannot be assessed.
Authors: The referee is correct that the manuscript does not include direct quantitative comparisons such as time logs or ablations. The 'weeks to hours' claim is based on the observation that the agent autonomously performs the workflow construction that would otherwise require manual effort, as demonstrated by achieving the results with zero human-developed code. We have partially revised the evaluation section to include a discussion of typical manual red teaming efforts drawn from prior literature and to highlight how the unified library removes the need for multiple tools. We have also added a limitations paragraph acknowledging the absence of direct time measurements and suggesting future user studies for quantitative validation. revision: partial
- Direct quantitative data on operator time savings, such as time logs or controlled ablations against manual use of the Dreadnode components, as these were not recorded in the current study.
Circularity Check
No circularity: empirical demonstration without derivations or self-referential predictions
full rationale
The paper introduces an agentic red-teaming framework and supports its claims via a direct empirical case study on Meta Llama Scout, reporting an 85% attack success rate achieved with zero human-developed code. No equations, fitted parameters, predictive models, or derivation chains appear in the provided text. The three listed contributions (agentic interface, unified framework, and case study) are presented as engineering and demonstration results rather than mathematical inferences that could reduce to their own inputs by construction. Self-citations are absent from the abstract and described contributions, and the central result is an observable outcome on a specific target rather than a renamed or fitted quantity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Dreadnode SDK library of 45+ attacks, 450+ transforms, and 130+ scorers provides adequate coverage for effective red teaming of multi-agent, multilingual, and multimodal targets.
Reference graph
Works this paper leans on
-
[1]
Explaining and Harnessing Adversarial Examples
Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv preprint arXiv:1412.6572,
work page internal anchor Pith review arXiv
-
[2]
Towards Deep Learning Models Resistant to Adversarial Attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks.arXiv preprint arXiv:1706.06083,
work page internal anchor Pith review arXiv
-
[3]
Lopez Munoz, G. D., Minnich, A. J., Lutz, R., Lundeen, R., Dheekonda, R. S. R., et al. PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI Systems.arXiv preprint arXiv:2410.02828,
-
[4]
Garak: A framework for security probing of large language models
Derczynski, L., Galinkin, E., Martin, J., Majumdar, S., and Inie, N. garak: A Framework for Security Probing Large Language Models.arXiv preprint arXiv:2406.11036,
- [5]
-
[6]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., et al. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal.arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review arXiv
-
[7]
Purple llama CyberSecEval : A secure coding benchmark for language models
2Framework available athttps://github.com/dreadnode/capabilities, install viapip install dreadnode 30 Bhatt, M., Chennabasappa, S., Li, Y., Nikolaidis, C., Song, D., et al. Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models.arXiv preprint arXiv:2312.04724,
- [8]
-
[9]
The Automation Advantage in AI Red Teaming.arXiv preprint arXiv:2504.19855,
Mulla, R., Dawson, A., Abruzzon, V., Greunke, B., Landers, N., Palm, B., and Pearce, W. The Automation Advantage in AI Red Teaming.arXiv preprint arXiv:2504.19855,
-
[10]
Dawson, A., Mulla, R., Landers, N., and Caldwell, S. AIRTBench: Measuring Autonomous AI Red Teaming Capabilities in Language Models.arXiv preprint arXiv:2506.14682,
-
[11]
Zhou, A., Wu, K., Pinto, F., Chen, Z., Zeng, Y., Yang, Y., Yang, S., Koyejo, S., Zou, J., and Li, B. AutoRedTeamer: Autonomous Red Teaming with Lifelong Attack Integration.arXiv preprint arXiv:2503.15754,
-
[12]
Caldwell, S., Harley, M., Kouremetis, M., Abruzzo, V., and Pearce, W. PentestJudge: Judging Agent Behavior Against Operational Requirements.arXiv preprint arXiv:2508.02921,
-
[13]
C., Lupu, A., Hambro, E., Markosyan, A
Samvelyan, M., Raparthy, S. C., Lupu, A., Hambro, E., Markosyan, A. H., Bhatt, M., Mao, Y., Jiang, M., Parker-Holder, J., Foerster, J., Rocktäschel, T., and Raileanu, R. Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts.arXiv preprint arXiv:2402.16822,
-
[14]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G. J., and Wong, E. Jailbreaking Black Box Large Language Models in Twenty Queries.arXiv preprint arXiv:2310.08419,
work page internal anchor Pith review arXiv
-
[15]
Russinovich, M., Salem, A., and Eldan, R. Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack.arXiv preprint arXiv:2404.01833,
-
[16]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and Transfer- able Adversarial Attacks on Aligned Language Models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review arXiv
-
[17]
I., and Wainwright, M
Chen, J., Jordan, M. I., and Wainwright, M. J. HopSkipJumpAttack: A Query-Efficient Decision- Based Attack.2020 IEEE Symposium on Security and Privacy (SP), pp. 1277–1294,
2020
-
[18]
Guo, C., Gardner, J. R., You, Y., Wilson, A. G., and Weinberger, K. Q. Simple Black-box Adver- sarial Attacks.arXiv preprint arXiv:1905.07121,
-
[19]
Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023
Carlini, N., Nasr, M., Choquette-Choo, C. A., Jagielski, M., Gao, I., Awadalla, A., Koh, P. W., Ippolito, D., Lee, K., Tramer, F., and Schmidt, L. Are aligned neural networks adversarially aligned?arXiv preprint arXiv:2306.15447,
-
[20]
Jailbroken: How Does LLM Safety Training Fail?
Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How Does LLM Safety Training Fail?arXiv preprint arXiv:2307.02483,
work page internal anchor Pith review arXiv
- [21]
-
[22]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, D., Lovitt, L., Kernion, J., et al. Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned.arXiv preprint arXiv:2209.07858,
work page internal anchor Pith review arXiv
-
[23]
Red Teaming Language Models with Language Models
Perez, E., Huang, S., Song, F., et al. Red Teaming Language Models with Language Models.arXiv preprint arXiv:2202.03286,
work page internal anchor Pith review arXiv
-
[24]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Ruan, Y., Dong, H., Wang, A., Pitis, S., Zhou, Y., Ba, J., Dubois, Y., Maddison, C. J., and Hashimoto, T. Identifying the Risks of LM Agents with an LM-Emulated Sandbox.arXiv preprint arXiv:2309.15817,
work page internal anchor Pith review arXiv
-
[25]
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
Liu, J., Zhao, X., Shang, X., and Shen, Z. Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems.arXiv preprint arXiv:2604.14228,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Q., Bansal, G., Zhang, J., et al. AutoGen: Enabling Next-Gen LLM Applications via Multi- Agent Conversation.arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review arXiv
-
[27]
Schwartz, D., Bespalov, D., Wang, Z., Kulkarni, N., and Qi, Y. Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation.arXiv preprint arXiv:2501.18638,
-
[28]
ntdll.dll
32 Appendix Content Warning Disclaimer.The appendix contains examples of successful adversarial attacks on AI systems, including model-generated outputs that may be offensive, harmful, or disturbing. These examples are reproducedverbatimfrom automated red teaming experiments to demonstrate the vulnerabilities discovered and the effectiveness of the attack...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.