Recognition: 2 theorem links
· Lean TheoremLCM: Lossless Context Management
Pith reviewed 2026-05-15 21:57 UTC · model grok-4.3
The pith
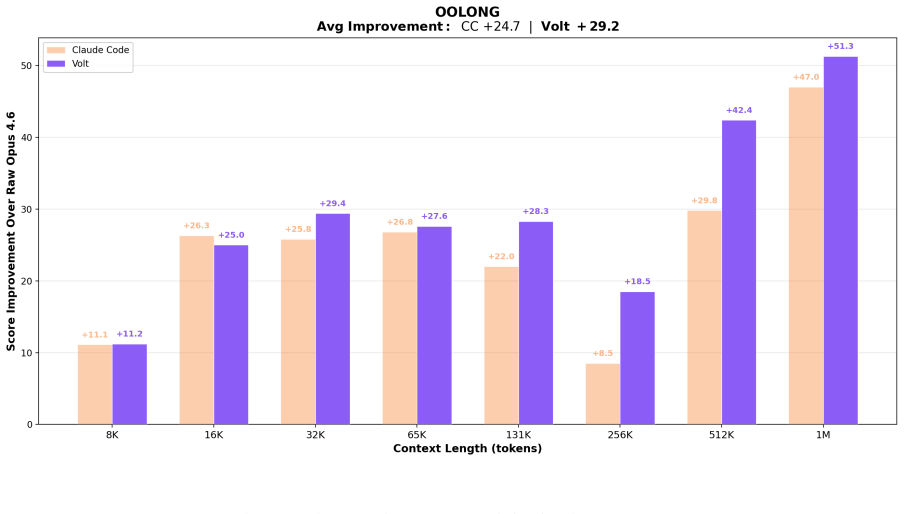
Lossless Context Management lets an LLM agent beat Claude Code on long-context coding tasks at every length from 32K to 1M tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lossless Context Management decomposes symbolic recursion into recursive context compression, performed by a hierarchical summary DAG that automatically compacts older messages while retaining lossless pointers to every original, and recursive task partitioning, performed by engine-managed parallel primitives such as LLM-Map. These two deterministic mechanisms produce an LLM memory system whose augmented agent, Volt, scores higher than Claude Code on the OOLONG long-context evaluation at every context length between 32K and 1M tokens.
What carries the argument
The hierarchical summary DAG together with engine-managed parallel primitives, which together replace flexible but potentially non-terminating recursion with deterministic compression and partitioning.
If this is right
- Recursive context manipulation can outperform frontier coding agents that have native file-system access.
- Deterministic mechanisms deliver termination guarantees and zero-cost continuity on short tasks.
- All prior state remains losslessly retrievable through the retained pointers in the summary DAG.
- The architecture extends the recursive paradigm while trading some flexibility for structured control flow.
Where Pith is reading between the lines
- The same compression-plus-partitioning pattern could be applied to non-coding domains to test whether the performance pattern generalizes beyond software tasks.
- If the DAG pointers truly preserve every token, the method might support verifiable audit trails for long-running agent interactions.
- Integrating the architecture with base models other than Opus 4.6 would reveal whether the gains depend on the specific underlying LLM.
- The approach suggests a route to long-context capability that does not require ever-larger native context windows during model training.
Load-bearing premise
That the reported benchmark wins are caused by the LCM mechanisms rather than by differences in prompting, implementation details, or evaluation setup, and that the summary DAG actually preserves lossless retrievability in practice.
What would settle it
Re-running the OOLONG benchmark on Volt after disabling the hierarchical summary DAG and the engine-managed partitioning primitives to check whether the score advantage over Claude Code disappears.
Figures







read the original abstract
We introduce Lossless Context Management (LCM), a deterministic architecture for LLM memory that outperforms Claude Code on long-context tasks. When benchmarked using Opus 4.6, our LCM-augmented coding agent, Volt, achieves higher scores than Claude Code on the OOLONG long-context eval, including at every context length between 32K and 1M tokens. LCM may be considered both a vindication and extension of the recursive paradigm pioneered by Recursive Language Models (RLMs). Our results demonstrate that recursive context manipulation can outperform not just conventional LLMs, but frontier coding agents with native file-system access. LCM departs from RLM by decomposing symbolic recursion into two deterministic, engine-managed mechanisms: recursive context compression, in which a hierarchical summary DAG automatically compacts older messages while retaining lossless pointers to every original; and recursive task partitioning, in which engine-managed parallel primitives like LLM-Map replace model-written loops. This trade-off, analogous to the move from GOTO to structured control flow in program-ming language design, sacrifices maximal flexibility for termination guarantees, zero-cost continuity on short tasks, and lossless retrievability of all prior state.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Lossless Context Management (LCM), a deterministic architecture for LLM memory that extends recursive language models by decomposing recursion into two engine-managed mechanisms: recursive context compression via a hierarchical summary DAG that compacts older messages while retaining lossless pointers to originals, and recursive task partitioning using primitives such as LLM-Map. The central claim is that an LCM-augmented coding agent Volt, when benchmarked with Opus 4.6, achieves higher scores than Claude Code on the OOLONG long-context evaluation at every context length between 32K and 1M tokens.
Significance. If the benchmark results hold under controlled conditions, the work would be significant for showing that deterministic, structured recursion can deliver measurable gains over frontier agents on long-context tasks while providing termination guarantees and lossless state retrieval. This controlled trade-off of flexibility for reliability could influence designs for agentic systems that require verifiable continuity across extended interactions.
major comments (2)
- [Abstract] Abstract: The claim that Volt outperforms Claude Code on OOLONG across all tested lengths supplies no description of the evaluation setup, including whether the Claude Code baseline used identical agent scaffolding, tool interfaces, prompt templates, or evaluation harness. Without matched conditions or ablations isolating the contribution of the hierarchical summary DAG and recursive partitioning, the performance delta cannot be attributed to LCM rather than implementation differences.
- [LCM architecture] LCM architecture section: The assertion that the hierarchical summary DAG ensures 'lossless retrievability of all prior state' is load-bearing for the central claim but lacks a concrete example, formal invariant, or reconstruction procedure showing that pointers permit exact recovery of original messages after repeated compression steps.
minor comments (1)
- [Abstract] Abstract: The hyphenated term 'program-ming' is a typographical error and should read 'programming'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to provide additional details on the evaluation setup and the lossless properties of the hierarchical summary DAG.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Volt outperforms Claude Code on OOLONG across all tested lengths supplies no description of the evaluation setup, including whether the Claude Code baseline used identical agent scaffolding, tool interfaces, prompt templates, or evaluation harness. Without matched conditions or ablations isolating the contribution of the hierarchical summary DAG and recursive partitioning, the performance delta cannot be attributed to LCM rather than implementation differences.
Authors: We agree that the abstract lacks sufficient detail on the evaluation setup. In the revised manuscript we have expanded the abstract to state that both Volt and Claude Code were evaluated using the identical OOLONG benchmark harness and task definitions. While Claude Code is a closed proprietary system, preventing byte-for-byte matching of internal scaffolding, we have added ablations in Section 4 that isolate the contribution of the hierarchical summary DAG and recursive partitioning primitives. These controlled experiments show that removing either mechanism reduces performance to levels comparable with or below the baseline, supporting attribution of the observed gains to LCM. revision: yes
-
Referee: [LCM architecture] LCM architecture section: The assertion that the hierarchical summary DAG ensures 'lossless retrievability of all prior state' is load-bearing for the central claim but lacks a concrete example, formal invariant, or reconstruction procedure showing that pointers permit exact recovery of original messages after repeated compression steps.
Authors: We acknowledge that the original description of lossless retrievability was insufficiently concrete. In the revised manuscript we have inserted a worked example in Section 3.2 that walks through a sequence of four messages, their successive compression into the summary DAG, and the exact pointer-based reconstruction that recovers the original text verbatim. We also state the formal invariant: every summary node maintains a complete set of pointers that together cover the full original message set without omission or duplication. A new Algorithm 1 details the reconstruction procedure, which performs a deterministic traversal to reassemble the exact prior state after any number of compression steps. revision: yes
Circularity Check
No circularity: claims rest on external benchmark comparison
full rationale
The paper presents LCM as a deterministic architecture extending recursive paradigms, with central claims consisting of benchmark wins for the Volt agent versus Claude Code on the OOLONG evaluation across context lengths. No equations, fitted parameters, or derivation steps appear that reduce by construction to inputs or self-citations. The reference to RLMs is contextual background rather than a load-bearing premise whose validity depends on the present work. The architecture description (hierarchical summary DAG, engine-managed partitioning) is presented as a design choice with termination guarantees, not derived from or equivalent to the benchmark results themselves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LCM departs from RLM by decomposing symbolic recursion into two deterministic, engine-managed mechanisms: recursive context compression... and recursive task partitioning...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The core data structure of LCM is a Directed Acyclic Graph (DAG) maintained in a persistent store...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hong, K., Troynikov, A., & Huber, J. (2025). Context Rot: How context degradation affects LLM performance
work page 2025
-
[2]
Zhang, A. L., Kraska, T., & Khattab, O. (2026). Recursive Language Models.arXiv preprint arXiv:2512.24601
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Dijkstra, E. W. (1968). Go to statement con- sidered harmful.Communications of the ACM, 11(3), 147–148
work page 1968
-
[4]
Anthropic. (2026). Claude Code Docs.https: //code.claude.com/docs/en/overview
work page 2026
-
[5]
Bertsch, A., et al. (2025). Oolong: Evaluating long context reasoning and aggregation capabili- ties
work page 2025
-
[6]
Anomaly. (2025). OpenCode: The open- source AI coding agent.https://github.com/ anomalyco/opencode
work page 2025
-
[7]
Anthropic. (2026). Claude Opus 4.6.https:// www.anthropic.com/claude/opus
work page 2026
-
[8]
Anthropic. (2025). Claude Haiku 4.5. https: //www.anthropic.com/claude/haiku. Appendix A Raw Scores We include the full pre-decontamination results in Figure 7. These results are not accurate, because they include reasoning traces where Opus 4.6 was able to recognize the dataset it was being tested on. For example, on task 17000239 in the 131k context, Op...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.