Recognition: unknown
Improving Medical VQA through Trajectory-Aware Process Supervision
Pith reviewed 2026-05-10 17:13 UTC · model grok-4.3
The pith
A reward based on the similarity of reasoning trajectories improves medical visual question answering models beyond exact answer matching alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
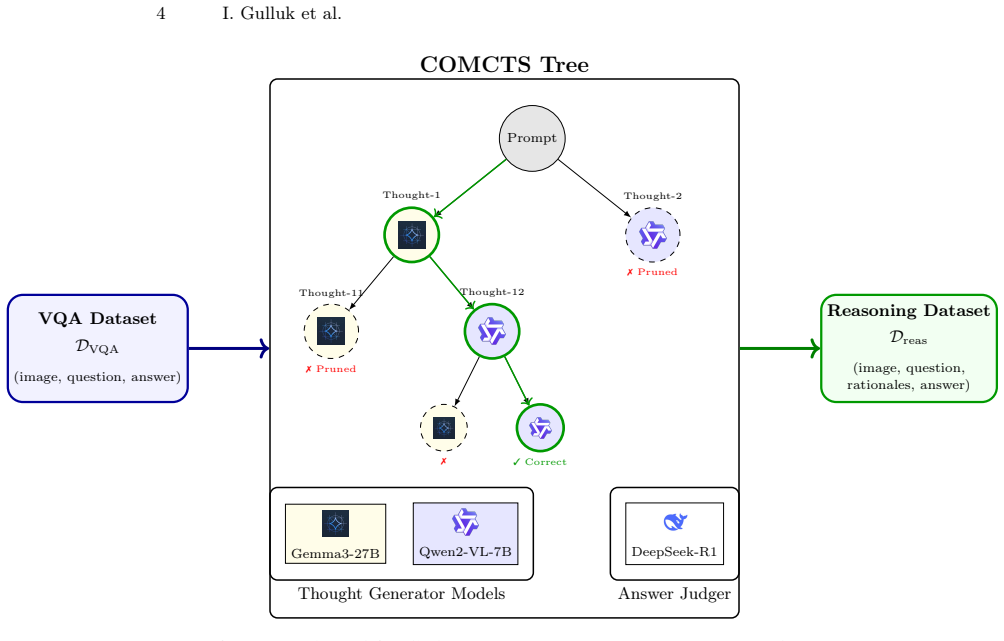
The authors generate reasoning trajectories for six medical VQA benchmarks using the COMCTS algorithm and an LLM judge, then train vision-language models with supervised fine-tuning followed by Group Relative Policy Optimization. The novel element is a process reward that combines exact-match scoring on the final answer with the dynamic time warping distance between sentence-transformer embeddings of the generated reasoning steps and the ground-truth trajectories. This combined reward produces consistent gains over supervised fine-tuning alone across all six benchmarks.
What carries the argument
The DTW-based process reward that compares sequences of sentence-transformer embeddings of generated and ground-truth reasoning trajectories.
If this is right
- Medical VQA models reach higher mean accuracy when process rewards guide their reasoning paths.
- Semantic and sequence-based explanation metrics improve alongside answer correctness.
- Process supervision adds value on top of standard outcome-only rewards in vision-language model training.
- Generated reasoning trajectory datasets become reusable resources for further medical VQA work.
Where Pith is reading between the lines
- The same trajectory comparison method could be tested on non-medical VQA or other step-by-step reasoning domains where trajectory data can be generated.
- Swapping the sentence transformer for domain-specific medical embeddings might strengthen or weaken the DTW signal.
- The gains rest on the initial quality of the generated trajectories, so advances in trajectory generation would directly affect results.
- Scaling the approach to larger base models could reveal whether the process reward benefit grows with model capacity.
Load-bearing premise
That dynamic time warping distance between embedded reasoning steps supplies a training signal that actually improves the quality of medical reasoning.
What would settle it
Training the same models with only the exact-match reward and observing that accuracy, BERTScore, and ROUGE-L no longer improve over the supervised-fine-tuning baseline on the six benchmarks would falsify the value of the trajectory component.
Figures








read the original abstract
Reasoning capabilities are crucial for reliable medical visual question answering (VQA); however, existing datasets rarely include reasoning explanations. We address this by generating reasoning trajectories for six medical VQA benchmarks using the COMCTS algorithm with open-source vision-language models, with an LLM serving as the verification judge. Building on these generated datasets, we propose a two-stage training framework: supervised fine-tuning followed by Group Relative Policy Optimization (GRPO) with a novel process-based reward. While standard approaches rely solely on exact-match rewards for final answers, we introduce a trajectory-aware reward that measures the similarity between generated and ground-truth reasoning processes. Specifically, we embed reasoning steps using sentence transformers and compute the Dynamic Time Warping (DTW) distance between the resulting vector sequences. Experiments across six benchmarks demonstrate that combining the DTW-based process reward with exact-match reward consistently outperforms SFT-only training, raising mean accuracy from 0.598 to 0.689, mean BERTScore from 0.845 to 0.881, and mean ROUGE-L from 0.665 to 0.748. Our results highlight the importance of process supervision in training reasoning-capable medical VLMs. We make our code and generated reasoning datasets publicly available at https://anonymous.4open.science/r/MICCAI-R1-MED-VQA-code-B14B/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that generating reasoning trajectories for six medical VQA benchmarks via COMCTS (with LLM verification) enables a two-stage pipeline of SFT followed by GRPO using a combined reward (exact-match on final answers plus DTW distance on sentence-transformer embeddings of reasoning steps). This yields consistent gains over SFT-only baselines: mean accuracy rises from 0.598 to 0.689, BERTScore from 0.845 to 0.881, and ROUGE-L from 0.665 to 0.748. The authors release the generated datasets and code.
Significance. If the central result holds after addressing controls, the work provides evidence that trajectory-aware process rewards can enhance reasoning quality in medical VLMs beyond outcome-only supervision, with the public datasets offering a reusable resource for the community.
major comments (2)
- [Experiments] Experiments section: The reported comparisons are limited to SFT-only versus SFT+GRPO with the combined DTW+exact-match reward. No GRPO run using exact-match reward alone (on the identical SFT checkpoint) is presented, so the observed gains cannot be attributed specifically to the DTW trajectory signal rather than to GRPO optimization, training duration, or reward scaling.
- [§3] §3 (Trajectory Generation): The ground-truth trajectories are produced by the same class of open-source VLMs used in training and verified only by an LLM judge, with no reported human validation, inter-annotator agreement, or quality metrics. This leaves open whether the DTW signal reflects genuine reasoning quality or artifacts of the generation process.
minor comments (3)
- [Abstract] Abstract and §4: Mean improvements are stated without the number of random seeds, standard deviations, or statistical significance tests, making it difficult to assess robustness across the six benchmarks.
- [Method] Method: The relative weighting between the DTW and exact-match terms is treated as a free hyperparameter, yet no ablation or sensitivity analysis on this weighting is provided.
- [Related Work] Related Work: The positioning relative to prior process-supervision methods (e.g., in math or general VQA) could be expanded with more direct citations to recent GRPO or trajectory-reward papers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point-by-point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported comparisons are limited to SFT-only versus SFT+GRPO with the combined DTW+exact-match reward. No GRPO run using exact-match reward alone (on the identical SFT checkpoint) is presented, so the observed gains cannot be attributed specifically to the DTW trajectory signal rather than to GRPO optimization, training duration, or reward scaling.
Authors: We agree that this ablation is necessary to isolate the contribution of the DTW-based process reward. In the revised manuscript, we will add results from an additional GRPO training run that uses only the exact-match reward on the identical SFT checkpoint. This will enable a direct comparison and clarify whether the observed gains stem from the trajectory signal or from other factors such as the GRPO optimization itself. revision: yes
-
Referee: [§3] §3 (Trajectory Generation): The ground-truth trajectories are produced by the same class of open-source VLMs used in training and verified only by an LLM judge, with no reported human validation, inter-annotator agreement, or quality metrics. This leaves open whether the DTW signal reflects genuine reasoning quality or artifacts of the generation process.
Authors: We acknowledge this limitation. Section 3 describes the use of COMCTS with open-source VLMs followed by LLM verification to scale trajectory generation across six benchmarks. We did not perform human validation or report inter-annotator agreement. In the revision, we will expand §3 with a dedicated discussion of the verification methodology, explicitly note the lack of human evaluation as a limitation, and report additional automatic quality metrics on the released trajectories (such as length statistics, embedding-based consistency, and diversity). The public release of the datasets will also allow the community to conduct further validation. revision: partial
Circularity Check
No circularity: empirical reward definition and results do not reduce to inputs by construction
full rationale
The paper's chain consists of (1) independent generation of reasoning trajectories via COMCTS + LLM judge on external benchmarks, (2) definition of a DTW process reward using a separate sentence-transformer embedding model, and (3) empirical comparison of combined reward vs. SFT-only. None of these steps is self-definitional, a fitted input renamed as prediction, or dependent on a load-bearing self-citation. The DTW distance is computed from externally generated references and an off-the-shelf embedder; the reported accuracy/BERTScore/ROUGE gains are experimental outcomes, not quantities forced by the training objective itself. Missing ablations are a methodological limitation but do not create circularity under the specified criteria.
Axiom & Free-Parameter Ledger
free parameters (2)
- reward weighting between DTW and exact-match
- GRPO and SFT training hyperparameters
axioms (3)
- domain assumption COMCTS with open-source VLMs can produce useful reasoning trajectories for medical VQA questions
- domain assumption An LLM can reliably judge the quality of generated reasoning trajectories
- domain assumption Sentence transformer embeddings plus DTW distance capture semantically meaningful similarity between reasoning processes
Forward citations
Cited by 1 Pith paper
-
LiteMedCoT-VL: Parameter-Efficient Adaptation for Medical Visual Question Answering
LiteMedCoT-VL distills chain-of-thought from a 235B model to 2B VLMs via LoRA, reaching 64.9% accuracy on PMC-VQA and beating a 4B zero-shot baseline by 11 points.
Reference graph
Works this paper leans on
- [1]
-
[2]
Ben Abacha, A., Hasan, S.A., Datla, V.V., Demner-Fushman, D., Müller, H.: Vqa-med: Overview of the medical visual question answering task at imageclef
-
[3]
9-12 September 2019 (2019)
In: Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes. 9-12 September 2019 (2019)
2019
-
[4]
Huatuogpt-o1, towards medical complex reasoning with llms
Chen,J.,Cai,Z.,Ji,K.,Wang,X.,Liu,W.,Wang,R.,Hou,J.,Wang,B.:Huatuogpt- o1, towards medical complex reasoning with llms. arXiv preprint arXiv:2412.18925 (2024)
-
[5]
arXiv preprint arXiv:2410.20327 (2024)
Chen, X., Lai, Z., Ruan, K., Chen, S., Liu, J., Liu, Z.: R-llava: Improving med-vqa understanding through visual region of interest. arXiv preprint arXiv:2410.20327 (2024)
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2003.10286 (2020)
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020)
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, Y., Li, T., Lu, Q., Shao, W., He, J., Qiao, Y., Luo, P.: Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22170–22183 (2024)
2024
-
[9]
Mathprompter: Mathematical reasoning using large language models
Imani, S., Du, L., Shrivastava, H.: Mathprompter: Mathematical reasoning using large language models. arXiv preprint arXiv:2303.05398 (2023)
-
[10]
In: Proceedings of the AAAI conference on artificial intelligence
Kwon, T., Ong, K.T.i., Kang, D., Moon, S., Lee, J.R., Hwang, D., Sohn, B., Sim, Y., Lee, D., Yeo, J.: Large language models are clinical reasoners: Reasoning-aware diagnosis framework with prompt-generated rationales. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 18417–18425 (2024)
2024
-
[11]
Advances in neural information processing systems35, 26337–26349 (2022)
Lample, G., Lacroix, T., Lachaux, M.A., Rodriguez, A., Hayat, A., Lavril, T., Ebner, G., Martinet, X.: Hypertree proof search for neural theorem proving. Advances in neural information processing systems35, 26337–26349 (2022)
2022
-
[12]
Scientific data 5(1), 1–10 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5(1), 1–10 (2018)
2018
-
[13]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
2023
-
[14]
Liévin, V., Hother, C.E., Motzfeldt, A.G., Winther, O.: Can large language models reason about medical questions? Patterns5(3) (2024)
2024
-
[15]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Lin, W., Zhao, Z., Zhang, X., Wu, C., Zhang, Y., Wang, Y., Xie, W.: Pmc- clip: Contrastive language-image pre-training using biomedical documents. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 525–536. Springer (2023)
2023
-
[16]
In: 2021 14 I
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In: 2021 14 I. Gulluk et al. IEEE 18th international symposium on biomedical imaging (ISBI). pp. 1650–1654. IEEE (2021)
2021
-
[17]
arXiv preprint arXiv:2407.01791 (2024)
Lozano, A., Nirschl, J., Burgess, J., Gupte, S.R., Zhang, Y., Unell, A., Yeung-Levy, S.: {\mu}-bench: A vision-language benchmark for microscopy understanding. arXiv preprint arXiv:2407.01791 (2024)
-
[18]
arXiv preprint arXiv:2310.10080 , year=
Ma, Q., Zhou, H., Liu, T., Yuan, J., Liu, P., You, Y., Yang, H.: Let’s reward step by step: Step-level reward model as the navigators for reasoning. arXiv preprint arXiv:2310.10080 (2023)
-
[19]
Information retrieval for music and motion pp
Müller, M.: Dynamic time warping. Information retrieval for music and motion pp. 69–84 (2007)
2007
-
[20]
Advances in neural information processing systems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing systems35, 27730–27744 (2022)
2022
-
[21]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[22]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., et al.: Gemma 3 technical report. arXiv preprint arXiv:2503.19786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Nejm Ai1(3), AIoa2300138 (2024)
Tu, T., Azizi, S., Driess, D., Schaekermann, M., Amin, M., Chang, P.C., Carroll, A., Lau, C., Tanno, R., Ktena, I., et al.: Towards generalist biomedical ai. Nejm Ai1(3), AIoa2300138 (2024)
2024
-
[26]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[29]
Wu, C., Lin, W., Zhang, X., Zhang, Y., Wang, Y., Xie, W.: Pmc-llama: towards building open-source language models for medicine (2023)
2023
-
[30]
Journal of the American Medical Informatics Association31(9), 1833–1843 (2024)
Wu, C., Lin, W., Zhang, X., Zhang, Y., Xie, W., Wang, Y.: Pmc-llama: toward building open-source language models for medicine. Journal of the American Medical Informatics Association31(9), 1833–1843 (2024)
2024
-
[31]
Beyond the first error: Process reward models for reflective mathematical reasoning
Yang, Z., He, C., Shi, X., Li, L., Yin, Q., Deng, S., Jiang, D.: Beyond the first error: Process reward models for reflective mathematical reasoning. arXiv preprint arXiv:2505.14391 (2025)
-
[32]
Yao, H., Huang, J., Wu, W., Zhang, J., Wang, Y., Liu, S., Wang, Y., Song, Y., Feng, H., Shen, L., et al.: Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search. arXiv preprint arXiv:2412.18319 (2024) Improving Medical VQA through Trajectory-Aware Process Supervision 15
-
[33]
Advances in neural information processing systems36, 11809–11822 (2023)
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., Narasimhan, K.: Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems36, 11809–11822 (2023)
2023
-
[34]
Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., et al.: Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915 (2023)
work page internal anchor Pith review arXiv 2023
-
[35]
arXiv preprint arXiv:2305.10415 , year=
Zhang, X., Wu, C., Zhao, Z., Lin, W., Zhang, Y., Wang, Y., Xie, W.: Pmc-vqa: Visual instruction tuning for medical visual question answering. arXiv preprint arXiv:2305.10415 (2023)
-
[36]
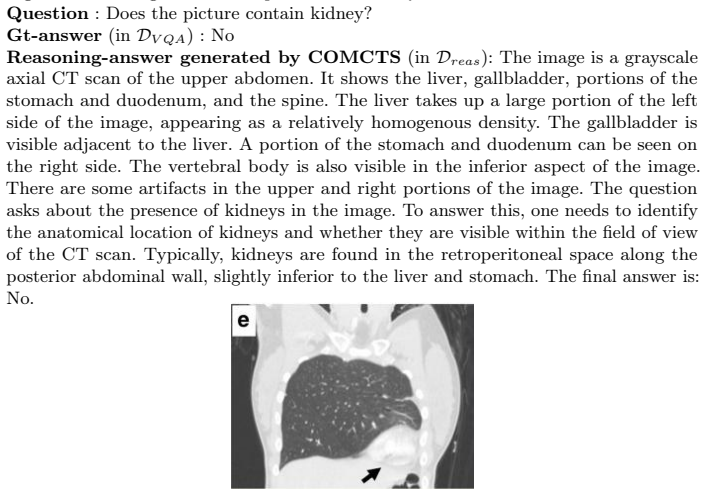
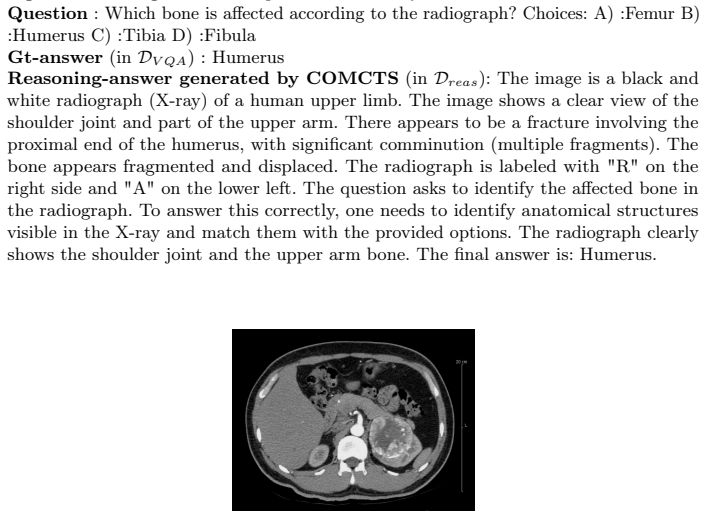
Zhang, Z., Zheng, C., Wu, Y., Zhang, B., Lin, R., Yu, B., Liu, D., Zhou, J., Lin, J.: The lessons of developing process reward models in mathematical reasoning. arXiv preprint arXiv:2501.07301 (2025) 16 I. Gulluk et al. Appendix .1 COMCTS Examples Fig.4: COMCTS generated sample from VQA-RAD. Question: What are the hyperdense lesions noted at the edges of ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.