Recognition: 2 theorem links
Frontier Lag: A Bibliometric Audit of Capability Misrepresentation in Academic AI Evaluation
Pith reviewed 2026-05-08 18:44 UTC · model grok-4.3
The pith
Academic LLM evaluations test models 10.85 ECI behind the frontier on average, with the lag widening and frequent overgeneralization to claims about AI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
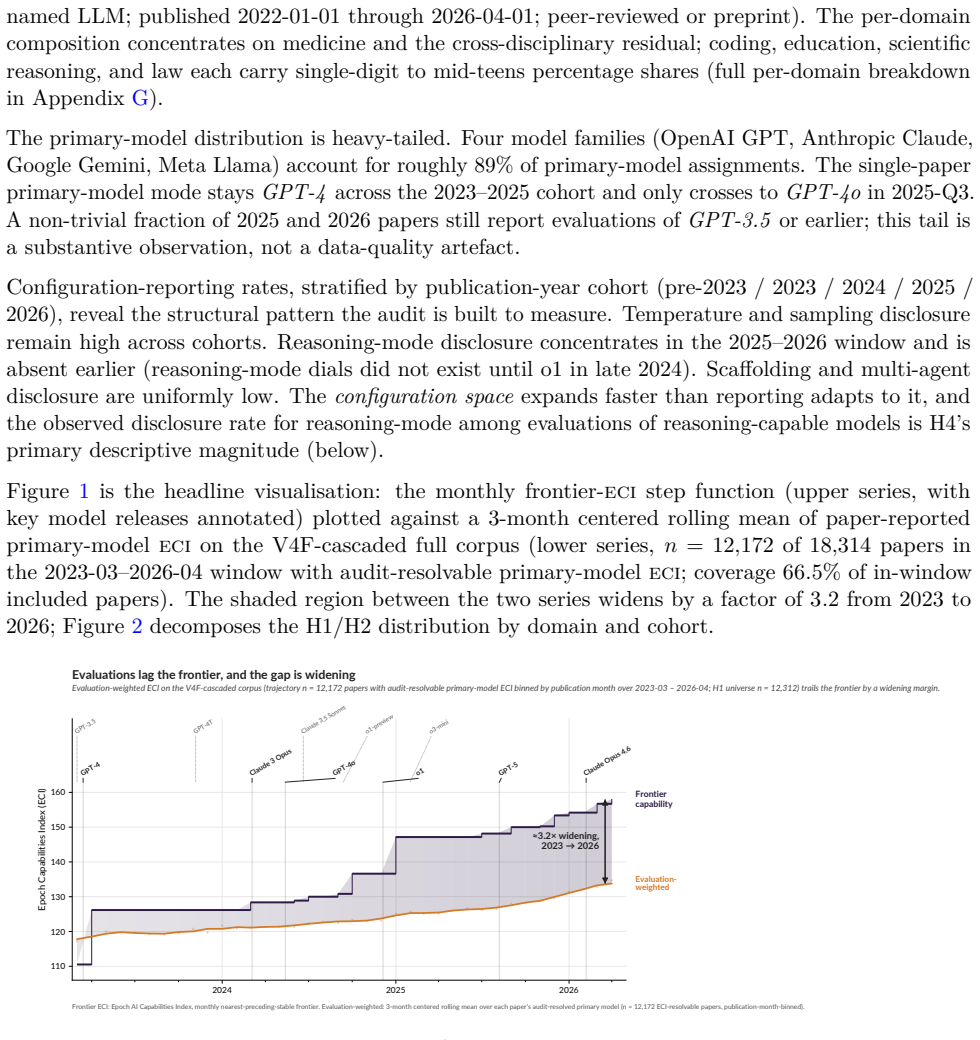
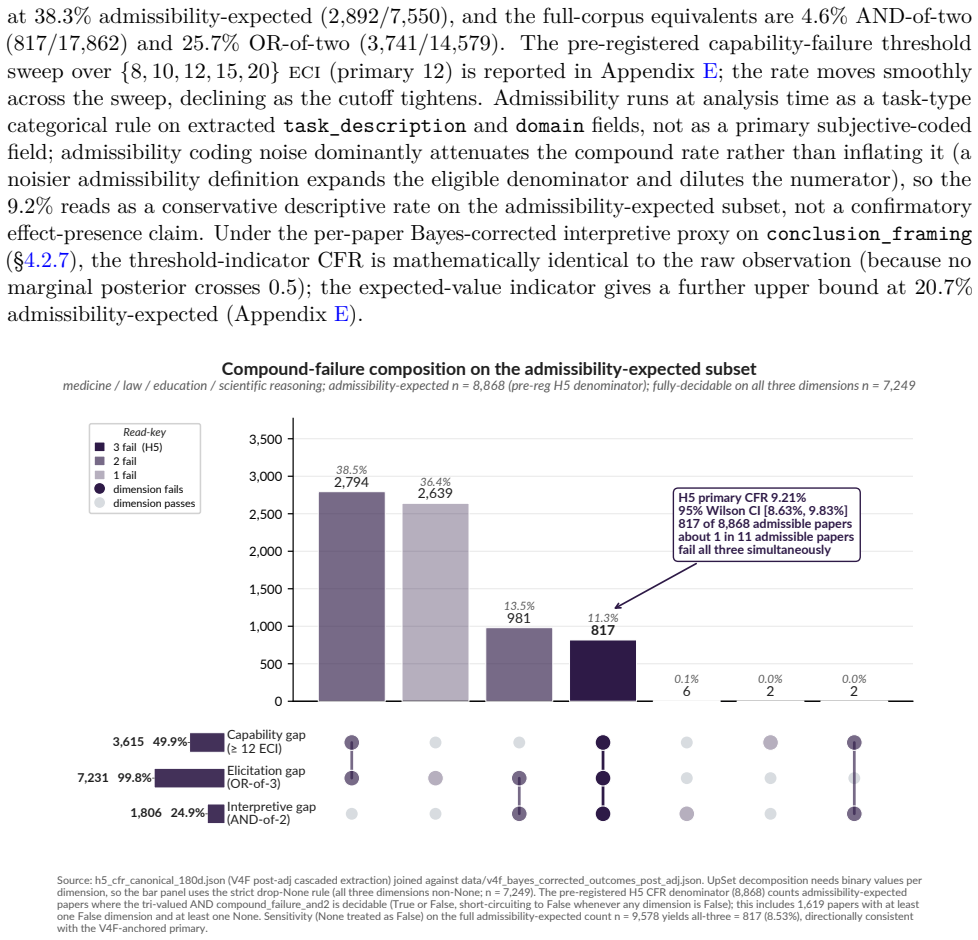
In a pre-registered bibliometric audit of 18,574 admissible papers, the median evaluation uses a model 10.85 ECI behind the contemporaneous frontier; the gap widens at 5.53 ECI per year. Only 3.2 percent of abstracts disclose reasoning-mode status, and 52.5 percent state conclusions at the level of AI rather than the evaluated model.
What carries the argument
The publication elicitation gap, defined as the difference between the capabilities of the model actually tested in a paper and the frontier capabilities available at the time of evaluation, quantified via the reproduced Epoch AI Capabilities Index.
If this is right
- Citations and policy documents that draw on this literature inherit systematically outdated capability estimates.
- Media and public discourse about AI progress are fed by reports that understate what current systems can do.
- Remedies such as API subsidies and mandatory configuration checklists would shrink the gap by reducing both latency and excess lag.
- The 75 percent excess-lag component implies that most of the delay is not explained by normal peer-review timelines.
Where Pith is reading between the lines
- If the pattern holds, training new models on the basis of published evaluations risks chasing capabilities that are already obsolete.
- Journals could reduce the problem by requiring authors to report the exact model snapshot and elicitation details as a condition of acceptance.
- The rising rate of AI-level claims suggests that the misrepresentation effect itself is accelerating.
Load-bearing premise
The keyword-sampled set of papers and the reproduced ECI rankings accurately reflect the broader LLM evaluation literature and the relative ordering of models at each past date.
What would settle it
A re-run of the audit on a fresh random sample of papers using an independently maintained frontier index that shows the median lag has shrunk below 5 ECI or reversed sign.
Figures




read the original abstract
Readers of applied-domain LLM capability evaluations want to know what AI systems can currently do. That literature answers a related, but consequentially different, question: what older, cheaper, less-elicited models could do months or years earlier (a 2026 paper evaluating GPT-4o-mini zero-shot, say, against a frontier of reasoning-capable, tool-using systems like GPT-5.5 Pro and Claude Opus 4.7), often reported with sparse configuration details and abstracted upward into claims about "AI" that propagate through citations, media, and policy. We measure the 'publication elicitation gap' (the gap between these answers) in a pre-registered audit of 112,303 LLM-keyword-matched candidate records (2022-01 to 2026-04; 18,574 admissible, 4,766 full-paper texts retrievable), comparing tested models to the contemporaneous frontier on the Epoch AI Capabilities Index (ECI), reproduced under Arena Elo and Artificial Analysis. The median paper evaluates a model +10.85 ECI (~1.4x the distance between Claude Sonnet 3.7 and Claude Opus 4.5) behind the contemporaneous frontier at evaluation time (H1); an exploratory rational-lag baseline (H8) decomposes this into ~25% peer-review latency, ~75% excess lag. The gap is widening at +5.53 ECI/year (H2; 95% CI [+5.03, +5.83]). Meanwhile, only 3.2% of abstracts (21.2% of full-texts) disclose reasoning-mode status on reasoning-capable models (H4) and 52.5% (95% CI [48.2, 56.9]) state conclusions at the level of "AI" rather than the evaluated model(s), rising at OR = 1.23/year. Proposed remedies include API-access subsidies and editorial enforcement of reporting frameworks mandating configuration-surface disclosure (model snapshot, reasoning mode/effort, tool access, scaffolding, prompting, etc.); VERSIO-AI is a 13-item checklist (Core 3 desk-reject) extending existing frameworks at the elicitation surface, with per-DOI analysis at frontierlag.org.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a pre-registered bibliometric audit of 112,303 LLM-keyword-matched records (2022-01 to 2026-04), yielding 18,574 admissible papers and 4,766 full texts. It claims the median paper evaluates a model +10.85 ECI behind the contemporaneous frontier (H1), with the gap widening at +5.53 ECI/year (H2; 95% CI [+5.03, +5.83]). Only 3.2% of abstracts disclose reasoning-mode status, 52.5% state conclusions at the 'AI' level (rising at OR=1.23/year), and an exploratory decomposition attributes ~75% of the lag to excess delay beyond peer review. Remedies include API subsidies and the 13-item VERSIO-AI checklist.
Significance. If the central measurements hold, the work documents a systematic mismatch between evaluated models and frontier capability in the applied LLM literature, with direct implications for citation chains, media reporting, and policy. Strengths include the pre-registered protocol, large corpus size, reported confidence intervals, use of an external index (reproduced ECI), and a concrete checklist proposal with per-DOI analysis at frontierlag.org. These elements provide a falsifiable empirical baseline that could inform editorial standards.
major comments (3)
- [Abstract / Data collection] Abstract and implied Methods: the keyword matching rules, exact admissibility criteria that reduce 112,303 records to 18,574 admissible papers, and the procedure for assigning ECI scores to each paper's tested models are not specified. These details are load-bearing for H1 and H2, as any systematic under-sampling of near-frontier evaluations would directly affect the reported median lag and trend.
- [ECI assignment and timestamp handling] Abstract and ECI reproduction description: no information is given on how evaluation timestamps are determined for each paper (publication date vs. actual experiment date), how Arena Elo and Artificial Analysis are combined to reproduce the Epoch index, or any validation of frontier identification at paper-specific times. The +10.85 ECI median and +5.53 ECI/year trend rest on accurate historical frontier assignment.
- [H8 rational-lag baseline] H8 exploratory baseline: the decomposition of the lag into ~25% peer-review latency and ~75% excess lag is presented without the underlying data, model, or sensitivity checks, yet it is used to interpret the main findings. This requires explicit methods and robustness tests to support the claim.
minor comments (3)
- [Abstract] The abstract states '2026-04' as the end date while the study period begins in 2022; clarify whether this is a typo for 2024 or an intentional forward-looking cutoff.
- [Introduction / Methods] Define 'ECI' and its scaling on first use; the parenthetical '~1.4x the distance between Claude Sonnet 3.7 and Claude Opus 4.5' is helpful but should be tied to an explicit equation or table in the main text.
- [Proposed remedies] The VERSIO-AI checklist is introduced as extending existing frameworks; provide a side-by-side comparison table with prior checklists (e.g., those referenced) to clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review, which highlights important areas for improving methodological transparency. We agree that the abstract and methods sections would benefit from greater explicitness regarding data collection, ECI assignment, and the H8 baseline to better support H1 and H2. We will make the revisions described below in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Data collection] Abstract and implied Methods: the keyword matching rules, exact admissibility criteria that reduce 112,303 records to 18,574 admissible papers, and the procedure for assigning ECI scores to each paper's tested models are not specified. These details are load-bearing for H1 and H2, as any systematic under-sampling of near-frontier evaluations would directly affect the reported median lag and trend.
Authors: The full Methods section of the manuscript (including the pre-registered protocol) specifies the keyword matching rules and the exact admissibility criteria applied to reduce the initial 112,303 records to 18,574 admissible papers. The ECI assignment procedure for tested models is also described in the ECI reproduction subsection. However, we acknowledge that these details are insufficiently prominent in the abstract and early methods overview. In revision we will add a concise summary of the keyword rules, admissibility filters, and model-to-ECI mapping steps to both the abstract and a new dedicated paragraph in Methods. This will make the load-bearing elements immediately verifiable without altering the reported results. revision: yes
-
Referee: [ECI assignment and timestamp handling] Abstract and ECI reproduction description: no information is given on how evaluation timestamps are determined for each paper (publication date vs. actual experiment date), how Arena Elo and Artificial Analysis are combined to reproduce the Epoch index, or any validation of frontier identification at paper-specific times. The +10.85 ECI median and +5.53 ECI/year trend rest on accurate historical frontier assignment.
Authors: Publication dates serve as the timestamp for frontier assignment because experiment dates are almost never reported in the sampled literature; we will explicitly state this proxy choice and its known limitations in the revised Methods. The combination of Arena Elo and Artificial Analysis to reproduce the Epoch ECI is already detailed in the ECI reproduction section (including normalization and weighting steps), but we will add a validation subsection that compares our reproduced frontier values against Epoch's published historical snapshots at multiple sampled dates. These clarifications will directly support the median lag and trend estimates without changing the numerical results. revision: yes
-
Referee: [H8 rational-lag baseline] H8 exploratory baseline: the decomposition of the lag into ~25% peer-review latency and ~75% excess lag is presented without the underlying data, model, or sensitivity checks, yet it is used to interpret the main findings. This requires explicit methods and robustness tests to support the claim.
Authors: H8 is presented as exploratory and relies on a simple rational-lag model that compares publication dates to model-release timelines to estimate the peer-review versus excess-lag split. We agree that the underlying assumptions, data sources, and sensitivity analyses are not sufficiently documented. In the revision we will add the full model specification, the exact data sources used for the ~25%/~75% decomposition, and report sensitivity checks under alternative peer-review latency assumptions. If any component of the baseline cannot be fully reproduced from the existing corpus, we will explicitly note this as a limitation of the exploratory analysis. revision: partial
Circularity Check
No circularity: direct empirical measurement against external index
full rationale
This is a bibliometric audit that samples 112,303 keyword-matched records, filters to 18,574 admissible papers, and computes median lag (+10.85 ECI) and trend (+5.53 ECI/year) by comparing each paper's tested model(s) to the contemporaneous frontier on the reproduced Epoch AI Capabilities Index. The central quantities are statistical summaries of observed data against an external benchmark (Arena Elo + Artificial Analysis); no equations, fitted parameters, or derivations are defined in terms of the reported lag itself. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the measurement procedure. The study is therefore self-contained against its external index and sampling frame.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Epoch AI Capabilities Index (ECI) provides a reliable, contemporaneous ranking of model capabilities.
- domain assumption Keyword-matched records from 2022-2026 accurately represent academic LLM evaluation papers.
Reference graph
Works this paper leans on
-
[1]
255-paper audit of GPT-3.5/GPT-4 ChatGPT-interface studies; 4.7M contaminated samples catalogued; nearest structural ancestor to this paper. Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chunyang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, Davide Fucci, Junda He, Christoph Treude, Marcos Kalino...
2026
-
[2]
Thirty-six-author systematic review of445LLM benchmarks from leading conferences; eight design recommendations targeting benchmark construct validity. Andrew M Bean, Rebecca Elizabeth Payne, Guy Parsons, Hannah Rose Kirk, Juan Ciro, Rafael Mosquera-Gómez, Sara Hincápié M, Aruna S Ekanayaka, Lionel Tarassenko, Luc Rocher, and Adam Mahdi. Reliability of LLM...
-
[3]
Competitive-comparison table corroborating the Opus 4.6 Thinking Max SWE-Bench-Verified baseline; accessed 2026-04-23. David Gringras. frontierlag: A python package for auditing the capability gap of published AI evaluations. Python Package Index (PyPI), 2026a. URLhttps://pypi.org/project/frontierlag/ 0.1.0/. Released 2026-04-16 under MIT license; live we...
work page doi:10.3348/kjr 2026
-
[4]
The STARD-AI Reporting Guideline for Di- agnostic Accuracy Studies Using Artificial Intelligence
Methodological template closest to the present audit: construct-named corpus audit of a capability-or-safety claim class, with code and reporting-discipline remedy. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt forma...
-
[5]
URL https://www.aisi.gov.uk/frontier-ai-trends-report. First public evidence-based assessment aggregating two years of AISI’s frontier model testing (November 2023 through October 2025); cited for the frontier-trajectory reframe of capability evaluation. Baptiste Vasey, Myura Nagendran, others, and DECIDE-AI Expert Group. Reporting guideline for the early...
-
[6]
Model version, to the exact identifier the provider exposes
-
[7]
Provider and access method
-
[8]
Block B: Tier and comparator context
Access or evaluation date window. Block B: Tier and comparator context
-
[9]
Within-family tier and rationale for tier selection
-
[10]
Declared capability frame (frontier / deployment / tier-specific), coherent with the tier identified under Item 1. 42
-
[11]
Block C: Configuration and elicitation
Comparator presence, type, and version (human experts, baseline LLMs with full configuration disclosed, non-LLM baselines, historical controls, or none stated). Block C: Configuration and elicitation
-
[12]
Reasoning mode status, where applicable
-
[13]
Reasoning effort or thinking budget, where applicable
-
[14]
Tool use and retrieval
-
[15]
Scaffolding, agent framework, and multi-turn structure
-
[16]
Block D: Evaluation and interpretation
Prompting strategy. Block D: Evaluation and interpretation
-
[17]
Sampling parameters and number of runs per item
-
[18]
models which are highly specialized may receive loweciscores, despite being very capable within their domain
Conclusion–evidence concordance and valence-conditional caveats. Full text of each item, including rationale, good example, and bad example, appears in the standalone versio-aiv1.2 specification. Note on weighted composites: a weighted Elicitation Completeness composite over Items 7–11 is exposed by the companionfrontierlagtool as an optional derived scor...
2024
-
[19]
All systems exhibitX
Determiner-headed collectives are anaphoric, not generic.“All systems exhibitX” with prior named models is an anaphoric reference; code asmodel_specific. Contrast with bare plural “LLMs exhibitX” as generic
-
[20]
Commercial LLMs,
Modifier-bounded generic terms remain generic.“Commercial LLMs,” “open-source LLMs,” “reasoning-capable LLMs” are still generic subjects; code asai_generic
-
[21]
LLMs like ChatGPT-4,
Hedged-generic constructions keep the generic term as subject.“LLMs like ChatGPT-4,” “AI tools such as Claude” are generic subjects with an illustrative modifier; code asai_generic
-
[22]
The LLM tested,
Definite-specifier singulars are specific.“The LLM tested,” “the evaluated system” refer to the tested instance; code asmodel_specific
-
[23]
AI could become...,
Forward-projection and implication sentences with generic subjects count as findings. “AI could become...,” “LLMs may be ready...,” and implication sentences with generic subjects triggerai_generic
-
[24]
LLM-based methods
Category descriptors vs named artefacts.“LLM-based methods” is a class-level claim (ai_generic) unless the subject is a named artefact (“LogReader,” “our RAG pipeline”), which is model_specific. Dev-set stability metrics Two temperature-0 runs on the 600-paper development set, executed in parallel at concurrency 30 with wall time∼83seconds per run, yield ...
2023
-
[25]
Table S5: Positive exemplars cleared on a scope-bounded reading ofversio-aiv1.2
plus three or more items from{3, 6, 9, 10, 11}, with the declared frame in Item 5 coherent with the tier identified in Item 1 at the abstract level (the layer downstream consumers actually read). Table S5: Positive exemplars cleared on a scope-bounded reading ofversio-aiv1.2. One entry per pre-registered domain with a clearing candidate; education is disc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.