Recognition: unknown
Agent Island: A Saturation- and Contamination-Resistant Benchmark from Multiagent Games
Pith reviewed 2026-05-08 17:03 UTC · model grok-4.3
The pith
Language model agents playing a multiplayer game of cooperation, conflict and persuasion create a dynamic benchmark that resists saturation and contamination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Agent Island, a multiplayer simulation environment in which language-model agents compete in a game of interagent cooperation, conflict, and persuasion. The environment yields a dynamic benchmark designed to mitigate both saturation and contamination; new models can always outperform the current leading player in this winner-take-all game, and agents compete against other adaptive agents rather than face a fixed task set. We rank players with a Bayesian Plackett-Luce model, allowing us to quantify uncertainty in player skill.
What carries the argument
The Agent Island multiplayer game environment together with Bayesian Plackett-Luce ranking applied to outcomes of a winner-take-all competition among adaptive agents.
If this is right
- New models can be inserted into ongoing competitions and will displace the leader if they are stronger, so the benchmark never saturates.
- Agents always face adaptive opponents drawn from the current pool rather than memorized static tests, lowering contamination risk.
- Bayesian Plackett-Luce ranking supplies both a skill ordering and uncertainty estimates for each model.
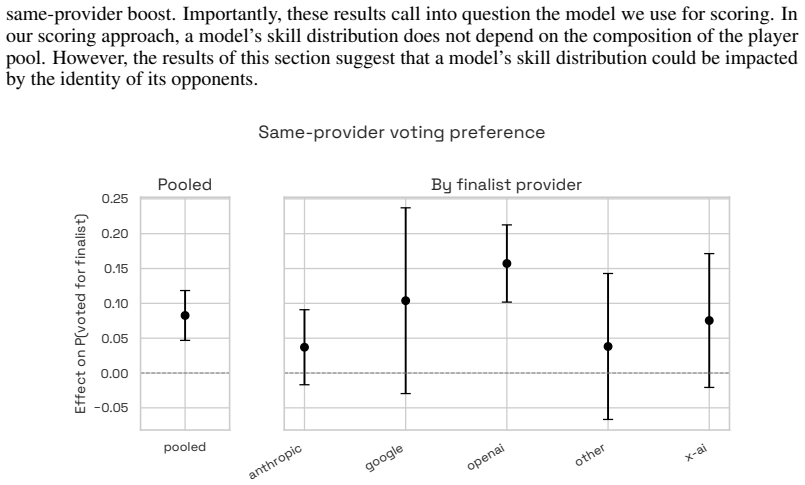
- Releasing the 999 game logs enables direct study of emergent behaviors such as same-provider voting preferences.
- The setup supports repeated, comparable evaluations as the model pool grows over time.
Where Pith is reading between the lines
- The same-provider preference observed in voting could be tested for robustness by varying game rules or adding explicit provider-agnostic instructions.
- If the game reliably tracks general capability, it could serve as a live testbed for studying how agents handle deception or coalition formation.
- Extending the environment to include asymmetric information or resource constraints might reveal whether current top models retain their advantage under altered conditions.
- Community re-ranking of the released logs with different priors would show how sensitive the reported ordering is to modeling choices.
Load-bearing premise
That results from this particular game of cooperation, conflict, and persuasion reliably measure general agent capabilities rather than simulation-specific behaviors that could be exploited or contaminated.
What would settle it
Finding that a model which performs strongly on conventional static benchmarks consistently ranks near the bottom of Agent Island games, or that a weak model ranks near the top, would indicate the game is measuring something other than general capability.
Figures

read the original abstract
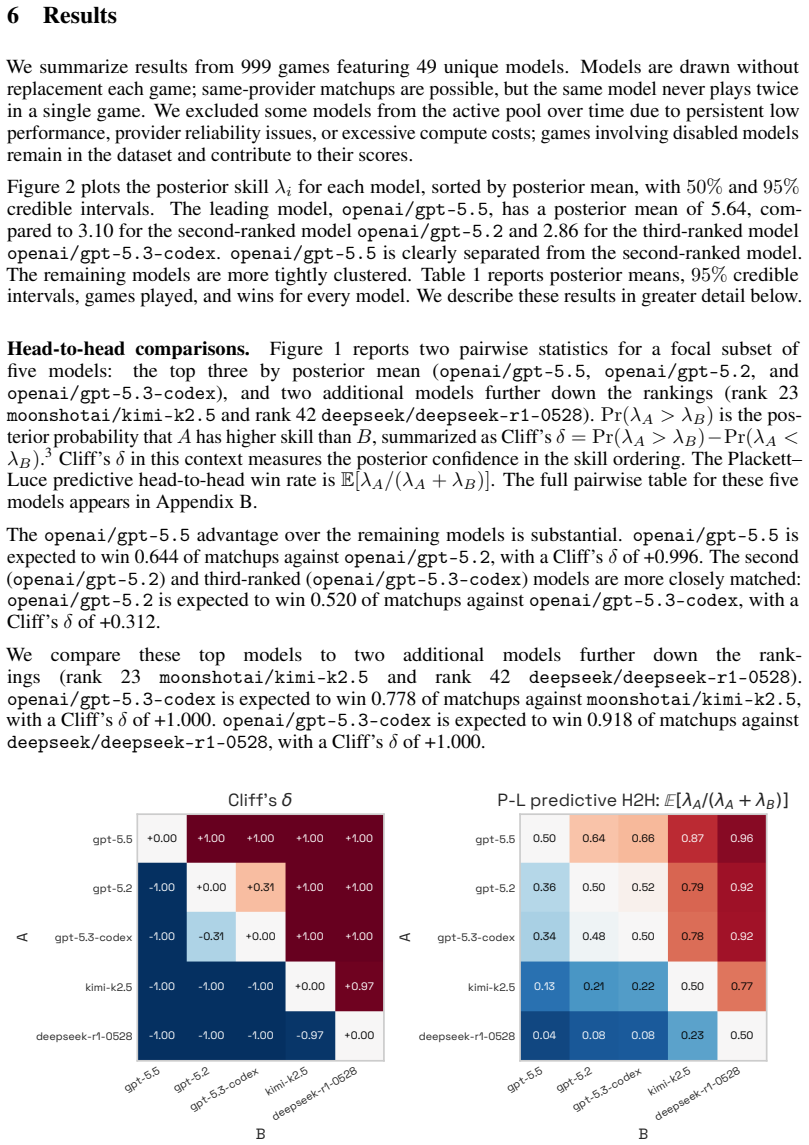
Static capabilities benchmarks suffer from saturation and contamination, making it difficult to track capabilities progress over time. We introduce Agent Island, a multiplayer simulation environment in which language-model agents compete in a game of interagent cooperation, conflict, and persuasion. The environment yields a dynamic benchmark designed to mitigate both saturation and contamination; new models can always outperform the current leading player in this winner-take-all game, and agents compete against other adaptive agents rather than face a fixed task set. We rank players with a Bayesian Plackett-Luce model, allowing us to quantify uncertainty in player skill. In 999 games involving 49 unique models, openai/gpt-5.5 dominates its peers with a posterior mean skill of 5.64, compared with 3.10 for the second-ranked model, openai/gpt-5.2, and 2.86 for the third-ranked model, openai/gpt-5.3-codex. We release the game logs as a dataset for analyses of model behavior. As an example, we investigate same-provider preference in final-round votes and find that models are 8.3 p.p. more likely to support a same-provider finalist than finalists from other providers. This preference is not uniform across providers: among separately estimated providers, the effect is strongest for OpenAI models and weakest for Anthropic models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent Island, a multiplayer simulation environment in which language-model agents compete in a game of interagent cooperation, conflict, and persuasion. It presents this as a dynamic benchmark to mitigate saturation and contamination in static capabilities tests, using a Bayesian Plackett-Luce model to rank 49 models from 999 games. The results show openai/gpt-5.5 dominating with posterior mean skill 5.64 (vs. 3.10 and 2.86 for the next two), and report an 8.3 p.p. same-provider voting preference in final rounds, with the game logs released as a dataset.
Significance. If the game outcomes reliably track transferable agent capabilities rather than simulation-specific artifacts, the winner-take-all adaptive design could provide a useful ongoing benchmark that evolves with new models and supplies public logs for behavioral analysis. The Bayesian ranking approach and same-provider bias finding are concrete contributions, but the significance is constrained by the absence of evidence linking performance to general capabilities.
major comments (3)
- [Abstract / Results] Abstract and results: The manuscript reports clear skill rankings and a same-provider preference but supplies no cross-validation or correlation analysis against established benchmarks (e.g., MMLU, GPQA, or other multi-agent tasks) to test whether game success reflects general capabilities rather than simulation-specific mechanics such as persuasion style or provider artifacts. This validation is load-bearing for the central claim that the benchmark resists contamination and measures transferable skills.
- [Methodology / Experimental Setup] Methodology: No details are given on the sampling procedure for the 999 games or the exact game rules (cooperation/conflict/persuasion mechanics), preventing assessment of whether the environment truly resists saturation via winner-take-all dynamics or allows new models to reliably outperform leaders. The abstract states the design intent but provides no empirical check or sensitivity analysis.
- [Results] Results: Although a Bayesian Plackett-Luce model is used to quantify uncertainty, the reported findings give only posterior means (5.64, 3.10, 2.86) with no credible intervals, variance estimates, or error analysis on the skill parameters, undermining confidence in the dominance claims and the 8.3 p.p. bias result.
minor comments (2)
- [Abstract] The abstract mentions releasing game logs as a dataset but does not specify the format, access method, or any accompanying documentation for reproducibility.
- [Methodology] Notation for the Bayesian model (e.g., how priors or the Plackett-Luce likelihood are defined) is not clarified in the provided summary, which could affect readers attempting to replicate the ranking.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript introducing Agent Island. We address each major point below, providing clarifications from the full paper and indicating revisions made to strengthen the presentation of the dynamic benchmark, Bayesian ranking, and empirical findings.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: The manuscript reports clear skill rankings and a same-provider preference but supplies no cross-validation or correlation analysis against established benchmarks (e.g., MMLU, GPQA, or other multi-agent tasks) to test whether game success reflects general capabilities rather than simulation-specific mechanics such as persuasion style or provider artifacts. This validation is load-bearing for the central claim that the benchmark resists contamination and measures transferable skills.
Authors: We agree that explicit cross-validation against static benchmarks like MMLU or GPQA would help substantiate claims of transferable skills. The manuscript's primary contribution is the introduction of a dynamic, winner-take-all multi-agent environment whose adaptive structure is designed to inherently resist saturation and contamination by pitting models against evolving opponents rather than fixed tasks. In the revised version, we have added a limitations subsection discussing the distinction between simulation-specific behaviors (e.g., persuasion tactics) and general capabilities, along with preliminary rank correlations against model scale and known performance tiers from public leaderboards. Full cross-validation experiments remain an important avenue for future work but were outside the scope of this initial benchmark paper. revision: partial
-
Referee: [Methodology / Experimental Setup] Methodology: No details are given on the sampling procedure for the 999 games or the exact game rules (cooperation/conflict/persuasion mechanics), preventing assessment of whether the environment truly resists saturation via winner-take-all dynamics or allows new models to reliably outperform leaders. The abstract states the design intent but provides no empirical check or sensitivity analysis.
Authors: The full manuscript details the game rules in Section 3, specifying the action space for cooperation (resource sharing), conflict (direct challenges), and persuasion (voting and negotiation rounds) with explicit state transitions and termination conditions. The 999 games were generated by randomly sampling groups of 4–6 agents from the 49-model pool, running each until a winner emerged or a round limit was reached. We have added a new experimental setup subsection with pseudocode for game sampling, a sensitivity analysis demonstrating ranking stability after ~500 games, and confirmation that the winner-take-all format permits new models to surpass current leaders in subsequent rounds. revision: yes
-
Referee: [Results] Results: Although a Bayesian Plackett-Luce model is used to quantify uncertainty, the reported findings give only posterior means (5.64, 3.10, 2.86) with no credible intervals, variance estimates, or error analysis on the skill parameters, undermining confidence in the dominance claims and the 8.3 p.p. bias result.
Authors: The Bayesian Plackett-Luce implementation computes full posterior distributions over skill parameters. The main text reported posterior means for brevity, but the supplementary materials and released dataset contain the complete posteriors. In the revision, we have updated the primary results table to include 95% credible intervals (e.g., gpt-5.5: [5.12, 6.17]) and added a figure of the posterior densities. For the same-provider bias, we now report the 8.3 p.p. estimate with its credible interval [5.2, 11.4] p.p. and a brief error analysis confirming statistical reliability. revision: yes
Circularity Check
No significant circularity in benchmark derivation
full rationale
The paper defines Agent Island directly as a new multiplayer simulation with winner-take-all dynamics and adaptive opponents; skill estimates are produced by applying a standard Bayesian Plackett-Luce model to the resulting game outcomes. No load-bearing claim reduces by construction to a fitted parameter, self-definition, or self-citation chain. Resistance to saturation and contamination is argued from the explicit game rules rather than from any renaming or smuggling of an ansatz. The derivation is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bayesian Plackett-Luce model produces reliable skill estimates and uncertainty from pairwise or multi-player game outcomes
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference , author=. 2024 , eprint=
2024
-
[2]
2025 , eprint=
A Rosetta Stone for AI Benchmarks , author=. 2025 , eprint=
2025
-
[3]
2023 , eprint=
Rethinking Benchmark and Contamination for Language Models with Rephrased Samples , author=. 2023 , eprint=
2023
-
[4]
2021 , eprint=
Dynabench: Rethinking Benchmarking in NLP , author=. 2021 , eprint=
2021
-
[5]
Terry , journal =
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
-
[6]
The Annals of Applied Statistics , number =
Fran. The Annals of Applied Statistics , number =. 2014 , doi =
2014
-
[7]
Survivor: Three principles of economics lessons as taught by a reality television show , urldate =
Dean Karlan , journal =. Survivor: Three principles of economics lessons as taught by a reality television show , urldate =
-
[8]
2024 , eprint=
SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents , author=. 2024 , eprint=
2024
-
[9]
2023 , eprint=
Generative Agents: Interactive Simulacra of Human Behavior , author=. 2023 , eprint=
2023
-
[10]
Bakhtin, Anton and Brown, Noam and Dinan, Emily and Farina, Gabriele and Flaherty, Colin and Fried, Daniel and Goff, Andrew and Gray, Jonathan and Hu, Hengyuan and Jacob, Athul Paul and Komeili, Mojtaba and Konath, Karthik and Kwon, Minae and Lerer, Adam and Lewis, Mike and Miller, Alexander H. and Mitts, Sasha and Renduchintala, Adithya and Roller, Steph...
2022
-
[11]
Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, Mojtaba Komeili, Karthik Konath, Minae Kwon, Adam Lerer, Mike Lewis, Alexander H. Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiyan Shi, Joe Spisak, Alexander Wei, David Wu, Hugh Zhan...
- [12]
-
[13]
Fran c ois Caron, Yee Whye Teh, and Thomas Brendan Murphy. Bayesian nonparametric Plackett–Luce models for the analysis of preferences for college degree programmes . The Annals of Applied Statistics, 8 0 (2): 0 1145 -- 1181, 2014. doi:10.1214/14-AOAS717. URL https://doi.org/10.1214/14-AOAS717
-
[14]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference, 2024. URL https://arxiv.org/abs/2403.04132
work page internal anchor Pith review arXiv 2024
-
[15]
A rosetta stone for ai benchmarks, 2025
Anson Ho, Jean-Stanislas Denain, David Atanasov, Samuel Albanie, and Rohin Shah. A rosetta stone for ai benchmarks, 2025. URL https://arxiv.org/abs/2512.00193
-
[16]
Survivor: Three principles of economics lessons as taught by a reality television show
Dean Karlan. Survivor: Three principles of economics lessons as taught by a reality television show. The Journal of Economic Education, 48 0 (3): 0 pp. 224--228, 2017. ISSN 00220485, 21524068. URL https://www.jstor.org/stable/48542336
-
[17]
arXiv:2104.14337 (2021), https://arxiv.org/abs/2104.14337
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. Dynabench: Rethinking benchmarking in nlp, 2021. URL https://arxiv....
-
[18]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023. URL https://arxiv.org/abs/2304.03442
work page internal anchor Pith review arXiv 2023
-
[19]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples, 2023. URL https://arxiv.org/abs/2311.04850
-
[20]
arXiv preprint arXiv:2310.11667 , year=
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. Sotopia: Interactive evaluation for social intelligence in language agents, 2024. URL https://arxiv.org/abs/2310.11667
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.