Recognition: unknown
Resilient AI Supercomputer Networking using MRC and SRv6
Pith reviewed 2026-05-08 16:54 UTC · model grok-4.3
The pith
MRC sprays AI training traffic across many paths so jobs keep running through network failures that used to stop them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
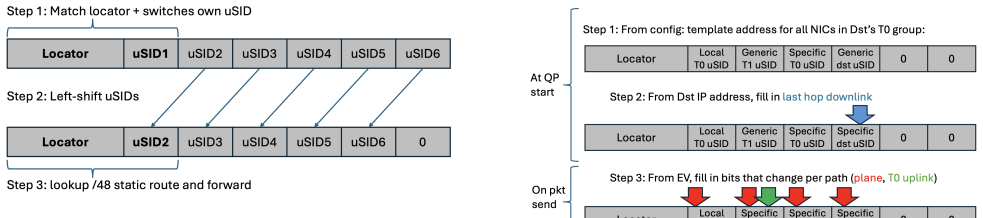
MRC is an RDMA-based transport that sprays packets across many paths and performs active load balancing between them to eliminate flow collisions. Combined with multi-plane Clos fabrics for physical redundancy and static SRv6 source routing that lets endpoints bypass failed elements, the system allows AI training jobs to ride out many network failures that previously interrupted training. The approach has been deployed in two of the world's largest training clusters and keeps synchronous pretraining jobs running at scales where tail latency otherwise dominates.
What carries the argument
MRC, the RDMA transport that sprays and load-balances across paths while using SRv6 for static source-routed failure bypass.
If this is right
- Synchronous pretraining jobs can keep all GPUs utilized during the majority of component failures instead of waiting for manual recovery or job restart.
- Two-tier multi-plane Clos networks become practical for clusters exceeding 100K GPUs while still providing enough redundancy to mask most failures.
- Operators no longer need to over-provision bandwidth solely to absorb the impact of tail latency from unlucky path collisions.
- Training software can remain unchanged because the resilience is provided entirely by the network and transport layer.
Where Pith is reading between the lines
- The same spraying-plus-SRv6 pattern could be tested on other collective-communication patterns such as inference serving or scientific simulations that also suffer from tail latency.
- If spraying increases the total number of packets in flight, buffer sizing and switch memory requirements may need to grow even if average link utilization stays the same.
- Long-term, the ability to bypass failures at the endpoint may reduce the pressure on network operators to achieve perfect switch reliability.
Load-bearing premise
The network failures seen in the two production clusters will remain representative when clusters grow much larger and that spraying traffic will not create new congestion or performance problems at those scales.
What would settle it
Run the same training workload on a cluster several times larger than the reported production deployments and record whether any single link or switch failure still causes the entire job to pause or lose progress.
Figures
















read the original abstract
Tail latency dominates the performance of synchronous pretraining jobs when running at very large scales. We describe a three-pronged approach: (1) a new RDMA-based transport protocol, MRC, sprays across many paths and actively load-balances between them, eliminating the issue of flow collisions (2) the use of multi-plane Clos topologies to get the benefits of high switch radix and redundancy, allowing training clusters well over 100K GPUs to be built as two-tier topologies while increasing physical redundancy, and (3) the use of static source-routing using SRv6 to allow MRC the freedom to bypass failures by itself. We describe our experiences running MRC and static SRv6 routing in production in OpenAI and Microsoft's largest training clusters, where it has been used to train the latest frontier models. We demonstrate how MRC allows AI training jobs to ride out many network failures that previously would have interrupted training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a three-pronged networking architecture for large-scale AI training: MRC, an RDMA transport that sprays flows across many paths with active load balancing to avoid collisions; multi-plane Clos topologies that increase redundancy while supporting >100K-GPU clusters as two-tier fabrics; and static SRv6 source routing that lets MRC bypass failures independently. The authors report production deployment of MRC plus SRv6 in OpenAI and Microsoft frontier-model training clusters and claim that this combination allows jobs to ride out network failures that previously caused interruptions.
Significance. If the resilience claims hold at scale, the work would directly address tail-latency and failure-induced downtime that currently limit synchronous pretraining, potentially enabling more reliable operation of clusters well beyond current sizes. The reported production experience constitutes a strength, as does the parameter-free nature of the static SRv6 segments and the absence of new fitted parameters in the MRC design.
major comments (3)
- [Abstract] Abstract and production-experience section: the central claim that MRC 'allows AI training jobs to ride out many network failures' is asserted without any quantitative metrics, before/after comparisons, failure-rate statistics, or latency distributions; this absence prevents assessment of whether the observed resilience is load-bearing or merely anecdotal.
- [Production Experience] Production-deployment description: the manuscript provides no analysis or data showing that the failure-mode distribution, path diversity, or congestion dynamics observed in the two existing clusters remain representative when the number of planes, ToRs, and GPUs increases by another 5–10×; without such scaling arguments or simulation, the claim that spraying plus static SRv6 will continue to prevent interruptions is unsupported.
- [MRC Transport] MRC transport description: the paper does not quantify the reordering or incast effects introduced by path spraying at larger radix or higher fan-in, nor does it demonstrate that SRv6 segment lists can react within the required time bounds for the new failure distribution; these omissions leave open the possibility that the 'ride-out' property fails at the scales the topology is intended to support.
minor comments (2)
- [Topology] The multi-plane Clos topology benefits are described qualitatively; a simple table comparing radix, bisection bandwidth, and physical redundancy against a conventional single-plane Clos would improve clarity.
- [SRv6 Routing] Notation for SRv6 segment lists and MRC path-selection state is introduced without a compact summary table; adding one would help readers track the static versus dynamic elements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments correctly identify areas where additional evidence and analysis would strengthen the manuscript. We respond to each major comment below and commit to revisions that address the concerns while remaining faithful to our production experience and design.
read point-by-point responses
-
Referee: [Abstract] Abstract and production-experience section: the central claim that MRC 'allows AI training jobs to ride out many network failures' is asserted without any quantitative metrics, before/after comparisons, failure-rate statistics, or latency distributions; this absence prevents assessment of whether the observed resilience is load-bearing or merely anecdotal.
Authors: We agree that the abstract and production-experience section would benefit from quantitative support. The current text reports successful production use in OpenAI and Microsoft clusters but presents the resilience benefits qualitatively. In the revision we will update the abstract with high-level metrics drawn from deployment logs (e.g., observed network failure counts and uninterrupted job completion rates) and expand the production section with before/after comparisons of interruption rates. These additions will make the load-bearing nature of the resilience explicit. revision: yes
-
Referee: [Production Experience] Production-deployment description: the manuscript provides no analysis or data showing that the failure-mode distribution, path diversity, or congestion dynamics observed in the two existing clusters remain representative when the number of planes, ToRs, and GPUs increases by another 5–10×; without such scaling arguments or simulation, the claim that spraying plus static SRv6 will continue to prevent interruptions is unsupported.
Authors: The manuscript positions the architecture for clusters well above 100 K GPUs via two-tier multi-plane Clos fabrics, and our reported deployments are already among the largest frontier-model clusters. We acknowledge the value of explicit scaling arguments. We will add a dedicated subsection that analyzes scaling: the static SRv6 segments require no per-scale reconfiguration, path diversity grows linearly with the number of planes, and MRC’s parameter-free load balancing does not rely on cluster-specific tuning. These properties, together with the observed failure-mode distributions in current deployments, support continued effectiveness at the targeted larger scales. revision: yes
-
Referee: [MRC Transport] MRC transport description: the paper does not quantify the reordering or incast effects introduced by path spraying at larger radix or higher fan-in, nor does it demonstrate that SRv6 segment lists can react within the required time bounds for the new failure distribution; these omissions leave open the possibility that the 'ride-out' property fails at the scales the topology is intended to support.
Authors: We will strengthen the MRC transport section with additional quantitative analysis. We will provide analytical bounds and implementation measurements on packet reordering caused by spraying at higher fan-in, together with an explanation of how RDMA’s out-of-order delivery absorbs these effects. For incast we will include evidence that active load balancing across planes prevents hotspot formation. On SRv6 reaction times we will describe the local failure-detection and segment-list update path, showing that bypass occurs without control-plane round-trips and within the sub-second window needed to preserve training continuity. These additions will be grounded in our production implementation. revision: partial
Circularity Check
No circularity; claims rest on production deployment experience with no derivations or self-referential reductions
full rationale
The paper describes a practical systems approach (MRC transport, multi-plane Clos topologies, static SRv6) and reports its use in existing large training clusters to handle observed failures. No equations, fitted parameters, ansatzes, uniqueness theorems, or derivation chains appear in the text. Central claims about riding out failures are grounded in reported production experience rather than any step that reduces by construction to the paper's own inputs or self-citations. This is the expected outcome for an empirical systems paper without mathematical modeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://p4
P4 Open Source Programming Language. https://p4. org/
-
[2]
Hedera: Dynamic Flow Scheduling for Data Cen- ter Networks
Mohammad Al-Fares, Sivasankar Radhakrishnan, Barath Raghavan, Nelson Huang, and Amin Vahdat. Hedera: Dynamic Flow Scheduling for Data Cen- ter Networks. InNetworked Systems Design and Implementation (NSDI). USENIX Association, 2010
2010
-
[3]
CONGA: Distributed Congestion-aware Load Balancing for Datacenters
Mohammad Alizadeh, Tom Edsall, Sarang Dharma- purikar, Ramanan Vaidyanathan, Kevin Chu, Andy Fin- gerhut, Vinh The Lam, Francis Matus, Rong Pan, Navin- dra Yadav, and George Varghese. CONGA: Distributed Congestion-aware Load Balancing for Datacenters. In Special Interest Group on Data Communication (SIG- COMM). ACM, 2014
2014
-
[4]
Demystifying parallel and distributed deep learning: An in-depth concurrency analysis.ACM Comput
Tal Ben-Nun and Torsten Hoefler. Demystifying parallel and distributed deep learning: An in-depth concurrency analysis.ACM Comput. Surv., 52(4), August 2019
2019
-
[5]
Microte: fine grained traffic engineer- ing for data centers
Theophilus Benson, Ashok Anand, Aditya Akella, and Ming Zhang. Microte: fine grained traffic engineer- ing for data centers. InProceedings of the Seventh COnference on Emerging Networking EXperiments and Technologies, CoNEXT ’11, New York, NY , USA, 2011. Association for Computing Machinery
2011
-
[6]
Flowcut switching: High- performance adaptive routing with in-order delivery 13 guarantees.IEEE Transactions on Networking, 34:1974– 1987, 2026
Tommaso Bonato, Daniele De Sensi, Salvatore Di Giro- lamo, Abdulla Bataineh, David Hewson, Duncan Roweth, and Torsten Hoefler. Flowcut switching: High- performance adaptive routing with in-order delivery 13 guarantees.IEEE Transactions on Networking, 34:1974– 1987, 2026
1974
-
[7]
REPS: Recycled entropy packet spraying for adaptive load balancing and failure mitigation, 2026
Tommaso Bonato, Abdul Kabbani, Ahmad Ghalayini, Michael Papamichael, Mohammad Dohadwala, Lukas Gianinazzi, Mikhail Khalilov, Elias Achermann, Daniele De Sensi, and Torsten Hoefler. REPS: Recycled entropy packet spraying for adaptive load balancing and failure mitigation, 2026
2026
-
[8]
ECMP Dynamic Load Balancing
Broadcom. ECMP Dynamic Load Balancing. https: //docs.broadcom.com/doc/56980-DS, 2019
2019
-
[9]
Compressed SRv6 Segment List Encod- ing
Weiqiang Cheng, Clarence Filsfils, Zhenbin Li, Bruno Decraene, Dezhong Cai, Daniel V oyer, Francois Clad, Shay Zadok, Jim Guichard, Aihua Liu, Robert Raszuk, and Cheng Li. Compressed SRv6 Segment List Encod- ing. RFC 9800, June 2025
2025
-
[10]
Ultra Ethernet specification v1.0.1, 2025
Ultra Ethernet Consortium. Ultra Ethernet specification v1.0.1, 2025
2025
-
[11]
The tail at scale
Jeffrey Dean and Luiz André Barroso. The tail at scale. Commun. ACM, 56(2):74–80, February 2013
2013
-
[12]
Hu, and Ra- mona R Kompella
Advait Dixit, Pawan Prokash, Charlie Y . Hu, and Ra- mona R Kompella. On the Impact of Packet Spraying in Data Center Networks. InInternational Conference on Computer Communications (INFOCOM). IEEE, 2013
2013
-
[13]
The LLaMa 3 herd of models, 2024
Aaron Grattafiori et al. The LLaMa 3 herd of models, 2024
2024
-
[14]
Toward deterministic path placement in AI backends: A practical SRv6-based architecture
Clarence Filsfils, Pablo Camarillo, Ahmed Abdelsalam, Arianna Quinci, Angelo Tulumello, Andrea Mayer, Pier- paolo Loreti, Lorenzo Bracciale, and Stefano Salsano. Toward deterministic path placement in AI backends: A practical SRv6-based architecture. In21st Interna- tional Conference on Network and Service Management (CNSM), Bologna, Italy, October 2025. IFIP
2025
-
[15]
Segment Routing over IPv6 (SRv6) Network Programming
Clarence Filsfils, Darren Dukes, Stefano Previdi, John Leddy, Satoru Matsushima, and Daniel V oyer. Segment Routing over IPv6 (SRv6) Network Programming. RFC 8986, February 2021
2021
-
[16]
Rdma over ethernet for distributed training at meta scale
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. Rdma over ethernet for distributed training at meta scale. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ...
2024
-
[17]
Gherghescu, Vlad-Andrei B ˘adoiu, Alexandru Agache, Mihai-Valentin Dumitru, Iuliu Vasilescu, Radu Mantu, and Costin Raiciu
Alexandru M. Gherghescu, Vlad-Andrei B ˘adoiu, Alexandru Agache, Mihai-Valentin Dumitru, Iuliu Vasilescu, Radu Mantu, and Costin Raiciu. I’ve got 99 problems but FLOPS ain’t one. InProceedings of the 23rd ACM Workshop on Hot Topics in Networks, HotNets ’24, page 195–204, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[18]
Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian
Soudeh Ghorbani, Zibin Yang, P. Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian. DRILL: Mi- cro load balancing for low-latency data center networks. InProceedings of the Conference of the ACM Special In- terest Group on Data Communication, SIGCOMM ’17, page 225–238, New York, NY , USA, 2017. Association for Computing Machinery
2017
-
[19]
Pingmesh: A large-scale system for data center network latency measurement and analysis.SIGCOMM Comput
Chuanxiong Guo, Lihua Yuan, Dong Xiang, Yingnong Dang, Ray Huang, Dave Maltz, Zhaoyi Liu, Vin Wang, Bin Pang, Hua Chen, Zhi-Wei Lin, and Varugis Kurien. Pingmesh: A large-scale system for data center network latency measurement and analysis.SIGCOMM Comput. Commun. Rev., 45(4):139–152, August 2015
2015
-
[20]
Moore, Gianni Antichi, and Marcin Wójcik
Mark Handley, Costin Raiciu, Alexandru Agache, An- drei V oinescu, Andrew W. Moore, Gianni Antichi, and Marcin Wójcik. Re-architecting Datacenter Networks and Stacks for Low Latency and High Performance. In Special Interest Group on Data Communication (SIG- COMM). ACM, 2017
2017
-
[21]
Presto: Edge-based load balancing for fast datacenter networks
Keqiang He, Eric Rozner, Kanak Agarwal, Wes Felter, John Carter, and Aditya Akella. Presto: Edge-based load balancing for fast datacenter networks. InProceed- ings of the 2015 ACM Conference on Special Interest Group on Data Communication, SIGCOMM ’15, page 465–478, New York, NY , USA, 2015. Association for Computing Machinery
2015
-
[22]
Characterizing the influence of system noise on large-scale applications by simulation
Torsten Hoefler, Timo Schneider, and Andrew Lums- daine. Characterizing the influence of system noise on large-scale applications by simulation. InProceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’10, page 1–11, USA, 2010. IEEE Com- puter Society
2010
-
[23]
Ultra ethernet’s design principles and architectural innovations, 2025
Torsten Hoefler, Karen Schramm, Eric Spada, Keith Un- derwood, Cedell Alexander, Bob Alverson, Paul Bot- torff, Adrian Caulfield, Mark Handley, Cathy Huang, Costin Raiciu, Abdul Kabbani, Eugene Opsasnick, Rong Pan, Adee Ran, and Rip Sohan. Ultra ethernet’s design principles and architectural innovations, 2025
2025
-
[24]
C. Hopps. Analysis of an Equal-Cost Multi-Path Algo- rithm. RFC 2992, November 2009. 14
2009
-
[25]
Demystifying NCCL: An in-depth analysis of GPU communication protocols and algorithms, 2026
Zhiyi Hu, Siyuan Shen, Tommaso Bonato, Sylvain Jeaugey, Cedell Alexander, Eric Spada, James Dinan, Jeff Hammond, and Torsten Hoefler. Demystifying NCCL: An in-depth analysis of GPU communication protocols and algorithms, 2026
2026
-
[26]
The RoCE initia- tive
InfiniBand Trade Association (IBTA). The RoCE initia- tive. (Accessed: May 2021)
2021
-
[27]
FlowBender: Flow-level Adaptive Routing for Improved Latency and Throughput in Data- center Networks
Abdul Kabbani, Balajee Vamanan, Jahangir Hasan, and Fabien Duchene. FlowBender: Flow-level Adaptive Routing for Improved Latency and Throughput in Data- center Networks. InConference on Emerging Network- ing Experiments and Technologies (CoNEXT). ACM, 2014
2014
-
[28]
CrystalNet: Faithfully emulat- ing large production networks
Hongqiang Liu, Yibo Zhu, Jitu Padhye, Jiaxin Cao, Sri Tallapragada, Nuno Lopes, Andrey Rybalchenko, Guo- han Lu, and Lihua Yuan. CrystalNet: Faithfully emulat- ing large production networks. InSOSP ’17 Proceedings of the 26th Symposium on Operating Systems Principles, pages 599–613. ACM, October 2017
2017
-
[29]
Multi-path transport for RDMA in datacenters
Yuanwei Lu, Guo Chen, Bojie Li, Kun Tan, Yongqiang Xiong, Peng Cheng, Jiansong Zhang, Enhong Chen, and Thomas Moscibroda. Multi-path transport for RDMA in datacenters. In15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), pages 357–371, Renton, WA, April 2018. USENIX Associa- tion
2018
-
[30]
Revisiting network support for RDMA
Radhika Mittal, Alexander Shpiner, Aurojit Panda, Eitan Zahavi, Arvind Krishnamurthy, Sylvia Ratnasamy, and Scott Shenker. Revisiting network support for RDMA. InProceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, SIG- COMM ’18, page 313–326, New York, NY , USA, 2018. Association for Computing Machinery
2018
-
[31]
Homa: A Receiver-driven Low- latency Transport Protocol Using Network Priorities
Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ousterhout. Homa: A Receiver-driven Low- latency Transport Protocol Using Network Priorities. In Special Interest Group on Data Communication (SIG- COMM). ACM, 2018
2018
-
[32]
Kerbyson, and Scott Pakin
Fabrizio Petrini, Darren J. Kerbyson, and Scott Pakin. The case of the missing supercomputer performance: Achieving optimal performance on the 8,192 processors of ASCI Q. InProceedings of the 2003 ACM/IEEE Con- ference on Supercomputing, SC ’03, page 55, New York, NY , USA, 2003. Association for Computing Machinery
2003
-
[33]
Alibaba HPN: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. Alibaba HPN: A data center network for large language model training. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, p...
2024
-
[34]
PLB: congestion signals are simple and ef- fective for network load balancing
Mubashir Adnan Qureshi, Yuchung Cheng, Qianwen Yin, Qiaobin Fu, Gautam Kumar, Masoud Moshref, Jun- hua Yan, Van Jacobson, David Wetherall, and Abdul Kabbani. PLB: congestion signals are simple and ef- fective for network load balancing. InProceedings of the ACM SIGCOMM 2022 Conference, SIGCOMM ’22, page 207–218, New York, NY , USA, 2022. Association for C...
2022
-
[35]
Improving Datacenter Performance and Robustness with Multipath TCP
Costin Raiciu, Sebastien Barre, Christopher Pluntke, Adam Greenhalgh, Damon Wischik, and Mark Hand- ley. Improving Datacenter Performance and Robustness with Multipath TCP. InSpecial Interest Group on Data Communication (SIGCOMM). ACM, 2010
2010
-
[36]
DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation ai scale, 2022
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Min- jia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation ai scale, 2022
2022
-
[37]
TACCL: Guiding collective algorithm synthesis using communi- cation sketches, 2022
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Ja- cob Nelson, Olli Saarikivi, and Rachee Singh. TACCL: Guiding collective algorithm synthesis using communi- cation sketches, 2022
2022
-
[38]
Collective communication for 100k+ GPUs, 2026
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Deep Shah, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Minlan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kannan, Cristian Lume...
2026
-
[39]
Surviv- ing switch failures in cloud datacenters.SIGCOMM Comput
Rachee Singh, Muqeet Mukhtar, Ashay Krishna, Anirud- dha Parkhi, Jitendra Padhye, and David Maltz. Surviv- ing switch failures in cloud datacenters.SIGCOMM Comput. Commun. Rev., 51(2):2–9, May 2021
2021
-
[40]
Arjun Singhvi, Nandita Dukkipati, Prashant Chandra, Hassan M. G. Wassel, Naveen Kr. Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Mon- tazeri, Neelesh Bansod, Sarin Thomas, Inho Cho, Hy- ojeong Lee Seibert, Baijun Wu, Rui Yang, Yuliang Li, Kai Huang, Qianwen Yin, Abhishek Agarwal, Srinivas Vaduvatha, Weihuang Wang, Masoud Moshref, Tao Ji, 15...
2025
-
[41]
Multipath Reliable Con- nection (MRC) Specification
Rip Sohan, Eric Spada, Eric Davis, Mark Handley, Idan Burstein, Tony Hurson, Jithin Jose, Vivek Kashyap, Rong Pan, and Sayantan Sur. Multipath Reliable Con- nection (MRC) Specification. Specification Version 1.0, Open Compute Project, 2026
2026
-
[42]
Let it flow: Resilient asym- metric load balancing with flowlet switching
Erico Vanini, Rong Pan, Mohammad Alizadeh, Parvin Taheri, and Tom Edsall. Let it flow: Resilient asym- metric load balancing with flowlet switching. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), pages 407–420, Boston, MA, March 2017. USENIX Association
2017
-
[43]
Rail-only: A low-cost high-performance network for training LLMs with tril- lion parameters
Weiyang Wang, Manya Ghobadi, Kayvon Shakeri, Ying Zhang, and Naader Hasani. Rail-only: A low-cost high-performance network for training LLMs with tril- lion parameters. In2024 IEEE Symposium on High- Performance Interconnects (HOTI), pages 1–10, 2024
2024
-
[44]
Scalable training of mixture-of-experts models with megatron core.arXiv preprint arXiv:2603.07685,
Zijie Yan, Hongxiao Bai, Xin Yao, Dennis Liu, Tong Liu, Hongbin Liu, Pingtian Li, Evan Wu, Shiqing Fan, Li Tao, et al. Scalable training of mixture-of-experts models with Megatron Core.arXiv preprint arXiv:2603.07685, 2026
-
[45]
To- wards understanding bugs in open source router soft- ware.SIGCOMM Comput
Zuoning Yin, Matthew Caesar, and Yuanyuan Zhou. To- wards understanding bugs in open source router soft- ware.SIGCOMM Comput. Commun. Rev., 40(3):34–40, June 2010
2010
-
[46]
Resilient datacenter load balanc- ing in the wild
Hong Zhang, Junxue Zhang, Wei Bai, Kai Chen, and Mosharaf Chowdhury. Resilient datacenter load balanc- ing in the wild. InProceedings of the Conference of the ACM Special Interest Group on Data Communication, SIGCOMM ’17, page 253–266, New York, NY , USA,
-
[47]
Association for Computing Machinery
-
[48]
UCCL- Tran: An extensible software transport layer for machine learning workloads.USENIX OSDI, 2026
Yang Zhou, Zhongjie Chen, Ziming Mao, ChonLam Lao, Shuo Yang, Pravein Govindan Kannan, Jiaqi Gao, Yilong Zhao, Yongji Wu, Kaichao You, Fengyuan Ren, Zhiying Xu, Costin Raiciu, and Ion Stoica. UCCL- Tran: An extensible software transport layer for machine learning workloads.USENIX OSDI, 2026
2026
-
[49]
Congestion control for large-scale RDMA de- ployments
Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Yehonatan Liron, Jitendra Pad- hye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. Congestion control for large-scale RDMA de- ployments. InProceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, SIG- COMM ’15, page 523–536, New York, NY , USA, ...
2015
-
[50]
victim” traffic as discussed in Section 5.2.8. Here we present some additional results for the same cross- spine 7 to 1 incast traffic pattern run in parallel to a “victim
Noa Zilberman, Gabi Bracha, and Golan Schzukin. Star- dust: Divide and conquer in the data center network. In 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), pages 141–160, Boston, MA, February 2019. USENIX Association. Appendix We provide some additional results demonstrating MRC’s robustness using Broadcom’s Thor Ultra NI...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.