Recognition: unknown
Coral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs
Pith reviewed 2026-05-08 16:41 UTC · model grok-4.3
The pith
Coral reduces the cost of serving multiple LLMs on mixed cloud GPUs by jointly optimizing allocation and per-replica strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coral jointly optimizes resource allocation to models and the serving strategy of each replica across all models at once. A lossless two-stage decomposition preserves the optimality of this joint problem while reducing solve time from hours to tens of seconds, enabling adaptation to changing throughput demand and resource availability. The resulting system lowers serving cost by up to 2.79 times over the strongest baseline and raises goodput by up to 2.39 times when resources are scarce.
What carries the argument
The lossless two-stage decomposition that splits the joint optimization of resource allocation and serving strategies while keeping the original optimal solution intact and allowing fast re-solving.
If this is right
- Serving costs drop when allocation decisions and per-replica strategies are chosen together instead of separately for each model.
- Goodput increases under tight resources because hardware is matched more precisely to the needs of all models simultaneously.
- The two-stage method lets the system react to demand changes in seconds while still reaching the same quality of solution as the full problem.
- These improvements appear consistently across evaluations with six models and twenty different GPU type combinations.
Where Pith is reading between the lines
- The decomposition approach could speed up other joint optimization problems that arise in distributed systems where decisions interact across components.
- Lower costs on varied hardware may let smaller operators run multiple LLMs without depending only on the most expensive GPUs.
- The emphasis on continuous tracking suggests that production systems would benefit from better sensors for both request patterns and hardware state.
Load-bearing premise
The two-stage decomposition always produces the same optimal allocation and strategies as the full joint problem, and real-time tracking of demand and GPU availability is accurate enough to support the adaptive choices.
What would settle it
A live deployment on a heterogeneous GPU cluster that logs actual serving cost and goodput under rapidly varying request rates from multiple models, then checks whether the measured savings match the claimed factors over non-adaptive baselines.
Figures




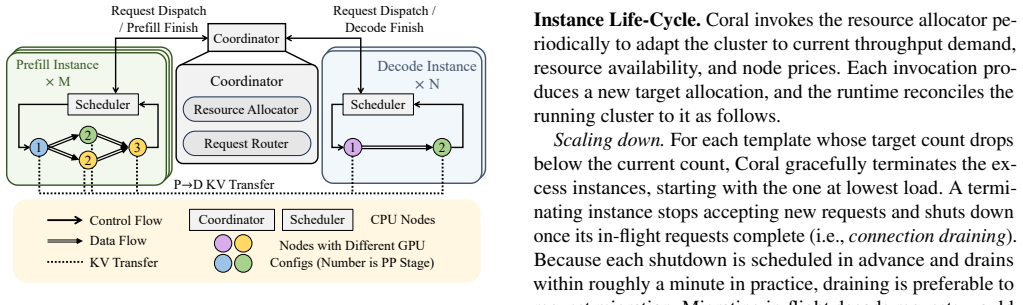







read the original abstract
The usage of large language models (LLMs) has grown increasingly fragmented, with no single model dominating. Meanwhile, cloud providers offer a wide range of mid-tier and older-generation GPUs that enjoy better availability and deliver comparable performance per dollar to top-tier hardware. To efficiently harness these heterogeneous resources for serving multiple LLMs concurrently, we introduce Coral, an adaptive heterogeneity-aware multi-LLM serving system. The key idea behind Coral is to jointly optimize resource allocation and the serving strategy of each model replica across all models. To keep pace with shifting throughput demand and resource availability, Coral applies a lossless two-stage decomposition that preserves joint optimality while cutting online solve time from hours to tens of seconds. Our evaluation across 6 models and 20 GPU configurations shows that Coral reduces serving cost by up to 2.79$\times$ over the best baseline, and delivers up to 2.39$\times$ higher goodput under scarce resource availability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Coral, a system for cost-efficient concurrent serving of multiple LLMs on heterogeneous cloud GPUs. It jointly optimizes resource allocation across models and the serving strategy (e.g., batching, parallelism) for each model replica. To handle dynamic demands, it proposes a lossless two-stage decomposition of the joint optimization problem that reduces solve time from hours to tens of seconds while preserving optimality. Evaluation across 6 models and 20 GPU configurations reports up to 2.79× lower serving cost versus the best baseline and up to 2.39× higher goodput under scarce resources.
Significance. If the lossless decomposition and empirical gains hold under rigorous validation, the work would advance practical multi-LLM serving by better exploiting mid-tier and older GPUs that offer strong price/performance. It targets a timely problem in cloud systems where LLM workloads are fragmented and hardware heterogeneity is increasing.
major comments (2)
- [Two-stage decomposition and solver (abstract and §4–5)] The central claim that the two-stage decomposition is lossless and recovers the exact joint optimum (resource allocation + per-replica serving strategy) is load-bearing for attributing the reported 2.79× cost and 2.39× goodput gains to joint optimization rather than heuristic effects. No direct optimality verification—such as matching objective values or solutions against the joint formulation on small instances—is described, leaving open the possibility that throughput-demand tracking or GPU-type separation introduces suboptimality.
- [Evaluation (§6)] The evaluation claims results across 6 models and 20 GPU configurations, yet supplies no details on baseline implementations (e.g., how vLLM or other systems were configured for heterogeneity), workload traces, statistical methods (repetitions, confidence intervals), or how the solver was validated against ground-truth optima. This weakens the data-to-claim link for the headline performance numbers.
minor comments (1)
- [Notation and problem formulation] Notation for variables such as throughput demand, goodput, and GPU-type constraints should be defined consistently in a table or early section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the lossless decomposition and evaluation details. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Two-stage decomposition and solver (abstract and §4–5)] The central claim that the two-stage decomposition is lossless and recovers the exact joint optimum (resource allocation + per-replica serving strategy) is load-bearing for attributing the reported 2.79× cost and 2.39× goodput gains to joint optimization rather than heuristic effects. No direct optimality verification—such as matching objective values or solutions against the joint formulation on small instances—is described, leaving open the possibility that throughput-demand tracking or GPU-type separation introduces suboptimality.
Authors: We appreciate this observation. The two-stage decomposition is proven lossless via a formal argument in §4 that shows the decomposed subproblems recover the exact optimum of the original joint formulation (no suboptimality is introduced by the separation of resource allocation from per-replica strategy selection). To provide the requested empirical verification, we will add an appendix containing small-instance experiments: we solve the full joint ILP on reduced problem sizes (e.g., 2–3 models and 4–6 GPUs) using a commercial solver and compare both objective values and recovered solutions against the two-stage method, confirming exact matches within numerical tolerance. This will directly support attribution of the reported gains to joint optimization. revision: yes
-
Referee: [Evaluation (§6)] The evaluation claims results across 6 models and 20 GPU configurations, yet supplies no details on baseline implementations (e.g., how vLLM or other systems were configured for heterogeneity), workload traces, statistical methods (repetitions, confidence intervals), or how the solver was validated against ground-truth optima. This weakens the data-to-claim link for the headline performance numbers.
Authors: We agree that additional implementation and methodological details will improve reproducibility and strengthen the claims. Section 6 already enumerates the six models and twenty GPU configurations, but we will expand it to include: explicit baseline configurations (e.g., how vLLM and other systems were adapted to heterogeneous GPUs via manual resource partitioning), workload trace descriptions (synthetic Poisson arrivals plus production-derived traces), statistical procedures (five independent runs per configuration with 95% confidence intervals), and the small-instance solver validation results referenced in the first comment. These clarifications will be added in the revised manuscript. revision: yes
Circularity Check
No circularity: decomposition and evaluation are independent of final metrics
full rationale
The paper formulates a joint optimization problem over resource allocation and per-replica serving strategies, then introduces a two-stage decomposition asserted to preserve optimality. Performance numbers (2.79× cost, 2.39× goodput) are obtained from direct empirical runs on 6 models and 20 GPU configurations. No equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citation chain is invoked to justify uniqueness or the decomposition, and the lossless property is presented as a technical claim rather than a definitional tautology. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Har- rison, Russell J Hewett, Mojan Javaheripi, Piero Kauff- mann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt- oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
Amazon Web Services. AWS and Anthropic announce strategic collaboration to advance generative AI.https: //press.aboutamazon.com/2023/9/amazon-and -anthropic-announce-strategic-collaborati on-to-advance-generative-ai , September 2023. Accessed: 2026-04-20
2023
-
[4]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review arXiv 2021
-
[6]
Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios N. Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: an open platform for evaluating llms by human preference. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Large scale distributed deep networks.Advances in neural informa- tion processing systems, 25, 2012
Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc’aurelio Ranzato, An- drew Senior, Paul Tucker, Ke Yang, et al. Large scale distributed deep networks.Advances in neural informa- tion processing systems, 25, 2012
2012
-
[9]
Gfs: A preemptive scheduling framework for gpu clusters with predictive spot management
Jiaang Duan, Shenglin Xu, Shiyou Qian, Dingyu Yang, Kangjin Wang, Chenzhi Liao, Yinghao Yu, Qin Hua, Hanwen Hu, Qi Wang, Wenchao Wu, Dongqing Bao, Tianyu Lu, Jian Cao, Guangtao Xue, Guodong Yang, Liping Zhang, and Gang Chen. Gfs: A preemptive scheduling framework for gpu clusters with predictive spot management. InProceedings of the 31th ACM In- ternation...
-
[10]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
2022
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, and Ion Stoica. M\’elange: Cost efficient large language model serv- ing by exploiting gpu heterogeneity.arXiv preprint arXiv:2404.14527, 2024
-
[13]
Gurobi Optimizer Refer- ence Manual, 2026
Gurobi Optimization, LLC. Gurobi Optimizer Refer- ence Manual, 2026
2026
-
[14]
O’Reilly Media, Inc., 2013
Pieter Hintjens.ZeroMQ: messaging for many applica- tions. O’Reilly Media, Inc., 2013
2013
-
[15]
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, et al. Inference without interfer- ence: Disaggregate llm inference for mixed downstream workloads.arXiv preprint arXiv:2401.11181, 2024. 13
-
[16]
Gpipe: Effi- cient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Effi- cient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
2019
-
[17]
Amant, Chetan Bansal, Victor Ruhle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St. Amant, Chetan Bansal, Victor Ruhle, Anoop Kulkarni, Steve Kofsky, and Saravan Rajmohan. Sageserve: Optimizing llm serving on cloud data centers with forecast aware auto-scaling.Proc. ACM Meas. Anal. Comput. Syst., 9(3), December 2025
2025
-
[18]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review arXiv 2024
-
[19]
Demystifying cost- efficiency in llm serving over heterogeneous gpus.ArXiv, abs/2502.00722,
Youhe Jiang, Fangcheng Fu, Xiaozhe Yao, Guoliang He, Xupeng Miao, Ana Klimovic, Bin Cui, Binhang Yuan, and Eiko Yoneki. Demystifying cost-efficiency in llm serving over heterogeneous gpus.arXiv preprint arXiv:2502.00722, 2025
-
[20]
Youhe Jiang, Fangcheng Fu, and Eiko Yoneki. Boute: Cost-efficient llm serving with heterogeneous llms and gpus via multi-objective bayesian optimization.arXiv preprint arXiv:2602.10729, 2026
-
[21]
Hexgen: generative infer- ence of large language model over heterogeneous en- vironment
Youhe Jiang, Ran Yan, Xiaozhe Yao, Yang Zhou, Beidi Chen, and Binhang Yuan. Hexgen: generative infer- ence of large language model over heterogeneous en- vironment. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[22]
SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[23]
Gonza- lez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling gi- ant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[25]
Zikun Li, Zhuofu Chen, Remi Delacourt, Gabriele Oliaro, Zeyu Wang, Qinghan Chen, Shuhuai Lin, April Yang, Zhihao Zhang, Zhuoming Chen, et al. Adaserve: Accelerating multi-slo llm serving with slo-customized speculative decoding.arXiv preprint arXiv:2501.12162, 2025
-
[26]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
Yanying Lin, Shijie Peng, Chengzhi Lu, Chengzhong Xu, and Kejiang Ye. Flexpipe: Adapting dy- namic llm serving through inflight pipeline refactor- ing in fragmented serverless clusters.arXiv preprint arXiv:2510.11938, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Skyserve: Serving ai mod- els across regions and clouds with spot instances
Ziming Mao, Tian Xia, Zhanghao Wu, Wei-Lin Chiang, Tyler Griggs, Romil Bhardwaj, Zongheng Yang, Scott Shenker, and Ion Stoica. Skyserve: Serving ai mod- els across regions and clouds with spot instances. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 159–175, New York, NY , USA, 2025. Association for Computing M...
2025
-
[29]
Helix: Serving large language models over heterogeneous gpus and net- work via max-flow
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Serving large language models over heterogeneous gpus and net- work via max-flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vol- ume 1, ASPLOS ’25, page 586–602, New York, NY ...
2025
-
[30]
The llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal AI innovation. https://ai.m eta.com/blog/llama-4-multimodal-intellige nce/, April 2025. Accessed: 2026-04-20
2025
-
[31]
Gloo: A collective communications library.https://github.com/pytorch/gloo, 2017
Meta Platforms, Inc. Gloo: A collective communications library.https://github.com/pytorch/gloo, 2017
2017
-
[32]
Spotserve: Serv- ing generative large language models on preemptible instances
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. Spotserve: Serv- ing generative large language models on preemptible instances. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 1112–1127, 2024
2024
-
[33]
Microsoft and OpenAI extend partner- ship
Microsoft Corp. Microsoft and OpenAI extend partner- ship. https://blogs.microsoft.com/blog/2023/ 01/23/microsoftandopenaiextendpartnership/ , January 2023. Accessed: 2026-04-20. 14
2023
-
[34]
NVIDIA Collective Communication Library (NCCL).https://github.com/NVIDIA/nccl, 2015
NVIDIA. NVIDIA Collective Communication Library (NCCL).https://github.com/NVIDIA/nccl, 2015
2015
-
[35]
NVIDIA Corporation, 2026
NVIDIA.Developing a Linux Kernel Module using GPUDirect RDMA. NVIDIA Corporation, 2026
2026
-
[36]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
2024
-
[37]
Inside the rise of enterprise ai model- switching
Perplexity Team. Inside the rise of enterprise ai model- switching. https://www.perplexity.ai/hub/blog /inside-the-rise-of-enterprise-ai-model-s witching, Feb 2026. Accessed: 2026-04-20
2026
-
[38]
Mooncake: A kvcache- centric disaggregated architecture for llm serving.ACM Transactions on Storage, 2024
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. Mooncake: A kvcache- centric disaggregated architecture for llm serving.ACM Transactions on Storage, 2024
2024
-
[39]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review arXiv 2023
-
[40]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[41]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Dynamollm: Designing llm inference clusters for performance and energy efficiency
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Tor- rellas, and Esha Choukse. Dynamollm: Designing llm inference clusters for performance and energy efficiency. In2025 IEEE International Symposium on High Per- formance Computer Architecture (HPCA), pages 1348–
-
[43]
Sailor: Automating distributed training over dynamic, heterogeneous, and geo-distributed clusters
Foteini Strati, Zhendong Zhang, George Manos, Ix- eia Sánchez Périz, Qinghao Hu, Tiancheng Chen, Berk Buzcu, Song Han, Pamela Delgado, and Ana Klimovic. Sailor: Automating distributed training over dynamic, heterogeneous, and geo-distributed clusters. InProceed- ings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 204–220,...
2025
-
[44]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Per- rin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas B...
2025
-
[45]
Burstgpt: A real-world workload dataset to optimize llm serving systems
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al. Burstgpt: A real-world workload dataset to optimize llm serving systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discov- ery and Data Mining V . 2, pages 5831–5841, 2025
2025
-
[46]
Can’t be late: Optimizing spot instance savings under deadlines
Zhanghao Wu, Wei-Lin Chiang, Ziming Mao, Zongheng Yang, Eric Friedman, Scott Shenker, and Ion Stoica. Can’t be late: Optimizing spot instance savings under deadlines. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 185–203, 2024
2024
-
[47]
The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
2025
-
[48]
Aegaeon: Effective gpu pooling for concurrent llm serving on the market
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. Aegaeon: Effective gpu pooling for concurrent llm serving on the market. InProceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, pages 1030–1045, 2025
2025
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[50]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[51]
Orca: A distributed serving system for {Transformer-Based} generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX symposium on operating sys- tems design and implementation (OSDI 22), pages 521– 538, 2022
2022
-
[52]
Prism: Unleashing gpu sharing for cost-efficient multi-llm serving, 2025
Shan Yu, Jiarong Xing, Yifan Qiao, Mingyuan Ma, Yang- min Li, Yang Wang, Shuo Yang, Zhiqiang Xie, Shiyi Cao, Ke Bao, et al. Prism: Unleashing gpu sharing for cost-efficient multi-llm serving.arXiv preprint arXiv:2505.04021, 2025
-
[53]
Cauchy: A cost- efficient llm serving system through adaptive hetero- geneous deployment
Yihui Zhang, Han Shen, Renyu Yang, Di Tian, Yuxi Luo, Menghao Zhang, Li Li, Chunming Hu, Tianyu Wo, Chengru Song, and Jin Ouyang. Cauchy: A cost- efficient llm serving system through adaptive hetero- geneous deployment. InProceedings of the 2025 ACM Symposium on Cloud Computing, SoCC ’25, page 881–893, New York, NY , USA, 2026. Association for Computing Machinery
2025
-
[54]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
2024
-
[55]
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the bar- rier of closed-source models in code intelligence.arXiv preprint arXiv:2406.11931, 2024. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.