Recognition: 2 theorem links
· Lean TheoremTowards Robust LLM Post-Training: Automatic Failure Management for Reinforcement Fine-Tuning
Pith reviewed 2026-05-08 18:14 UTC · model grok-4.3
The pith
RFT failures during LLM post-training can be automatically detected, diagnosed, and remediated by a unified framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that by building RFT-FaultBench and studying its failure data, it is possible to see that RFT failures are observable from training dynamics and distinguishable through their empirical fault fingerprints. This enables RFT-FM, an automatic failure management framework for reinforcement fine-tuning that unifies anomaly detection, failure diagnosis, and auto remediation in a closed loop.
What carries the argument
RFT-FM, a closed-loop automatic failure management system for reinforcement fine-tuning that performs anomaly detection, diagnosis, and remediation based on training dynamics and fault fingerprints identified in the RFT-FaultBench.
If this is right
- Practitioners can reduce dependence on manual inspection during RFT processes.
- Failures become manageable through automated responses rather than process halts.
- The benchmark provides a standard way to test and improve failure management tools.
- RFT processes gain reliability as the framework mitigates issues in real time.
Where Pith is reading between the lines
- Extending this to production LLM training could minimize wasted compute on faulty runs.
- Similar fingerprinting techniques might help in diagnosing issues in other types of model training beyond RFT.
- Future work could explore integrating RFT-FM with existing training platforms for seamless adoption.
Load-bearing premise
The fault families and types used to create the benchmark are representative of the failures that naturally occur during real-world reinforcement fine-tuning of large language models.
What would settle it
Observing whether RFT-FM accurately detects and remediates failures in actual RFT training runs that have no pre-injected faults, compared to human expert analysis of the same runs.
Figures





read the original abstract
Reinforcement fine-tuning (RFT) has become a core paradigm for post-training large language models, yet its training process remains highly fragile. Existing efforts mainly improve reliability at the system level or address specific issues in individual subproblems by modifying RFT algorithms. Despite their effectiveness, they largely overlook the problem of failure management at the training-process level. When training goes wrong, practitioners still rely heavily on expert-driven manual inspection and correction, and automatic failure management for RFT remains largely unexplored. In this paper, we take a first step toward systematic failure management for reinforcement fine-tuning. To understand the empirical structure of RFT failures, we first construct RFT-FaultBench, the first benchmark for fine-grained failures in reinforcement fine-tuning, covering 5 fault families, 16 fault types, 779 training runs, 22,549 train-step records, and 1,457,288 trajectory-level records. Based on this benchmark, we conduct a comprehensive empirical study showing that RFT failures are both observable from training dynamics and distinguishable through their empirical fault fingerprints. Building on these findings, we propose RFT-FM, an automatic failure management framework for reinforcement fine-tuning that unifies anomaly detection, failure diagnosis, and auto remediation in a closed loop. Experimental results show that RFT-FaultBench is neither trivial nor saturated: it exhibits clear anomaly structure while still posing substantial challenges, especially under subtle fault settings. Moreover, RFT-FM shows strong capability in detecting, diagnosing, and mitigating RFT failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RFT-FaultBench, the first benchmark for fine-grained failures in reinforcement fine-tuning covering 5 fault families, 16 fault types, 779 training runs, 22,549 train-step records, and 1,457,288 trajectory-level records. An empirical study shows that RFT failures exhibit observable dynamics and distinguishable fault fingerprints. Building on this, the authors propose RFT-FM, a closed-loop automatic failure management framework unifying anomaly detection, diagnosis, and remediation, claiming that the benchmark exhibits clear anomaly structure and that RFT-FM demonstrates strong capability in detecting, diagnosing, and mitigating RFT failures.
Significance. If the synthetic fault injections prove representative of real RFT failure distributions, the work would be significant as the first systematic treatment of failure management at the training-process level for reinforcement fine-tuning of LLMs. The construction of a large-scale benchmark with trajectory-level records and the demonstration of distinguishable empirical fingerprints provide a concrete foundation for future automated tools, moving beyond ad-hoc manual inspection.
major comments (2)
- [Abstract] Abstract: the claim that 'RFT-FM shows strong capability in detecting, diagnosing, and mitigating RFT failures' is presented without any quantitative metrics, baseline comparisons, or details on how remediation success was measured, making the strength of the empirical results impossible to assess from the reported summary.
- [Benchmark construction and experimental evaluation] Benchmark construction and experimental evaluation sections: the central claim that RFT-FM exhibits strong capability 'in practice' rests on the untested premise that the 5 deliberately injected fault families and 16 types in the 779 controlled runs produce fingerprints that statistically match the failure modes arising in uncontrolled real-world RFT runs (e.g., reward hacking, noisy-gradient instability, or environment-specific collapse). No evidence is supplied that the benchmark's fault fingerprints align with those from practitioner-collected failed trainings, which is load-bearing for the practical significance of the closed-loop pipeline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of how we present our empirical claims and the scope of our benchmark. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'RFT-FM shows strong capability in detecting, diagnosing, and mitigating RFT failures' is presented without any quantitative metrics, baseline comparisons, or details on how remediation success was measured, making the strength of the empirical results impossible to assess from the reported summary.
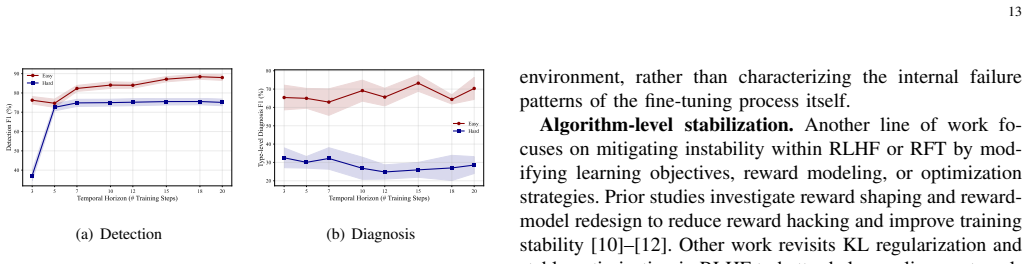
Authors: We agree that the abstract would benefit from more concrete quantitative support. The current abstract summarizes the overall findings at a high level. In the revised manuscript we will expand the abstract to report key performance numbers from our experiments, including detection metrics (e.g., F1 scores under different fault settings), diagnosis accuracy across the 16 fault types, and remediation success rates relative to the baselines we evaluated. This will make the strength of the RFT-FM results directly assessable from the abstract. revision: yes
-
Referee: [Benchmark construction and experimental evaluation] Benchmark construction and experimental evaluation sections: the central claim that RFT-FM exhibits strong capability 'in practice' rests on the untested premise that the 5 deliberately injected fault families and 16 types in the 779 controlled runs produce fingerprints that statistically match the failure modes arising in uncontrolled real-world RFT runs (e.g., reward hacking, noisy-gradient instability, or environment-specific collapse). No evidence is supplied that the benchmark's fault fingerprints align with those from practitioner-collected failed trainings, which is load-bearing for the practical significance of the closed-loop pipeline.
Authors: We acknowledge the importance of this point. The fault families and types in RFT-FaultBench were chosen to reflect failure modes frequently described in the RFT literature (reward hacking, gradient instability, data-quality collapse, etc.). Our empirical analysis of the 779 controlled runs shows that these injected faults produce observable dynamics and distinguishable fingerprints. However, we do not supply direct statistical alignment against a corpus of real-world failed RFT runs, as such large-scale practitioner data is not publicly available and is difficult to collect systematically. We will revise the manuscript to state this limitation explicitly in the benchmark construction and discussion sections and to outline concrete directions for future validation with real-world traces. The current benchmark still offers the first large-scale, trajectory-level resource for studying and automating RFT failure management. revision: partial
Circularity Check
No circularity: empirical construction and held-out evaluation are independent
full rationale
The paper's chain consists of independent benchmark construction (injecting 5 fault families into 779 controlled runs to produce RFT-FaultBench), an empirical study of observable dynamics and fingerprints on that data, and evaluation of the proposed RFT-FM closed-loop framework on held-out runs. No equations, fitted parameters, or self-citations reduce the claimed detection/diagnosis/remediation performance to inputs defined from the same data by construction. The benchmark and framework are built and tested separately, so the derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement fine-tuning of LLMs produces observable training dynamics that can be used for anomaly detection.
invented entities (1)
-
RFT-FM framework
no independent evidence
Lean theorems connected to this paper
-
Cost.Jcost / Foundation.LogicAsFunctionalEquationwashburn_uniqueness_aczel unclearcore RFT telemetry such as reward, KL divergence, entropy, return, response length, policy loss
Reference graph
Works this paper leans on
-
[1]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi et al., “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,” Nature, vol. 645, no. 8081, pp. 633–638, 2025
2025
-
[2]
Competitive programming with large reasoning models.arXiv preprint arXiv:2502.06807, 2025
A. El-Kishky, A. Wei, A. Saraiva, B. Minaiev, D. Selsam, D. Do- han, F. Song, H. Lightman, I. Clavera, J. Pachocki et al., “Com- petitive programming with large reasoning models,” arXiv preprint arXiv:2502.06807, 2025
-
[3]
L. Zhang, L. Fang, C. Duan, M. He, L. Pan, P. Xiao, S. Huang, Y . Zhai, X. Hu, P. S. Yu et al., “A survey on parallel text generation: From parallel decoding to diffusion language models,” arXiv preprint arXiv:2508.08712, 2025
-
[4]
L. Pan, Z. Fu, Y . Zhai, S. Tao, S. Guan, S. Huang, L. Zhang, Z. Liu, B. Ding, F. Henry et al., “Omni-safetybench: A benchmark for safety evaluation of audio-visual large language models,” arXiv preprint arXiv:2508.07173, 2025
-
[5]
d-treerpo: Towards more reliable policy optimization for diffusion language models
L. Pan, S. Tao, Y . Zhai, Z. Fu, L. Fang, M. He, L. Zhang, Z. Liu, B. Ding, A. Liu et al., “d-treerpo: Towards more reliable policy optimization for diffusion language models,” arXiv preprint arXiv:2512.09675, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
L4: Diagnosing large-scale llm training failures via automated log analysis,
Z. Jiang, J. Huang, G. Yu, Z. Chen, Y . Li, R. Zhong, C. Feng, Y . Yang, Z. Yang, and M. Lyu, “L4: Diagnosing large-scale llm training failures via automated log analysis,” in Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 51–63
2025
-
[7]
Role-based fault tolerance system for llm rl post-training,
Z. Chen, B. Zhong, X. Li, Q. Dai, X. Zhao, M. Ye, R. Cheng, L. Zhang, and J. Yin, “Role-based fault tolerance system for llm rl post-training,” arXiv preprint arXiv:2512.22492, 2025
-
[8]
TRANSOM: An efficient fault-tolerant system for training LLMs.arXiv preprint arXiv:2310.10046, 2023
B. Wu, L. Xia, Q. Li, K. Li, X. Chen, Y . Guo, T. Xiang, Y . Chen, and S. Li, “Transom: An efficient fault-tolerant system for training llms,” arXiv preprint arXiv:2310.10046, 2023
-
[9]
Flashrecovery: Fast and low-cost recovery from failures for large-scale training of llms,
H. Zhang, J. Wang, Z. Yu, Y . Zhang, X. Ji, K. Mao, J. Zhang, Y . Zhang, T. Wu, F. Jie et al., “Flashrecovery: Fast and low-cost recovery from failures for large-scale training of llms,” arXiv preprint arXiv:2509.03047, 2025
-
[10]
arXiv preprint arXiv:2502.18770 , year=
J. Fu, X. Zhao, C. Yao, H. Wang, Q. Han, and Y . Xiao, “Reward shaping to mitigate reward hacking in rlhf,” arXiv preprint arXiv:2502.18770, 2025
-
[11]
Information-theoretic reward modeling for stable rlhf: Detecting and mitigating reward hacking,
Y . Miao, L. Ding, S. Zhang, R. Bao, L. Zhang, and D. Tao, “Information- theoretic reward modeling for stable rlhf: Detecting and mitigating reward hacking,” arXiv preprint arXiv:2510.13694, 2025
-
[12]
Mitigating reward hacking in rlhf via bayesian non-negative reward modeling, 2026
Z. Duan, G. Rong, Z. Li, B. Chen, M. Zhou, and D. Guo, “Mitigating reward hacking in rlhf via bayesian non-negative reward modeling,” arXiv preprint arXiv:2602.10623, 2026
-
[13]
Rethinking KL regularization in RLHF : From value estimation to gradient optimization
K. Liu, J. K. Liu, M. Chen, and Y . Liu, “Rethinking kl regularization in rlhf: From value estimation to gradient optimization,” arXiv preprint arXiv:2510.01555, 2025
-
[14]
Unifying stable optimization and reference regularization in rlhf,
L. He, Q. Qu, H. Zhao, S. Wan, D. Wang, L. Yao, and T. Liu, “Unifying stable optimization and reference regularization in rlhf,” in The Fourteenth International Conference on Learning Representations
-
[15]
A survey of aiops in the era of large language models,
L. Zhang, T. Jia, M. Jia, Y . Wu, A. Liu, Y . Yang, Z. Wu, X. Hu, P. Yu, and Y . Li, “A survey of aiops in the era of large language models,”ACM Computing Surveys, 2025
2025
-
[16]
A survey of aiops methods for failure management,
P. Notaro, J. Cardoso, and M. Gerndt, “A survey of aiops methods for failure management,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 12, no. 6, pp. 1–45, 2021
2021
-
[17]
Y . Remil, A. Bendimerad, R. Mathonat, and M. Kaytoue, “Aiops solutions for incident management: Technical guidelines and a com- prehensive literature review,” arXiv preprint arXiv:2404.01363, 2024
-
[18]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[19]
Fine-Tuning Language Models from Human Preferences
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving, “Fine-tuning language models from human preferences,” arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review arXiv 1909
-
[20]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” Advances in Neural Information Processing Systems, vol. 36, pp. 53 728–53 741, 2023
2023
-
[21]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,” arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
J. Hu, X. Wu, Z. Zhu, W. Wang, D. Zhang, Y . Cao et al., “Openrlhf: An easy-to-use, scalable and high-performance rlhf framework,” arXiv preprint arXiv:2405.11143, 2024
-
[24]
Language models learn to mislead hu- mans via rlhf,
J. Wen, R. Zhong, A. Khan, E. Perez, J. Steinhardt, M. Huang, S. R. Bowman, H. He, and S. Feng, “Language models learn to mislead hu- mans via rlhf,” in The Thirteenth International Conference on Learning Representations
-
[25]
Odin: disentangled reward mitigates hacking in rlhf,
L. Chen, C. Zhu, J. Chen, D. Soselia, T. Zhou, T. Goldstein, H. Huang, M. Shoeybi, and B. Catanzaro, “Odin: disentangled reward mitigates hacking in rlhf,” in Proceedings of the 41st International Conference on Machine Learning, 2024, pp. 7935–7952
2024
-
[26]
Language models resist alignment: Evidence from data compression,
J. Ji, K. Wang, T. A. Qiu, B. Chen, J. Zhou, C. Li, H. Lou, J. Dai, Y . Liu, and Y . Yang, “Language models resist alignment: Evidence from data compression,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), 2025, pp. 23 411–23 432
2025
-
[27]
Why do some language models fake alignment while others don’t?
A. Sheshadri, J. Hughes, J. Michael, A. T. Mallen, A. Jose, and F. Roger, “Why do some language models fake alignment while others don’t?” in The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[28]
C. Xue, Y . Wang, M. Liu, D. Liang, X. Han, P. Liu, X. Wu, C. Lu, L. Jiang, Y . Lu et al., “Why supervised fine-tuning fails to learn: A systematic study of incomplete learning in large language models,”arXiv preprint arXiv:2604.10079, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022. 15
2022
-
[30]
Tranad: deep transformer networks for anomaly detection in multivariate time series data,
S. Tuli, G. Casale, and N. R. Jennings, “Tranad: deep transformer networks for anomaly detection in multivariate time series data,” Proceedings of the VLDB Endowment, vol. 15, no. 6, pp. 1201–1214, 2022
2022
-
[31]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network,
Y . Su, Y . Zhao, C. Niu, R. Liu, W. Sun, and D. Pei, “Robust anomaly detection for multivariate time series through stochastic recurrent neural network,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 2828– 2837
2019
-
[32]
Anomaly transformer: Time series anomaly detection with association discrepancy,
J. Xu, H. Wu, J. Wang, and M. Long, “Anomaly transformer: Time series anomaly detection with association discrepancy,” in International Conference on Learning Representations
-
[33]
Root cause analysis in microservice using neural granger causal discovery,
C.-M. Lin, C. Chang, W.-Y . Wang, K.-D. Wang, and W.-C. Peng, “Root cause analysis in microservice using neural granger causal discovery,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 1, 2024, pp. 206–213
2024
-
[34]
Causalrca: Causal inference based pre- cise fine-grained root cause localization for microservice applications,
R. Xin, P. Chen, and Z. Zhao, “Causalrca: Causal inference based pre- cise fine-grained root cause localization for microservice applications,” Journal of Systems and Software, vol. 203, p. 111724, 2023
2023
-
[35]
Circa: A framework for collaborative identification of root cause analysis in iot microservices,
X. Jiang, H. Luo, Y . Sun, and S. K. Das, “Circa: A framework for collaborative identification of root cause analysis in iot microservices,” IEEE Transactions on Services Computing, 2025
2025
-
[36]
Deeplog: Anomaly detection and diagnosis from system logs through deep learning,
M. Du, F. Li, G. Zheng, and V . Srikumar, “Deeplog: Anomaly detection and diagnosis from system logs through deep learning,” in Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, 2017, pp. 1285–1298
2017
-
[37]
Isolation-based anomaly detection,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation-based anomaly detection,” ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 6, no. 1, pp. 1–39, 2012
2012
-
[38]
Conditional anomaly detection,
X. Song, M. Wu, C. Jermaine, and S. Ranka, “Conditional anomaly detection,” IEEE Transactions on knowledge and Data Engineering, vol. 19, no. 5, pp. 631–645, 2007
2007
-
[39]
Multivariate log- based anomaly detection for distributed database,
L. Zhang, T. Jia, M. Jia, Y . Li, Y . Yang, and Z. Wu, “Multivariate log- based anomaly detection for distributed database,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 4256–4267
2024
-
[40]
Reducing events to augment log-based anomaly detection models: An empirical study,
L. Zhang, T. Jia, K. Wang, M. Jia, Y . Yang, and Y . Li, “Reducing events to augment log-based anomaly detection models: An empirical study,” in Proceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, 2024, pp. 538– 548
2024
-
[41]
E-log: Fine-grained elastic log-based anomaly detection and diagnosis for databases,
L. Zhang, T. Jia, X. Tan, X. Huang, M. Jia, H. Liu, Z. Wu, and Y . Li, “E-log: Fine-grained elastic log-based anomaly detection and diagnosis for databases,” IEEE Transactions on Services Computing, 2025
2025
-
[42]
Aaad: Asynchronous inter-variable relationship-aware anomaly detection for multivariate time series,
H. Liu, X. Huang, M. Jia, L. Zhang, T. Jia, Z. Wu, and Y . Li, “Aaad: Asynchronous inter-variable relationship-aware anomaly detection for multivariate time series,” in 2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2025, pp. 1–6
2025
-
[43]
Logaction: Consistent cross-system anomaly detection through logs via active domain adaptation,
C. Duan, M. He, P. Xiao, T. Jia, X. Zhang, Z. Zhong, X. Luo, Y . Niu, L. Zhang, S. Yu et al., “Logaction: Consistent cross-system anomaly detection through logs via active domain adaptation,” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 700–712
2025
-
[44]
Walk the talk: Is your log-based software reliability main- tenance system really reliable?
M. He, T. Jia, C. Duan, P. Xiao, L. Zhang, K. Wang, Y . Wu, Y . Li, and G. Huang, “Walk the talk: Is your log-based software reliability main- tenance system really reliable?” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 3784–3788
2025
-
[45]
Xraglog: A resource- efficient and context-aware log-based anomaly detection method using retrieval-augmented generation,
L. Zhang, T. Jia, M. Jia, Y . Wu, H. Liu, and Y . Li, “Xraglog: A resource- efficient and context-aware log-based anomaly detection method using retrieval-augmented generation,” inAAAI 2025 Workshop on Preventing and Detecting LLM Misinformation (PDLM), 2025
2025
-
[46]
Coorlog: Efficient-generalizable log anomaly detection via adaptive coordinator in software evolution,
P. Xiao, C. Duan, M. He, T. Jia, Y . Wu, J. Xu, G. Gao, L. Zhang, W. Hong, Y . Li et al., “Coorlog: Efficient-generalizable log anomaly detection via adaptive coordinator in software evolution,” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 1119–1131
2025
-
[47]
Runtimeslicer: Towards generalizable unified runtime state representation for failure management,
L. Zhang, T. Jia, W. Hong, M. Wang, C. Duan, M. He, R. Wang, X. Peng, M. Wang, G. Zhang et al., “Runtimeslicer: Towards generalizable unified runtime state representation for failure management,” arXiv preprint arXiv:2603.21495, 2026
-
[48]
Ad-llm: Benchmarking large language models for anomaly detection,
T. Yang, Y . Nian, L. Li, R. Xu, Y . Li, J. Li, Z. Xiao, X. Hu, R. A. Rossi, K. Ding et al., “Ad-llm: Benchmarking large language models for anomaly detection,” in Findings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 1524–1547
2025
-
[49]
Ora: Job runtime prediction for high-performance computing platforms using the online retrieval-augmented language model,
H. Liu, Y . Ma, X. Huang, L. Zhang, T. Jia, and Y . Li, “Ora: Job runtime prediction for high-performance computing platforms using the online retrieval-augmented language model,” in Proceedings of the 39th ACM International Conference on Supercomputing, 2025, pp. 884–894
2025
-
[50]
Lm-pace: Confidence estimation by large language models for effective root causing of cloud incidents,
D. Zhang, X. Zhang, C. Bansal, P. Las-Casas, R. Fonseca, and S. Raj- mohan, “Lm-pace: Confidence estimation by large language models for effective root causing of cloud incidents,” in Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024, pp. 388–398
2024
-
[51]
Automatic root cause analysis via large language models for cloud incidents,
Y . Chen, H. Xie, M. Ma, Y . Kang, X. Gao, L. Shi, Y . Cao, X. Gao, H. Fan, M. Wen et al., “Automatic root cause analysis via large language models for cloud incidents,” in Proceedings of the Nineteenth European Conference on Computer Systems, 2024, pp. 674–688
2024
-
[52]
Scalalog: Scalable log-based failure diagnosis using llm,
L. Zhang, T. Jia, M. Jia, Y . Wu, H. Liu, and Y . Li, “Scalalog: Scalable log-based failure diagnosis using llm,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[53]
Agentfm: Role-aware failure management for distributed databases with llm-driven multi-agents,
L. Zhang, Y . Zhai, T. Jia, X. Huang, C. Duan, and Y . Li, “Agentfm: Role-aware failure management for distributed databases with llm-driven multi-agents,” arXiv preprint arXiv:2504.06614, 2025
-
[54]
Test: Text prototype aligned embedding to activate llm’s ability for time series,
C. Sun, H. Li, Y . Li, and S. Hong, “Test: Text prototype aligned embedding to activate llm’s ability for time series,” in The Twelfth International Conference on Learning Representations, 2024
2024
-
[55]
Learning representations on logs for aiops,
P. Gupta, H. Kumar, D. Kar, K. Bhukar, P. Aggarwal, and P. Mohap- atra, “Learning representations on logs for aiops,” in 2023 IEEE 16th International Conference on Cloud Computing (CLOUD). IEEE, 2023, pp. 155–166
2023
-
[56]
Art: A unified unsupervised framework for incident management in mi- croservice systems,
Y . Sun, B. Shi, M. Mao, M. Ma, S. Xia, S. Zhang, and D. Pei, “Art: A unified unsupervised framework for incident management in mi- croservice systems,” in Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1183–1194
2024
-
[57]
Towards close-to-zero runtime collection overhead: Raft-based anomaly diagnosis on system faults for distributed storage system,
L. Zhang, T. Jia, M. Jia, H. Liu, Y . Yang, Z. Wu, and Y . Li, “Towards close-to-zero runtime collection overhead: Raft-based anomaly diagnosis on system faults for distributed storage system,” IEEE Transactions on Services Computing, vol. 18, no. 2, pp. 1054–1067, 2024
2024
-
[58]
Cslparser: A collaborative framework using small and large language models for log parsing,
W. Hong, Y . Wu, L. Zhang, C. Duan, P. Xiao, M. He, X. Yang, and Y . Li, “Cslparser: A collaborative framework using small and large language models for log parsing,” in 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2025, pp. 61–72
2025
-
[59]
United we stand: Towards end-to-end log-based fault diagnosis via interactive multi-task learning,
M. He, C. Duan, P. Xiao, T. Jia, S. Yu, L. Zhang, W. Hong, J. Han, Y . Wu, Y . Liet al., “United we stand: Towards end-to-end log-based fault diagnosis via interactive multi-task learning,” in 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2025, pp. 661–673
2025
-
[60]
Efficient failure management for multi-agent systems with reasoning trace representation,
L. Zhang, T. Jia, M. Wang, W. Hong, C. Duan, M. He, R. Wang, X. Peng, M. Wang, G. Zhang et al., “Efficient failure management for multi-agent systems with reasoning trace representation,” arXiv preprint arXiv:2603.21522, 2026
-
[61]
Latent error prediction and fault localization for microservice applications by learning from system trace logs,
X. Zhou, X. Peng, T. Xie, J. Sun, C. Ji, D. Liu, Q. Xiang, and C. He, “Latent error prediction and fault localization for microservice applications by learning from system trace logs,” in Proceedings of the 2019 27th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, 2019, pp. 683–694
2019
-
[62]
Seer: Leveraging big data to navigate the complexity of performance debugging in cloud microservices,
Y . Gan, Y . Zhang, K. Hu, D. Cheng, Y . He, M. Pancholi, and C. Delimitrou, “Seer: Leveraging big data to navigate the complexity of performance debugging in cloud microservices,” in Proceedings of the twenty-fourth international conference on architectural support for programming languages and operating systems, 2019, pp. 19–33
2019
-
[63]
Unsupervised detection of microservice trace anomalies through service-level deep bayesian networks,
P. Liu, H. Xu, Q. Ouyang, R. Jiao, Z. Chen, S. Zhang, J. Yang, L. Mo, J. Zeng, W. Xue et al., “Unsupervised detection of microservice trace anomalies through service-level deep bayesian networks,” in 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2020, pp. 48–58
2020
-
[64]
Sage: practical and scalable ml-driven performance debugging in microservices,
Y . Gan, M. Liang, S. Dev, D. Lo, and C. Delimitrou, “Sage: practical and scalable ml-driven performance debugging in microservices,” in Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2021, pp. 135–151
2021
-
[65]
Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments,
G. Yu, P. Chen, H. Chen, Z. Guan, Z. Huang, L. Jing, T. Weng, X. Sun, and X. Li, “Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments,” in Proceedings of the Web Conference 2021, 2021, pp. 3087–3098
2021
-
[66]
Tracerank: Abnormal service localization with dis-aggregated end-to-end tracing data in cloud native systems,
G. Yu, Z. Huang, and P. Chen, “Tracerank: Abnormal service localization with dis-aggregated end-to-end tracing data in cloud native systems,” Journal of Software: Evolution and Process, vol. 35, no. 10, p. e2413, 2023. 16
2023
-
[67]
Trace-based multi-dimensional root cause localization of performance issues in mi- croservice systems,
C. Zhang, Z. Dong, X. Peng, B. Zhang, and M. Chen, “Trace-based multi-dimensional root cause localization of performance issues in mi- croservice systems,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–12
2024
-
[68]
Thinkfl: Self-refining failure localization for microservice systems via reinforcement fine-tuning,
L. Zhang, Y . Zhai, T. Jia, C. Duan, S. Yu, J. Gao, B. Ding, Z. Wu, and Y . Li, “Thinkfl: Self-refining failure localization for microservice systems via reinforcement fine-tuning,” ACM Transactions on Software Engineering and Methodology, 2025
2025
- [69]
-
[70]
L. Zhang, T. Jia, Y . Zhai, L. Pan, C. Duan, M. He, P. Xiao, and Y . Li, “Hypothesize-then-verify: Speculative root cause analysis for microser- vices with pathwise parallelism,” arXiv preprint arXiv:2601.02736, 2026
-
[71]
Agentic memory enhanced recursive reasoning for root cause localization in microservices,
L. Zhang, T. Jia, Y . Zhai, L. Pan, C. Duan, M. He, M. Jia, and Y . Li, “Agentic memory enhanced recursive reasoning for root cause localization in microservices,” arXiv preprint arXiv:2601.02732, 2026
-
[72]
Uda-rcl: Unsupervised domain adaptation for microservice root cause localization utilizing multimodal data,
X. Huang, H. Liu, Y . Wu, L. Zhang, T. Jia, Y . Li, and Z. Wu, “Uda-rcl: Unsupervised domain adaptation for microservice root cause localization utilizing multimodal data,” IEEE Transactions on Services Computing, 2025
2025
-
[73]
Recommending root-cause and mitigation steps for cloud incidents using large language models,
T. Ahmed, S. Ghosh, C. Bansal, T. Zimmermann, X. Zhang, and S. Rajmohan, “Recommending root-cause and mitigation steps for cloud incidents using large language models,” in 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 1737–1749
2023
-
[74]
X-lifecycle learning for cloud incident management using llms,
D. Goel, F. Husain, A. Singh, S. Ghosh, A. Parayil, C. Bansal, X. Zhang, and S. Rajmohan, “X-lifecycle learning for cloud incident management using llms,” in Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024, pp. 417– 428
2024
-
[75]
A holistic view of ai-driven network incident management,
P. Hamadanian, B. Arzani, S. Fouladi, S. K. R. Kakarla, R. Fonseca, D. Billor, A. Cheema, E. Nkposong, and R. Chandra, “A holistic view of ai-driven network incident management,” in Proceedings of the 22nd ACM Workshop on Hot Topics in Networks, 2023, pp. 180–188
2023
-
[76]
Xpert: Empowering incident management with query recommendations via large language models,
Y . Jiang, C. Zhang, S. He, Z. Yang, M. Ma, S. Qin, Y . Kang, Y . Dang, S. Rajmohan, Q. Lin et al., “Xpert: Empowering incident management with query recommendations via large language models,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[77]
Shellgpt: Gener- ative pre-trained transformer model for shell language understanding,
J. Shi, S. Jiang, B. Xu, J. Liang, Y . Xiao, and W. Wang, “Shellgpt: Gener- ative pre-trained transformer model for shell language understanding,” in 2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2023, pp. 671–682
2023
-
[78]
Automated code generation for information technology tasks in yaml through large language models,
S. Pujar, L. Buratti, X. Guo, N. Dupuis, B. Lewis, S. Suneja, A. Sood, G. Nalawade, M. Jones, A. Morari et al., “Automated code generation for information technology tasks in yaml through large language models,” in 2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023, pp. 1–4
2023
-
[79]
Lever- aging large language models for the auto-remediation of microservice applications: An experimental study,
K. Sarda, Z. Namrud, M. Litoiu, L. Shwartz, and I. Watts, “Lever- aging large language models for the auto-remediation of microservice applications: An experimental study,” in Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024, pp. 358–369
2024
-
[80]
Ansible lightspeed: A code generation service for it automation,
P. Sahoo, S. Pujar, G. Nalawade, R. Genhardt, L. Mandel, and L. Buratti, “Ansible lightspeed: A code generation service for it automation,” in Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 2148–2158
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.