Recognition: unknown
A Hybrid Method for Low-Resource Named Entity Recognition
Pith reviewed 2026-05-08 16:44 UTC · model grok-4.3
The pith
A two-stage hybrid system uses rules to group complex labels then restores them after model training to improve Vietnamese named entity recognition with scarce data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a hybrid pipeline which reduces label complexity through rule-based grouping, fine-tunes pre-trained language models on the simplified task, restores fine-grained labels via post-processing, and augments training data with large language models produces higher extraction accuracy than strong RoBERTa baselines across five Vietnamese domain datasets.
What carries the argument
The two-stage pipeline that first applies rule-based grouping to reduce label complexity, fine-tunes pre-trained models, then restores original labels through post-processing while using LLM-generated examples to enlarge the training set.
If this is right
- The method maintains application-level usability by restoring detailed labels after simplification.
- Data augmentation via large language models removes the need for complete re-annotation when label sets grow.
- Performance gains appear consistently across logistics, wildlife, healthcare, and service domains.
- The pipeline can be reused on other low-resource languages that share similar label heterogeneity.
Where Pith is reading between the lines
- The same grouping-plus-restoration pattern could be tested on other sequence-labeling problems such as part-of-speech tagging or relation extraction.
- If the rule component is made language-independent, the framework might transfer to additional low-resource languages beyond Vietnamese.
- Further work could measure how much the augmentation step contributes when the initial labeled set is reduced even further.
Load-bearing premise
Rule-based grouping and large-language-model augmentation preserve accuracy without introducing errors that degrade final performance.
What would settle it
Apply the same hybrid pipeline to a fresh Vietnamese domain dataset with heterogeneous labels and check whether the hybrid version matches or exceeds the accuracy of a standard fine-tuned model trained on the same data.
Figures


read the original abstract
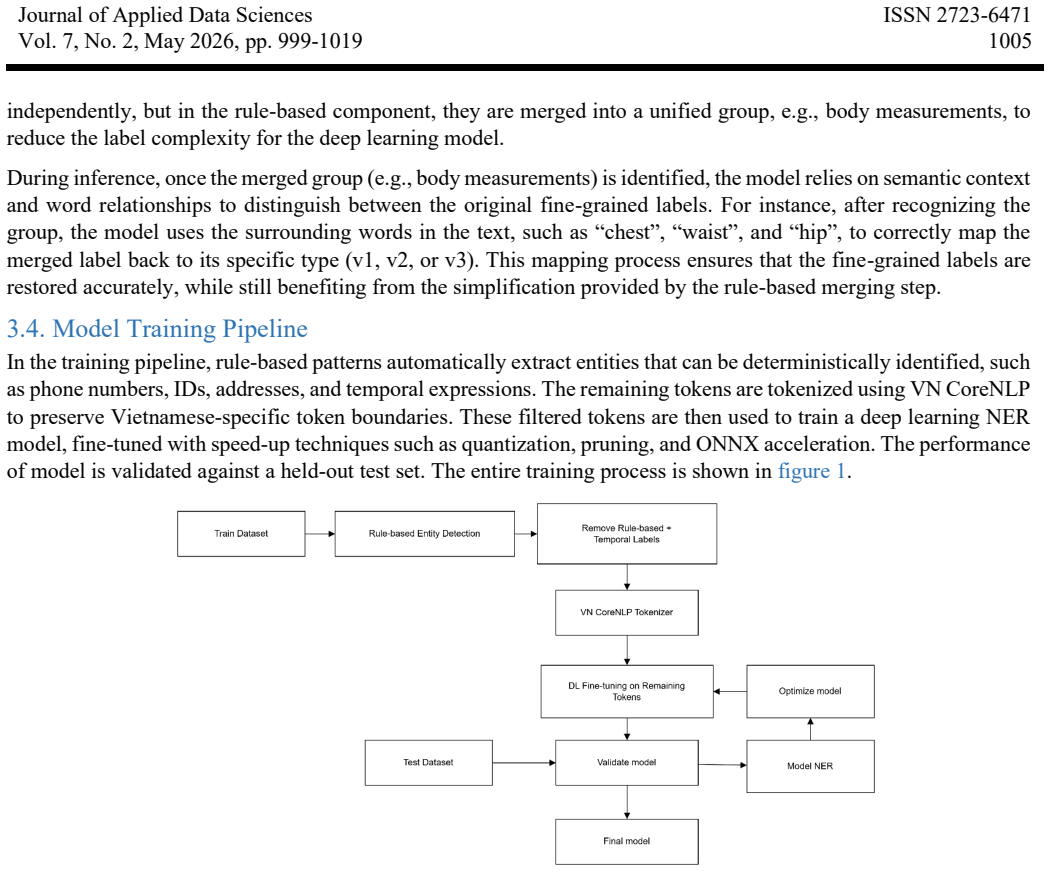
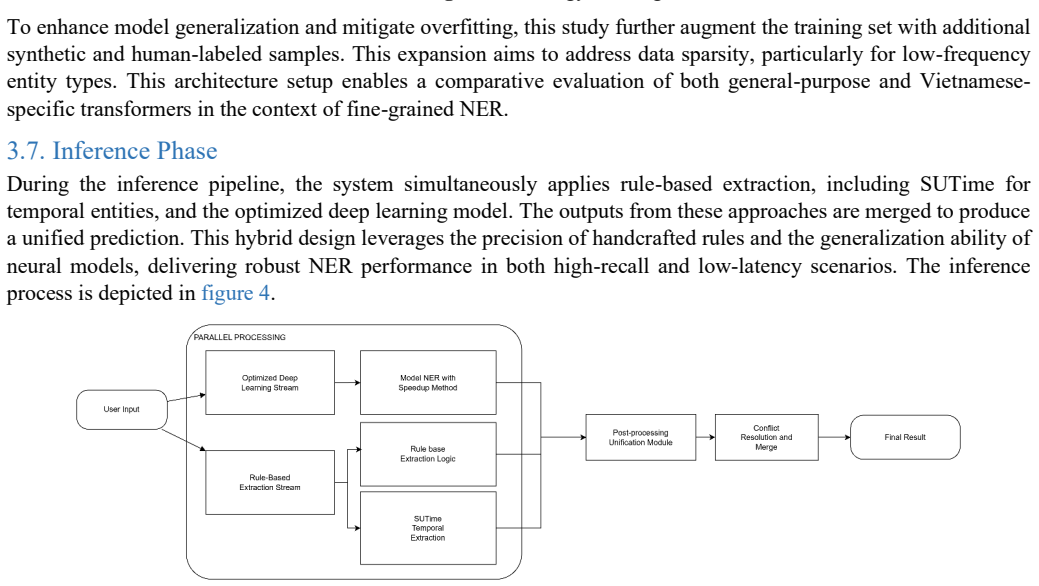
Named Entity Recognition (NER) is a critical component of Natural Language Processing with diverse applications in information extraction and conversational AI. However, NER in specific domains for low-resource languages faces challenges such as limited annotated data and heterogeneous label sets. This study addresses these issues by proposing a hybrid neurosymbolic framework that integrates rule-based processing with deep learning models for Vietnamese NER. The core idea involves a two-stage pipeline: first, a rule-based component reduces label complexity by grouping relational and special categories; second, pre-trained language models are fine-tuned for high-precision extraction. A post-processing module is then utilized to restore fine-grained labels, preserving expressiveness for application-level usability. To mitigate data scarcity, a scalable data augmentation strategy leveraging Large Language Models (LLMs) is introduced to expand the label set without full re-annotation, which is a significant novelty of this work. The effectiveness of this method was evaluated across five specific-domain datasets, including logistics, wildlife, and healthcare. Experimental results demonstrate substantial improvements over strong RoBERTa-based baselines. Specifically, the proposed system achieved F1 scores of 90 percent in Customer Service, up from 83 percent; 84 percent in GAM, up from 73 percent; 83 percent in AI Fluent, up from 80 percent; 94 percent in PhoNER_Covid19, up from 91 percent; and 60 percent in Rare Wildlife, up from 36 percent. These findings confirm that the hybrid approach effectively captures the linguistic complexity of Vietnamese and contextual nuances in specialized domains, offering a robust contribution to low-resource NER research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid neurosymbolic framework for low-resource Vietnamese NER that first applies rule-based grouping to collapse relational and special label categories, then fine-tunes pre-trained models (RoBERTa baseline), augments training data via LLMs to expand the label set without full re-annotation, and finally uses post-processing to restore the original fine-grained labels. Experiments on five domain-specific datasets report F1 gains over the baseline: 90% vs. 83% (Customer Service), 84% vs. 73% (GAM), 83% vs. 80% (AI Fluent), 94% vs. 91% (PhoNER_Covid19), and 60% vs. 36% (Rare Wildlife).
Significance. If the gains prove robust, the approach offers a pragmatic way to manage heterogeneous label inventories and annotation scarcity in specialized low-resource NER, with the largest reported lift on the Rare Wildlife dataset suggesting utility for real-world, imbalanced domains. The neurosymbolic combination of rules and LLMs is a timely direction, but its value depends on demonstrating that each stage contributes positively rather than merely simplifying the task or introducing unmeasured noise.
major comments (3)
- [§4 (Experiments)] §4 (Experiments): Only end-to-end F1 scores versus the RoBERTa baseline are reported. No ablation removes the rule-based grouping step while retaining the same expanded label inventory and LLM-augmented data, so it is impossible to isolate whether the 24-point gain on Rare Wildlife arises from label simplification, augmentation, or their interaction.
- [§3.2 (Post-processing)] §3.2 (Post-processing): The assertion that post-processing accurately restores fine-grained labels after grouping is presented without quantitative support (e.g., restoration error rate, confusion matrix, or per-category F1 before/after restoration). If restoration mismatches occur, they could inflate the final scores.
- [§3.3 (LLM Augmentation)] §3.3 (LLM Augmentation): No error analysis or noise quantification is provided for the LLM-generated examples. A sample audit or comparison of model performance with vs. without the augmented portion is needed to confirm that added data does not silently introduce boundary or type errors that the downstream model and post-processing fail to correct.
minor comments (2)
- [Abstract] Abstract and §4: F1 improvements are given as point estimates without confidence intervals, standard deviations across runs, or statistical significance tests, which would help assess whether the smaller gains (e.g., +3 on PhoNER_Covid19) are reliable.
- [§3.1] §3.1: The exact rule definitions for grouping relational/special categories are described at a high level; providing the full rule set or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects for strengthening the empirical validation of our hybrid framework. We address each major comment below and commit to incorporating the requested analyses and ablations in the revised manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): Only end-to-end F1 scores versus the RoBERTa baseline are reported. No ablation removes the rule-based grouping step while retaining the same expanded label inventory and LLM-augmented data, so it is impossible to isolate whether the 24-point gain on Rare Wildlife arises from label simplification, augmentation, or their interaction.
Authors: We agree that an ablation isolating the rule-based grouping step is required to determine the source of the observed gains. In the revised manuscript, we will add results from training the model on the LLM-augmented data using the expanded label inventory directly, without applying the grouping step. This will be reported in Section 4, allowing quantification of whether the 24-point improvement on the Rare Wildlife dataset stems primarily from label simplification, data augmentation, or their combination. revision: yes
-
Referee: [§3.2 (Post-processing)] §3.2 (Post-processing): The assertion that post-processing accurately restores fine-grained labels after grouping is presented without quantitative support (e.g., restoration error rate, confusion matrix, or per-category F1 before/after restoration). If restoration mismatches occur, they could inflate the final scores.
Authors: We acknowledge that the post-processing module lacks supporting quantitative metrics in the current version. We will revise Section 3.2 to include the restoration error rate computed on a validation subset, a confusion matrix detailing mismatches between grouped and restored labels, and per-category F1 scores comparing performance before and after restoration. This will confirm the accuracy of the step and rule out any inflation of the end-to-end F1 scores. revision: yes
-
Referee: [§3.3 (LLM Augmentation)] §3.3 (LLM Augmentation): No error analysis or noise quantification is provided for the LLM-generated examples. A sample audit or comparison of model performance with vs. without the augmented portion is needed to confirm that added data does not silently introduce boundary or type errors that the downstream model and post-processing fail to correct.
Authors: We concur that error analysis of the LLM-augmented examples is essential. In the revision, we will add a manual audit of a representative sample of generated instances, quantifying error types such as boundary mismatches and incorrect label assignments. We will also include an ablation comparing F1 scores with and without the augmented data to demonstrate the net benefit and verify that any introduced noise is effectively handled by the fine-tuned model and post-processing. revision: yes
Circularity Check
Empirical hybrid NER pipeline with no derivations or self-referential predictions
full rationale
The paper describes a two-stage neurosymbolic pipeline (rule-based grouping followed by fine-tuning and post-processing) plus LLM-based data augmentation, then reports end-to-end F1 scores on five datasets against a RoBERTa baseline. No equations, first-principles derivations, or parameter-fitting steps are claimed; performance numbers are measured outcomes, not quantities predicted from the same fitted inputs. No self-citation chains or uniqueness theorems are invoked to justify core components. The work is therefore self-contained as an empirical engineering contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fine-tuning works after label simplification.
- ad hoc to paper Post-processing restores labels accurately.
Reference graph
Works this paper leans on
-
[1]
Lingvisticæ Investigationes , author =
D. Nadeau and S. Sekine, “A survey of named entity recognition and classification,” Lingvisticae Investigationes, vol. 30, no. 1, pp. 3-26, 2007, doi: 10.1075/li.30.1.03nad
-
[2]
A survey on deep learning for named entity recognition,
J. Li, A. Sun, J. Han, and C. Li, “A survey on deep learning for named entity recognition,” IEEE Trans. Knowl. Data Eng ., vol. 34, no. 1, pp. 50-70, 2022, doi : 10.1109/TKDE.2020.2981314
-
[3]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre -training of Deep Bidirectional Transformers for Language Understanding,” in Proc. 2019 Conf. North Amer. Chapter Assoc. Comput. Linguistics , vol. 2019, no. 1, pp. 1-7, 2019, doi : 10.18653/v1/N19-1423
-
[4]
A survey on recent advances in named entity recognition from deep learning models,
V. Yadav and S. Bethard, “A survey on recent advances in named entity recognition from deep learning models,” in Proc. 27th Int. Conf. Comput. Linguistics, vol. 2019, no. Aug., pp. 2145–2158, 2019, doi : 10.48550/arXiv.1910.11470
-
[5]
S ci BERT : A pretrained language model for scientific text
I. Beltagy, K. Lo, and A. Cohan, “SciBERT: A Pretrained Language Model for Scientific Text,” in Proc. 2019 Conf. Empirical Methods Natural Language Processing, vol. 2019, no. Nov., pp. 3615–3620, 2019, doi : 10.18653/v1/D19-1371
-
[6]
PhoBERT: Pre-trained language models for Vietnamese,
D.Q. Nguyen and A.T. Nguyen, “PhoBERT: Pre-trained language models for Vietnamese,” arXiv preprint arXiv:2003.00744, vol. 2020, no. Mar., pp. 1–12, 2020, doi : 10.48550/arXiv.2003.00744
-
[7]
On the Vietnamese Name Entity Recognition: A Deep Learning Method Approach,
L.N. Chi, N.Y. Nguyen, and A.D. Trinh, “On the Vietnamese Name Entity Recognition: A Deep Learning Method Approach,” in RIVF Int. Conf. Computing Commun. Technol. (RIVF) , vol. 2020, no. Oct., pp. 1 –5, 2020 . doi : 10.1109/RIVF48685.2020.9140754
-
[8]
COVID-19 Named Entity Recognition for Vietnamese,
T.H. Truong, M. Dao, and D.Q. Nguyen, “COVID-19 Named Entity Recognition for Vietnamese,” NAACL-HLT, vol. 2021, no. Jun., pp. 1–10, 2021, doi : 10.18653/v1/2021.naacl-main.173
-
[9]
Financial Named Entity Recognition: How Far Can LLM Go?,
Y-T. Lu and Y. Huo, “Financial Named Entity Recognition: How Far Can LLM Go?,” in Proc. Joint Workshop 9th Financial Technology Natural Language Processing (FinNLP), 6th Financial Narrative Processing (FNP), and 1st Workshop Large Language Models Finance Legal (LLMFinLegal), FinNLP, vol. 2025, no. Jul., pp. 1 –7, 2025 . https://aclanthology.org/2025.finnl...
2025
-
[10]
Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition,
E. Tjong Kim Sang and F. De Meulder, “Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition,” in Proc. Seventh Conf. Natural Language Learning , vol. 2003, no. Jul., pp. 1 –10, 2003 , doi : 10.48550/arXiv.cs/0306050
-
[11]
Message Understanding Conference-6: A Brief History,
R. Grishman and B.M. Sundheim, “Message Understanding Conference-6: A Brief History,” in Proc. 16th Int. Conf. Comput. Linguistics, vol. 1996, no. Aug., pp. 1–10, 1996, doi :10.3115/992628.992709
-
[12]
Named entity recognition in query,
J. Guo, G. Xu, X. Cheng, and H. Li, “Named entity recognition in query,” in Proc. 32nd Int. ACM SIGIR Conf. Research Dev. Information Retrieval, vol. 2009, no. Jul., pp. 1–10, 2009, doi : 10.1145/1571941.1571989
-
[13]
Performance Issues and Error Analysis in an Open -Domain Question Answering System,
D.I. Moldovan, M. Pasca, S.M. Harabagiu, and M. Surdeanu, “Performance Issues and Error Analysis in an Open -Domain Question Answering System,” ACM Trans. Inf. Syst., vol. 21, no. Apr., pp. 133-154, 2002, doi: 10.3115/1073083.1073091
-
[14]
Improving machine translation quality with automatic named entity recognition,
B. Babych and A. Hartley, “Improving machine translation quality with automatic named entity recognition,” in Proc. EAMT- ISTAS Workshop, vol. 2003, no. May, pp. 1–9, 2003, doi : 10.3115/1609822.1609823
-
[15]
Knowledge Base Population: Successful Approaches and Challenges,
H. Ji and R. Grishman, “Knowledge Base Population: Successful Approaches and Challenges,” in Proc. 49th Ann. Meet. Assoc. Comput. Linguistics: Human Lang. Technol., Portland, OR, USA , vol. 2011, no. Jun., pp. 1148 –1158, 2011 . https://aclanthology.org/P11-1115/
2011
-
[16]
Neural Architectures for Named Entity Recognition
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, C. Dyer, “Neural architectures for named entity recognition,” in Proc. 2016 Conf. North Amer. Chapter Assoc. Comput. Linguistics: Human Lang. Technol ., NAACL-HLT, vol. 2016, no. Jun., pp. 260–270, 2016, doi : 10.18653/v1/N16-1030
-
[17]
A neural network multi-task learning approach to biomedical named entity recognition,
G.K.O. Crichton, S. Pyysalo, B. Chiu, and A. Korhonen, “A neural network multi-task learning approach to biomedical named entity recognition,” BMC Bioinformatics, ol. 18, no. Apr., pp. 1–10, 2017, doi: 10.1186/s12859-017-1776-8
-
[18]
Cross -type biomedical named entity recognition with deep multi -task learning,
Y. Wang, L. Wang, M. Rastegar -Mojarad, H. Liu, “Cross -type biomedical named entity recognition with deep multi -task learning,” Bioinformatics, vol. 35, no. 10, pp. 1745–1752, 2019, doi : 10.1093/bioinformatics/bty869
-
[19]
Named Entity Recognition in the Romanian Legal Domain,
V. Pais, M. Mitrofan, C.L. Gasan, V. Coneschi, A. Ianov, “Named Entity Recognition in the Romanian Legal Domain,” in Proc. Natural Legal Language Processing Workshop 2021, vol. 2021, no. Jun., pp. 9–18, 2021, doi: 10.18653/v1/2021.nllp- 1.2
-
[20]
Legal Entity Extraction: An Experimental Study of NER Approach for Legal Documents,
V. Naik, P. Patel, R. Kannan, “Legal Entity Extraction: An Experimental Study of NER Approach for Legal Documents,” Int. J. Adv. Comput. Sci. Appl., vol. 14, no. 3, pp. 775–781, 2023, doi: 10.14569/IJACSA.2023.0140389
-
[21]
FiNER -ORD: Financial Named Entity Recognition Open Research Dataset,
A. Shah, A. Gullapalli, R. Vithani, M. Galarnyk, S. Chava, “FiNER -ORD: Financial Named Entity Recognition Open Research Dataset,” arXiv, vol. 2023, no. Feb., pp. 1–12, 2023, doi : 10.48550/arXiv.2302.11157
-
[22]
A Feature -Rich Vietnamese Named-Entity Recognition Model,
P.Q.N. Minh, “A Feature -Rich Vietnamese Named-Entity Recognition Model,” arXiv, vol. 2018, no. Mar., pp. 1 –12, 2018, doi : 10.48550/arXiv.1803.04375
-
[23]
Layer -Condensed KV Cache for Efficient Inference of Large Language Models,
H. Wu and K. Tu, “Layer -Condensed KV Cache for Efficient Inference of Large Language Models,” in Proc. 62nd Ann . Meet. Assoc. Comput. Linguistics, vol. 2024, no. Jul., pp. 1–12, 2024, doi : 10.18653/v1/2024.acl-long.602
-
[24]
J. Dai, Z. Huang, H. Jiang, C. Chen, D. Cai, et al., “CORM: Cache Optimization with Recent Message for Large Language Model Inference,” arXiv, vol. 2024, no. Apr., pp. 1–12, 2024, doi: 10.48550/arXiv.2404.15949
-
[25]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
T. Dao, D.Y. Fu, S. Ermon, A. Rudra, C. Ré, “FlashAttention: Fast and Memory -Efficient Exact Attention with IO - Awareness,” arXiv, vol. 2022, no. May, pp. 1–12, 2022, doi: 10.48550/arXiv.2205.14135
work page internal anchor Pith review doi:10.48550/arxiv.2205.14135 2022
-
[26]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv, vol. 2019, no. Jul., pp. 1–12, 2019, doi: 10.48550/arXiv.1907.11692
work page internal anchor Pith review doi:10.48550/arxiv.1907.11692 2019
-
[27]
Adam: A Method for Stochastic Optimization
D.P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” CoRR, arXiv, vol. 2014, no. Dec., pp. 1 –12, doi : 10.48550/arXiv.1412.6980
work page internal anchor Pith review doi:10.48550/arxiv.1412.6980 2014
-
[28]
Y. Liu, Z. Li, Z. Fang, N. Xu, R. He, T. Tan, “Rethinking the Role of Prompting Strategies in LLM Test -Time Scaling: A Perspective of Probability Theory,” in Proc. 63rd Ann. Meet. Assoc. Comput. Linguistics (Volume 1: Long Papers), vol. 2025, no. Jul., pp. 1–12, 2025, doi 10.18653/v1/2025.acl-long.1356
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.