Recognition: unknown
SCOUT: Active Information Foraging for Long-Text Understanding with Decoupled Epistemic States
Pith reviewed 2026-05-08 17:16 UTC · model grok-4.3
The pith
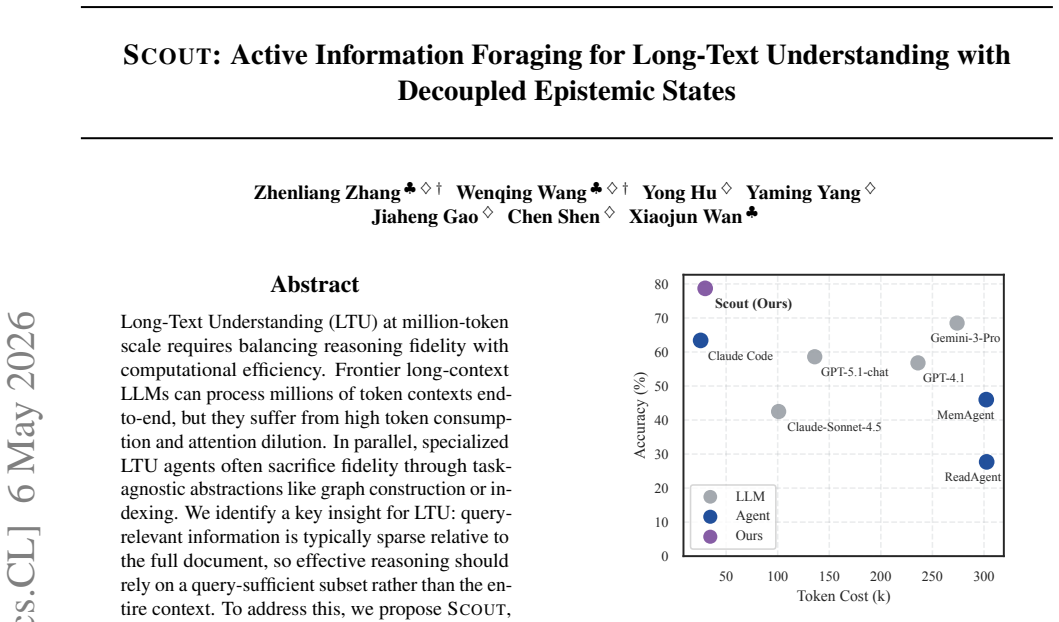
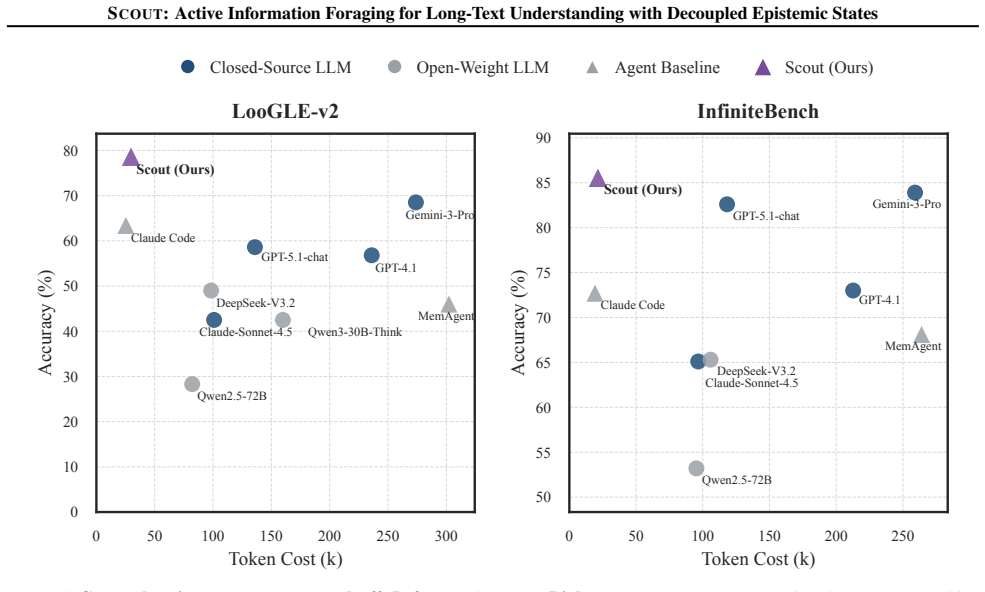
SCOUT treats long documents as explorable environments and forages only the sparse query-relevant information needed, matching proprietary models while cutting token use by up to 8x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCOUT shifts long-text understanding from passive full-context processing to active information foraging: it models the document as an environment, diagnoses gaps in a decoupled epistemic state, and alternates coarse-to-fine exploration with anchored state updates until the state reaches query sufficiency.
What carries the argument
Decoupled epistemic states that start broad and contract through guided coarse-to-fine exploration and state updates.
If this is right
- Token consumption drops by up to 8x relative to end-to-end long-context models.
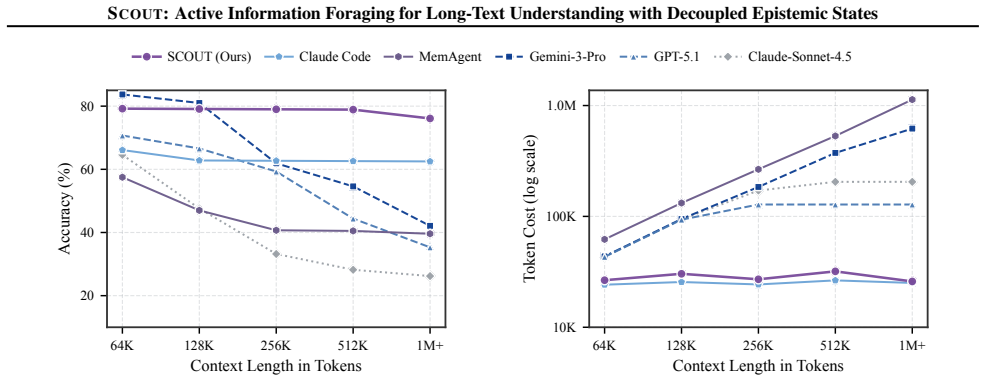
- Performance remains stable rather than degrading as context length scales to millions of tokens.
- The method achieves parity with state-of-the-art proprietary systems on long-text benchmarks without requiring full-document attention.
- Provenance is preserved because every answer element traces back to specific explored passages.
Where Pith is reading between the lines
- The same foraging logic could apply to other sparse-information domains such as large code repositories or scientific paper collections.
- Future systems might embed foraging primitives directly rather than relying on ever-larger context windows.
- Lower token budgets per query would reduce both monetary cost and energy use for repeated long-text tasks.
Load-bearing premise
Query-relevant information is sparse enough in most documents that adaptive exploration can locate it without missing critical details.
What would settle it
A controlled test in which critical query answers are deliberately placed in dense, hard-to-locate sections and SCOUT consistently fails to retrieve them while full-context baselines succeed.
Figures

read the original abstract
Long-Text Understanding (LTU) at million-token scale requires balancing reasoning fidelity with computational efficiency. Frontier long-context LLMs can process millions of token contexts end-to-end, but they suffer from high token consumption and attention dilution. In parallel, specialized LTU agents often sacrifice fidelity through task-agnostic abstractions like graph construction or indexing. We identify a key insight for LTU: query-relevant information is typically sparse relative to the full document, so effective reasoning should rely on a query-sufficient subset rather than the entire context. To address this, we propose SCOUT, a new paradigm for LTU that shifts from passive processing to active information foraging. It treats the document as an explorable environment and answers from a compact, provenance-grounded epistemic state. Guided by state-level gap diagnosis, SCOUT adaptively alternates between coarse-to-fine exploration and anchored state updates that progressively contract its epistemic state toward query sufficiency. Experiments show that SCOUT matches state-of-the-art proprietary models while reducing token consumption by up to 8x. Moreover, SCOUT remains stable as context length scales, substantially alleviating the practical cost-performance trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SCOUT, a new paradigm for long-text understanding (LTU) that shifts from passive full-context processing to active information foraging. The document is treated as an explorable environment; a decoupled epistemic state is maintained and progressively contracted toward query sufficiency via state-level gap diagnosis, coarse-to-fine exploration, and anchored updates. The central empirical claims are that SCOUT matches the performance of state-of-the-art proprietary long-context models while reducing token consumption by up to 8x and remains stable as context length increases.
Significance. If the results are substantiated, SCOUT offers a promising direction for efficient LTU by exploiting the sparsity of query-relevant information through adaptive, provenance-grounded foraging rather than end-to-end attention or task-agnostic abstractions. The decoupling of epistemic states and the use of gap diagnosis as a control mechanism constitute a conceptual contribution that could alleviate the cost-performance trade-off at million-token scales.
major comments (3)
- [Abstract] Abstract: The claim that SCOUT 'matches state-of-the-art proprietary models' while reducing token consumption by up to 8x is load-bearing for the central contribution, yet the abstract (and the provided manuscript description) supplies no baselines, datasets, metrics, or error analysis. Without these, it is impossible to assess whether the foraging mechanism preserves fidelity or simply under-samples.
- [Abstract] Abstract, paragraph on method: The assumption that 'query-relevant information is typically sparse' and that coarse-to-fine exploration plus state-level gap diagnosis will always reach query sufficiency without omitting critical details is not supported by any quantitative recall analysis or failure-mode study. If the LLM-driven exploration systematically misses sparsely distributed but necessary facts, the fidelity claim collapses even while token counts remain low.
- [Abstract] The stability claim ('SCOUT remains stable as context length scales') is presented without reference to how context length was varied, which metrics were tracked, or controls for increasing document size. This directly affects the practical cost-performance alleviation asserted in the abstract.
minor comments (1)
- [Abstract] The term 'epistemic state' and 'state-level gap diagnosis' are introduced without a concise formal definition or pseudocode in the abstract; a short boxed definition or diagram would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract and the load-bearing claims. We address each major comment point by point below and will revise the manuscript to improve clarity and substantiation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that SCOUT 'matches state-of-the-art proprietary models' while reducing token consumption by up to 8x is load-bearing for the central contribution, yet the abstract (and the provided manuscript description) supplies no baselines, datasets, metrics, or error analysis. Without these, it is impossible to assess whether the foraging mechanism preserves fidelity or simply under-samples.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will expand the abstract to name the primary datasets (LongBench and InfiniteBench), the main baselines (GPT-4o, Claude-3 Opus, and selected open long-context models), the metrics (accuracy and F1), and a brief note that detailed error analysis appears in Section 5. The full experimental protocol and results, which already demonstrate comparable fidelity at substantially lower token cost, remain in Section 4. revision: yes
-
Referee: [Abstract] Abstract, paragraph on method: The assumption that 'query-relevant information is typically sparse' and that coarse-to-fine exploration plus state-level gap diagnosis will always reach query sufficiency without omitting critical details is not supported by any quantitative recall analysis or failure-mode study. If the LLM-driven exploration systematically misses sparsely distributed but necessary facts, the fidelity claim collapses even while token counts remain low.
Authors: We acknowledge that an explicit quantitative recall analysis and failure-mode study would strengthen the sparsity and sufficiency claims. While overall performance metrics in Section 4 provide indirect support, we will add a dedicated subsection (or appendix) reporting recall rates for query-relevant spans and a systematic analysis of failure cases. This addition will be included in the revised manuscript. revision: yes
-
Referee: [Abstract] The stability claim ('SCOUT remains stable as context length scales') is presented without reference to how context length was varied, which metrics were tracked, or controls for increasing document size. This directly affects the practical cost-performance alleviation asserted in the abstract.
Authors: We thank the referee for highlighting this omission. Section 4.3 already details the stability experiments: context length is varied from 10k to 1M tokens on both synthetic and real documents, with accuracy, token consumption, and latency tracked under controlled document-size and query-difficulty conditions. We will revise the abstract to reference this analysis and the observed stability. revision: yes
Circularity Check
No significant circularity; SCOUT is a self-contained methodological proposal
full rationale
The paper introduces SCOUT as a new paradigm for long-text understanding based on the insight that query-relevant information is sparse, using active foraging with decoupled epistemic states, state-level gap diagnosis, coarse-to-fine exploration, and anchored updates. No equations, parameter fittings, or derivations are presented that reduce any claim to its own inputs by construction. No self-citations appear as load-bearing for uniqueness theorems, ansatzes, or renamings of known results. Experimental claims of matching SOTA performance at lower token cost are framed as empirical outcomes rather than forced predictions. The approach is independent of prior fitted quantities and does not rely on self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Query-relevant information is typically sparse relative to the full document
- domain assumption Adaptive alternation between exploration and state updates can contract the epistemic state to query sufficiency
invented entities (2)
-
epistemic state
no independent evidence
-
state-level gap diagnosis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5 system card
Anthropic . Claude sonnet 4.5 system card. https://www.anthropic.com/claude/sonnet, 2025 a . Released September 29, 2025
2025
-
[2]
Claude code
Anthropic . Claude code. https://code.claude.com/docs/en/overview, 2025 b
2025
-
[3]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-rag: Learning to retrieve, generate, and critique through self-reflection. 2024
2024
-
[4]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Bai, Y., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y., Tang, J., and Li, J. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguis...
2025
-
[6]
Deepseek-v3.2-exp: Boosting long-context efficiency with deepseek sparse attention, 2025
DeepSeek-AI. Deepseek-v3.2-exp: Boosting long-context efficiency with deepseek sparse attention, 2025
2025
-
[8]
Gemini 3 pro
Google DeepMind . Gemini 3 pro. https://deepmind.google/technologies/gemini/, 2025. Released November 18, 2025
2025
-
[10]
He, Z., Wang, Y., Li, J., Liang, K., and Zhang, M. Loogle v2: Are llms ready for real world long dependency challenges? In Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
2025
-
[11]
and Grave, E
Izacard, G. and Grave, E. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume, pp.\ 874--880, 2021
2021
-
[12]
The AI hippocampus: How far are we from human memory? Trans
Jia, Z., Li, J., Kang, Y., Wang, Y., Wu, T., Wang, Q., Wang, X., Zhang, S., Shen, J., Li, Q., Qi, S., Liang, Y., He, D., Zheng, Z., and Zhu, S.-C. The AI hippocampus: How far are we from human memory? Trans. Mach. Learn. Res., 2025, 2025. URL https://openreview.net/forum?id=Sk7pwmLuAY
2025
-
[15]
Learning to reason and memorize with self-notes
Lanchantin, J., Toshniwal, S., Weston, J., Sukhbaatar, S., et al. Learning to reason and memorize with self-notes. Advances in Neural Information Processing Systems, 36: 0 11891--11911, 2023
2023
-
[17]
u ttler, H., Lewis, M., Yih, W.-t., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \"u ttler, H., Lewis, M., Yih, W.-t., Rockt \"a schel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33: 0 9459--9474, 2020
2020
-
[23]
OpenAI . Gpt-4.1. https://openai.com/index/gpt-4-1, 2025 a . Released April 14, 2025
2025
-
[24]
Gpt-5 system card
OpenAI . Gpt-5 system card. https://openai.com/index/introducing-gpt-5, 2025 b . Released August 7, 2025
2025
-
[26]
Qwen2.5: A party of foundation models, September 2024
Qwen Team . Qwen2.5: A party of foundation models, September 2024. URL https://qwenlm.github.io/blog/qwen2.5/
2024
-
[27]
Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., and Manning, C. D. Raptor: Recursive abstractive processing for tree-organized retrieval. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review arXiv 2024
-
[30]
Adaptive preference optimization with uncertainty-aware utility anchor
Wang, X., Jia, Z., Li, J., Liu, Q., and Zheng, Z. Adaptive preference optimization with uncertainty-aware utility anchor. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 19204--19225, 2025
2025
-
[33]
R., and Cao, Y
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023. URL https://openreview.net/forum?id=WE\_vluYUL-X
2023
-
[37]
Evolving generalist virtual agents with generative and associative memory
Zhang, Z., Bu, W., Pan, K., Miao, B., Zhang, W., Wang, G., Ji, W., Tang, R., Li, J., and Tang, S. Evolving generalist virtual agents with generative and associative memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 13006--13014, 2026
2026
-
[39]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review arXiv
-
[40]
arXiv preprint arXiv:2508.13167 , year=
Chain-of-agents: End-to-end agent foundation models via multi-agent distillation and agentic rl , author=. arXiv preprint arXiv:2508.13167 , year=
-
[41]
arXiv preprint arXiv:2402.09727 , year=
A human-inspired reading agent with gist memory of very long contexts , author=. arXiv preprint arXiv:2402.09727 , year=
-
[42]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent , author=. arXiv preprint arXiv:2507.02259 , year=
-
[43]
Li, Shilong and He, Yancheng and Guo, Hangyu and Bu, Xingyuan and Bai, Ge and Liu, Jie and Liu, Jiaheng and Qu, Xingwei and Li, Yangguang and Ouyang, Wanli and Su, Wenbo and Zheng, Bo. G raph R eader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024...
-
[44]
2024 , publisher=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. 2024 , publisher=
2024
-
[45]
B ench: Extending Long Context Evaluation Beyond 100 K Tokens
Zhang, Xinrong and Chen, Yingfa and Hu, Shengding and Xu, Zihang and Chen, Junhao and Hao, Moo and Han, Xu and Thai, Zhen and Wang, Shuo and Liu, Zhiyuan and Sun, Maosong. B ench: Extending Long Context Evaluation Beyond 100 K Tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi...
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review arXiv
-
[47]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review arXiv
-
[48]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Ring attention with blockwise transformers for near-infinite context , author=. arXiv preprint arXiv:2310.01889 , year=
work page internal anchor Pith review arXiv
-
[49]
Zhao, Jun and Zu, Can and Hao, Xu and Lu, Yi and He, Wei and Ding, Yiwen and Gui, Tao and Zhang, Qi and Huang, Xuanjing. LONGAGENT : Achieving Question Answering for 128k-Token-Long Documents through Multi-Agent Collaboration. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.912
-
[50]
Advances in Neural Information Processing Systems , volume=
Learning to reason and memorize with self-notes , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2310.05029 , year=
Walking down the memory maze: Beyond context limit through interactive reading , author=. arXiv preprint arXiv:2310.05029 , year=
-
[52]
L ight RAG : Simple and Fast Retrieval-Augmented Generation
Guo, Zirui and Xia, Lianghao and Yu, Yanhua and Ao, Tu and Huang, Chao. L ight RAG : Simple and Fast Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.568
-
[53]
Memorag: Moving towards next-gen rag via memory-inspired knowledge discovery, 2024
Memorag: Moving towards next-gen rag via memory-inspired knowledge discovery , author=. arXiv preprint arXiv:2409.05591 , volume=
-
[54]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Agentic retrieval-augmented generation: A survey on agentic rag , author=. arXiv preprint arXiv:2501.09136 , year=
work page internal anchor Pith review arXiv
-
[55]
The Twelfth International Conference on Learning Representations , year=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. The Twelfth International Conference on Learning Representations , year=
-
[56]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review arXiv
-
[57]
Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year=
LooGLE v2: Are LLMs Ready for Real World Long Dependency Challenges? , author=. Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year=
-
[58]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[59]
2025 , note=
GPT-5 System Card , author=. 2025 , note=
2025
-
[60]
2025 , note=
Claude Sonnet 4.5 System Card , author=. 2025 , note=
2025
-
[61]
2025 , note=
Gemini 3 Pro , author=. 2025 , note=
2025
-
[62]
2025 , note=
GPT-4.1 , author=. 2025 , note=
2025
-
[63]
Claude Code , author=
-
[64]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
arXiv preprint arXiv:2510.21618 , year=
DeepAgent: A General Reasoning Agent with Scalable Toolsets , author=. arXiv preprint arXiv:2510.21618 , year=
-
[66]
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization , author=. arXiv preprint arXiv:2509.13313 , year=
-
[67]
DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention , author=
-
[68]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review arXiv
-
[69]
Qwen2.5: A Party of Foundation Models , url =
-
[70]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[71]
Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
Leveraging passage retrieval with generative models for open domain question answering , author=. Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume , pages=
-
[72]
arXiv preprint arXiv:2510.20022 , year=
SALT: Step-level advantage assignment for long-horizon agents via trajectory graph , author=. arXiv preprint arXiv:2510.20022 , year=
-
[73]
ACON : Optimizing context compression for long-horizon LLM agents, 2025
Acon: Optimizing context compression for long-horizon llm agents , author=. arXiv preprint arXiv:2510.00615 , year=
-
[74]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Tiantian Fan and Gaohong Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Chen and Chengyi Wang and Hongli ...
-
[75]
Lost in the Middle: How Language Models Use Long Contexts
Tom. The NarrativeQA Reading Comprehension Challenge , journal =. 2018 , url =. doi:10.1162/TACL\_A\_00023 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2018
-
[76]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks , booktitle =
Yushi Bai and Shangqing Tu and Jiajie Zhang and Hao Peng and Xiaozhi Wang and Xin Lv and Shulin Cao and Jiazheng Xu and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , editor =. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks , booktitle =. 2025 , url =
2025
-
[77]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[78]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[79]
Corrective Retrieval Augmented Generation
Corrective retrieval augmented generation , author=. arXiv preprint arXiv:2401.15884 , year=
work page internal anchor Pith review arXiv
-
[80]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Evolving Generalist Virtual Agents with Generative and Associative Memory , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[81]
arXiv preprint arXiv:2404.12045 , year=
RAM: Towards an Ever-Improving Memory System by Learning from Communications , author=. arXiv preprint arXiv:2404.12045 , year=
-
[82]
Jia, Zixia and Li, Jiaqi and Kang, Yipeng and Wang, Yuxuan and Wu, Tong and Wang, Quansen and Wang, Xiaobo and Zhang, Shuyi and Shen, Junzhe and Li, Qing and Qi, Siyuan and Liang, Yitao and He, Di and Zheng, Zilong and Zhu, Song-Chun , title=. Trans. Mach. Learn. Res. , volume=. 2025 , url=
2025
-
[83]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Adaptive Preference Optimization with Uncertainty-aware Utility Anchor , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.