Recognition: unknown
Velox: Learning Representations of 4D Geometry and Appearance
Pith reviewed 2026-05-08 17:13 UTC · model grok-4.3
The pith
Dynamic shape tokens from point clouds can represent both 4D geometry and appearance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
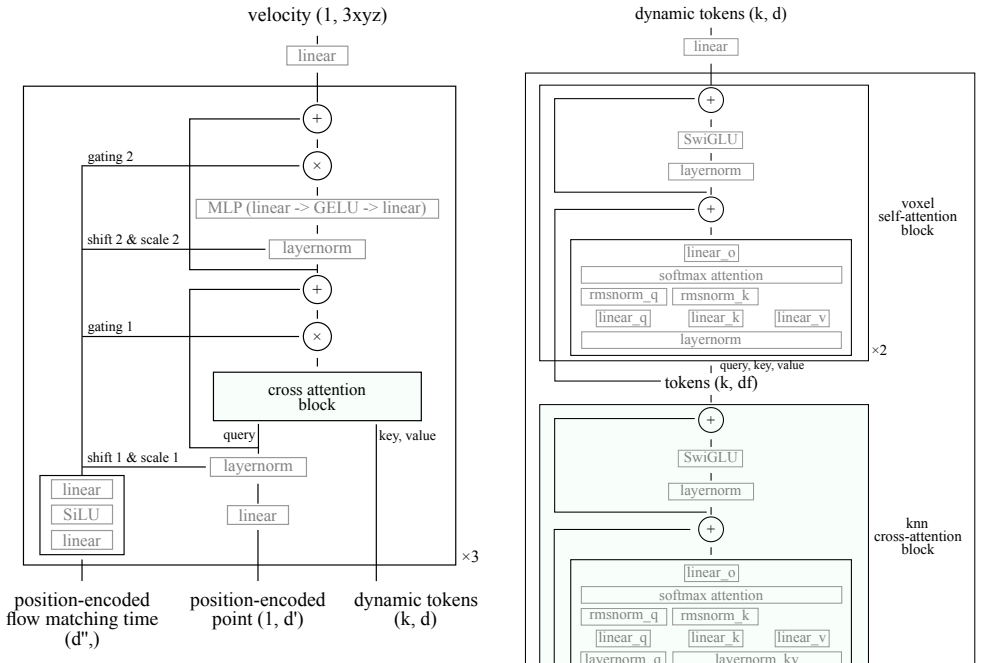
Velox trains an encoder to compress spatiotemporal color point clouds into a set of dynamic shape tokens. These tokens are supervised using two complementary decoders: a 4D surface decoder, which models the time-varying surface distribution capturing the geometry; and a Gaussian decoder, which maps the tokens to 3D Gaussians, helping learn appearance. The framework yields a representation that is descriptive, compressive, and accessible.
What carries the argument
dynamic shape tokens supervised by a 4D surface decoder and a Gaussian decoder
If this is right
- The tokens support strong performance in video-to-4D generation.
- They enable effective 3D tracking through the learned representations.
- Image-to-4D generation works for cloth simulation tasks.
- The compressive nature improves efficiency in downstream 4D processing.
- Only unstructured dynamic point clouds are required as input.
Where Pith is reading between the lines
- The tokens might support efficient storage and transmission of 4D content in applications like streaming.
- The dual decoder setup could allow somewhat independent control or refinement of geometry versus appearance.
- This compression approach might reduce data needs for training other 4D models compared to mesh or voxel methods.
- It could extend to full scene dynamics if the tokens prove robust beyond single objects.
Load-bearing premise
The dynamic shape tokens, when decoded separately, accurately and completely represent the 4D object's geometry and appearance without mode collapse or need for extra structure.
What would settle it
If the decoded surfaces or Gaussians show large errors compared to the input point clouds in geometry or appearance, or if results on video-to-4D generation, 3D tracking, and cloth simulation fall below prior methods, the central claim would not hold.
Figures









read the original abstract
We introduce a framework for learning latent representations of 4D objects which are descriptive, faithfully capturing object geometry and appearance; compressive, aiding in downstream efficiency; and accessible, requiring minimal input, i.e., an unstructured dynamic point cloud, to construct. Specifically, Velox trains an encoder to compress spatiotemporal color point clouds into a set of dynamic shape tokens. These tokens are supervised using two complementary decoders: a 4D surface decoder, which models the time-varying surface distribution capturing the geometry; and a Gaussian decoder, which maps the tokens to 3D Gaussians, helping learn appearance. To demonstrate the utility of our representation, we evaluate it across three downstream tasks -- video-to-4D generation, 3D tracking, and cloth simulation via image-to-4D generation -- and observe strong performances in all settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Velox, a framework for learning latent representations of 4D objects from unstructured spatiotemporal color point clouds. An encoder compresses the input into a set of dynamic shape tokens supervised jointly by a 4D surface decoder (capturing time-varying geometry) and a Gaussian decoder (capturing appearance). The representation is evaluated on three downstream tasks—video-to-4D generation, 3D tracking, and cloth simulation via image-to-4D generation—where it reports strong performance.
Significance. If the results hold, the work offers a potentially useful compressive and accessible 4D representation that jointly encodes geometry and appearance from minimal unstructured input. The dual-decoder supervision is a clear strength for ensuring descriptive power, and the multi-task evaluation demonstrates practical utility for generation, tracking, and simulation pipelines. Explicit credit is due for the self-contained encoder-decoder design that avoids additional structured inputs such as correspondences.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim that the dynamic shape tokens are both compressive and faithful rests on downstream task performance, yet no ablation studies on token count, loss weighting between the two decoders, or explicit checks for mode collapse / temporal consistency are reported. Without these, it remains unclear whether the joint supervision actually prevents one decoder from dominating or the latent space from degenerating, which directly undermines the 'compressive and accessible' guarantees.
- [§3.2 (Decoder supervision)] §3.2 (Decoder supervision): the 4D surface decoder and Gaussian decoder are presented as complementary, but the manuscript provides no analysis or regularization term ensuring that the shared token set allocates capacity to both geometry and appearance rather than collapsing to one. This is load-bearing for the claim that a single token set faithfully represents the underlying 4D object.
minor comments (2)
- [Abstract] The abstract states 'strong performances' without any numerical values, baselines, or error bars; this should be supplemented with at least one key quantitative result per task to allow readers to assess the contribution immediately.
- [§3 (Method)] Notation for the dynamic shape tokens (e.g., how they are indexed over time) is introduced without a clear diagram or equation reference in the early sections, making the architecture description harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of Velox's potential utility. We address the two major comments below and commit to revisions that directly strengthen the experimental and analytical support for our claims.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim that the dynamic shape tokens are both compressive and faithful rests on downstream task performance, yet no ablation studies on token count, loss weighting between the two decoders, or explicit checks for mode collapse / temporal consistency are reported. Without these, it remains unclear whether the joint supervision actually prevents one decoder from dominating or the latent space from degenerating, which directly undermines the 'compressive and accessible' guarantees.
Authors: We agree that the current evaluation relies primarily on downstream task performance and that targeted ablations would provide more direct validation of the claims. In the revised manuscript we will add: (i) an ablation on token count (e.g., 64, 128, 256) with corresponding compression ratios and downstream metrics; (ii) loss-weighting sweeps between the 4D surface and Gaussian terms, reporting both geometry and appearance fidelity; and (iii) explicit checks for mode collapse and temporal consistency via per-frame reconstruction variance, token activation diversity, and qualitative temporal coherence visualizations. These results will be incorporated into §4 and the associated tables. revision: yes
-
Referee: [§3.2 (Decoder supervision)] §3.2 (Decoder supervision): the 4D surface decoder and Gaussian decoder are presented as complementary, but the manuscript provides no analysis or regularization term ensuring that the shared token set allocates capacity to both geometry and appearance rather than collapsing to one. This is load-bearing for the claim that a single token set faithfully represents the underlying 4D object.
Authors: We acknowledge that an explicit analysis of capacity allocation is missing. The joint supervision is intended to be complementary because the 4D surface decoder requires accurate spatiotemporal geometry while the Gaussian decoder requires view-consistent appearance; however, we will strengthen §3.2 by adding an analysis that quantifies each decoder's contribution (e.g., performance drop when one loss is removed) and by reporting token utilization statistics across geometry versus appearance features. We will also discuss why the current formulation did not require an additional regularization term and, if needed, introduce a lightweight balancing term in the revision. revision: yes
Circularity Check
No significant circularity; standard multi-decoder supervision on learned tokens
full rationale
The described framework trains an encoder to map unstructured spatiotemporal point clouds to dynamic shape tokens, then applies independent supervision via a 4D surface decoder (for geometry) and a Gaussian decoder (for appearance). These decoder objectives are external to the token definition itself and serve as training signals rather than tautological redefinitions. Downstream evaluations on video-to-4D generation, tracking, and simulation provide separate empirical checks. No equations, self-citations, fitted parameters renamed as predictions, or uniqueness theorems are quoted that would collapse the central claim back to its inputs by construction. The architecture remains self-contained with clear separation between representation and supervision.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of dynamic shape tokens
- training hyperparameters
axioms (2)
- domain assumption Unstructured dynamic point clouds contain sufficient information to recover both time-varying geometry and appearance
- standard math Standard supervised training with reconstruction losses will yield generalizable latent tokens
invented entities (1)
-
dynamic shape tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Peasant girl breakdance 1990 (fbx).https: / / sketchfab
624230037. Peasant girl breakdance 1990 (fbx).https: / / sketchfab . com / 3d - models / 624230037 - peasant - girl - breakdance - 1990 - fbx - 01782ab4a2994d0a89e58ef96e951958, 2022. Licensed under Creative Commons Attribution. 3
1990
-
[2]
Bo Ai, Stephen Tian, Haochen Shi, Yixuan Wang, Che- ston Tan, Yunzhu Li, and Jiajun Wu. Robopack: Learning tactile-informed dynamics models for dense packing.arXiv preprint arXiv:2407.01418, 2024. 2, 8
-
[3]
Sherwin Bahmani, Xian Liu, Wang Yifan, Ivan Sko- rokhodov, Victor Rong, Ziwei Liu, Xihui Liu, Jeong Joon Park, Sergey Tulyakov, Gordon Wetzstein, Andrea Tagliasacchi, and David B. Lindell. Tc4d: Trajectory- conditioned text-to-4d generation.arXiv, 2024. 2, 8
2024
-
[4]
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gor- don Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B. Lindell. 4d-fy: Text-to-4d generation using hybrid score distillation sampling.IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 8
2024
-
[5]
Motion2vecsets: 4d latent vector set diffu- sion for non-rigid shape reconstruction and tracking
Wei Cao, Chang Luo, Biao Zhang, Matthias Nießner, and Jiapeng Tang. Motion2vecsets: 4d latent vector set diffu- sion for non-rigid shape reconstruction and tracking. In IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2024. 2
2024
-
[6]
Mathilde Caron, Ishan Misra, Julien Mairal, Piotr Bo- janowski, Armand Joulin, Matthijs Douze, and Herv ´e J´egou. Unsupervised learning of visual features by contrast- ing cluster assignments.arXiv preprint arXiv:2008.04968,
-
[7]
Emerging properties in self-supervised vision transformers.arXiv preprint arXiv:2104.14294,
M. Caron et al. Emerging properties in self-supervised vi- sion transformers.arXiv preprint arXiv:2104.14294, 2021. 1
-
[8]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inpro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017. 6, 7
2017
-
[9]
Jo ˜ao Carreira, Dilara Gokay, Michael King, Chuhan Zhang, Ignacio Rocco, Aravindh Mahendran, Thomas Al- bert Keck, Joseph Heyward, Skanda Koppula, Etienne Pot, Goker Erdogan, Yana Hasson, Yi Yang, Klaus Greff, Guil- laume Le Moing, Sjoerd van Steenkiste, Daniel Zoran, Drew A. Hudson, Pedro V ´elez, Luisa Polan´ıa, Luke Fried- man, Chris Duvarney, Ross Go...
2024
-
[10]
3D Shape Tokenization via La- tent Flow Matching.arXiv, 2024
Jen-Hao Rick Chang, Yuyang Wang, Miguel An- gel Bautista Martin, Jiatao Gu, Xiaoming Zhao, Josh Susskind, and Oncel Tuzel. 3D Shape Tokenization via La- tent Flow Matching.arXiv, 2024. 2, 3, 4, 1
2024
-
[11]
LiTo: Surface Light Field Tokenization
Jen-Hao Rick Chang ∗, Xiaoming Zhao∗, Dorian Chan, and Oncel Tuzel. LiTo: Surface Light Field Tokenization. InIn- ternational Conference on Learning Representations, 2026. 2, 3, 4, 5, 7, 8, 1
2026
-
[12]
Dora: Sampling and benchmarking for 3d shape variational auto-encoders
Rui Chen, Jianfeng Zhang, Yixun Liang, Guan Luo, Weiyu Li, Jiarui Liu, Xiu Li, Xiaoxiao Long, Jiashi Feng, and Ping Tan. Dora: Sampling and benchmarking for 3d shape variational auto-encoders. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 16251–16261, 2025. 2
2025
-
[13]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen Chen, Simon Kornblith, Mohammad Noroozi, and Geoffrey Hinton. A simple framework for con- trastive learning of visual representations.arXiv preprint arXiv:2002.05709, 2020. 1
work page internal anchor Pith review arXiv 2002
-
[14]
Pointcept: A codebase for point cloud perception research.https://github.com/ Pointcept/Pointcept, 2023
Pointcept Contributors. Pointcept: A codebase for point cloud perception research.https://github.com/ Pointcept/Pointcept, 2023. 2
2023
-
[15]
Kettlebell swing
coolguy26bog. Kettlebell swing. Sketchfab, 2020. Li- censed under Creative Commons Attribution. 1
2020
-
[16]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Infor- mation Processing Systems (NeurIPS), 35:16344–16359,
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo- pher R ´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Infor- mation Processing Systems (NeurIPS), 35:16344–16359,
-
[17]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Obja- verse: A universe of annotated 3d objects.arXiv preprint arXiv:2212.08051, 2022. 2, 4, 5, 6
-
[18]
Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Chris- tian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023. 2, 4
-
[19]
Yellow joy butterfly.https://skfb
@dylansburner. Yellow joy butterfly.https://skfb. ly/o8pYF, 2021. Licensed under Creative Commons At- tribution. 1
2021
-
[20]
Hyperdiffusion: Generating implicit neural fields with weight-space diffusion, 2023
Ziya Erkoc ¸, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. Hyperdiffusion: Generating implicit neural fields with weight-space diffusion, 2023. 2
2023
-
[21]
Fast dynamic radiance fields with time-aware neural voxels
Jiemin Fang, Taoran Yi, Xinggang Wang, Lingxi Xie, Xi- aopeng Zhang, Wenyu Liu, Matthias Nießner, and Qi Tian. Fast dynamic radiance fields with time-aware neural voxels. InSIGGRAPH Asia 2022 Conference Papers, 2022. 2
2022
-
[22]
Black, Trevor Darrell, and Angjoo Kanazawa
Haiwen Feng*, Junyi Zhang*, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, and Angjoo Kanazawa. St4rtrack: Simultaneous 4d recon- struction and tracking in the world. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[23]
K- planes: Explicit radiance fields in space, time, and appear- ance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K- planes: Explicit radiance fields in space, time, and appear- ance. InCVPR, 2023. 2
2023
-
[24]
arXiv preprint arXiv:2403.12365 (2024)
Quankai Gao, Qiangeng Xu, Zhe Cao, Ben Mildenhall, Wenchao Ma, Le Chen, Danhang Tang, and Ulrich Neu- mann. Gaussianflow: Splatting gaussian dynamics for 4d content creation.arXiv preprint arXiv:2403.12365, 2024. 2, 8
-
[25]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step genera- tive modeling.arXiv preprint arXiv:2505.13447, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[26]
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jonathan B Grill, Florian Strub, Martin Altchech, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Moham- mad Gheshlaghi Azar, B ´eatrice Piot, G ´abor V ´ertesi, Marc G Bellemare, et al. Bootstrap your own latent: A new approach to self-supervised learning.arXiv preprint arXiv:2006.07733, 2020. 1
-
[27]
Harley, Fangyu Li, S
Adam W. Harley, Fangyu Li, S. Lakshmikanth, Xian Zhou, H. Tung, and Katerina Fragkiadaki. Embodied view- contrastive 3d feature learning, 2019. 2
2019
-
[28]
Particle video revisited: Tracking through occlusions using point trajectories
Adam W Harley, Zhaoyuan Fang, and Katerina Fragki- adaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Com- puter Vision, pages 59–75. Springer, 2022. 2, 4, 7
2022
-
[29]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B Girshick. Momentum contrast for unsuper- vised visual representation learning.arXiv preprint arXiv:1911.05722, 2020. 1
-
[30]
Learning dexterous deformable object manipulation through cross-embodiment dynamics learn- ing
Zihao He, Bo Ai, Yulin Liu, Weikang Wan, Henrik I Chris- tensen, and Hao Su. Learning dexterous deformable object manipulation through cross-embodiment dynamics learn- ing. In3rd RSS Workshop on Dexterous Manipulation: Learning and Control with Diverse Data, 2025. 2, 8
2025
-
[31]
Mesh-based dynamics with occlusion reasoning for cloth manipulation
Zixuan Huang, Xingyu Lin, and David Held. Mesh-based dynamics with occlusion reasoning for cloth manipulation. arXiv preprint arXiv:2206.02881, 2022. 2, 8
-
[32]
Jaegle, S
A. Jaegle, S. Borgeaud, J. Alayrac, et al. Perceiver io: A general architecture for structured inputs & outputs. InInternational Conference on Learning Representations (ICLR), 2022. 2, 3, 4, 1
2022
-
[33]
Consistent4d: Consistent 360° dynamic object gener- ation from monocular video
Yanqin Jiang, Li Zhang, Jin Gao, Weiming Hu, and Yao Yao. Consistent4d: Consistent 360° dynamic object gener- ation from monocular video. InThe Twelfth International Conference on Learning Representations, 2024. 2, 6, 8, 4, 5
2024
-
[34]
Stereo4d: Learning how things move in 3d from internet stereo videos.arXiv preprint, 2024
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4d: Learning how things move in 3d from internet stereo videos.arXiv preprint, 2024. 2, 8
2024
-
[35]
Co- tracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker: It is better to track together. InProc. ECCV, 2024. 7
2024
-
[36]
Co- Tracker3: Simpler and better point tracking by pseudo- labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- Tracker3: Simpler and better point tracking by pseudo- labelling real videos. InIEEE International Conference on Computer Vision (ICCV), 2025. 2, 4, 5, 8, 3, 7
2025
-
[37]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), 2023. 3, 4
2023
-
[38]
Kim, and Rana Hanocka
Hyunwoo Kim, Itai Lang, Noam Aigerman, Thibault Groueix, Vladimir G. Kim, and Rana Hanocka. Meshup: Multi-target mesh deformation via blended score distilla- tion, 2024. 2
2024
-
[39]
Tapvid-3d: A benchmark for tracking any point in 3d
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, Jo˜ao Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch. Tapvid-3d: A benchmark for tracking any point in 3d. InNeurIPS, 2024. 8, 3, 5
2024
-
[40]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Ste- fan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual re- lationship detection at scale.International Journal of Com- puter Vis...
1956
-
[41]
Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics (TOG), 2020
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics (TOG), 2020. 5
2020
-
[42]
Harley, and Katerina Fragkiadaki
Shamit Lal, Mihir Prabhudesai, Ishita Mediratta, Adam W. Harley, and Katerina Fragkiadaki. Coconets: Continuous contrastive 3d scene representations, 2021. 2
2021
-
[43]
Dense optical tracking: Connecting the dots
Guillaume Le Moing, Jean Ponce, and Cordelia Schmid. Dense optical tracking: Connecting the dots. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19187–19197, 2024. 2, 7
2024
-
[44]
xformers: A modular and hackable trans- former modelling library.https://github.com/ facebookresearch/xformers, 2022
Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, Daniel Haziza, Luca Wehrstedt, Jeremy Reizenstein, and Grigory Sizov. xformers: A modular and hackable trans- former modelling library.https://github.com/ facebookresearch/xformers, 2022. 2
2022
-
[45]
Neural 3d video synthesis from multi- view video, 2022
Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, and Zhaoyang Lv. Neural 3d video synthesis from multi- view video, 2022. 2
2022
-
[46]
Yunzhu Li, Jiajun Wu, Russ Tedrake, Joshua B Tenen- baum, and Antonio Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and flu- ids.arXiv preprint arXiv:1810.01566, 2018. 5
-
[47]
arXiv2502.06608(2025) 5, 6, 10
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. TripoSG: High-fidelity 3d shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608, 2025. 1
-
[48]
arXiv preprint arXiv:2405.16645 , year=
Hanwen Liang, Yuyang Yin, Dejia Xu, Hanxue Liang, Zhangyang Wang, Konstantinos N Plataniotis, Yao Zhao, and Yunchao Wei. Diffusion4d: Fast spatial-temporal con- sistent 4d generation via video diffusion models.arXiv preprint arXiv:2405.16645, 2024. 2, 5, 8
-
[49]
Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fi- dler, and Karsten Kreis. Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8576–8588, 2024. 2, 8
2024
-
[50]
Learning keypoints for robotic cloth manipulation us- ing synthetic data, 2024
Thomas Lips, Victor-Louis De Gusseme, and Francis wyf- fels. Learning keypoints for robotic cloth manipulation us- ing synthetic data, 2024. 4, 5
2024
-
[51]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InIEEE International Conference on Computer Vision (ICCV), pages 9298–9309,
-
[52]
Robust dynamic radi- ance fields
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Jo- hannes Kopf, and Jia-Bin Huang. Robust dynamic radi- ance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 2
2023
-
[53]
Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis. In3DV, 2024. 2, 4
2024
-
[54]
Diffusion probabilistic models for 3d point cloud generation
Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 2837– 2845, 2021. 2
2021
-
[55]
Unified particle physics for real-time ap- plications.ACM Transactions on Graphics (TOG), 33(4): 1–12, 2014
Miles Macklin, Matthias M ¨uller, Nuttapong Chentanez, and Tae-Yong Kim. Unified particle physics for real-time ap- plications.ACM Transactions on Graphics (TOG), 33(4): 1–12, 2014. 5
2014
-
[56]
Mantiuk, Param Hanji, Maliha Ashraf, Yuta Asano, and Alexandre Chapiro
Rafal K. Mantiuk, Param Hanji, Maliha Ashraf, Yuta Asano, and Alexandre Chapiro. Colorvideovdp: A visual difference predictor for image, video and display distor- tions.ACM Trans. Graph., 43(4), 2024. 6
2024
-
[57]
Character x bot
Mirandanimator. Character x bot. Sketchfab, 2014. Li- censed under Creative Commons Attribution. 3
2014
-
[58]
Salsa.https://skfb.ly/6VPwM, 2020
Miyake. Salsa.https://skfb.ly/6VPwM, 2020. Li- censed under Creative Commons Attribution. 5
2020
-
[59]
Shazam roblox
mortaleiros. Shazam roblox. Sketchfab, 2018. Licensed under Creative Commons Attribution. 7
2018
-
[60]
DELTA: Dense efficient long-range 3D tracking for any video.arXiv preprint arXiv:2410.24211, 2024
Tuan Duc Ngo, Peiye Zhuang, Chuang Gan, Evange- los Kalogerakis, Sergey Tulyakov, Hsin-Ying Lee, and Chaoyang Wang. Delta: Dense efficient long-range 3d tracking for any video.arXiv preprint arXiv:2410.24211,
-
[61]
Katzschmann, and Stelian Coros
Jan Obrist, Miguel Zamora, Hehui Zheng, Ronan Hinchet, Firat Ozdemir, Juan Zarate, Robert K. Katzschmann, and Stelian Coros. Pokeflex: A real-world dataset of volumetirc deformable objects for robotics.Under review, 2025. 4, 6
2025
-
[62]
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El- Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Pa...
2024
-
[63]
arXiv preprint arXiv:2401.08742 , year=
Zijie Pan, Zeyu Yang, Xiatian Zhu, and Li Zhang. Effi- cient4d: Fast dynamic 3d object generation from a single- view video.arXiv preprint arXiv 2401.08742, 2024. 2, 8
-
[64]
Swimming fish.https://skfb.ly/ 6st7K, n.d
@paula1221965. Swimming fish.https://skfb.ly/ 6st7K, n.d. Licensed under Creative Commons Attribu- tion. 6
-
[65]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InIEEE International Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 3, 4
2023
-
[66]
D-nerf: Neural radiance fields for dynamic scenes.arXiv preprint arXiv:2011.13961,
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes.arXiv preprint arXiv:2011.13961,
-
[67]
Point- net++: Deep hierarchical feature learning on point sets in a metric space
Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Point- net++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2017. 1
2017
-
[68]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021. 7
2021
-
[69]
Davis Rempe, Tolga Birdal, Yongheng Zhao, Zan Gojcic, Srinath Sridhar, and L. Guibas. Caspr: Learning canonical spatiotemporal point cloud representations, 2020. 2
2020
-
[70]
arXiv preprint arXiv:2312.17142 , year=
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. Dreamgaussian4d: Generative 4d gaussian splatting.arXiv preprint arXiv:2312.17142,
-
[71]
L4gm: Large 4d gaussian reconstruction model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xi- aohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, and Huan Ling. L4gm: Large 4d gaussian reconstruction model. InAdvances in Neural Information Processing Systems, 2024. 2, 4, 6, 7, 3, 8
2024
-
[72]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution im- age synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2021. 2
work page Pith review arXiv 2021
-
[73]
Astro13 run.https : / / sketchfab
Nia Karaga Rosello. Astro13 run.https : / / sketchfab . com / 3d - models / astro13 - run - 1b5063221c724ee7b4751eb9c737ec77, 2021. Li- censed under Creative Commons Attribution. 3
2021
-
[74]
Particle video: Long-range mo- tion estimation using point trajectories.International jour- nal of computer vision, 80(1):72–91, 2008
Peter Sand and Seth Teller. Particle video: Long-range mo- tion estimation using point trajectories.International jour- nal of computer vision, 80(1):72–91, 2008. 2, 7
2008
-
[75]
Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering, 2023
Ruizhi Shao, Zerong Zheng, Hanzhang Tu, Boning Liu, Hongwen Zhang, and Yebin Liu. Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering, 2023. 2
2023
-
[76]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.CoRR, abs/2002.05202, 2020. 2
work page internal anchor Pith review arXiv 2002
-
[77]
Haochen Shi, Huazhe Xu, Samuel Clarke, Yunzhu Li, and Jiajun Wu. Robocook: Long-horizon elasto-plastic object manipulation with diverse tools.arXiv preprint arXiv:2306.14447, 2023. 2, 8
-
[78]
Robocraft: Learning to see, simulate, and shape elasto-plastic objects in 3d with graph networks.The In- ternational Journal of Robotics Research, 43(4):533–549,
Haochen Shi, Huazhe Xu, Zhiao Huang, Yunzhu Li, and Ji- ajun Wu. Robocraft: Learning to see, simulate, and shape elasto-plastic objects in 3d with graph networks.The In- ternational Journal of Robotics Research, 43(4):533–549,
-
[79]
Zero123++: a single image to consistent multi- view diffusion base model, 2023
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. Zero123++: a single image to consistent multi- view diffusion base model, 2023. 8
2023
-
[80]
arXiv preprint arXiv:2308.16512 , year=
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation.arXiv:2308.16512, 2023. 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.